projectdiscovery / katana
- четверг, 10 ноября 2022 г. в 00:36:22
A next-generation crawling and spidering framework.




Features • Installation • Usage • Scope • Config • Filters • Join Discord
katana requires Go 1.18 to install successfully. To install, just run the below command or download pre-compiled binary from release page.
go install github.com/projectdiscovery/katana/cmd/katana@latestkatana -hThis will display help for the tool. Here are all the switches it supports.
Usage:
./katana [flags]
Flags:
INPUT:
-u, -list string[] target url / list to crawl
CONFIGURATION:
-d, -depth int maximum depth to crawl (default 2)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-ct, -crawl-duration int maximum duration to crawl the target for
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml)
-mrs, -max-response-size int maximum response size to read (default 2097152)
-timeout int time to wait for request in seconds (default 10)
-aff, -automatic-form-fill enable optional automatic form filling (experimental)
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom header/cookie to include in request
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file
HEADLESS:
-hl, -headless enable headless hybrid crawling (experimental)
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless mode
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawling
FILTER:
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
-sf, -store-field string field to store in per-host output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
-em, -extension-match string[] match output for given extension (eg, -em php,html,js)
-ef, -extension-filter string[] filter output for given extension (eg, -ef png,css)
RATE-LIMIT:
-c, -concurrency int number of concurrent fetchers to use (default 10)
-p, -parallelism int number of concurrent inputs to process (default 10)
-rd, -delay int request delay between each request in seconds
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minute
OUTPUT:
-o, -output string file to write output to
-j, -json write output in JSONL(ines) format
-nc, -no-color disable output content coloring (ANSI escape codes)
-silent display output only
-v, -verbose display verbose output
-version display project versionkatana requires url or endpoint to crawl and accepts single or multiple inputs.
Input URL can be provided using -u option, and multiple values can be provided using comma-separated input, similarly file input is supported using -list option and additionally piped input (stdin) is also supported.
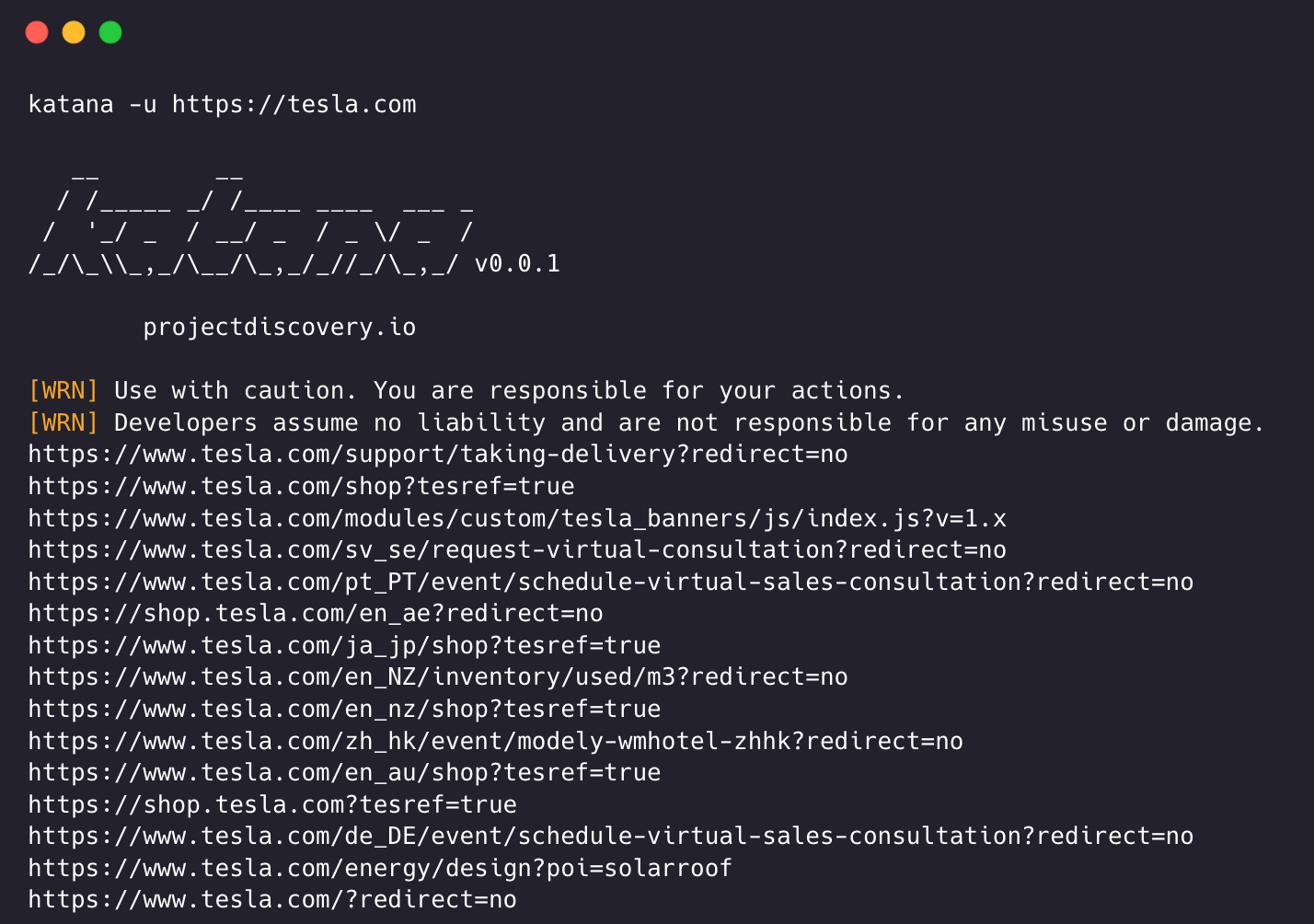
katana -u https://tesla.comkatana -u https://tesla.com,https://google.com$ cat url_list.txt
https://tesla.com
https://google.comkatana -list url_list.txt
echo https://tesla.com | katanacat domains | httpx | katanaExample running katana -
katana -u https://youtube.com
__ __
/ /_____ _/ /____ ____ ___ _
/ '_/ _ / __/ _ / _ \/ _ /
/_/\_\\_,_/\__/\_,_/_//_/\_,_/ v0.0.1
projectdiscovery.io
[WRN] Use with caution. You are responsible for your actions.
[WRN] Developers assume no liability and are not responsible for any misuse or damage.
https://www.youtube.com/
https://www.youtube.com/about/
https://www.youtube.com/about/press/
https://www.youtube.com/about/copyright/
https://www.youtube.com/t/contact_us/
https://www.youtube.com/creators/
https://www.youtube.com/ads/
https://www.youtube.com/t/terms
https://www.youtube.com/t/privacy
https://www.youtube.com/about/policies/
https://www.youtube.com/howyoutubeworks?utm_campaign=ytgen&utm_source=ythp&utm_medium=LeftNav&utm_content=txt&u=https%3A%2F%2Fwww.youtube.com%2Fhowyoutubeworks%3Futm_source%3Dythp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen
https://www.youtube.com/new
https://m.youtube.com/
https://www.youtube.com/s/desktop/4965577f/jsbin/desktop_polymer.vflset/desktop_polymer.js
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-home-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/cssbin/www-onepick.css
https://www.youtube.com/s/_/ytmainappweb/_/ss/k=ytmainappweb.kevlar_base.0Zo5FUcPkCg.L.B1.O/am=gAE/d=0/rs=AGKMywG5nh5Qp-BGPbOaI1evhF5BVGRZGA
https://www.youtube.com/opensearch?locale=en_GB
https://www.youtube.com/manifest.webmanifest
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-watch-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/jsbin/web-animations-next-lite.min.vflset/web-animations-next-lite.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/custom-elements-es5-adapter.vflset/custom-elements-es5-adapter.js
https://www.youtube.com/s/desktop/4965577f/jsbin/webcomponents-sd.vflset/webcomponents-sd.js
https://www.youtube.com/s/desktop/4965577f/jsbin/intersection-observer.min.vflset/intersection-observer.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/scheduler.vflset/scheduler.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-i18n-constants-en_GB.vflset/www-i18n-constants.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-tampering.vflset/www-tampering.js
https://www.youtube.com/s/desktop/4965577f/jsbin/spf.vflset/spf.js
https://www.youtube.com/s/desktop/4965577f/jsbin/network.vflset/network.js
https://www.youtube.com/howyoutubeworks/
https://www.youtube.com/trends/
https://www.youtube.com/jobs/
https://www.youtube.com/kids/Standard crawling modality uses the standard go http library under the hood to handle HTTP requests/responses. This modality is much faster as it doesn't have the browser overhead. Still, it analyzes HTTP responses body as is, without any javascript or DOM rendering, potentially missing post-dom-rendered endpoints or asynchronous endpoint calls that might happen in complex web applications depending, for example, on browser-specific events.
Headless mode hooks internal headless calls to handle HTTP requests/responses directly within the browser context. This offers two advantages:
Headless crawling is optional and can be enabled using -headless option.
Here are other headless CLI options -
katana -h headless
Flags:
HEADLESS:
-hl, -headless enable experimental headless hybrid crawling
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless modeCrawling can be endless if not scoped, as such katana comes with multiple support to define the crawl scope.
-field-scopeMost handy option to define scope with predefined field name, rdn being default option for field scope.
rdn - crawling scoped to root domain name and all subdomains (default)fqdn - crawling scoped to given sub(domain)dn - crawling scoped to domain name keywordkatana -u https://tesla.com -fs dn
-crawl-scopeFor advanced scope control, -cs option can be used that comes with regex support.
katana -u https://tesla.com -cs login
For multiple in scope rules, file input with multiline string / regex can be passed.
$ cat in_scope.txt
login/
admin/
app/
wordpress/katana -u https://tesla.com -cs in_scope.txt
-crawl-out-scopeFor defining what not to crawl, -cos option can be used and also support regex input.
katana -u https://tesla.com -cos logout
For multiple out of scope rules, file input with multiline string / regex can be passed.
$ cat out_of_scope.txt
/logout
/log_outkatana -u https://tesla.com -cos out_of_scope.txt
-no-scopeKatana is default to scope *.domain, to disable this -ns option can be used and also to crawl the internet.
katana -u https://tesla.com -ns
-display-out-scopeAs default, when scope option is used, it also applies for the links to display as output, as such external URLs are default to exclude and to overwrite this behavior, -do option can be used to display all the external URLs that exist in targets scoped URL / Endpoint.
katana -u https://tesla.com -do
Here is all the CLI options for the scope control -
katana -h scope
Flags:
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawlingKatana comes with multiple options to configure and control the crawl as the way we want.
-depthOption to define the depth to follow the urls for crawling, the more depth the more number of endpoint being crawled + time for crawl.
katana -u https://tesla.com -d 5
-js-crawlOption to enable JavaScript file parsing + crawling the endpoints discovered in JavaScript files, disabled as default.
katana -u https://tesla.com -jc
-crawl-durationOption to predefined crawl duration, disabled as default.
katana -u https://tesla.com -ct 2
-known-filesOption to enable crawling robots.txt and sitemap.xml file, disabled as default.
katana -u https://tesla.com -kf robotstxt,sitemapxml
-automatic-form-fillOption to enable automatic form filling for known / unknown fields, known field values can be customized as needed by updating form config file at $HOME/.config/katana/form-config.yaml.
Automatic form filling is experimental feature.
-aff, -automatic-form-fill enable optional automatic form filling (experimental)
There are more options to configure when needed, here is all the config related CLI options -
katana -h config
Flags:
CONFIGURATION:
-d, -depth int maximum depth to crawl (default 2)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-ct, -crawl-duration int maximum duration to crawl the target for
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml)
-mrs, -max-response-size int maximum response size to read (default 2097152)
-timeout int time to wait for request in seconds (default 10)
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom header/cookie to include in request
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file-fieldKatana comes with build in fields that can be used to filter the output for the desired information, -f option can be used to specify any of the available fields.
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
Here is a table with examples of each field and expected output when used -
| FIELD | DESCRIPTION | EXAMPLE |
|---|---|---|
url |
URL Endpoint | https://admin.projectdiscovery.io/admin/login?user=admin&password=admin |
qurl |
URL including query param | https://admin.projectdiscovery.io/admin/login.php?user=admin&password=admin |
qpath |
Path including query param | /login?user=admin&password=admin |
path |
URL Path | https://admin.projectdiscovery.io/admin/login |
fqdn |
Fully Qualified Domain name | admin.projectdiscovery.io |
rdn |
Root Domain name | projectdiscovery.io |
rurl |
Root URL | https://admin.projectdiscovery.io |
file |
Filename in URL | login.php |
key |
Parameter keys in URL | user,password |
value |
Parameter values in URL | admin,admin |
kv |
Keys=Values in URL | user=admin&password=admin |
dir |
URL Directory name | /admin/ |
udir |
URL with Directory | https://admin.projectdiscovery.io/admin/ |
Here is an example of using field option to only display all the urls with query parameter in it -
katana -u https://tesla.com -f qurl -silent
https://shop.tesla.com/en_au?redirect=no
https://shop.tesla.com/en_nz?redirect=no
https://shop.tesla.com/product/men_s-raven-lightweight-zip-up-bomber-jacket?sku=1740250-00-A
https://shop.tesla.com/product/tesla-shop-gift-card?sku=1767247-00-A
https://shop.tesla.com/product/men_s-chill-crew-neck-sweatshirt?sku=1740176-00-A
https://www.tesla.com/about?redirect=no
https://www.tesla.com/about/legal?redirect=no
https://www.tesla.com/findus/list?redirect=no
-store-fieldTo compliment field option which is useful to filter output at run time, there is -sf, -store-fields option which works exactly like field option except instead of filtering, it stores all the information on the disk under katana_output directory sorted by target url.
katana -u https://tesla.com -sf key,fqdn,qurl -silent
$ ls katana_output/
https_www.tesla.com_fqdn.txt
https_www.tesla.com_key.txt
https_www.tesla.com_qurl.txt
|
Here are additonal filter options -
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,file,key,value,kv,dir,udir)
-sf, -store-field string field to store in per-host output (url,path,fqdn,rdn,rurl,qurl,file,key,value,kv,dir,udir)
-em, -extension-match string[] match output for given extension (eg, -em php,html,js)
-ef, -extension-filter string[] filter output for given extension (eg, -ef png,css)It's easy to get blocked / banned while crawling if not following target websites limits, katana comes with multiple option to tune the crawl to go as fast / slow we want.
-delayoption to introduce a delay in seconds between each new request katana makes while crawling, disabled as default.
katana -u https://tesla.com -delay 20
-concurrencyoption to control the number of urls per target to fetch at the same time.
katana -u https://tesla.com -c 20
-parallelismoption to define number of target to process at same time from list input.
katana -u https://tesla.com -p 20
-rate-limitoption to use to define max number of request can go out per second.
katana -u https://tesla.com -rl 100
-rate-limit-minuteoption to use to define max number of request can go out per minute.
katana -u https://tesla.com -rlm 500
Here is all long / short CLI options for rate limit control -
katana -h rate-limit
Flags:
RATE-LIMIT:
-c, -concurrency int number of concurrent fetchers to use (default 10)
-p, -parallelism int number of concurrent inputs to process (default 10)
-rd, -delay int request delay between each request in seconds
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minute-jsonKatana support both file output in plain text format as well as JSON which includes additional information like, source, tag, and attribute name to co-related the discovered endpoint.
katana -u https://example.com -json -do | jq .{
"timestamp": "2022-11-05T22:33:27.745815+05:30",
"endpoint": "https://www.iana.org/domains/example",
"source": "https://example.com",
"tag": "a",
"attribute": "href"
}Here are additional CLI options related to output -
katana -h output
OUTPUT:
-o, -output string file to write output to
-j, -json write output in JSONL(ines) format
-nc, -no-color disable output content coloring (ANSI escape codes)
-silent display output only
-v, -verbose display verbose output
-version katana is made with
