http://habrahabr.ru/post/252937/
Из этой статьи вы узнаете, что распознавание даже коротких звуковых фрагментов в зашумленной записи — вполне решаемая задача, а прототип так вообще реализуется за 30 строчек кода на Python. Мы увидим, как тут помогает преобразование Фурье, и наглядно посмотрим, как работает алгоритм поиска и сопоставления отпечатков. Статья будет полезна, если вы сами хотите написать подобную систему, или вам интересно, как она может быть устроена.
Для начала зададимся вопросом: кому вообще нужно распознавать рекламу на радио? Это полезно рекламодателям, которые могут отслеживать реальные выходы своих рекламных роликов, ловить случаи обрезки или прерывания; радиостанции могут мониторить выход сетевой рекламы в регионах, и т.п. Та же задача распознавания возникает, если мы хотим отследить проигрывание музыкального произведения (что очень любят правообладатели), или по небольшому фрагменту узнать песню (как делают Shazam и другие подобные сервисы).
Более строго задача формулируется так: у нас есть некоторый набор эталонных аудио-фрагментов (песен или рекламных роликов), и есть аудио-запись эфира, в котором предположительно звучат какие-то из этих фрагментов. Задача — найти все прозвучавшие фрагменты, определить моменты начала и длительность проигрывания. Если мы анализируем записи эфира, то нужно чтобы система в целом работала быстрее реального времени.
Как это работает
Все знают что звук (в узком смысле) — это волны сжатий и разрежений, распространяющиеся в воздухе. Запись звука, например в wav-файле, представляет собой последовательность значений амплитуды (физически она соответствует степени сжатия, или давлению). Если вы открывали аудио-редактор, то наверняка видели визуализацию этих данных — график зависимости амплитуды от времени (длительность фрагмента 0.025 с):
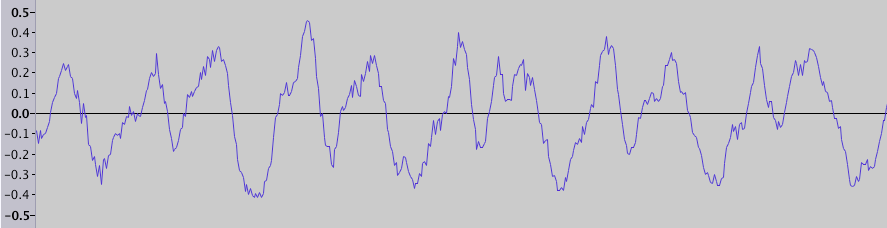
Но мы не воспринимаем эти колебания частоты непосредственно, а слышим звуки разной частоты и тембра. Поэтому часто используется другой способ визуализации звука —
спектрограмма, где на горизонтальной оси представлено время, на вертикальной — частота, а цвет точки обозначает амплитуду. Например, вот спектрограмма звучания скрипки, охватывающая по времени несколько секунд:
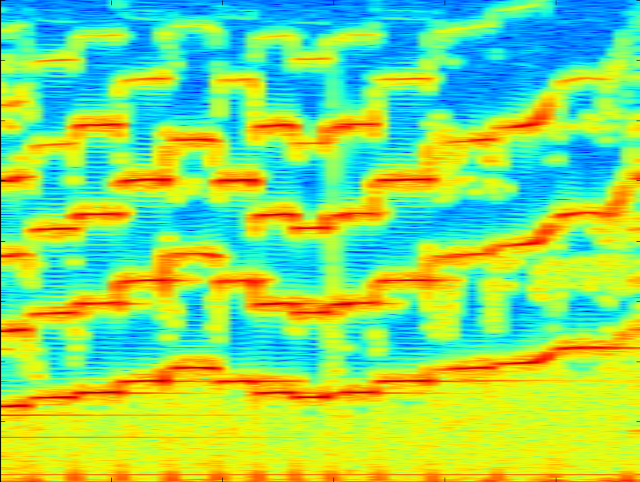
На ней видны отдельные ноты и их гармоники, а также шумы — вертикальные полосы, охватывающие весь диапазон частот.
Построить такую спектрограмму при помощи Python можно так:Для загрузки данных из wav файла можно использовать библиотеку
SciPy, а для построения спектрограммы использовать
matplotlib. Все примеры даны для версии Python 2.7, но вероятно должны работать и для 3-ей версии. Предполагаем что в file.wav содержится запись звука с частотой дискретизации 8000 Гц:
import numpy
from matplotlib import pyplot, mlab
import scipy.io.wavfile
from collections import defaultdict
SAMPLE_RATE = 8000 # Hz
WINDOW_SIZE = 2048 # размер окна, в котором делается fft
WINDOW_STEP = 512 # шаг окна
def get_wave_data(wave_filename):
sample_rate, wave_data = scipy.io.wavfile.read(wave_filename)
assert sample_rate == SAMPLE_RATE, sample_rate
if isinstance(wave_data[0], numpy.ndarray): # стерео
wave_data = wave_data.mean(1)
return wave_data
def show_specgram(wave_data):
fig = pyplot.figure()
ax = fig.add_axes((0.1, 0.1, 0.8, 0.8))
ax.specgram(wave_data,
NFFT=WINDOW_SIZE, noverlap=WINDOW_SIZE - WINDOW_STEP, Fs=SAMPLE_RATE)
pyplot.show()
wave_data = get_wave_data('file.wav')
show_specgram(wave_data)
Задачу поиска фрагмента в эфире можно разбить на две части: сначала найти среди большого числа эталонных фрагментов кандидаты, а затем проверить, действительно ли кандидат звучит в данном фрагменте эфира, и если да, то в какой момент начинается и заканчивается звучание. Обе операции используют для своей работы «отпечаток» фрагмента звучания. Он должен быть устойчивым к шумам и быть достаточно компактным. Этот отпечаток строится так: мы разбиваем спектрограмму на короткие отрезки по времени, и в каждом таком отрезке ищем частоту с максимальной амплитудой (на самом деле лучше искать несколько максимумов в различных диапазонах, но для простоты возьмем один максимум в наиболее содержательном диапазоне). Набор таких частот (или индексов частот) и представляет собой отпечаток. Очень грубо можно сказать, что это «ноты», звучащие в каждый момент времени.
Вот как получить отпечаток звукового фрагментаdef get_fingerprint(wave_data):
# pxx[freq_idx][t] - мощность сигнала
pxx, _, _ = mlab.specgram(wave_data,
NFFT=WINDOW_SIZE, noverlap=WINDOW_OVERLAP, Fs=SAMPLE_RATE)
band = pxx[15:250] # наиболее интересные частоты от 60 до 1000 Hz
return numpy.argmax(band.transpose(), 1) # max в каждый момент времени
print get_fingerprint(wave_data)
Мы можем получить отпечаток фрагмента эфира и всех эталонных фрагментов, и нам останется только научиться быстро искать кандидаты и сравнивать фрагменты. Сначала посмотрим на задачу сравнения. Понятно что отпечатки никогда не совпадут в точности из-за шумов и искажений. Но оказывается что таким огрубленные таким образом частоты достаточно хорошо переживают все искажения (частоты почти никогда не «плывут»), и достаточно большой процент частот совпадает в точности — таким образом, нам остается только найти сдвиг при котором среди двух последовательностей частот много совпадений. Простой способ визуализировать этот — сначала найти все пары точек, совпавших по частоте, а потом построить гистограмму разниц во времени между совпавшими точками. Если два фрагмента имеют общий участок, то на гистограмме будет ярко выраженный пик (а положение пика говорит о времени начала совпавшего фрагмента):
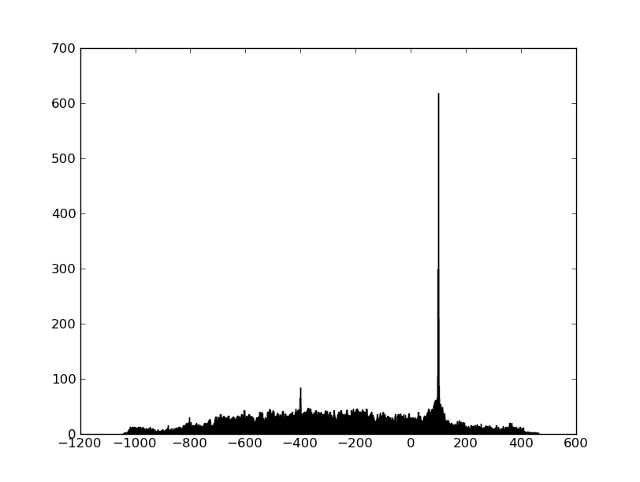
Если два фрагмента никак не связаны, то никакого пика не будет:
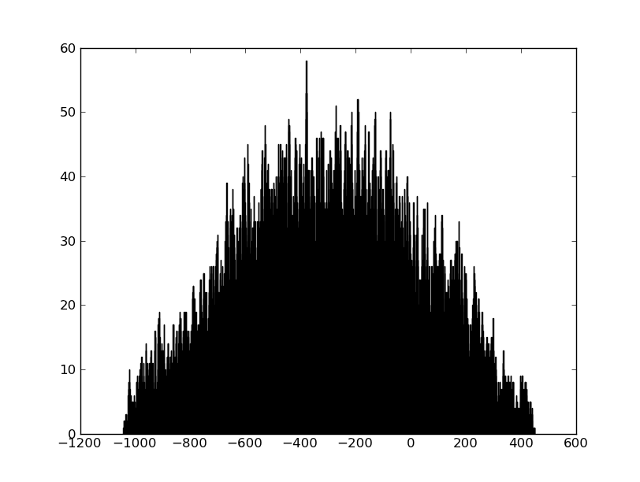
Построить такую замечательную гистограмму можно так:def compare_fingerprints(base_fp, fp):
base_fp_hash = defaultdict(list)
for time_index, freq_index in enumerate(base_fp):
base_fp_hash[freq_index].append(time_index)
matches = [t - time_index # разницы времен совпавших частот
for time_index, freq_index in enumerate(fp)
for t in base_fp_hash[freq_index]]
pyplot.clf()
pyplot.hist(matches, 1000)
pyplot.show()
Файлы, на которых можно потренироваться в распознавании, лежат
тут.
Проблема поиска кандидатов обычно решается с использованием хэширования — по отпечатку фрагмента строится больше число хэшей, как правило это несколько значений из отпечатка идущие подряд или на некотором расстоянии. Различные подходы можно посмотреть по ссылкам в конце статьи. В нашем случае количество эталонных фрагментов было порядка сотни, и можно было вообще обойтись без этапа отбора кандидатов.
Результаты
На тех записях, что были у нас,
F-score составил 98.5%, а точность определения начала — около 1 с. Как и ожидалось, большая часть ошибок была на коротких (4-5 с) роликах. Но основной вывод лично для меня — что в таких задачах решение, написанное самостоятельно, часто работает лучше чем уже готовое (например из EchoPrint, про который уже
писали на хабре, получалось выжать не более 50-70% из-за коротких роликов) просто потому, что у всех задач и данных есть своя специфика, и когда в алгоритме много вариаций и большой произвол по выбору параметров, то понимание всех этапов работы и визуализация на реальных данных очень способствует хорошему результату.
Fun facts:- На спектрограмме одного из треков группы Aphex Twin есть человеческое лицо
- Автор статьи, который воспроизвел алгоритм Shazam на Java, получил от их юристов письма с угрозами
Литература:



