What if you could imitate a famous celebrity's voice or sing like a famous singer?
This project started with a goal to convert someone's voice to a specific target voice.
So called, it's voice style transfer.
We worked on this project that aims to convert someone's voice to a famous English actress Kate Winslet's
voice.
We implemented a deep neural networks to achieve that and more than 2 hours of audio book sentences read by Kate Winslet are used as a dataset.
Model Architecture
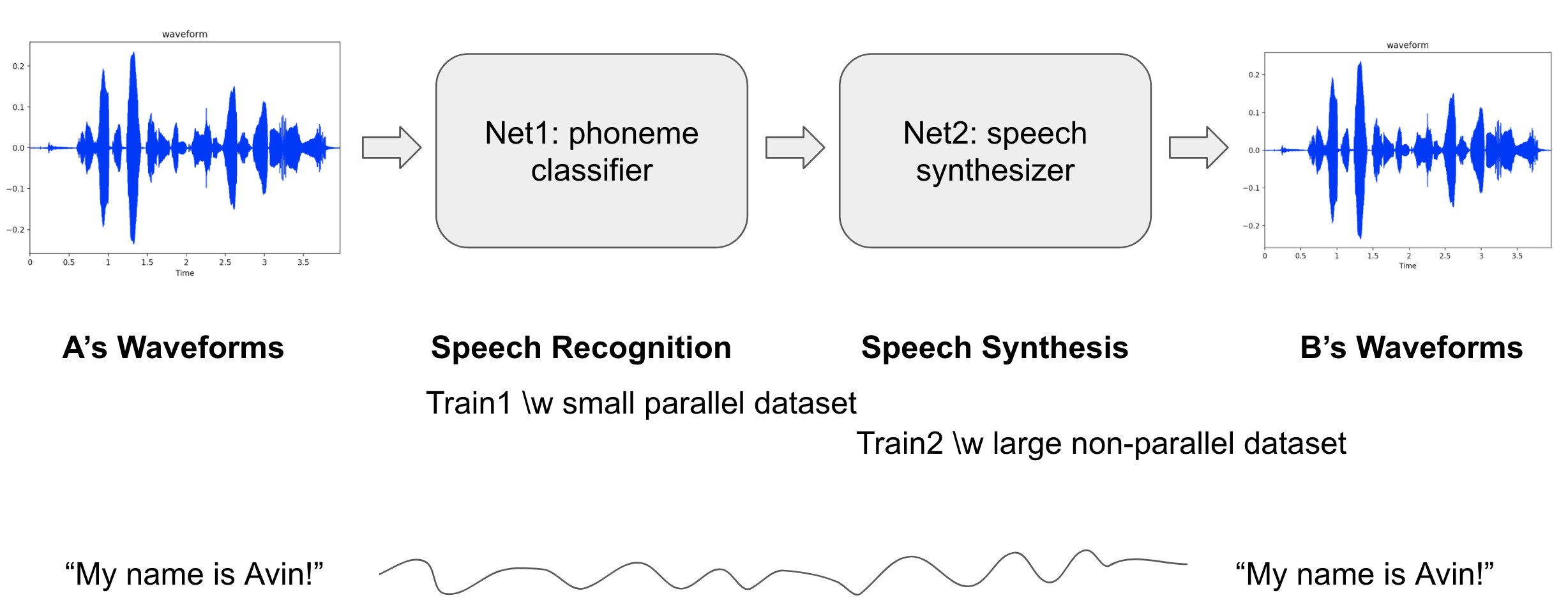
This is a many-to-one voice conversion system.
The main significance of this work is that we could generate a target speaker's utterances without parallel data like <source's wav, target's wav>, <wav, text> or <wav, phone>, but only waveforms of the target speaker.
(To make these parallel datasets needs a lot of effort.)
All we need in this project is a number of waveforms of the target speaker's utterances and only a small set of <wav, phone> pairs from a number of anonymous speakers.
The model architecture consists of two modules:
Net1(phoneme classification) classify someone's utterances to one of phoneme classes at every timestep.
Phonemes are speaker-independent while waveforms are speaker-dependent.
Net2(speech synthesis) synthesize speeches of the target speaker from the phones.
We applied CBHG(1-D convolution bank + highway network + bidirectional GRU) modules that are mentioned in Tacotron.
CBHG is known to be good for capturing features from sequential data.