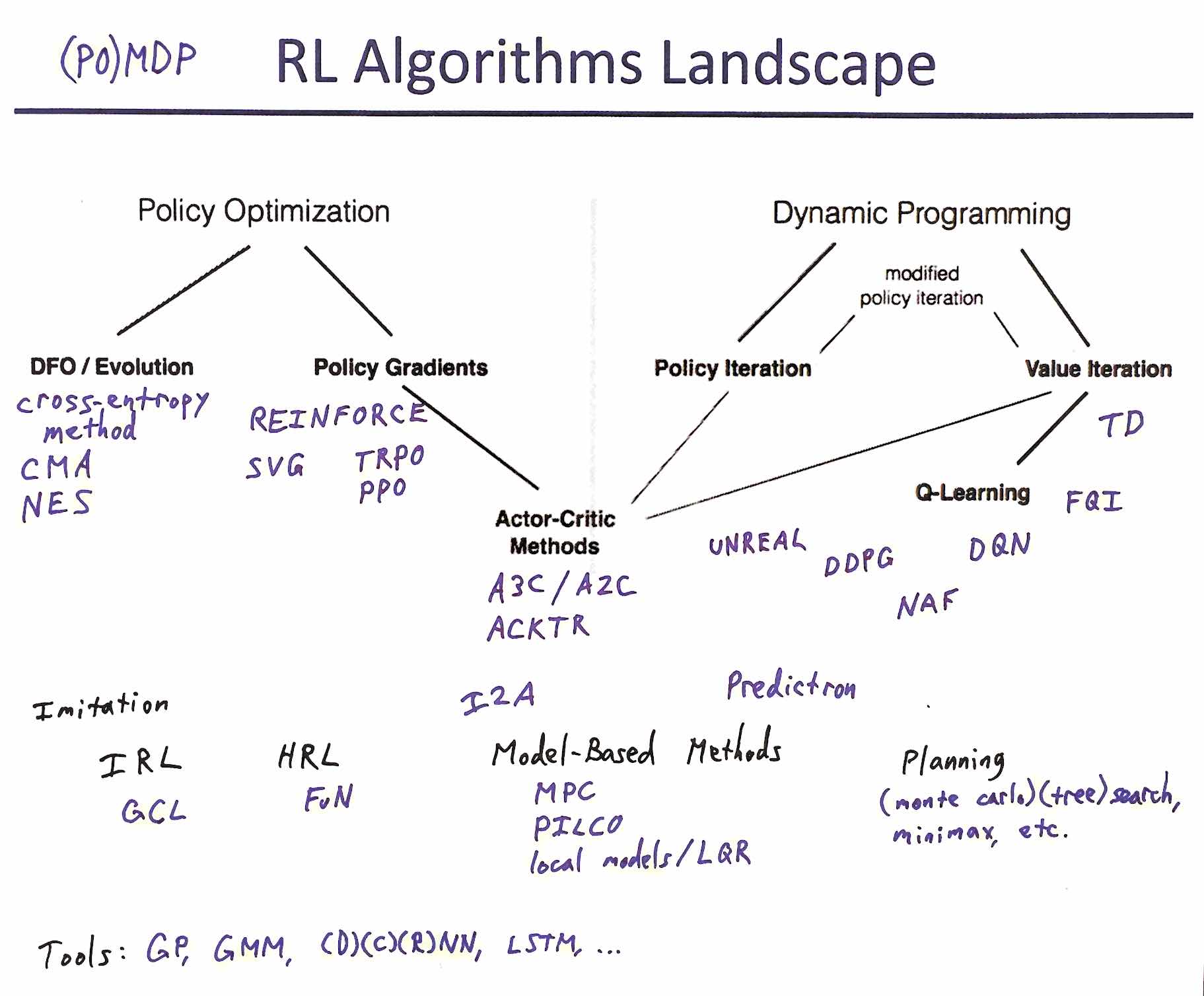
The deep reinforcement learning community has made several improvements to the policy gradient algorithms. This tutorial presents latest extensions in the following order:
Remember you are not stuck unless you have spent more than a week on a single algorithm. It is perfectly normal if you do not have all the required knowledge of mathematics and CS.
Carefully go through the paper. Try to see what is the problem the authors are solving. Understand a high-level idea of the approach, then read the code (skipping the proofs), and after go over the mathematical details and proofs.