instacart / lore
- пятница, 27 июля 2018 г. в 00:15:58
Python
Lore makes machine learning approachable for Software Engineers and maintainable for Machine Learning Researchers

Lore is a python framework to make machine learning approachable for Engineers and maintainable for Data Scientists.
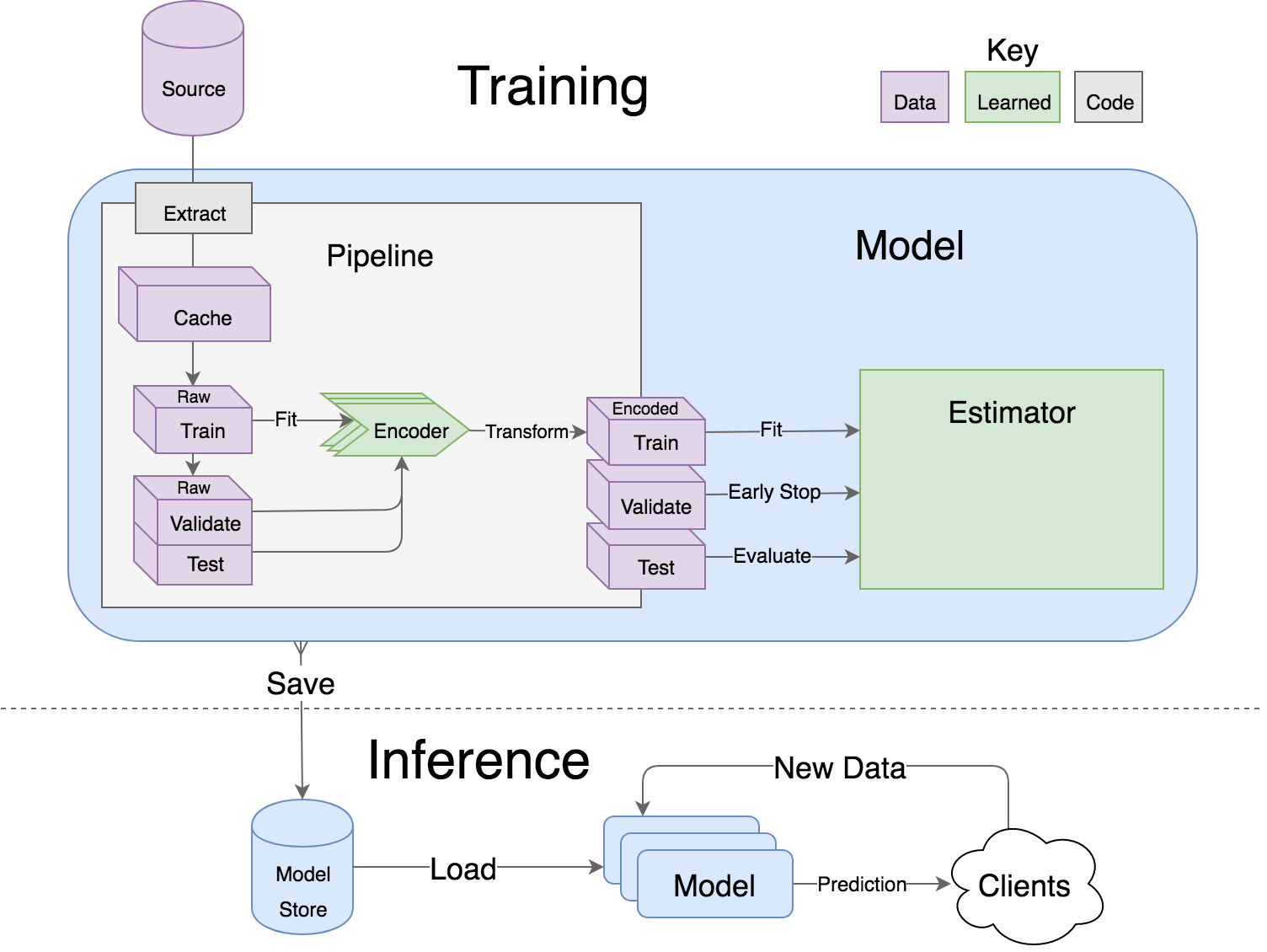
This example demonstrates nested transformers and how to use lore.io with a postgres database users table that has feature first_name and response has_subscription columns. If you don't want to create the database, you can follow a database free example app on medium.
$ pip install lore
$ lore init my_app --python-version=3.6.4 --keras --xgboost --postgres
# fix up .env, config/database.cfg, circle.yml, README.rstWe'll naively try to predict whether users are subscribers, given their first name.
Update config/database.cfg to specify your database url:
# config/database.cfg
[MAIN]
url: $DATABASE_URLyou can set environment variable for only the lore process with the .env file:
# .env
DATABASE_URL=postgres://localhost:5432/developmentCreate a sql file that specifies your data:
-- my_app/extracts/subscribers.sql
SELECT
first_name,
has_subscription
FROM users
LIMIT = %(limit)sPipelines are the unsexy, but essential component of most machine learning applications. They transform raw data into encoded training (and prediction) data for a model. Lore has several features to make data munging more palatable.
# my_app/pipelines/subscribers.py
import lore.io
import lore.pipelines
from lore.encoders import Norm, Discrete, Boolean, Unique
from lore.transformers import NameAge, NameSex, Log
class Holdout(lore.pipelines.holdout.Base):
def get_data(self):
# lore.io.main is a Connection created by config/database.cfg + DATABASE_URL
# dataframe() supports keyword args for interpolation (limit)
# subscribers is the name of the extract
# cache=True enables LRU query caching
return lore.io.main.dataframe(filename='subscribers', limit=100, cache=True)
def get_encoders(self):
# An arbitrairily chosen set of encoders (w/ transformers)
# that reference sql columns in the extract by name.
# A fair bit of thought will probably go into expanding
# your list with features for your model.
return (
Unique('first_name', minimum_occurrences=100),
Norm(Log(NameAge('first_name'))),
Discrete(NameSex('first_name'), bins=10),
)
def get_output_encoder(self):
# A single encoder that references the predicted outcome
return Boolean('has_subscription')The superclass lore.pipelines.base.Holdout will take care of:
Define some models that will fit and predict the data. Base models are designed to be extended and overridden, but work with defaults out of the box.
# my_app/models/subscribers.py
import lore.models.keras
import lore.models.xgboost
import lore.estimators.keras
import lore.estimators.xgboost
from my_app.pipelines.subscribers import Holdout
class DeepName(lore.models.keras.Base):
def __init__(self):
super(DeepName, self).__init__(
pipeline=Holdout(),
estimator=lore.estimators.keras.BinaryClassifier() # a canned estimator for deep learning
)
class BoostedName(lore.models.xgboost.Base):
def __init__(self):
super(BoostedName, self).__init__(
pipeline=Holdout(),
estimator=lore.estimators.xgboost.Base() # a canned estimator for XGBoost
)Test the models predictive power:
# tests/unit/test_subscribers.py
import unittest
from my_app.models.subscribers import DeepName, BoostedName
class TestSubscribers(unittest.TestCase):
def test_deep_name(self):
model = DeepName() # initialize a new model
model.fit(epochs=20) # fit to the pipeline's training_data
predictions = model.predict(model.pipeline.test_data) # predict the holdout
self.assertEqual(list(predictions), list(model.pipeline.encoded_test_data.y)) # hah!
def test_xgboosted_name(self):
model = BoostedName()
model.fit()
predictions = model.predict(model.pipeline.test_data)
self.assertEqual(list(predictions), list(model.pipeline.encoded_test_data.y)) # hah hah hah!Run tests:
$ lore testExperiment and tune notebooks/ with $ lore notebook using the app kernel
├── .env.template <- Template for environment variables for developers (mirrors production)
├── README.md <- The top-level README for developers using this project.
├── requirements.txt <- keeps dev and production in sync (pip)
├── runtime.txt <- keeps dev and production in sync (pyenv)
│
├── data/ <- query cache and other temp data
│
├── docs/ <- generated from src
│
├── logs/ <- log files per environment
│
├── models/ <- local model store from fittings
│
├── notebooks/ <- explorations of data and models
│ └── my_exploration/
│ └── exploration_1.ipynb
│
├── appname/ <- python module for appname
│ ├── __init__.py <- loads the various components (makes this a module)
│ │
│ ├── api/ <- external entry points to runtime models
│ │ └── my_project.py <- hub endpoint for predictions
│ │
│ ├── extracts/ <- sql
│ │ └── my_project.sql
│ │
│ ├── estimators/ <- Code that make predictions
│ │ └── my_project.py <- Keras/XGBoost implementations
│ │
│ ├── models/ <- Combine estimator(s) w/ pipeline(s)
│ │ └── my_project.py
│ │
│ └── pipelines/ <- abstractions for processing data
│ └── my_project.py <- train/test/split data encoding
│
└── tests/
├── data/ <- cached queries for fixture data
├── models/ <- model store for test runs
└── unit/ <- unit tests
Lore provides python modules to standardize Machine Learning techniques across multiple libraries.
Use your favorite library in a lore project, just like you'd use them in any other python project. They'll play nicely together.
There are many ways to manage python dependencies in development and production, and each has it's own pitfalls. Lore codifies a solution that “just works” with lore install, which exactly replicates what will be run in production.
Python 2 & 3 compatibility
Heroku_ buildpack compatibility CircleCI_, Domino_ , isc)
Environment Specific Configuration
logging.getLogger(__name__) is setup appropriately to console, file and/or syslog depending on environmentMultiple concurrent project compatibility
ISC compatibility
Binary library installation for MAXIMUM SPEED
IO
lore.io.connection.Connection.select() and Connection.dataframe() can be automatically LRU cached to diskConnection supports python %(name)s variable replacement in SQLConnection statements are always annotated with metadata for pgHeroConnection is lazy, for fast startup, and avoids bootup errors in development with low connectivityConnection supports multiple concurrent database connectionsSerialization
Caching
Encoders
Transformers
Base Models
Fitting
Keras/Tensorflow
Utils
lore.util.timer context manager writes to the log in development or librato in production*lore.util.timed is a decorator for recording function execution wall time$ lore server # start an api process
$ lore console # launch a console in your virtual env
$ lore notebook # launch jupyter notebook in your virtual env
$ lore fit MODEL # train the model
$ lore generate [scaffold, model, estimator, pipeline, notebook, test] NAME
$ lore init [project] # create file structure
$ lore install # setup dependencies in virtualenv
$ lore test # make sure the project is in working order
$ lore pip # launch pip in your virtual env
$ lore python # launch python in your virtual env