intel-analytics / ipex-llm
- пятница, 5 апреля 2024 г. в 00:00:03
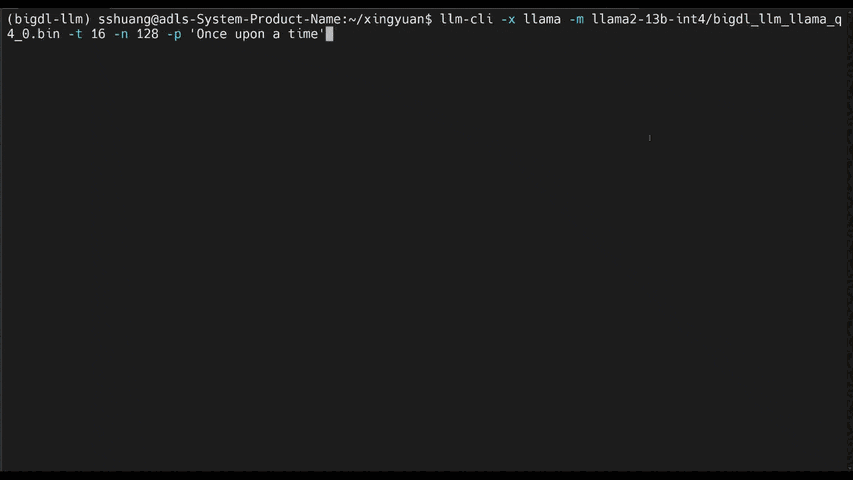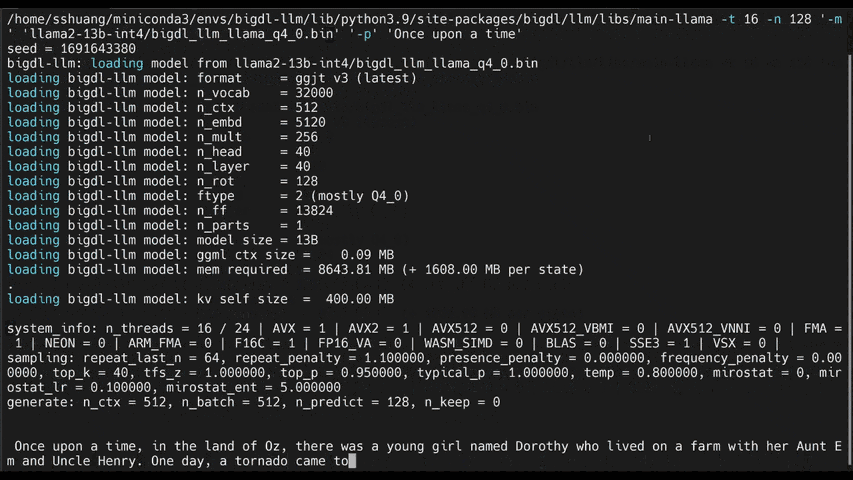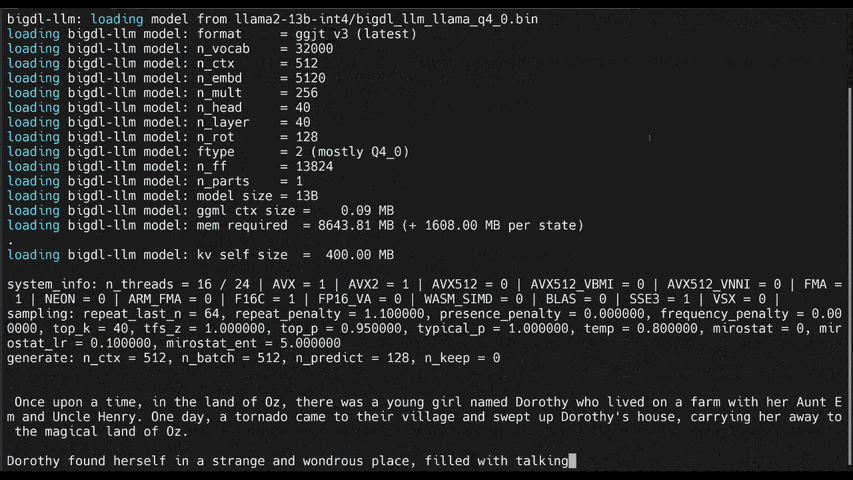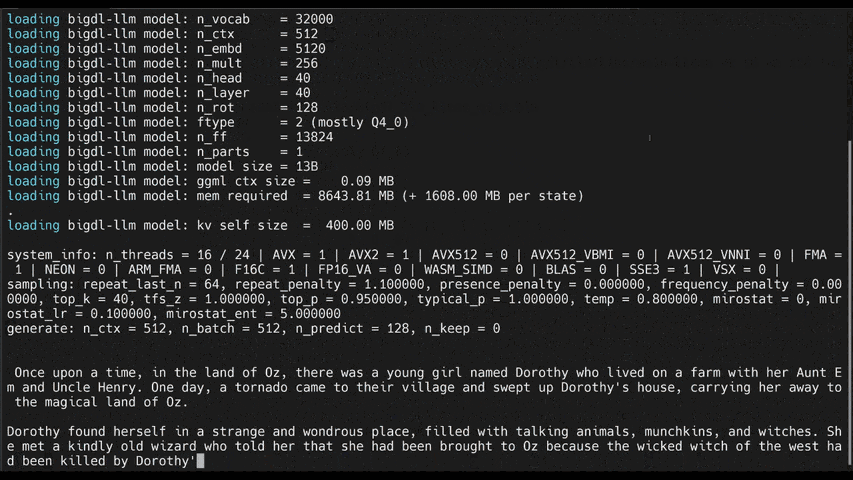
Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma, etc.) on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max). A PyTorch LLM library that seamlessly integrates with llama.cpp, HuggingFace, LangChain, LlamaIndex, DeepSpeed, vLLM, FastChat, ModelScope, etc.
Important
bigdl-llm has now become ipex-llm (see the migration guide here); you may find the original BigDL project here.
IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) with very low latency1.
Note
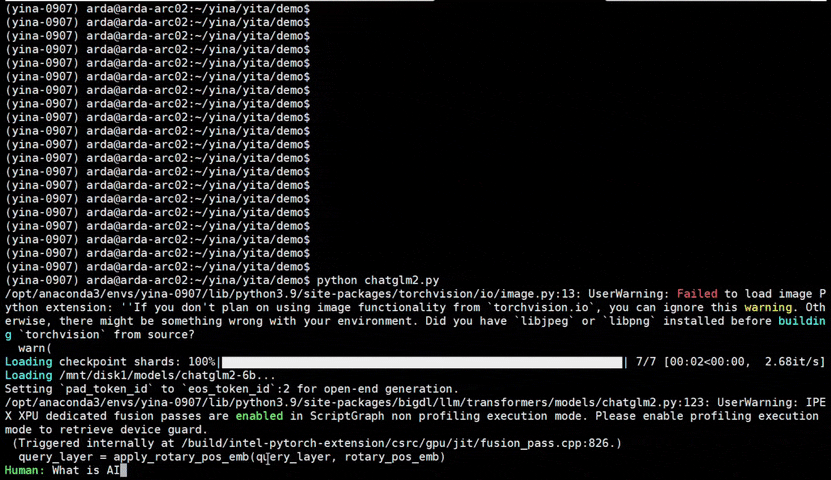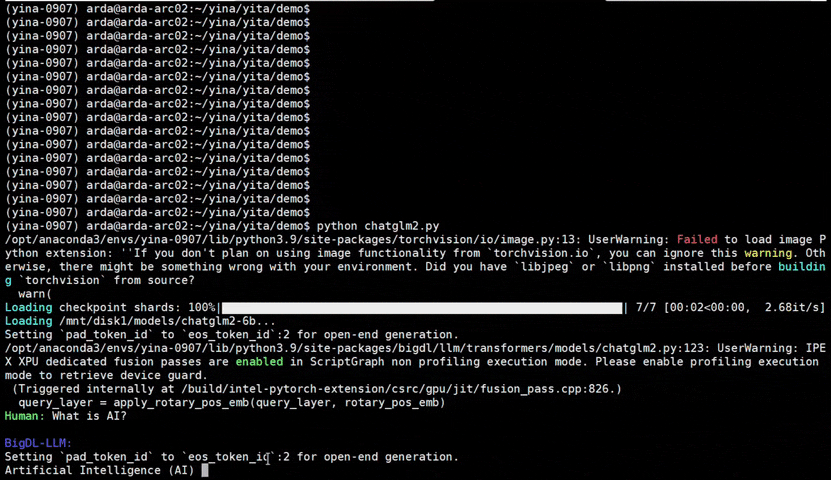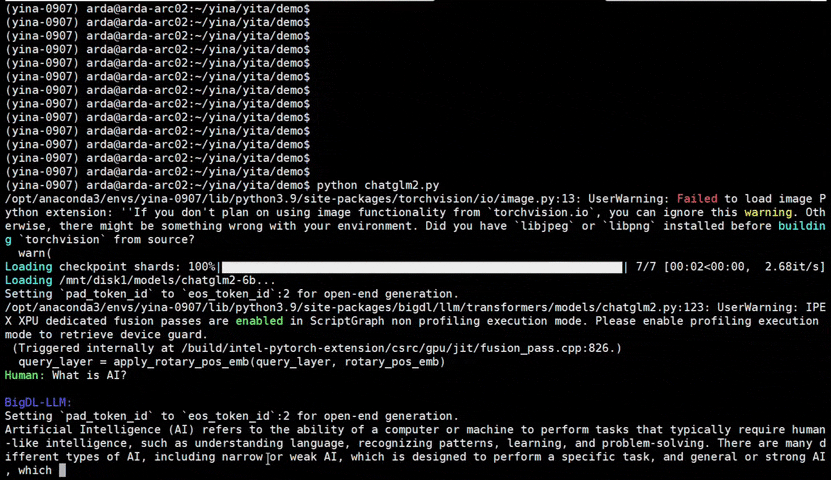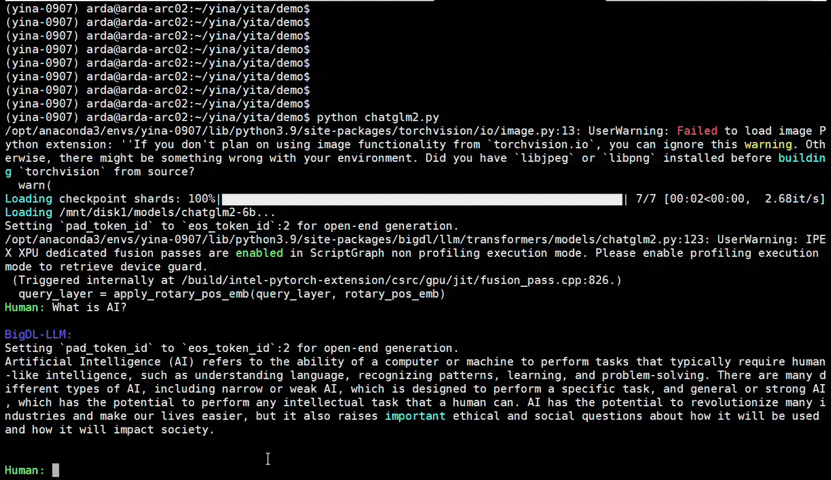
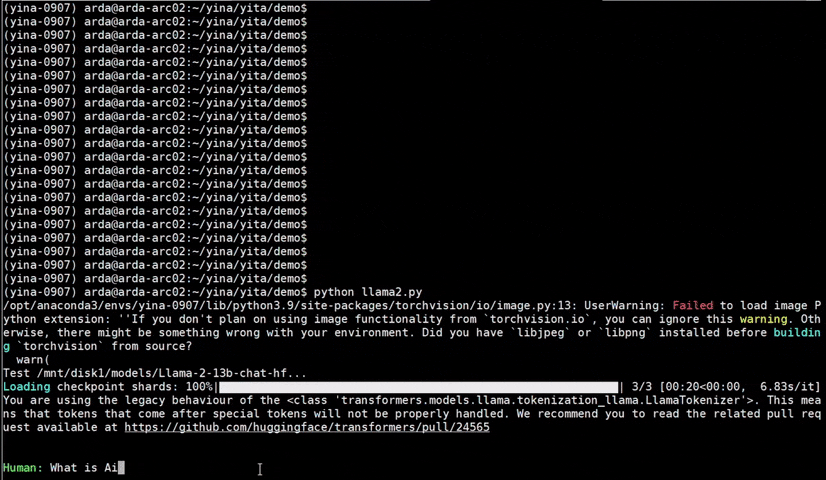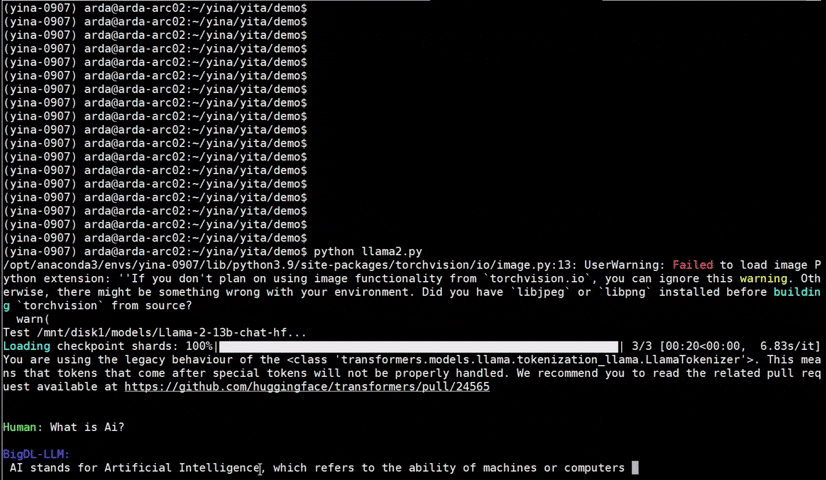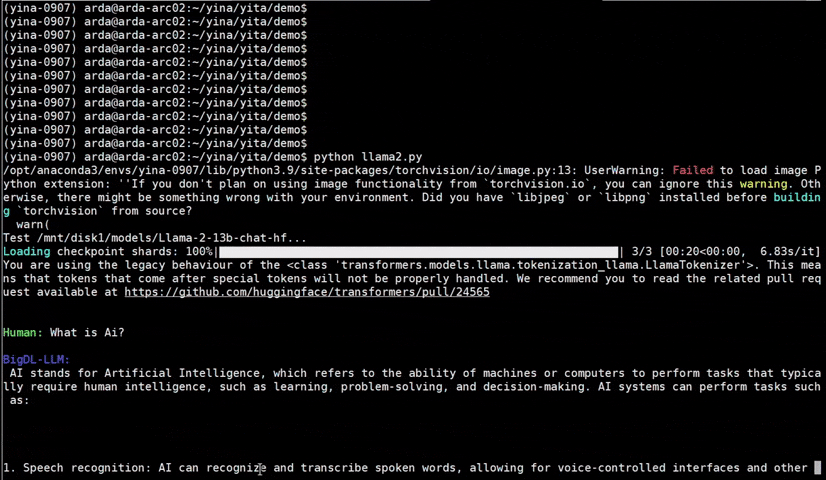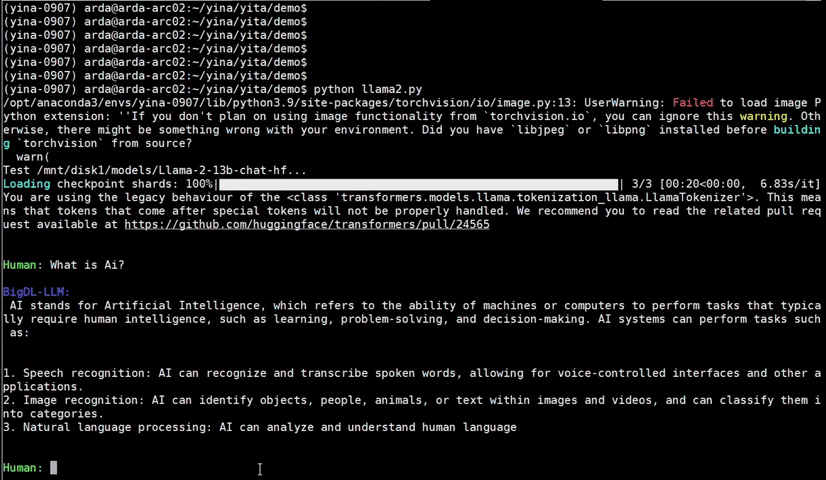
IPEX), as well as the excellent work of llama.cpp, bitsandbytes, vLLM, qlora, AutoGPTQ, AutoAWQ, etc.ipex-llm (including LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, RWKV, and more); see the complete list here.bigdl-llm has now become ipex-llm (see the migration guide here); you may find the original BigDL project here.ipex-llm now supports directly loading model from ModelScope (魔搭).ipex-llm added inital INT2 support (based on llama.cpp IQ2 mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.ipex-llm through Text-Generation-WebUI GUI.ipex-llm now supports Self-Speculative Decoding, which in practice brings ~30% speedup for FP16 and BF16 inference latency on Intel GPU and CPU respectively.ipex-llm now supports a comprehensive list of LLM finetuning on Intel GPU (including LoRA, QLoRA, DPO, QA-LoRA and ReLoRA).ipex-llm QLoRA, we managed to finetune LLaMA2-7B in 21 minutes and LLaMA2-70B in 3.14 hours on 8 Intel Max 1550 GPU for Standford-Alpaca (see the blog here).ipex-llm now supports ReLoRA (see "ReLoRA: High-Rank Training Through Low-Rank Updates").ipex-llm now supports Mixtral-8x7B on both Intel GPU and CPU.ipex-llm now supports QA-LoRA (see "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models").ipex-llm now supports FP8 and FP4 inference on Intel GPU.ipex-llm is available.ipex-llm now supports vLLM continuous batching on both Intel GPU and CPU.ipex-llm now supports QLoRA finetuning on both Intel GPU and CPU.ipex-llm now supports FastChat serving on on both Intel CPU and GPU.ipex-llm now supports Intel GPU (including iGPU, Arc, Flex and MAX).ipex-llm tutorial is released.See the optimized performance of chatglm2-6b and llama-2-13b-chat models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU | Intel Arc GPU | ||
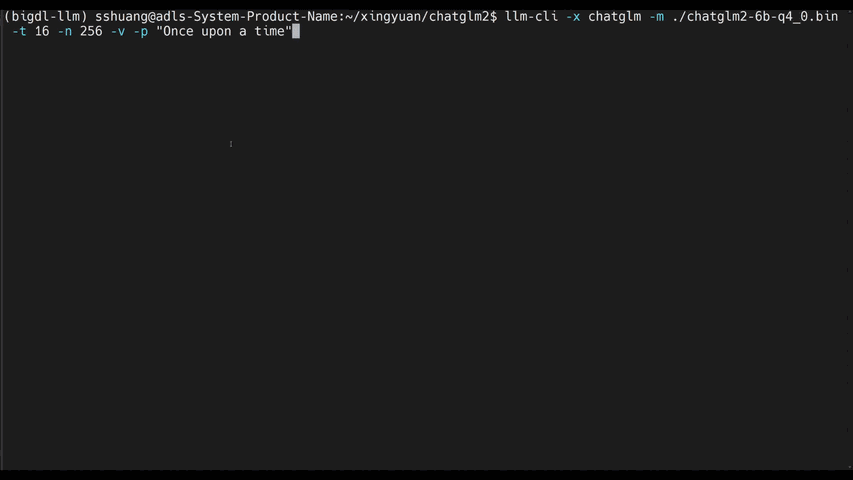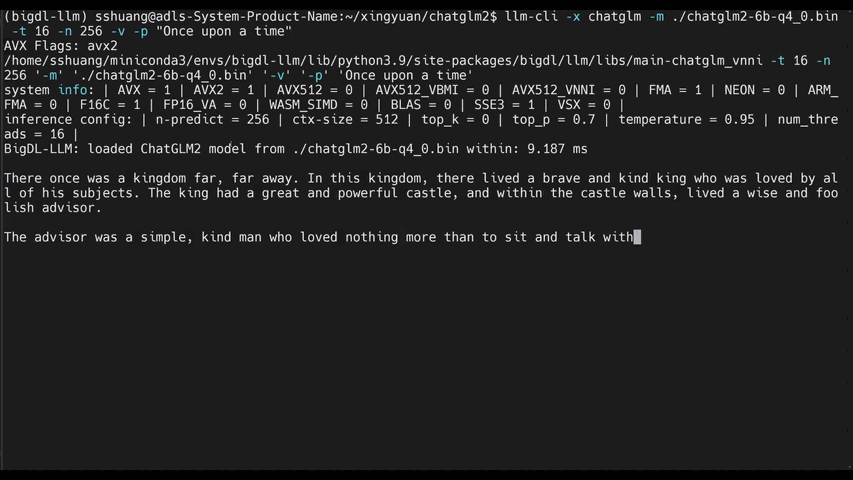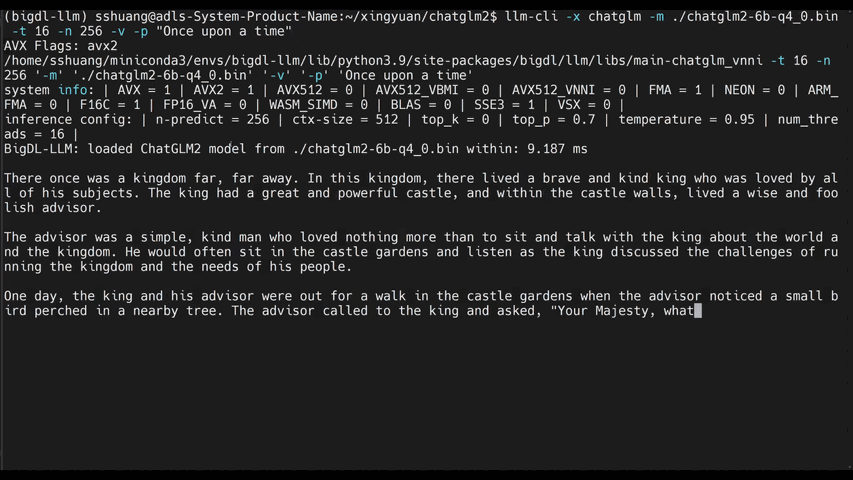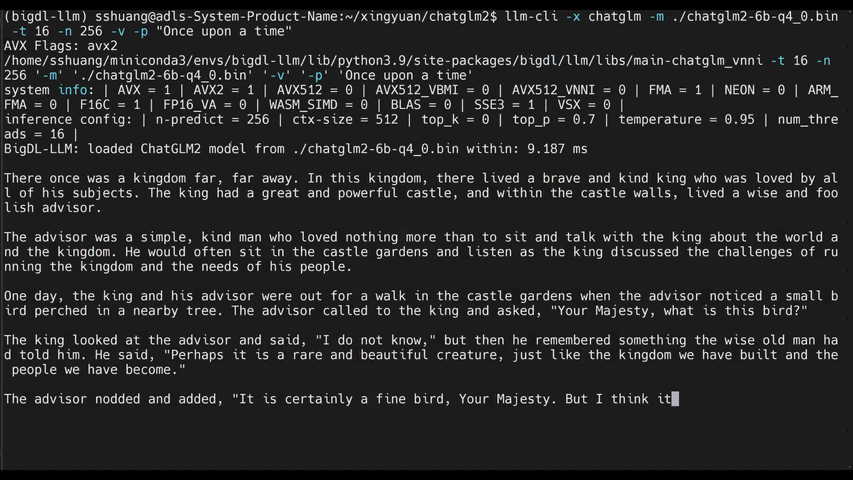
|
|
|
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
ipex-llm on Windows with Intel GPUipex-llm on Linux with Intel GPUipex-llm dockers on Intel CPU and GPUipex-llm as an accelerated backend for llama.cpp on Intel GPU)ipex-llm in vLLM on both Intel GPU and CPUipex-llm in FastChat serving on on both Intel GPU and CPUipex-llm in LangChain-Chatchat (Knowledge Base QA using RAG pipeline)ipex-llm in oobabooga WebUIipex-llm on Intel CPU and GPUipex-llm low-bit modelsipex-llmipex-llmipex-llmFor more details, please refer to the ipex-llm document website.
Over 50 models have been optimized/verified on ipex-llm, including LLaMA/LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM2/ChatGLM3, Baichuan/Baichuan2, Qwen/Qwen-1.5, InternLM and more; see the list below.
| Model | CPU Example | GPU Example |
|---|---|---|
| LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1, link2 | link |
| LLaMA 2 | link1, link2 | link |
| ChatGLM | link | |
| ChatGLM2 | link | link |
| ChatGLM3 | link | link |
| Mistral | link | link |
| Mixtral | link | link |
| Falcon | link | link |
| MPT | link | link |
| Dolly-v1 | link | link |
| Dolly-v2 | link | link |
| Replit Code | link | link |
| RedPajama | link1, link2 | |
| Phoenix | link1, link2 | |
| StarCoder | link1, link2 | link |
| Baichuan | link | link |
| Baichuan2 | link | link |
| InternLM | link | link |
| Qwen | link | link |
| Qwen1.5 | link | link |
| Qwen-VL | link | link |
| Aquila | link | link |
| Aquila2 | link | link |
| MOSS | link | |
| Whisper | link | link |
| Phi-1_5 | link | link |
| Flan-t5 | link | link |
| LLaVA | link | link |
| CodeLlama | link | link |
| Skywork | link | |
| InternLM-XComposer | link | |
| WizardCoder-Python | link | |
| CodeShell | link | |
| Fuyu | link | |
| Distil-Whisper | link | link |
| Yi | link | link |
| BlueLM | link | link |
| Mamba | link | link |
| SOLAR | link | link |
| Phixtral | link | link |
| InternLM2 | link | link |
| RWKV4 | link | |
| RWKV5 | link | |
| Bark | link | link |
| SpeechT5 | link | |
| DeepSeek-MoE | link | |
| Ziya-Coding-34B-v1.0 | link | |
| Phi-2 | link | link |
| Yuan2 | link | link |
| Gemma | link | link |
| DeciLM-7B | link | link |
| Deepseek | link | link |
| StableLM | link | link |
Performance varies by use, configuration and other factors. ipex-llm may not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. ↩