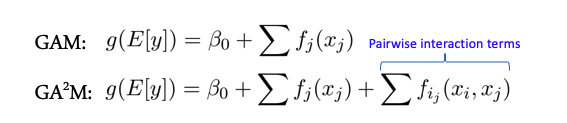https://habr.com/ru/company/ruvds/blog/517830/- Блог компании RUVDS.com
- Python
- Data Mining
- Big Data
- Data Engineering
Мы снова в эфире и продолжаем цикл заметок Дата Сайентиста и сегодня представляю мой абсолютно субъективный чек-лист по выбору модели машинного обучения.
Это топ-10 свойств задачи и просто пунктов (без порядка в них), с точки зрения которых я начинаю выбор модели и вообще моделирование задачи по анализу данных.
Совсем не обязательно, что у вас он будет таким же — здесь все субъективно, но делюсь опытом из жизни.
А какая у нас вообще цель? Интерпретируемость и точность — спектр
 Источник
Источник
Пожалуй самый важный вопрос, который стоит перед дата сайентист перед тем, как начать моделирование это:
В чем, собственно, состоит бизнес задача?
Или исследовательская, если речь об академии, etc.
Например, нам нужна аналитика на основе модели данных или наоборот нас только интересуют качественные предсказания вероятности того, что письмо — это спам.
Классический баланс, который я видел, это как раз спектр между интерпретируемостью метода и его точностью (как на графике выше).
Но по сути нужно не просто прогнать Catboost / Xgboost / Random Forest и выбрать модельку, а понять, что хочет бизнес, какие у нас есть данные и как это будет применяться.
На моей практике — это сразу будет задавать точку на спектре интерпретируемости и точности (чтобы это не значило здесь). А исходя из этого уже можно думать о методах моделирования задачи.
Тип самой задачи
Дальше, после того как мы поняли, что хочет бизнес — нам нужно понять к какому математическому типу задач машинного обучения относится наша, например
- Exploratory analysis — чистая аналитика имеющихся данных и тыканье палочкой
- Clustering — собрать данные в группы по какой-тому общему признаку(ам)
- Regression — нужно вернуть целочисленный результат или там вероятность события
- Classification — нужно вернуть одну метку класса
- Multi-label — нужно вернуть одну или более меток класса для каждой записи
Примеры
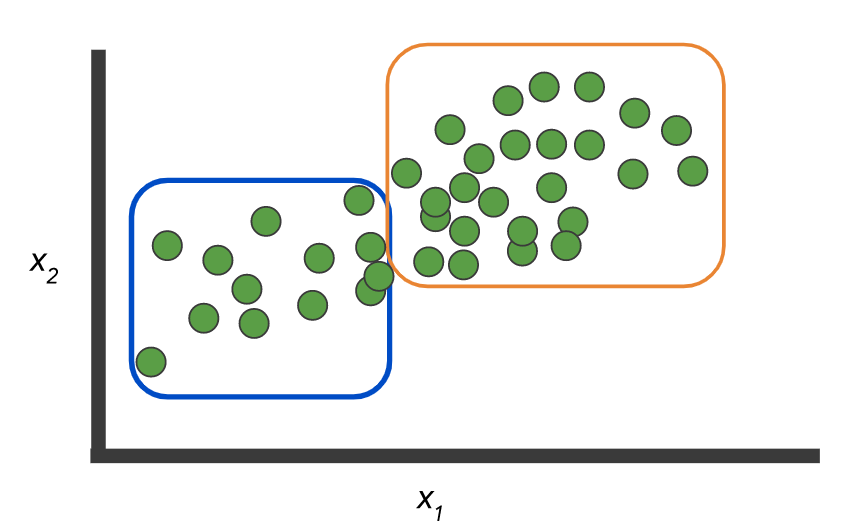
Данные: имеются два класса и набор записей без меток:
И нужно построить модель, которая разметит эти самые данные:
Или как вариант никаких меток нет и нужно выделить группы:
Как например вот здесь:
Картинки
отсюда.
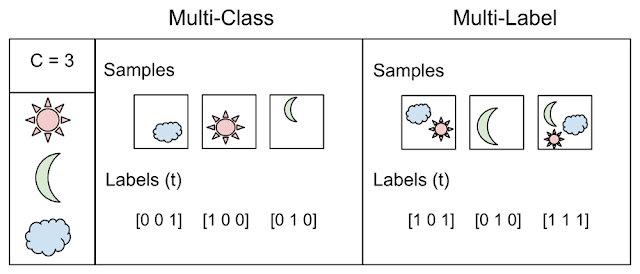
А вот собственно пример иллюстрирует разницу между двумя понятиями: классификация, когда N > 2 классов — multi class vs. multi label
Взято
отсюда
Вы удивитесь, но очень часто этот пункт тоже стоит напрямую проговорить с бизнесом — это может сэкономить вам действительно много сил и времени. Не стесняйтесь рисовать картинки и давать простые примеры (но не слишком упрощенные).
Точность и как она определена
Начну с простого примера, если вы банк и выдаете кредит, то на неудачном кредите мы теряем в пять раз больше, чем получаем на удачном.
Поэтому вопрос об измерении качества работы первичен! Или представьте, что у вас присутствует существенный дисбаланс в данных, класс А = 10%, а class B = 90%, тогда классификатор, который просто возвращает B всегда умеет 90% точность! Скорее всего это не то, чтобы хотели увидеть, обучая модель.
Поэтому критично определить метрику оценки модели включая:
- weight class — как в примере выше, вес плохого кредита 5, а хорошего 1
- cost matrix — возможно перепутать low и medium risk — это не беда, а вот low risk и high risk — уже проблема
- Должна ли метрика отражать баланс? как например ROC AUC
- А мы вообще считаем вероятности или прям метки классов?
- А может быть класс вообще «один» и у нас precision/recall и другие правила игры?
В целом выбор метрики обусловлен задачей и ее формулировкой — и именно у тех, кто ставит эту задачу (обычно бизнес-люди) и надо выяснять и уточнять все эти детали, иначе на выходе будет швах.
Model post analysis
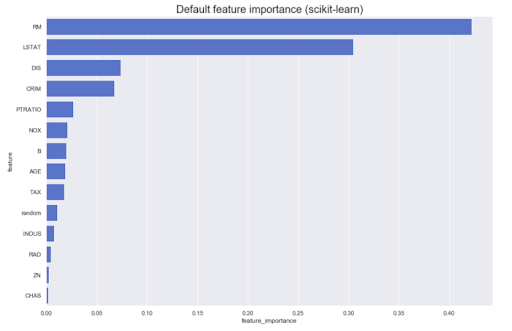
Часто приходится проводить аналитику на основе самой модели. Например, какой вклад имеют разные признаки в исходный результат: как правило, большинство методов могут выдать что-то похожее на вот это:
Однако, что если нам нужно знать направление — большие значения признака A увеличивают принадлежность классу Z или наоборот? Назовем их направленные feature importance — их можно получить у некоторых моделей, например, линейных (через коэффициенты на нормированных данных)
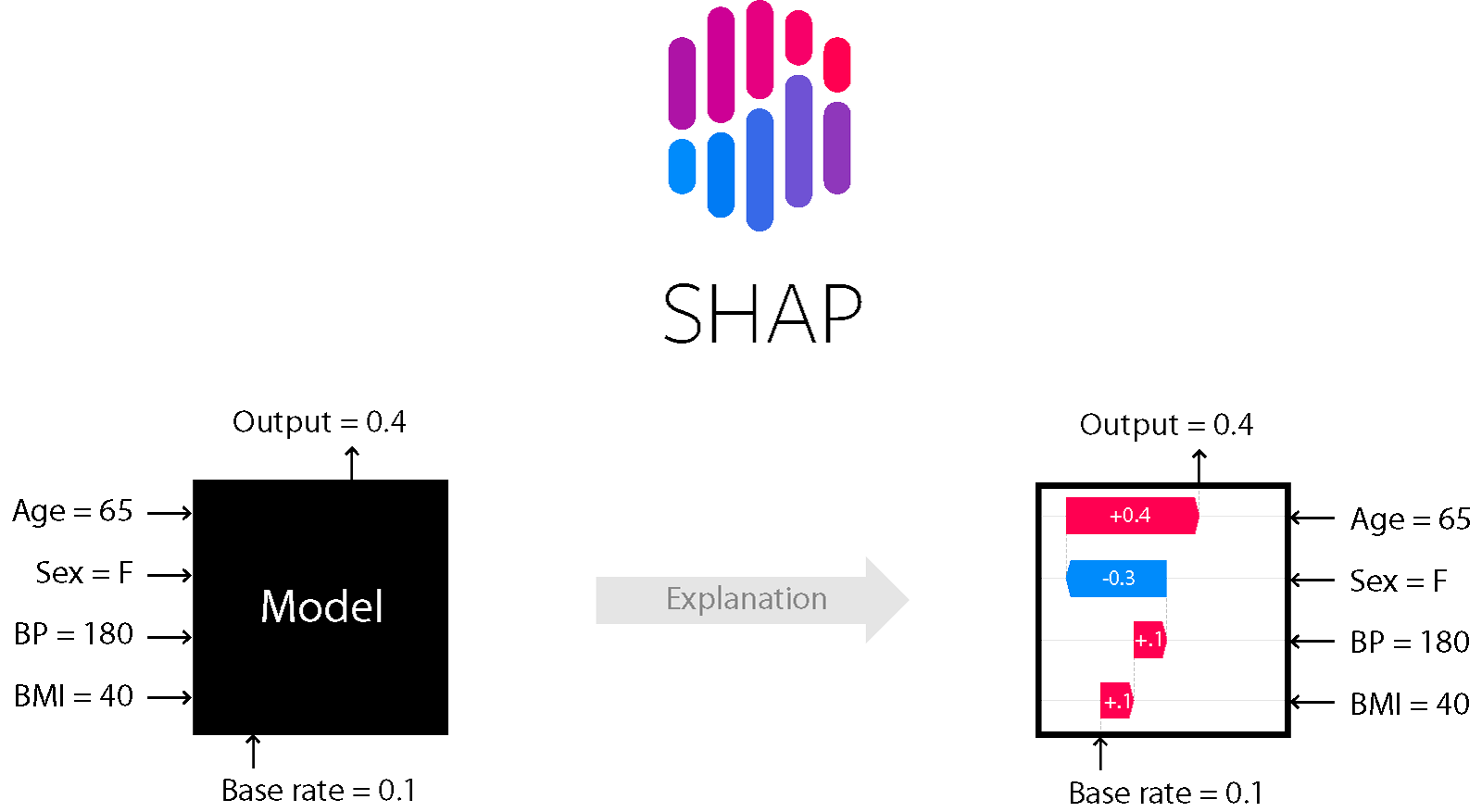
Для ряда моделей, основанных на деревьях и бустинге — например, подходит метод SHapley Additive exPlanations.
SHAP
Это один из методов анализа модели, который позволяет заглянуть «под капот» модели.
Он позволяет оценить направление эффекта:
Причем для деревьев (и методах на них основанных) он точный. Подробнее об этом
тут.
Noise level — устойчивость, линейная зависимость, outlier detection и тд
Устойчивость к шуму и все эти радости жизни — это отдельная тема и нужно крайне внимательно анализировать уровень шума, а также подбирать соответствующие методы. Если вы уверены, что в данных будут выбросы — нужно их обязательно качественно чистить и применять методы устойчивые к шуму (высокий bias, регуляризация и тд).
Также признаки могут быть коллинеарны и присутствовать бессмысленные признаки — разные модели по-разному на это реагируют. Приведем пример на классическом датасете German Credit Data (UCI) и трех простых (относительно) моделях обучения:
- Ridge regression classifier: классическая регрессия с регуляризатором Тихонова
- Decition trees
- CatBoost от Яндекса
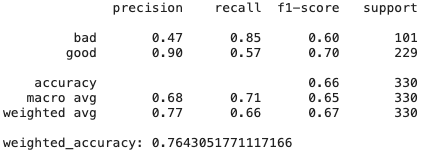
Ridge regression
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Decision Trees
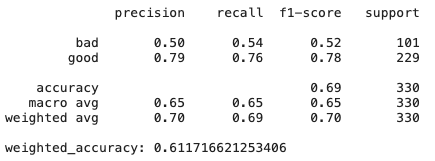
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost
# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))

Как мы видим просто модель гребневой регрессии, которая имеет высокий bias и регуляризацию, показывает результаты даже лучше, чем CatBoost — тут много признаков не слишком полезных и коллинеарных, поэтому методы, которые к ним устойчивы показывают хорошие результаты.
Еще про DT — а если чуть чуть поменять датасет? Feature importance может поменяться, так как decision trees вообще чувствительные методы, даже к перемешиванию данных.
Вывод: иногда проще — лучше и эффективнее.
Масштабируемость
Действительно ли вам нужен Spark или нейросети с миллиардами параметров?
Во-первых, нужно здраво оценивать объем данных, уже неоднократно доводилось наблюдать массовое использование спарка на задачах, которые легко умещаются в память одной машины.
Спарк усложняет отладку, добавляет overhead и усложняет разработку — не стоит его применять там, где не нужно.
Классика.
Во-вторых, нужно конечно же оценивать сложность модели и соотносить ее с задачей. Если ваши конкуренты показывают отличные результаты и у них бегает RandomForest, возможно стоит дважды подумать нужна ли вам нейросеть на миллиарды параметров.
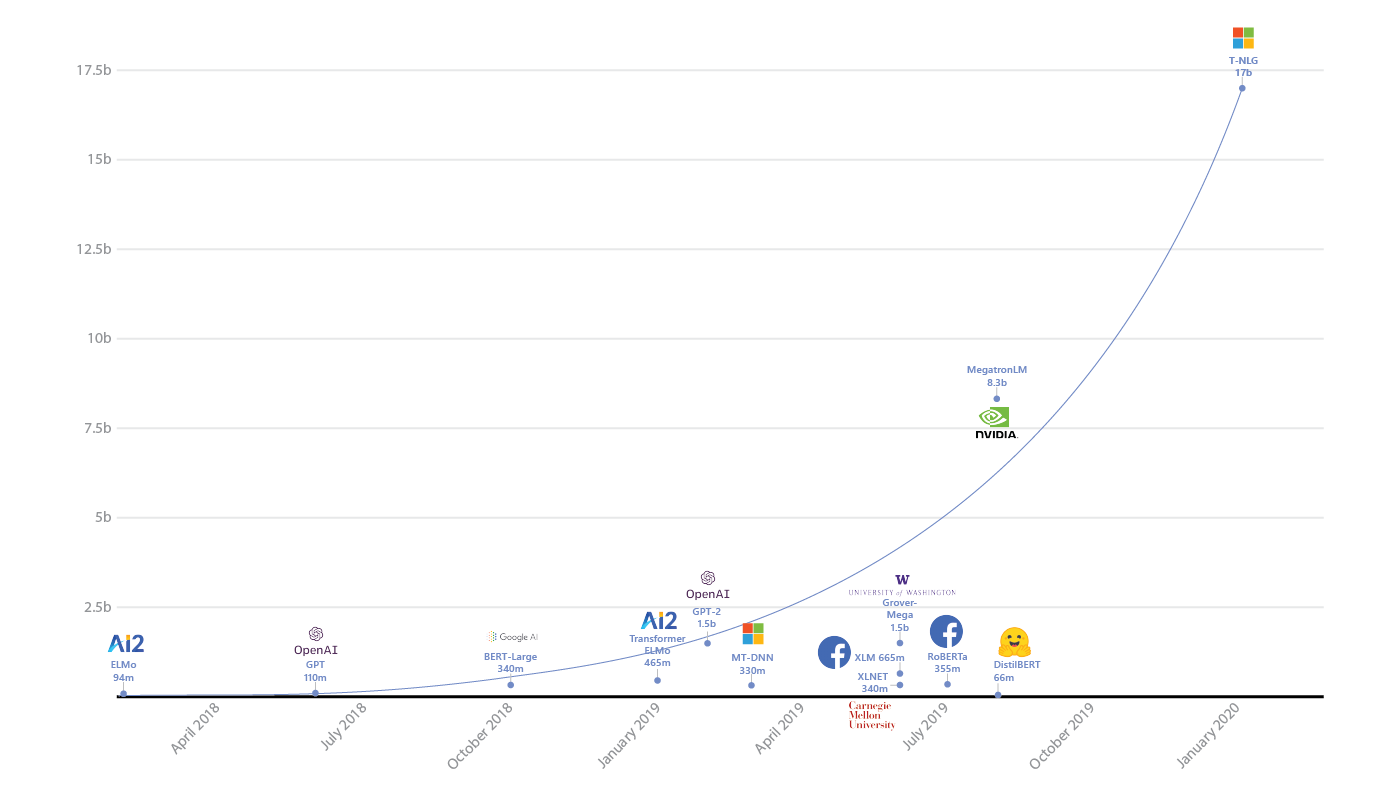
И конечно же необходимо учитывать, что если у вас и правда крупные данные, то модель должна быть способной работать на них — как обучаться по батчам, либо иметь какие-то механизмы распределенного обучения (и тд). А там же не слишком терять в скорости при увеличении объема данных. Например, мы знаем, что kernel methods требуют квадрата памяти для вычислений в dual space — если вы ожидаете увеличение размера данных в 10 раз, то стоит дважды подумать, а умещаетесь ли вы в имеющиеся ресурсы.
Наличие готовых моделей
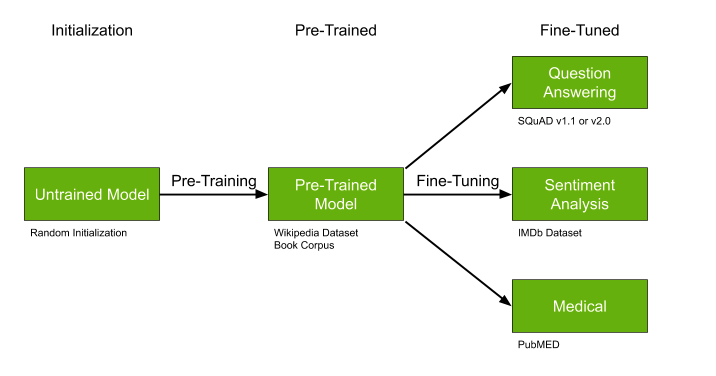
Еще одна важнейшая деталь — это поиск уже натренированных моделей, которые можно до-обучить, идеально подходит, если:
- Данных не очень много, но они очень специфичны для нашей задачи — например, медицинские тексты.
- Тема в целом относительно популярна — например, выделением тем текста — много работ в NLP.
- Ваш подход допускает в принципе до-обучение — как например с некоторым типом нейросетей.
Pre-trained модели как GPT-2 и BERT могут существенно упростить решение вашей задачи и если уже натренированные модели существуют — крайне рекомендую не проходит мимо и использовать этот шанс.
Feature interactions и линейные модели
Некоторые модели лучше работают, когда между признаками (features) нет сложных взаимодействий — например весь класс линейных моделей — Generalized Additive Models. Есть расширение этих моделей на случай взаимодействия двух признаков под название GA2M — Generalized Additive Models with Pairwise Interactions.
Как правило такие модели показывают хорошие результаты на таких данных, отлично регуляризируются, интерпретируемые и устойчивы к шуму. Поэтому однозначно стоит обратить на них внимание.
Однако, если признаки активно взаимодействуют группами больше 2, то данные методы уже не показывают таких хороших результатов.
Package and model support
Многие крутые алгоритмы и модели из статей бывают оформлены в виде модуля или пакета для python, R и тд. Стоит реально дважды подумать, прежде чем использовать и в долгосрочной перспективе полагаться на такое решение (это я говорю, как человек написавший немало статей по ML с таким кодом). Вероятность того, что через год будет нулевая поддержка — очень высок, ибо автору скорее всего сейчас необходимо заниматься другими проектами нет времени, и никаких incentives вкладываться в развитие модуля или репозитория.
В этом плане библиотеки а-ля scikit learn хороши именно тем, что у них фактически есть гарантированная группа энтузиастов вокруг и если что-то будет серьезно поломано — это рано или поздно пофиксят.
Biases and Fairness
Вместе с автоматическими принятиями решений к нам в жизнь приходят люди недовольные такими решениями — представьте, что у нас есть какая-то система ранжирования заявок на стипендию или грант исследователя в универе. Универ у нас будет необычный — в нем только две группы студентов: историки и математики. Если вдруг система на основе своих данных и логики вдруг раздала все гранты историкам и ни одному математику их не присудила — это может неслабо так обидеть математиков. Они назовут такую систему предвзятой. Сейчас об это только ленивый не говорит, а компании и люди судятся между собой.
Условно, представьте упрощенную модель, которая просто считает цитирования статей и пусть историки друг друга цитируют активно — среднее 100 цитат, а математики нет, у них среднее 20 — и пишут вообще мало, тогда система распознает всех историков, как «хороших» ибо цитируемость высокая 100 > 60 (среднее), а математиков, как «плохих» потому что у них у всех цитируемость куда ниже среднего 20 < 60. Такая система вряд ли может показаться кому-то адекватной.
Классика сейчас предъявить логику принятия решения и тренировки моделей, которые борются с таким предвзятым подходом. Таким образом, для каждого решения у вас есть объяснение (условно) почему оно было принято и как вы собственно приложили усилия к тому, чтобы модель не сделала фигню (ELI5 GDPR).

Подробнее у гугла
тут, или вот в статье
тут.
В целом многие компании начали подобную деятельность особенно в свете выхода GDPR — подобные меры и проверки могут позволить избежать проблем в дальнейшем.
Если какая-то тема заинтересовала больше остальных — пишите в комментарии, будем идти в глубину. (DFS)!