This part is for dummies who are new to Data Science
This is a shortcut path to start studying Data Science. Just follow the steps to answer the questions, "What is Data Science and what should I study to learn Data Science?"
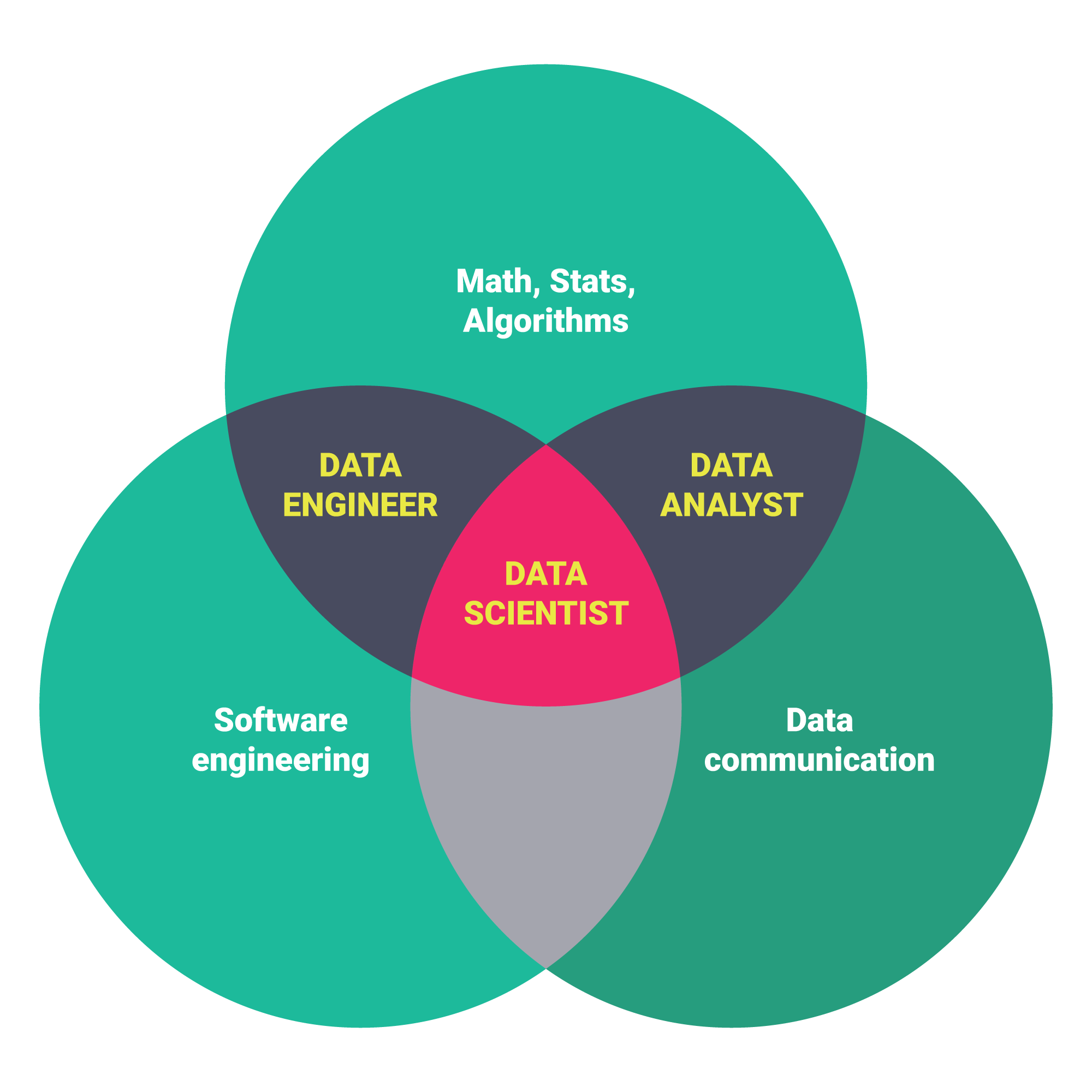
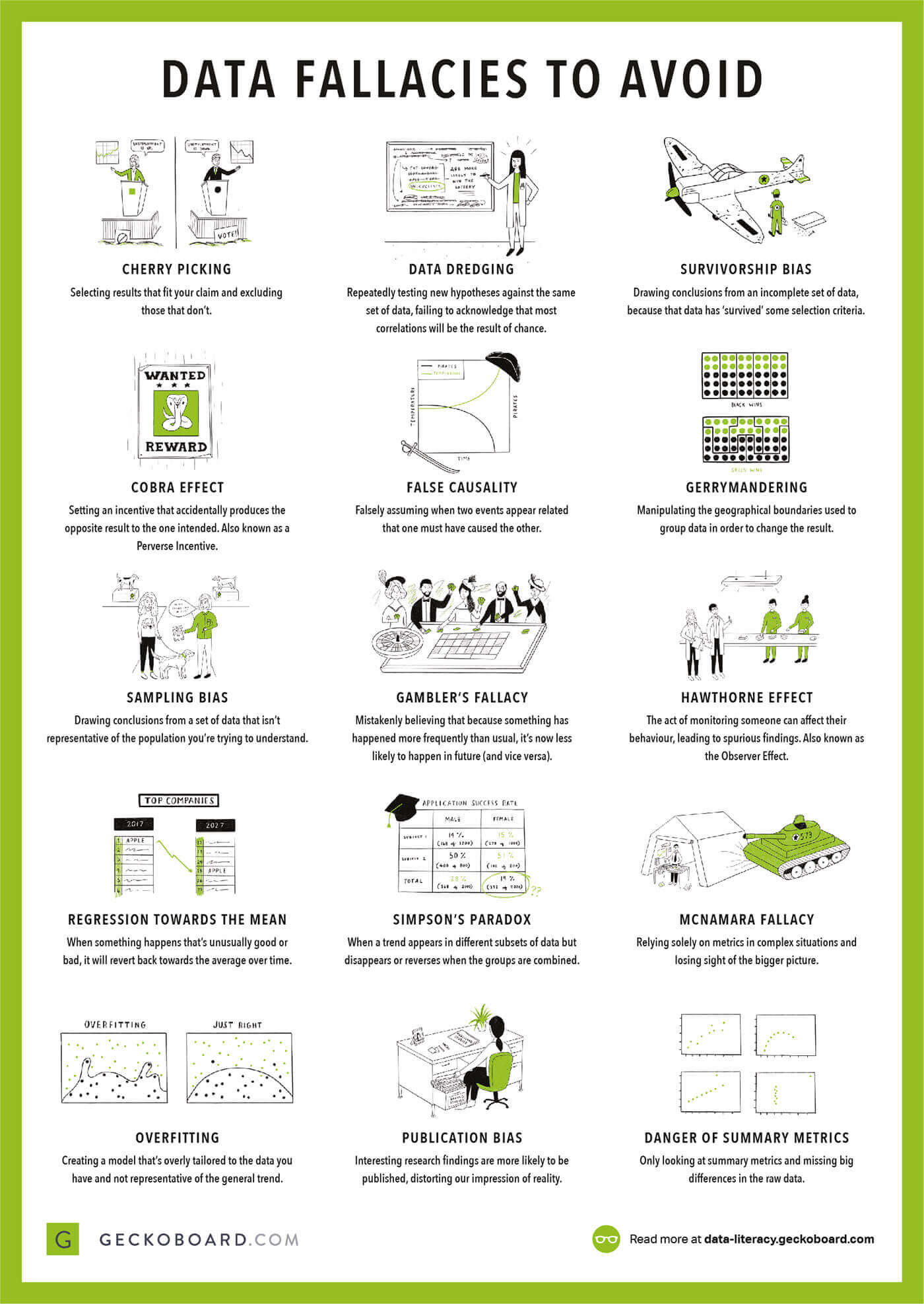
First of all, Data Science is one of the hottest topics on the Computer and Internet farmland nowadays. People have gathered data from applications and systems until today and now is the time to analyze them. The next steps are producing suggestions from the data and creating predictions about the future. Here you can find the biggest question for Data Science and hundreds of answers from experts.
Secondly, Our favorite programming language is Python nowadays for #DataScience. Python's - Pandas library has full functionality for collecting and analyzing data. We use Anaconda to play with data and to create applications.
Infographic
Preview
Description
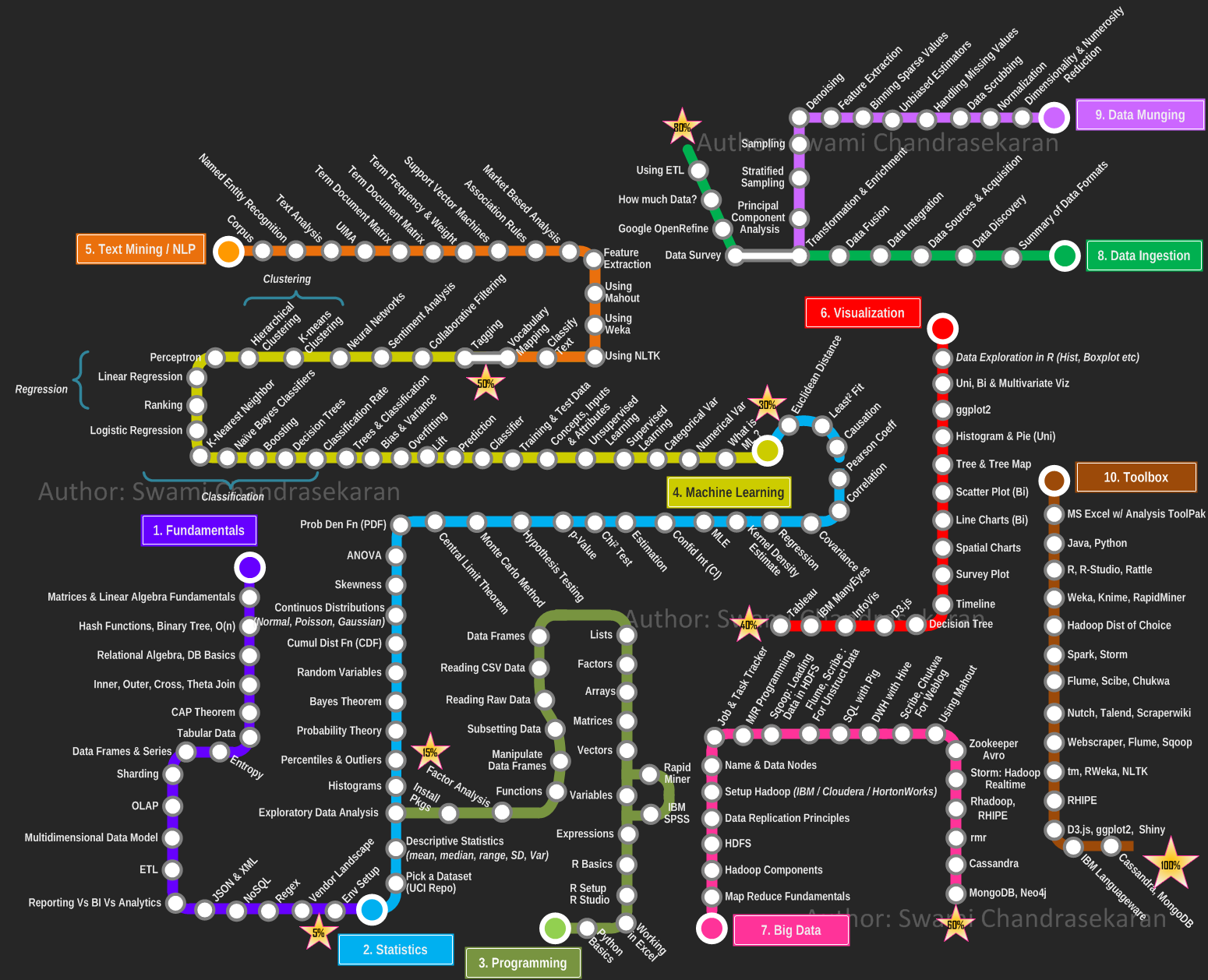
A visual guide to Becoming a Data Scientist in 8 Steps by DataCamp(img)
enigma.com - Navigate the world of public data - Quickly search and analyze billions of public records published by governments, companies and organizations.
Paul Miller Based in the UK and working globally, Cloud of Data's consultancy services help clients understand the implications of taking data and more to the Cloud.
Data Science London Data Science London is a non-profit organization dedicated to the free, open, dissemination of data science.
We are the largest data science community in Europe.
We are more than 3,190 data scientists and data geeks in our community.
Datawrangling by Peter Skomoroch. MACHINE LEARNING, DATA MINING, AND MORE
Data Science Report MDS, Inc. Helps Build Careers in Data Science, Advanced Analytics, Big Data Architecture, and High Performance Software Engineering
Louis Dorard a technology guy with a penchant for the web and for data, big and small
Machine Learning Mastery about helping professional programmers to confidently apply machine learning algorithms to address complex problems.
Micheal Le Gal a data enthusiast who gets hooked on solving intriguing problems and crafting beautiful stories and visualizations with data. Over the past 5 years, He haas applied statistics to solve problems in government, brain sciences, and most recently, retail.
WhatSTheBigData is some of, all of, or much more than the above and this blog explores its impact on information technology, the business world, government agencies, and our lives.
Mic Farris Focusing on science, datascience, business, technology, and channeling inner geekness!
John Myles White Scientist at Facebook and Julia developer. Author of Machine Learning for Hackers and Bandit Algorithms for Website Optimization. Tweets reflect my views only.
Juan Miguel Lavista - Principal Data Scientist @ Microsoft Data Science Team
Luis Rei - PhD Student. Programming, Mobile, Web. Artificial Intelligence, Intelligent Robotics Machine Learning, Data Mining, Natural Language Processing, Data Science.
Mark Stevenson - Data Analytics Recruitment Specialist at Salt (@SaltJobs) | Analytics - Insight - Big Data - Datascience
Matt Harrison - Opinions of full-stack Python guy, author, instructor, currently playing Data Scientist. Occasional fathering, husbanding, ult|goalt-imate, organic gardening.
Mert Nuhoğlu Data Scientist at BizQualify, Developer
Monica Rogati - Data @ Jawbone. Turned data into stories & products at LinkedIn. Text mining, applied machine learning, recommender systems. Ex-gamer, ex-machine coder; namer.
Paul Miller - Cloud Computing/ Big Data/ Open Data Analyst & Consultant. Writer, Speaker & Moderator. Gigaom Research Analyst.
Peter Skomoroch - Creating intelligent systems to automate tasks & improve decisions. Entrepreneur, ex Principal Data Scientist @LinkedIn. Machine Learning, ProductRei, Networks
Prash Chan - Solution Architect @ IBM, Master Data Management, Data Quality & Data Governance Blogger. Data Science, Hadoop, Big Data & Cloud.
Ryan Orban - Data scientist, genetic origamist, hardware aficionado
Sean J. Taylor - Social Scientist. Hacker. Facebook Data Science Team. Keywords: Experiments, Causal Inference, Statistics, Machine Learning, Economics.
WNYC Data News Team - The data news crew at @WNYC. Practicing data-driven journalism, making it visual and showing our work.
@SkymindIO's open-source deep learning for the JVM. Integrates with Hadoop, Spark. Distributed GPU/CPUs | http://nd4j.org | https://www.skymind.ai/
Open Data Science – First Telegram Data Science channel. Covering all technical and popular staff about anything related to Data Science: AI, Big Data, Machine Learning, Statistics, general Math and the applications of former.
Loss function porn — Beautiful posts on DS/ML theme with video or graphic vizualization.
Karate Club - An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API.
ML Workspace - All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code).
neptune.ml -> Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility.
steppy -> Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design.
steppy-toolkit -> Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective.
Datalab from Google easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively.
Hortonworks Sandbox is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials.
R is a free software environment for statistical computing and graphics.
RStudio IDE – powerful user interface for R. It’s free and open source, works onWindows, Mac, and Linux.
Python - Pandas - Anaconda Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing
NumPy NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays.
SciPy SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization.
Wolfram Data Science Platform Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generating rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language.
Sense Data Science Development Platform A New Cloud Platform for Data Science and Big Data Analytics
Collaborate on, scale, and deploy data analysis and advanced analytics projects radically faster. Use the most powerful tools — R, Python, JavaScript, Redshift, Hive, Impala, Hadoop, and more — supercharged and integrated in the cloud.
Datadog Solutions, code, and devops for high-scale data science.
Variance Build powerful data visualizations for the web without writing JavaScript
Kite Development Kit The Kite Software Development Kit (Apache License, Version 2.0), or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem.
Domino Data Labs Run, scale, share, and deploy your models — without any infrastructure or setup.
Apache Flink A platform for efficient, distributed, general-purpose data processing.
Apache Hama Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce.
Weka Weka is a collection of machine learning algorithms for data mining tasks.
Octave GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab)
Julia – high-level, high-performance dynamic programming language for technical computing
IJulia – a Julia-language backend combined with the Jupyter interactive environment
Apache Zeppelin - Web-based notebook that enables data-driven,
interactive data analytics and collaborative documents with SQL, Scala and more
Featuretools - An open source framework for automated feature engineering written in python
Optimus - Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend.
Albumentations - А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops.
DVC - An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files.
Lambdo is a workflow engine which significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation.
Feast - A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving.
Polyaxon - A platform for reproducible and scalable machine learning and deep learning.
Trains - Auto-Magical Experiment Manager, Version Control & DevOps for AI
Hopsworks - Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale.