Выделение памяти в Go
- четверг, 5 марта 2026 г. в 00:00:09
Эта статья посвящена языку программирования Go 1.24, работающему на Linux на архитектуре ARM. Она может не охватывать специфические для других операционных систем (ОС) или аппаратных архитектур детали.
В этой статье подробно рассматриваются следующие вопросы:
Выделение памяти (memory allocation) — это сердце любой среды выполнения языка программирования, и Go не исключение. Эффективное выделение и управление памятью напрямую влияет на производительность, масштабируемость и отзывчивость Go-приложений. Хотя Go абстрагирует большую часть связанной с этим сложности через простые API (new(T), &T{} и make), понимание того, что происходит под капотом, дает ценные знания о том, как среда выполнения достигает эффективности и где могут возникнуть узкие места производительности.
В этой статье мы подробно изучим распределитель памяти (allocator) Go. Мы рассмотрим его ключевые компоненты, то, как они взаимодействуют между собой для обработки выделений памяти разных размеров, и то, как работает стек (stack) и куча (heap). Также мы рассмотрим некоторые примеры реализаций стратегий выделения памяти. К концу статьи у вас будет четкое понимание того, как Go абстрагирует выделение памяти, обеспечивая высокую производительность приложений.
Перед погружением в тему статьи, важно разобраться с некоторыми фундаментальными концепциями о том, как работает память в типичной ОС. Рекомендую сначала прочитать статью «Основы виртуальной памяти». Если вы уже знакомы с этими концепциями, можете не читать. Теперь перейдем к отображению виртуальной памяти Go.
Процесс Go — это просто приложение пользовательского пространства, следующее стандартной структуре виртуальной памяти, описанной в указанной выше статье. В частности, сегмент Stack процесса - это стек g0 (так называемый системный стек), связанный с основным потоком (thread) m0 среды выполнения Go. Инициализированные (т.е. имеющие ненулевое значение) глобальные переменные хранятся в сегменте Data, а неинициализированные — в сегменте BSS.
Традиционный сегмент Heap, находящийся под прерывателем программы (program break), не используется средой выполнения для выделения объектов кучи. Вместо этого, среда выполнения использует сегменты, отображаемые в память (memory-mapped segments) для выделения памяти для объектов кучи и стеков горутин (goroutines). Далее я буду ссылаться на эти сегменты как на кучу (не путайте ее с традиционной кучей под прерывателем программы).
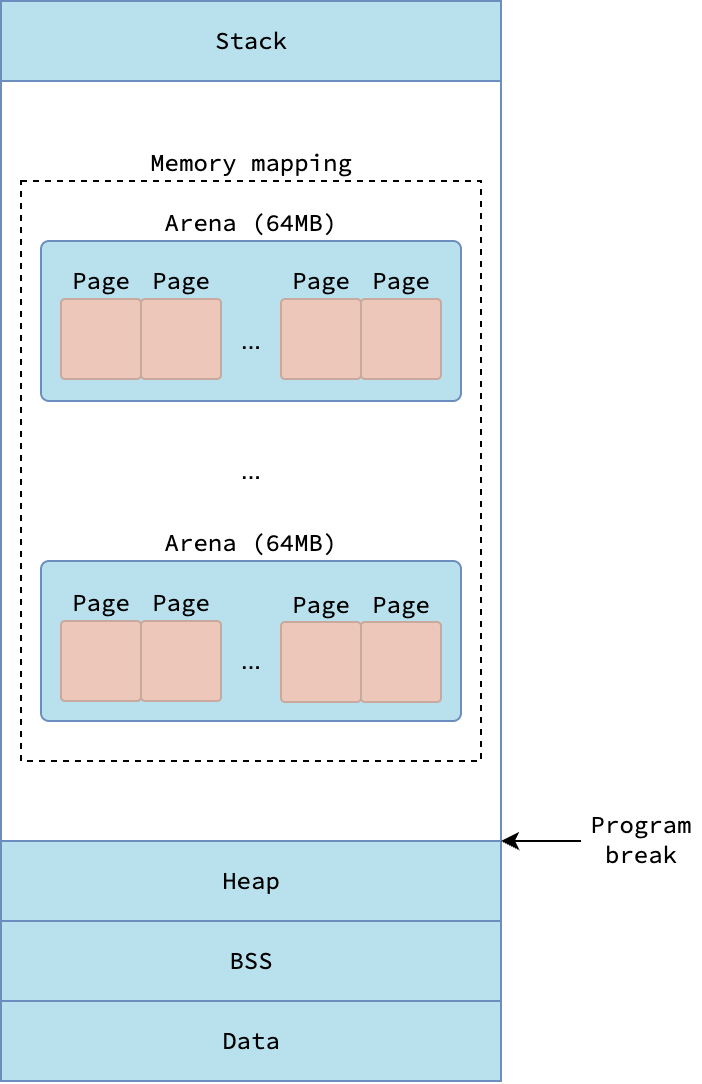
Структура виртуальной памяти с точки зрения среды выполнения Go
Для эффективного управления памятью среда выполнения делит эти сегменты, отображаемые в память, на иерархические единицы от крупнозернистых (coarse-grained) до мелкозернистых (fine-grained). Самые крупнозернистые единицы называются аренами (arenas) - регион фиксированного размера в 64 МБ. Среда выполнения старается сделать арены непрерывными/смежными (contiguous), но это не всегда удается из-за поведения системного вызова mmap, который может возвращать другой адрес вместо запрошенного.
Каждая арена далее делится на меньшие единицы фиксированного размера в 8 КБ, называемые страницами (pages). Следует отметить, что эти управляемые средой выполнения страницы отличаются от типичных страниц ОС, о которых рассказывается в статье про основы виртуальной памяти, которые, как правило, имеют размер 4 КБ. Каждая страница содержит несколько объектов одинакового размера, если объекты меньше 8 КБ, или только один объект, если его размер ровно 8 КБ. Объекты, размер которых превышает 8 КБ, «растягиваются» на несколько страниц.
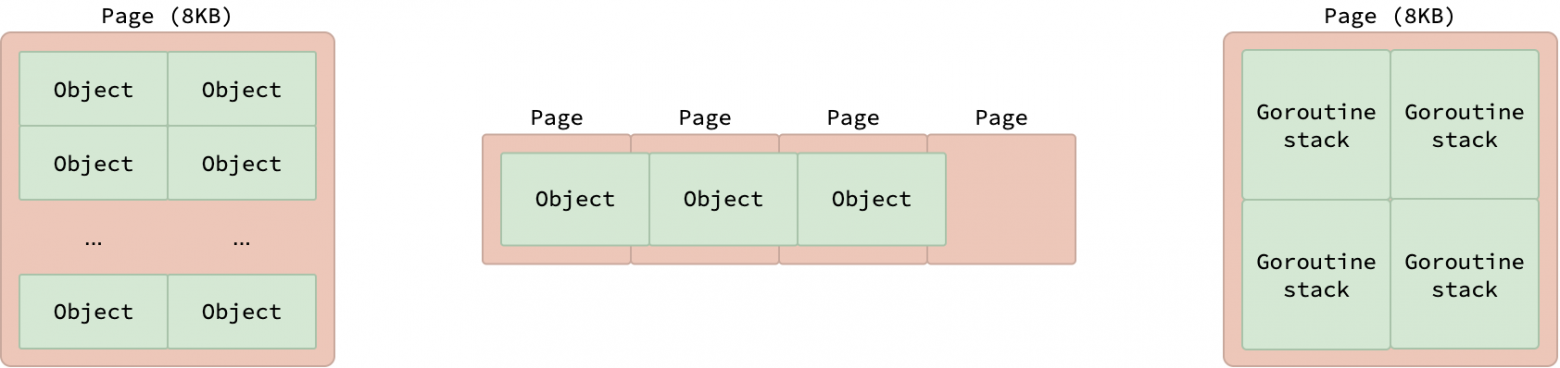
Эти страницы также используются для выделения стеков горутин. Как упоминалось в статье «Планировщик Go», каждый стек горутины изначально занимает 2 КБ. Это означает, что одна 8 КБ страница может содержать до 4 стеков горутин.
Другой ключевой концепцией выделения памяти в Go является спан (span). Спан - это единица памяти, состоящая из выделенных вместе непрерывных страниц. Каждый спан делится на несколько объектов одного размера. Разделяя спан на несколько равных объектов, Go эффективно использует стратегию выделения памяти с разделением по размерам (segregated fit). Эта стратегия позволяет Go эффективно выделять память для объектов разных размеров, минимизируя фрагментацию.
Go использует структуру mspan для хранения метаданных спана, таких как начальный адрес первой страницы, количество страниц, количество выделенных объектов и т.п. В этой статье, когда я говорю спан, я имею ввиду представляемую им область памяти, а когда я говорю mspan, я имею ввиду структуру, описывающую эту область.
В среде выполнения Go размеры объектов организованы в набор предопределенных групп, называемых классами размера (size classes). Каждый спан принадлежит ровно одному классу размера, определяемому размером содержащихся в нем объектов. Go определяет 68 различных классов размера, пронумерованных от 0 до 67, как показано в этой таблице классов размера. Класс размера 0 зарезервирован для обработки выделения памяти для крупных (large) объектов, размер которых превышает 32 КБ, в то время как классы размера от 1 до 67 используются для крошечных (tiny) и малых (small) объектов.

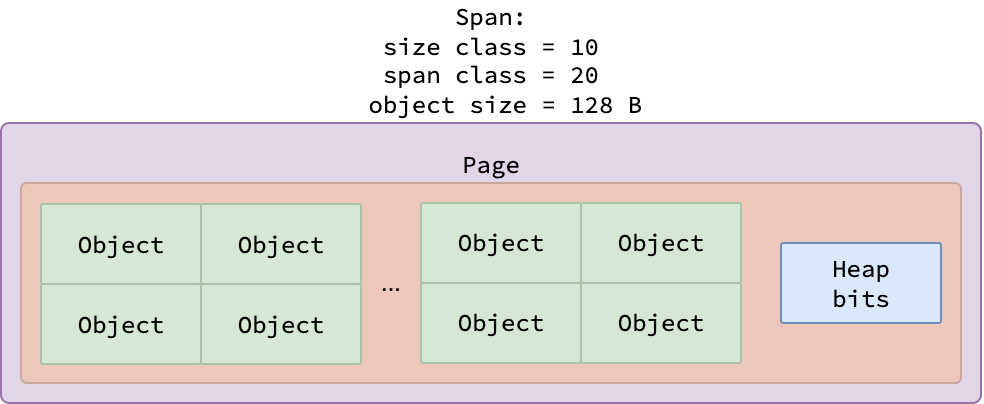
Два спана с разными классами размера
Спаны, принадлежащие к определенному классу размера, содержат фиксированное количество страниц и объектов, что определяется колонками bytes/span и objects таблицы. На рисунке выше показаны два спана: один из класса размера 38 (содержащий объекты размером 2048 байт), другой из класса размера 55 (содержащий объекты размером 10880 байт). Поскольку на одной странице размером 8 КБ помещается ровно четыре объекта размером 2048 байт, раздел для класса размера 38 содержит 4 объекта на одной странице. И, наоборот, поскольку каждый объект размером 10880 байт превышает одну страницу, раздел для класса размера 55 охватывает 4 страницы, вмещая 3 объекта.
Но почему спан класса размера 55 не содержит только один объект и не занимает две страницы, как показано на рисунке ниже? Причина в уменьшении фрагментации памяти. Поскольку объекты внутри спана являются смежными (расположены последовательно), между последним объектом и концом спана может образоваться пустое пространство. Это пространство называется хвостовыми потерями памяти (tail waste) и легко определяется по формуле (количество страниц)*8192-(количество объектов)*(размер объекта). Если бы спан был распределен на две страницы, хвостовые потери составили бы 2*8192-10880*1=5504 байта, что значительно больше, чем 4*8192-10880*3=128 байт хвостовых потерь при распределении на четыре страницы.
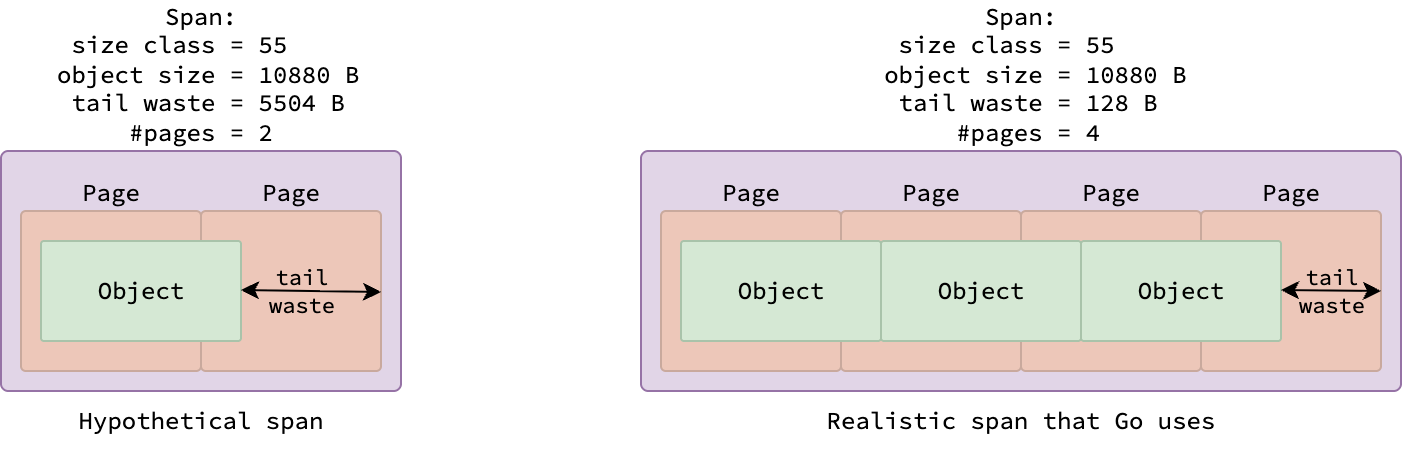
Хвостовые потери в спане
Хотя пользовательское приложение Go может выделять объекты разных размеров, почему в Go существует всего 67 классов размера для малых объектов? Что если наше приложение выделит малый объект размером 300 байт, которому не соответствует ни одна запись в таблице классов размера? В таком случае среда выполнения Go округлит размер объекта до следующего класса размера, который в данном случае равен 320 байтам. Зеленые блоки на рисунках выше — это не фактические объекты, выделенные пользовательским приложением, а объекты классов размера, управляемый средой выполнения.
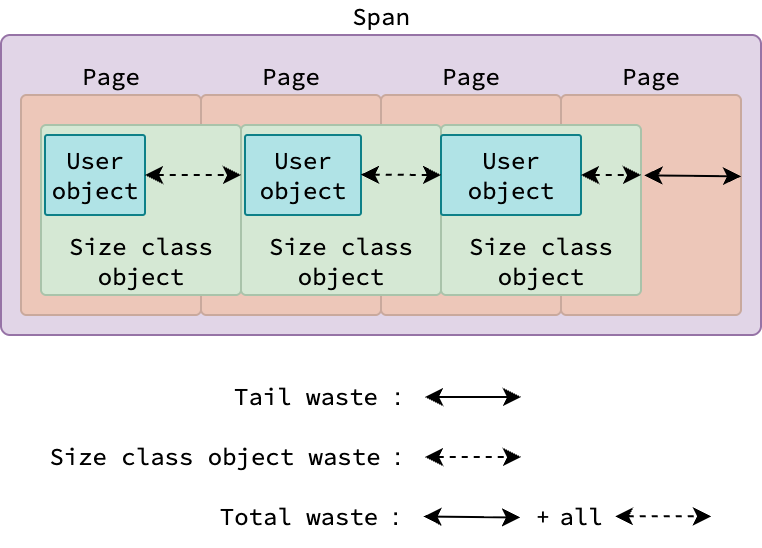
Объекты, выделяемые пользовательским приложением (пользовательские объекты), содержатся в объекте класса размера. Пользовательские объекты могут быть разных размеров, но они должны быть меньше размера объекта класса размера, к которому они принадлежат. Из-за этого между размером пользовательского объекта и размером объекта класса размера могут возникать потери (waste). Расходы всех объектов классов размера + хвостовые потери = общие потери памяти (total waste) спана.
Объект класса размера не всегда содержит ровно один пользовательский объект. Для малых и крупных пользовательских объектов каждый объект класса размера, как правило, содержит ровно один пользовательский объект. Однако крошечные пользовательские объекты могут быть упакованы в один объект класса размера (см. раздел «Распределитель крошечных объектов»).
Рассмотрим спан класса размера 55 в худшем случае, когда он содержит три пользовательских объекта, каждый размером 10241 байт (минимальный размер для объектов этого класса). Расходы от трех таких объектов составляют 3*(10880-10241)=3*639=1917 байт, а потери от хвоста — 4*8192-10880*3=128 байт. Следовательно, общие потери этого спана составляют 1917+128=2045 байт, в то время как размер спана составляет 4*8192=32768 байт, что приводит к максимальным общим потерям 2045/32768=6.24%, как указано в шестом столбце класса размера 55 соответствующей таблицы.
Хотя Go использует стратегию разделения памяти для уменьшения ее фрагментации, некоторые потери памяти все же возникают. Общие потери спана отражают количество внешне фрагментированной памяти в нем.
Сборщик мусора Go является трассирующим (tracing). Это означает, что в процессе сборки ему нужно обойти (traverse) граф объектов для определения всех достижимых/доступных (reachable) объектов. Однако, если известно, что тип не содержит указателей ни напрямую, ни в своих полях (например, структура имеет несколько полей, и некоторые из них содержат указатели на примитивные типы или другие структуры), то сборщик мусора может безопасно пропустить сканирование объектов этого типа для уменьшения накладных расходов и повышения производительности, верно? Наличие или отсутствие указателей в типе определяется во время компиляции, поэтому эта оптимизация не влечет за собой дополнительных затрат во время выполнения.
Для упрощения такого поведения среда выполнения Go вводит концепцию класса спана (span class). Этот класс классифицирует спаны на основе двух свойств: класса размера содержащихся в них объектов и наличия у этих объектов указателей. Если объекты содержат указатели, спан относится к классу scan (сканируемый). Если нет, он классифицируется как noscan (несканируемый).
Поскольку наличие указателя — бинарное свойство (тип либо содержит указатели, либо нет), общее количество классов спана в два раза превышает количество классов размера. Таким образом, Go определяет 68*2=136 классов спана. класс спана представлен целым числом от 0 до 135. Если число четное, это класс scan, иначе — noscan.
Ранее упоминалось, что каждый спан принадлежит ровно одному классу размера. Если быть более точным, каждый спан принадлежит ровно одному классу спана. Соответствующий класс размера может быть получен путем деления номера класса спана на 2. Таким образом, принадлежность спана к классу scan или noscan определяется четностью номера класса спана.
Для эффективного управления спанами среда выполнения Go организует их в структуру данных под названием «множество/набор спанов» (span set). Набор спанов — это коллекция объектов mspan, принадлежащих одному классу спана, как показано на этом рисунке.
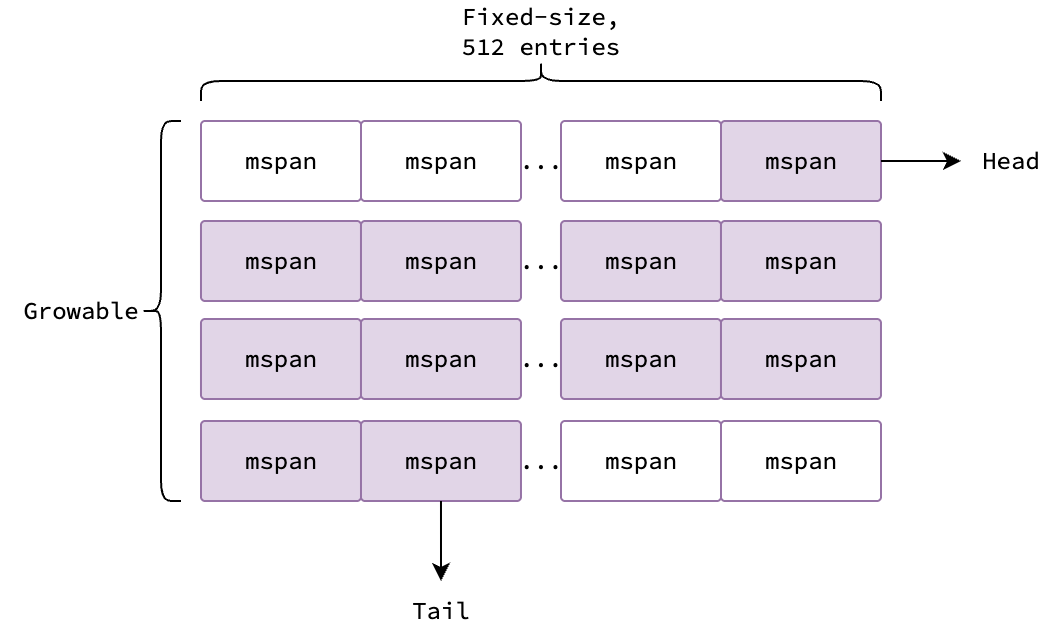
По сути, это срез (slice) массивов. Срез растет динамически по мере необходимости, а размер каждого массива является фиксированным и составляет 512 элементов. Каждый элемент в массиве — это объект mspan, содержащий метаданные спана, и поэтому может быть нулевым. Фиолетовые элементы на рисунке ненулевые, а белые нулевые.
Набор спанов также имеет два дополнительных поля, head и tail, которые используются для отслеживания первого и последнего элемента во множестве. Удаление элементов из набора начинается с head, массивы обходятся сверху вниз, а элементы каждого массива — слева направо. Добавление элементов в набор начинается с tail, массивы также обходятся сверху вниз и заполняются слева направо. В случае, если выполнение операции приводит к пустому массиву, он удаляется из множества спанов и добавляется в пул (pool) свободных массивов для дальнейшего использования.
Обратите внимание, что head и tail являются атомарными переменными, поэтому добавление или удаление спанов из набора может выполняться несколькими горутинами одновременно без необходимости в дополнительной блокировке.
Рассмотрим большую структуру с 1000 полей, где некоторые поля являются указателями. Как сборщик мусора узнает, какие поля являются указателями, чтобы правильно обходить граф объектов? Если бы сборщику мусора приходилось проверять каждое поле каждого объекта во время выполнения, это было бы крайне неэффективно, особенно для больших или глубоко вложенных структур данных. Для решения этой проблемы Go использует метаданные для эффективного определения местоположения указателей без сканирования всех полей. Этот механизм основан на двух ключевых структурах: битах кучи и заголовках malloc.
Для объектов размером менее 512 байт Go выделяет память в виде спанов и использует битовую карту кучи (heap bitmap) для отслеживания того, какие слова (words) в спане содержат указатели. Каждый бит в битовой карте соответствует слову (обычно, 8 байт): 1 указывает на указатель, 0 — на данные, не являющиеся указателями. Битовая карта хранится в конце спана и используется всеми объектами в нем. При создании спана Go резервирует место для битовой карты и использует оставшееся пространство для размещения как можно большего количества объектов.
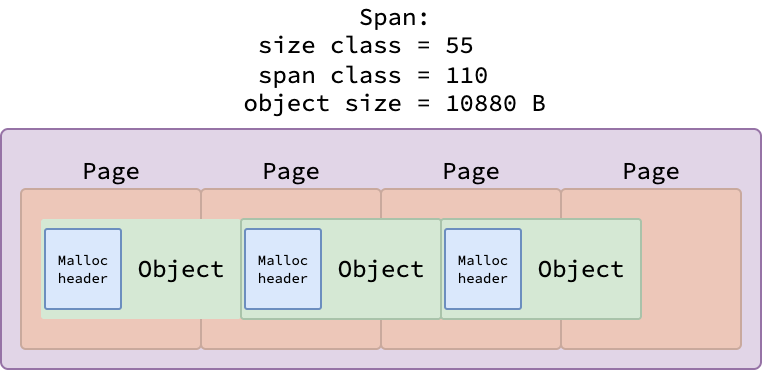
Для объектов, размером более 512 байт, поддержание большой битовой карты неэффективно. Вместо этого, каждый объект сопровождается 8-байтовым заголовком malloc — указателем на информацию о типе объекта. Эти метаданные типа включают поле GCData, которое кодирует структуру указателей типа. Сборщик мусора использует эти данные для точного и эффективного поиска только тех полей, которые содержат указатели, при обходе графа объектов.
Абстракция кучи (heap) Go основана на областях, отображаемых в память (memory-mapped segments), управляемых глобальным объектом mheap. mheap отвечает за выделение новых спанов, удаление неиспользуемых спанов и даже за управление стеками горутин.
Поскольку среда выполнения Go работает в обширном виртуальном адресном пространстве, распределитель памяти mheap может испытывать трудности с эффективным поиском смежных свободных страниц при выделении спана, особенно при высоком уровне параллелизма. В ранних версиях Go, как подробно описано в предложении «Масштабирование распределителя страниц Go», каждая операция mheap была глобально синхронизирована. Такая конструкция приводила к значительному снижению пропускной способности и увеличению задержки в хвосте распределения при больших объемах операций выделения памяти. Современный распределитель памяти Go реализует масштабируемую конструкцию из этого предложения. Рассмотрим, как он преодолевает эти узкие места и эффективно управляет выделением памяти в средах с высокой параллельностью.
Поскольку виртуальное адресное пространство велико, а состояние каждой страницы (свободна или используется) является бинарным свойством, имеет смысл хранить эту информацию в битовой карте, где 1 обозначает использование, а 0 — свободу. Обратите внимание, что в данном контексте «используется» или «свободна» относится к тому, принадлежит ли страница определенному спану, а не к тому, используется ли она пользовательским приложением. Каждая битовая карта представляет собой массив из 8 значений uint64, занимающий в общей сложности 64 байта, и может представлять состояние 512 смежных страниц.
Учитывая, что размер арены составляет 64 МБ, а каждая страница весит 8 КБ, в арене содержится 64MB/8KB=8192 страницы. Поскольку каждая битовая карта покрывает 512 страниц, для арены требуется 8192/512=16 битовых карт. При размере каждой битовой карты в 64 байта, общий размер всех битовых карт арены составляет 16×64=1024 байта, или 1 КБ.
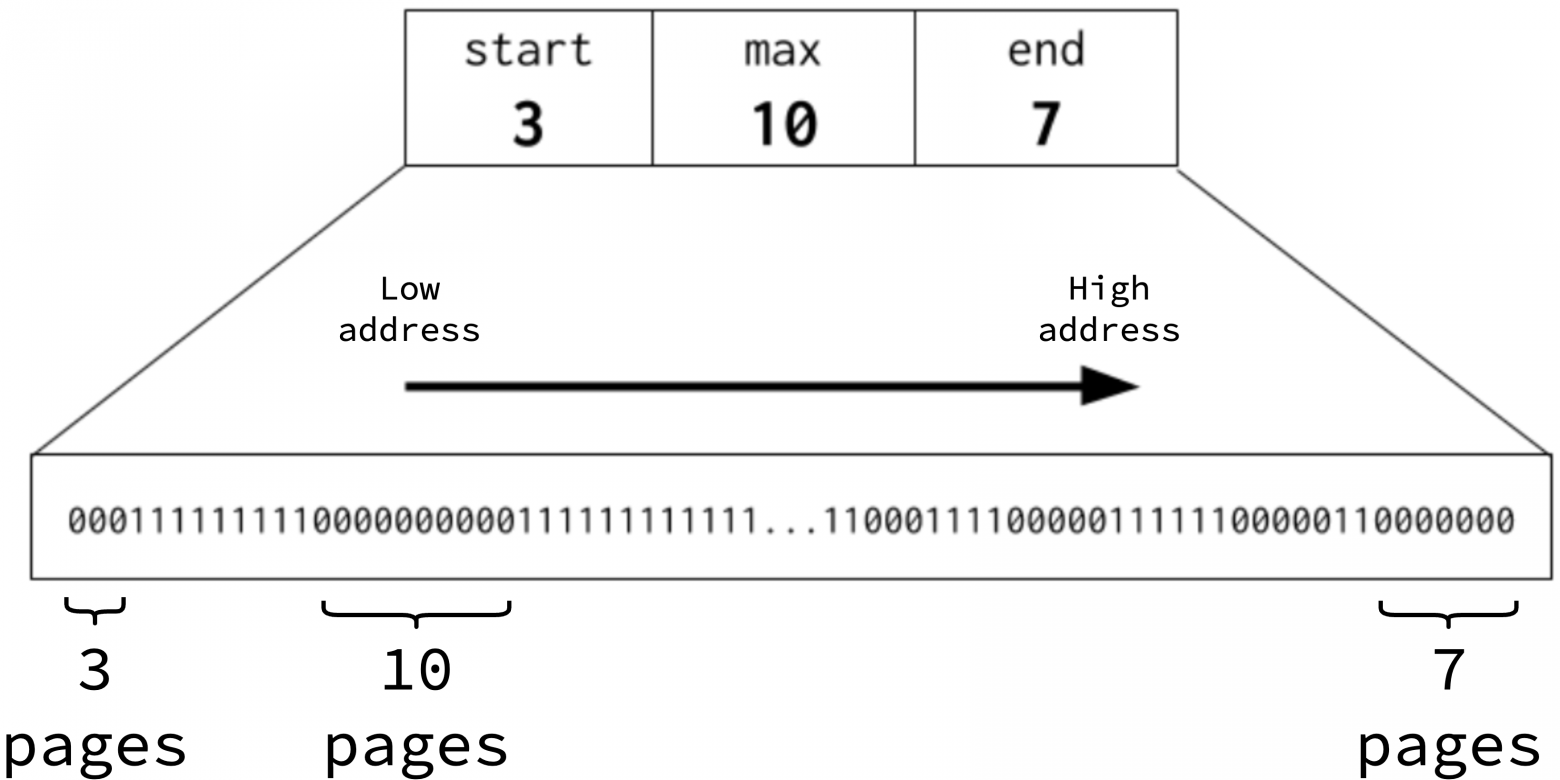
Однако перебор битовой карты для поиска последовательности свободных страниц по-прежнему неэффективен и расточителен, если битовая карта не содержит свободных страниц. Лучше каким-то образом кэшировать свободные страницы, чтобы можно было быстро найти свободную страницу без сканирования битовой карты. В Go вводится понятие сводки (summary) битовой карты, которая содержит три поля: start, end и max. start — это количество последовательных нулевых битов в начале битовой карты. Аналогично, end — это количество последовательных нулевых битов в конце битовой карты. Наконец, max представляет собой наибольшую последовательность нулевых битов. Сводки обновляются при каждом изменении битовой карты, то есть когда страница выделяется или освобождается.
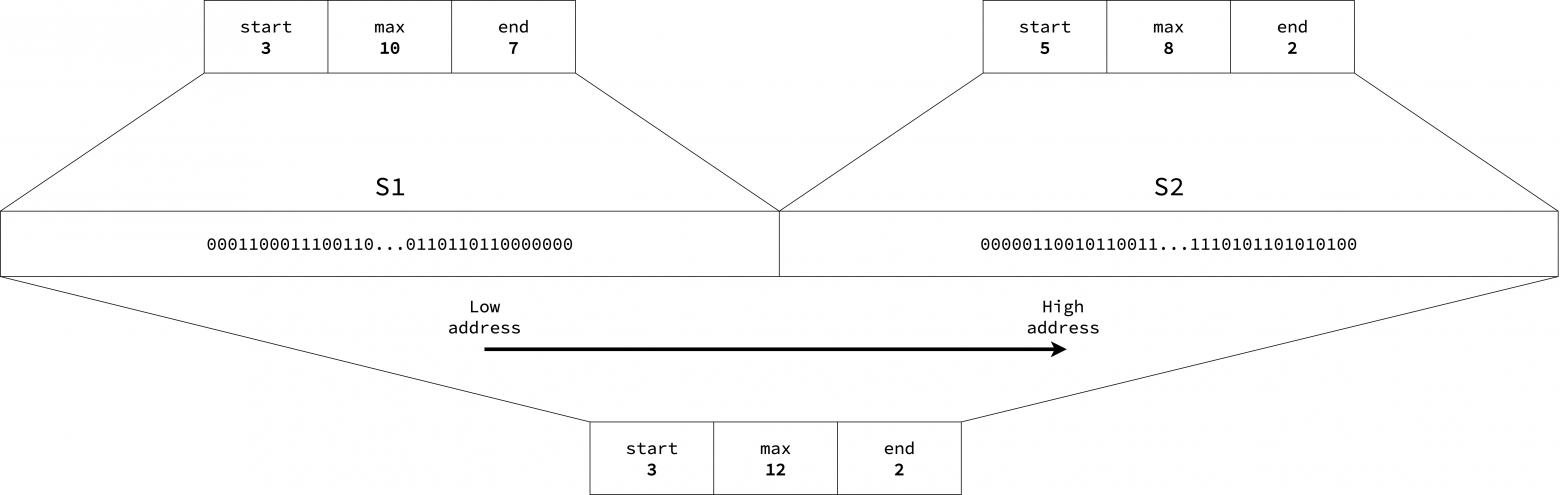
На рисунке ниже представлено краткое описание битовой карты: в начале имеется 3 непрерывных свободных страницы, в конце — 7, а самая длинная последовательность свободных страниц составляет 10. Стрелкой показано направление роста адресного пространства, то есть 3 свободные страницы по нижнему адресу (lower address) и 7 свободных страниц по верхнему адресу (higher address).
Благодаря этим полям Go может найти достаточный непрерывный свободный фрагмент памяти в пределах одной арены или нескольких смежных арен, объединив сводки соседних фрагментов памяти. Рассмотрим два смежных фрагмента, S1 и S2, каждый из которых занимает 512 страниц. Сводка S1 — start=3, end=7 и max=10, а сводка S2 - start=5, end=2 и max=8. Поскольку эти фрагменты последовательные, их можно объединить в одну сводку, охватывающую все 1024 страницы. Объединенная сводка вычисляется как start=S1.start=3, end=S2.end=2, max=max(S1.max, S2.max, S1.end+S2.start)=max(10, 8, 7+5)=12.
Объединяя сводки нижнего уровня, Go неявно создает иерархическую структуру, обеспечивающую эффективное отслеживание непрерывных свободных страниц. Он управляет всем виртуальным адресным пространством, используя единое глобальное базисное дерево (radix tree) сводок, как показано на рисунке ниже. Каждый синий прямоугольник представляет собой сводку для смежного блока памяти, а пунктирные линии, ведущие к следующему уровню, отражают, какую часть следующего уровня он охватывает. Зеленый прямоугольник представляет собой битовую карту 512 страниц, на которые ссылается сводка листового узла (leaf node).
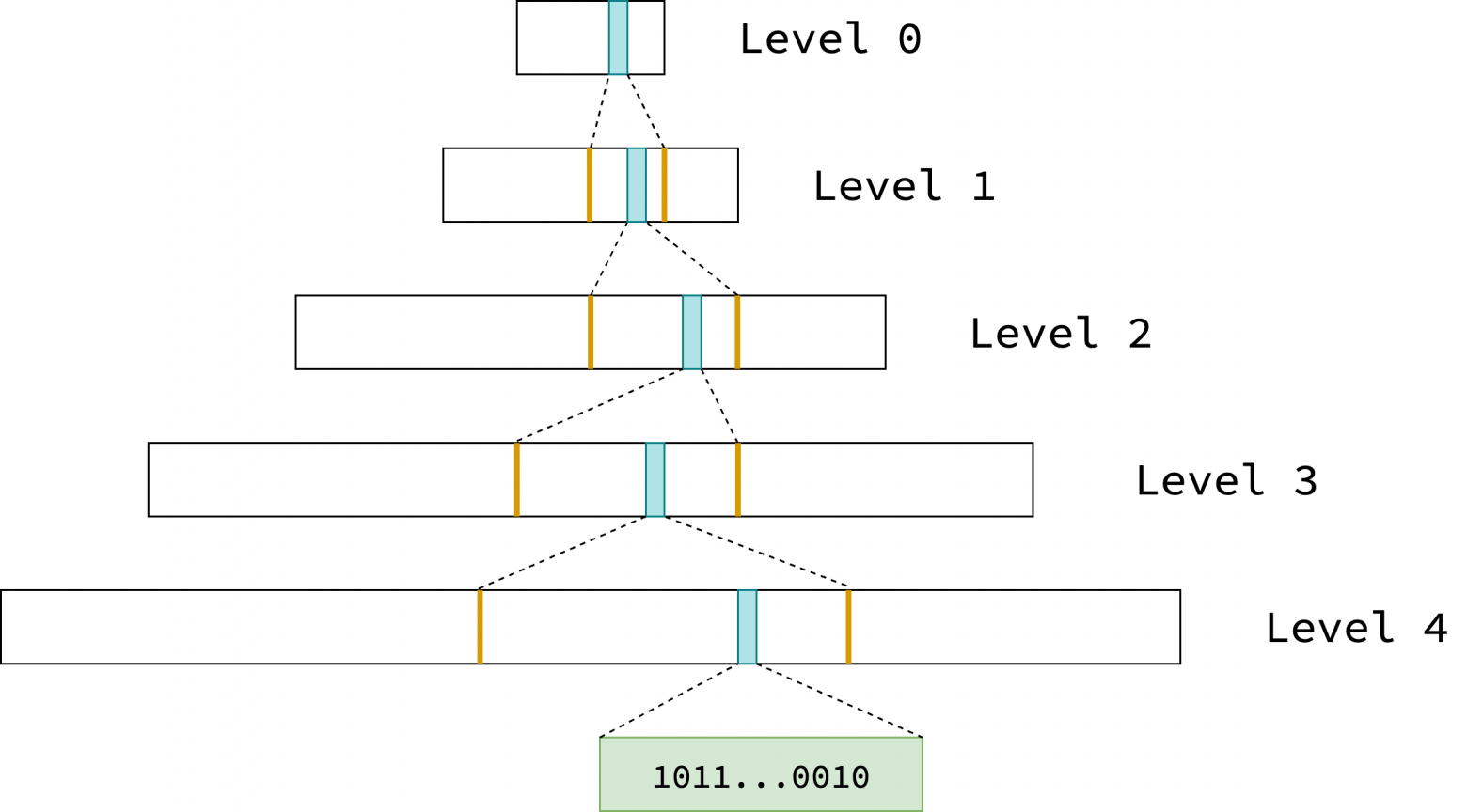
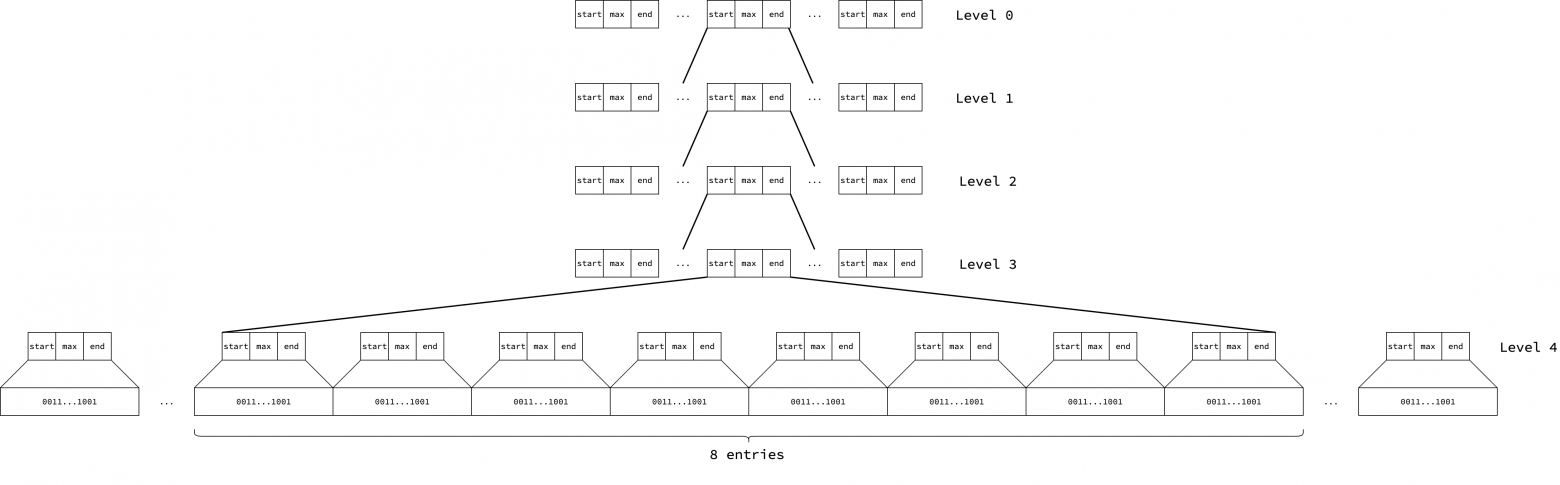
В архитектуре Linux/AMD64 Go использует 48-битное виртуальное адресное пространство, которое занимает 2^48 байт или 256 ТБ. В этой конфигурации высота базисного дерева равна 5. Внутренние узлы (уровни от 0 до 3) хранят сводки, полученные путем слияния их 8 дочерних узлов. Каждый листовой узел (уровень 4) соответствует сводке одной битовой карты, которая охватывает 512 страниц.
На уровне 0 содержится 16384 записи, на уровне 1 — 16384*8, на уровне 2 — 16384*8^2, на уровне 3 — 16384*8^3 и на уровне 4 — 16384*8^4. Поскольку каждая листовая запись охватывает 512 страниц, каждая запись нулевого уровня охватывает 512*8^4=2097152 смежных страниц, что соответствует 2097152*8KB=16 ГБ памяти. Обратите внимание, что эти числа представляют максимально возможное количество записей. Фактическое количество записей на каждом уровне постепенно увеличивается по мере роста кучи.
Как упоминалось ранее, каждый уровень 0 охватывает 209715=2^21 смежных страниц, start, end и max могут быть размером до 2^21. Как следствие, хранение этих трех полей требует до 21*3=63 бит. Это делает возможным упаковать сводку в единый uint64 под названием pallocSum: первые 21 бита хранят start, следующие 21 — end и следующие 21 - max.
Существует один специальный случай: если max=2^21, значит, весь фрагмент пуст. В этом случае start и end также равняются 2^21, а сводка кодируется как 2^63. Напротив, если фрагмент не имеет свободных страниц, т.е. start, end и max равняются 0, значение сводки также равняется 0.
Сводное базисное дерево реализовано как массив срезов, где каждый срез соответствует уровню дерева. Массив фиксирует количество уровней дерева, а срезы динамически увеличиваются по мере расширения кучи. Сводки для нижнего адреса остаются в начале среза, а сводки для верхнего адреса добавляются в конец среза. Поскольку срез сводки на данном уровне охватывает все зарезервированное адресное пространство, индекс сводки внутри этого среза напрямую определяет область памяти, которую он представляет.
Для поиска достаточной последовательности свободных страниц в Go используется алгоритм поиска в глубину (deep-first search, DFS). Он начинается со сканирования до 16384 записей на уровне 0 базисного дерева. Если в сводке указано 0 (нет свободных страниц), он переходит к следующей записи. Если достаточная последовательность найдена на границе между двумя соседними записями или в начале первой записи, или в конце последней, то он немедленно возвращает адрес свободной последовательности, основываясь на адресе, на который ссылается сводка.
В противном случае, если поле max текущей сводки удовлетворяет запросу на выделение памяти, поиск переходит к 8 дочерним записям следующего уровня. Если поиск достигает конечного уровня, но все еще не может найти достаточную последовательность, то он сканирует битовую карту внутри записи, значение max которой достаточно велико, чтобы найти точную последовательность свободных страниц. Если мы проходим все записи на уровне 0, но все еще не можем найти достаточную последовательность, он возвращает значение 0, указывающее на отсутствие свободных страниц.
Вы можете заметить недостаток этого алгоритма: если многие страницы в начале уровня 0 уже используются, распределитель памяти будет многократно проходить по одному и тому же пути в дереве при каждом выделении памяти, что неэффективно. Go решает эту проблему, поддерживая подсказку (hint) searchAddr, которая отмечает адрес, перед которым нет свободных страниц. Это позволяет распределителю памяти начинать поиск непосредственно с подсказки, а не с самого начала.
Если в базисном дереве нет свободных страниц, т.е. pageAlloc.find возвращает 0, среда выполнения Go должна запросить у ядра расширение виртуального адресного пространства с помощью системного вызова mmap. Расширение происходит не на количество запрошенных страниц, а большими блоками, округленными до размера арены (64 МБ). Даже если запрошена только одна страница, куча расширяется на 64 МБ в виртуальном адресном пространстве (а не в физическом, благодаря страничной организации памяти по требованию).
Для управления этим среда выполнения поддерживает список адресов-подсказок (hint addresses) arenaHints — адресов, которые она предпочитает использовать для новых выделений памяти ядром. Этот список инициализируется перед выполнением функции main, и его элементы можно найти здесь. В процессе расширения кучи, Go перебирает эти подсказки, запрашивая у ядра выделение памяти по каждому предложенному адресу, передавая этот адрес в качестве первого параметра системного вызова mmap.
Однако ядро может выбрать другое местоположение. В этом случае Go переходит к следующей подсказке. Если все подсказки не срабатывают, Go возвращается к запросу памяти по случайному адресу, выровненному по размеру арены, а затем обновляет список подсказок таким образом, чтобы будущий рост оставался смежным с вновь выделенной ареной.
Этот процесс переводит раздел памяти из состояния None (не используется) в состояние Reserved (зарезервирован). После регистрации арены в среде выполнения, то есть добавления ее в список всех арен, раздел переходит из состояния Reserved в состояние Prepared (подготовлен). На этом этапе дерево сводок обновляется, чтобы включить новую арену, расширяя срезы сводок на каждом уровне, помечая битовую карту для новых страниц как свободную и соответствующим образом обновляя сводки. Этот новый раздел памяти также отслеживается как используемый (in-use).
После обнаружения свободной последовательности страниц, среда выполнения настраивает объект mspan для управления этим диапазоном памяти. Как и любой другой объект Go, объект mspan сам должен «жить» в памяти. mspan выделяются распределителем slab fixalloc, который запрашивает память непосредственно у ядра с помощью системного вызова mmap.
Затем для каждого спана указывается его класс размера, количество покрываемых им страниц и адрес первой страницы. Соответствующий раздел памяти переходит из состояния Prepared в состояние Ready, что означает его готовность к использованию в mcentral.
К сожалению, и pageAlloc.find, и mheap.grow используют глобальные блокировки, которые могут стать узкими местами производительности при большом количестве параллельных выделений памяти. Поскольку уровень параллелизма программы на Go определяется количеством процессоров, локальное кэширование свободных страниц в каждом процессоре помогает избежать конфликтов с глобальными блокировками.
В Go это реализовано с помощью объекта pageCache для каждого процессора. pageCache состоит из базового адреса для блока памяти, выровненного по 64 страницам, и 64-битной битовой карты, отслеживающей, какие из этих страниц свободны. Поскольку каждая страница имеет размер 8 КБ, один pageCache может содержать до 512 КБ свободной памяти.
Когда горутина запрашивает спан у mheap, среда выполнения сначала проверяет pageCache текущего процессора. Если свободных страниц достаточно, они используются для настройки спана. Иначе, среда выполнения вызывает pageAlloc.find для поиска подходящей последовательности страниц.
Если pageCache пуст, среда выполнения выделяет новый. Сначала она пытается получить страницы рядом с текущей подсказкой searchAddr в сводном базисном дереве (см. раздел «Поиск свободных страниц»). Поскольку подсказка может быть неточной, для поиска свободных страниц может потребоваться обход дерева.
Обратите внимание, что вероятность наличия N свободных страниц уменьшается при приближении N к 64, поскольку pageCache ограничен 64 страницами. В таком случае, может быть слишком много промахов кэша (cache misses), и среда выполнения будет часто обращаться к pageAlloc.find для поиска свободных страниц. Поэтому, если значение N равно или больше 16, среда выполнения не проверяет кэш и сразу использует pageAlloc.find.
Рисунок ниже показывает логику поиска свободных страниц для выделения спана. Серый блок Find pages был описан в разделе «Поиск свободных страниц», зеленый блок Grow the heap был описан в разделе «Расширение кучи», а синий блок Set up a span был описан в разделе «Настройка спана».

После получения новых страниц, они помечаются как используемые в сводном базисном дереве, чтобы предотвратить их присвоение другими процессорами и гарантировать, что распределитель памяти не будет использовать их повторно при следующем расширении кучи. Подсказка сводного дерева также обновляется, чтобы последующие выделения памяти пропускали эти используемые страницы.
Как упоминалось в разделе «Настройка спана», для представления и управления спаном страниц должен быть выделен объект mspan. Если mspan извлекается прямо из mheap, требуется глобальная блокировка, что может стать узким местом производительности. Во избежание этого, Go кэширует свободные mspan для каждого процессора P, как страницы.
После обнаружения свободных страниц в pageCache, среда выполнения сначала проверяет, есть ли у текущего P кэшированный mspan. Если есть, он может быть повторно использован незамедлительно без конкуренции за глобальную блокировку. Иначе, среда выполнения выделяет несколько mspan из mheap, кэширует их в свободном списке P для будущего использования и присваивает один из них для управления выделенной последовательностью страниц.
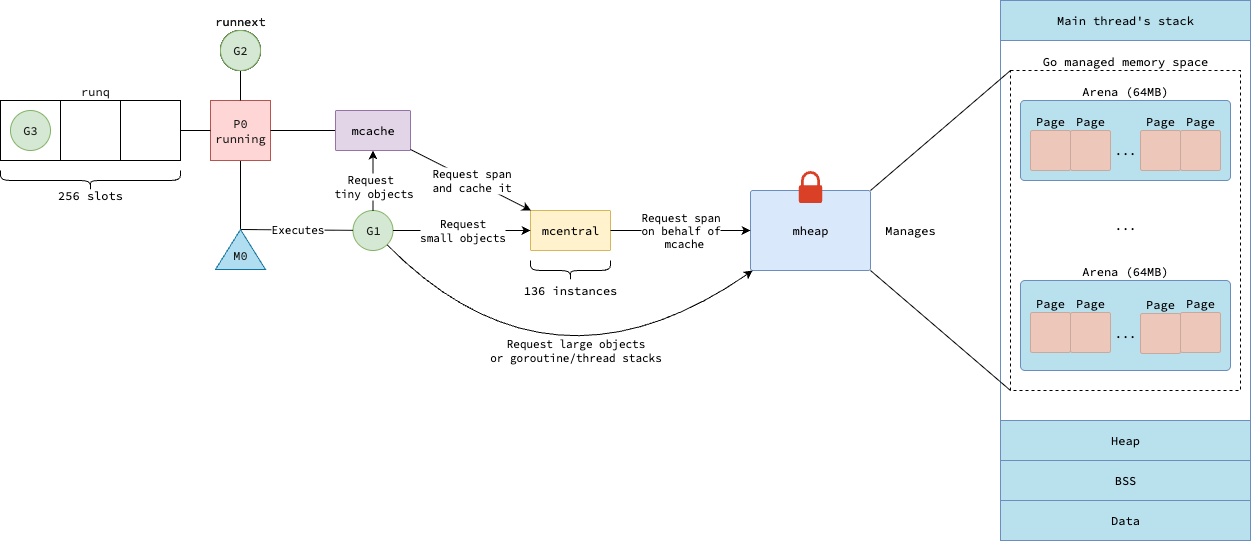
Поскольку mheap в основном управляет крупнозернистыми единицами памяти, такими как страницы и крупные спаны, он не предоставляет эффективного способа выделения и освобождения крошечных или малых объектов. Эту роль выполняет mcentral, который также служит связующим звеном между mheap и распределителями памяти на уровне P mcache.
Каждый mcentral управляет спанами, принадлежащими определенному классу спана. В сумме mheap поддерживает 136 экземпляров mcentral — по одному для каждого класса. В mcentral существует 2 категории множеств спанов: полные (full) (спаны без свободных объектов) и частичные (partial) (спаны с некоторыми объектами). Каждая категория далее также делится на 2 множества спанов: swept (очищенные) и unswept (неочищенные), в зависимости от того, были спаны очищены или нет.
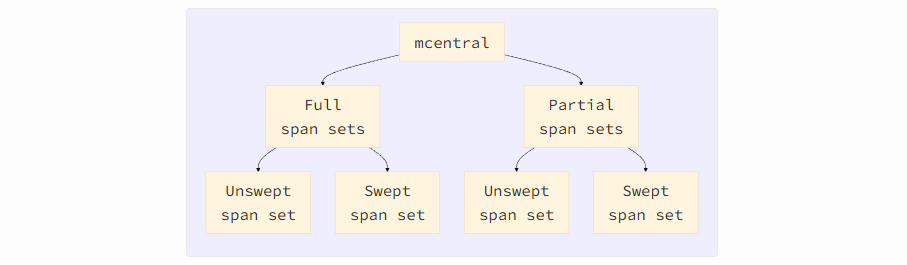
Что означает «очистка» спана? Сборщик мусора Go основан на принципе «пометить и очистить» (mark-and-sweep): сначала он помечает все доступные объекты, затем удаляет недоступные, либо возвращая эту память среде выполнения для повторного использования, либо, в некоторых случаях, возвращая ее ядру для уменьшения занимаемой процессом памяти. Очистка — сложный процесс, но, по сути, он включает в себя следующие три шага: удаление спана из неочищенного множества, освобождение объектов, помеченных как недоступные в этом спане, и добавление спана в очищенное множество.
Переход спана между частичным и полным определяется в процессе выделения или очистки памяти, в зависимости от увеличения или уменьшения количества свободных объектов в спане. Если количество свободных объектов в спане достигает 0, он перемещается из частичного множества в полное. Если число свободных объектов в спане положительное, он перемещается из полного набора в частичный.
Поскольку наборы спанов являются потокобезопасными (thread-safe), mcentral доступен нескольким горутинам одновременно без необходимости дополнительной блокировки. Это повышает пропускную способность выделения спанов.
Как посредник между mheap и mcache, mcentral отвечает за подготовку спана (либо из существующих множеств спанов, либо из запрошенных у mheap) для запрашивающего mcache. Эта логика подробно иллюстрируется на рисунке ниже. Логика зеленого блока Request mheap to allocate a span описана в разделе «Выделение спана».
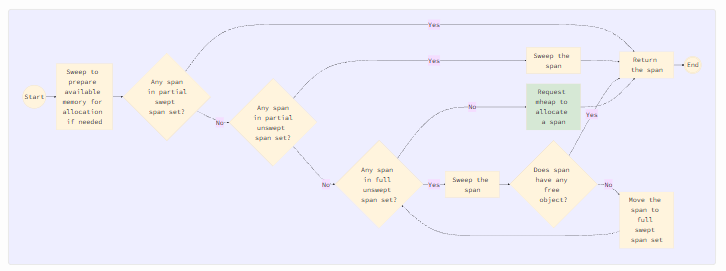
Когда mcache необходимо вернуть спан обратно в mcentral, он вызывает метод mcentral.uncacheSpan. Если спан еще не был очищен, он сначала очищается, чтобы освободить недоступные объекты. Затем, независимо от того, требовалась ли очистка, фрагмент помещается либо в полный, либо в частичный набор очищенных объектов, в зависимости от количества свободных объектов в нем.
Как упоминалось в статье «Планировщик Go», каждый процессор P служит контекстом выполнения горутин. Как горутина может выделять память, так и каждый P также поддерживает собственный распределитель памяти mcache, оптимизированный для выделения кучи для крошечных и малых объектов, а также за выделение стека для горутин.
Название «mcache» происходит от того, что он кэширует спаны со свободными объектами для каждого класса спана в своем поле alloc. При инициализации экземпляра mcache, каждый класс спана кэшируется с emptyspan, который не содержит свободных объектов. Когда горутине требуется выделить пользовательский объект определенного класса спана, она запрашивает у mcache свободный объект класса размера для размещения запрошенного объекта пользователя — либо из кэшированного спана, либо путем запроса нового спана из mcentral, если в кэшированном спане нет свободного объекта. Эта логика показана на следующем рисунке.
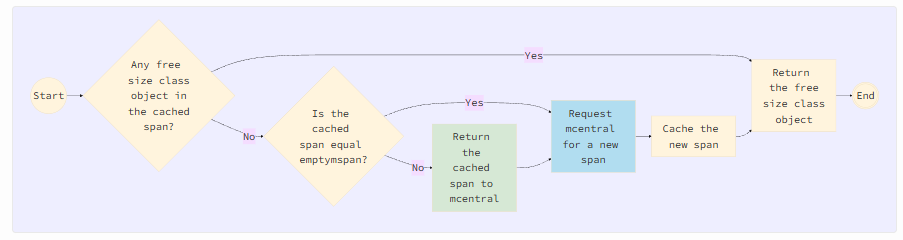
Логика для зеленого блока Return the cached span to mcentral описана в разделе «Очистка спана». Логика для синего блока описана в разделе «Подготовка спана».
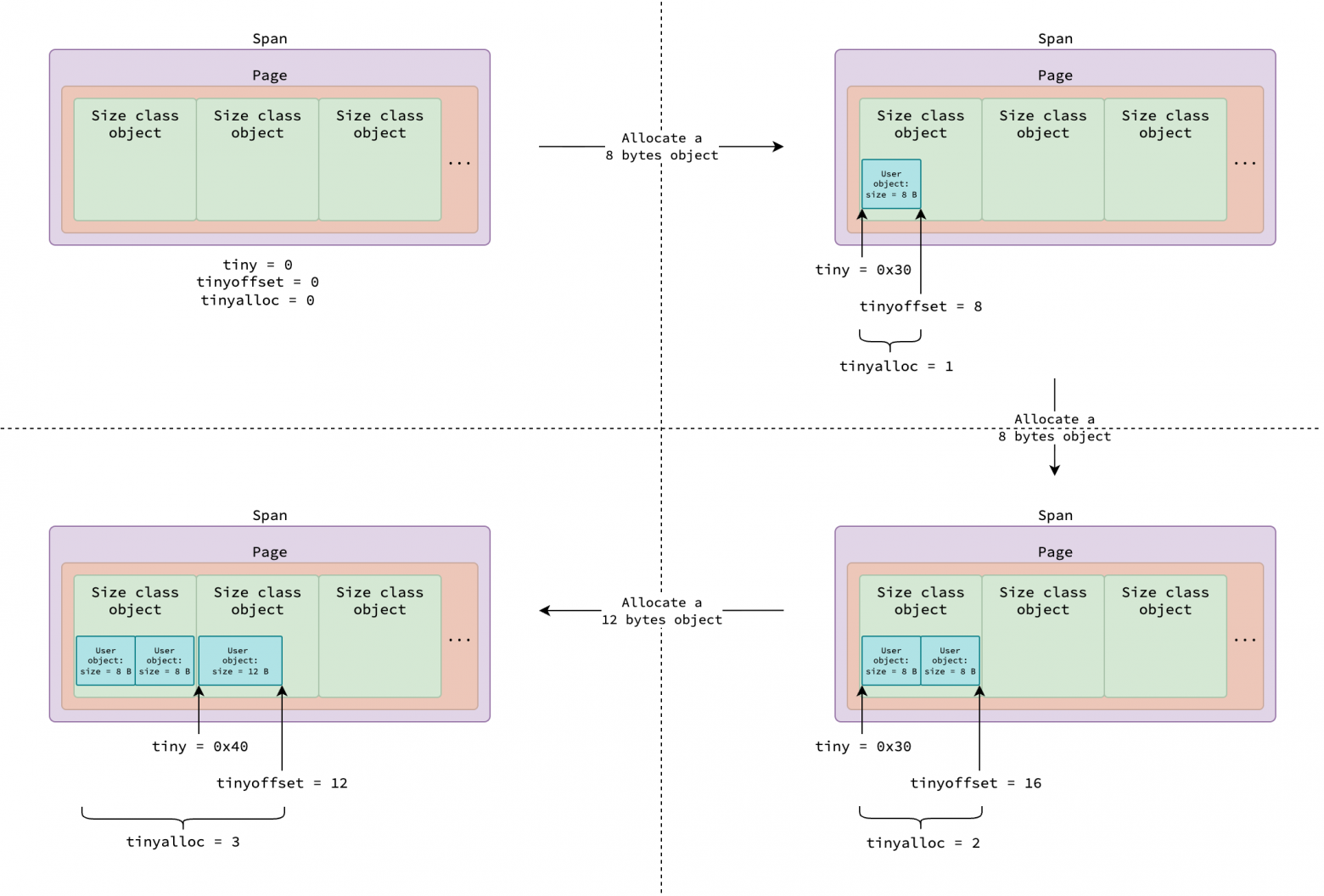
Все крошечные объекты пользователя разных размеров (менее 16 байт) выделяются из класса спана 5 (класса размера 2), где каждый объект класса размера занимает 16 байт. Каждый экземпляр mcache отслеживает выделение памяти для крошечных объектов в спане с помощью трех полей:
tiny — начальный адрес текущего объекта класса размера, имеющего доступное пространство для выделения
tinyoffset — конечная позиция (относительно tiny) последнего выделенного объекта пользователя
tinyalloc - общее количество выделенных крошечных объектов пользователя в текущем спане
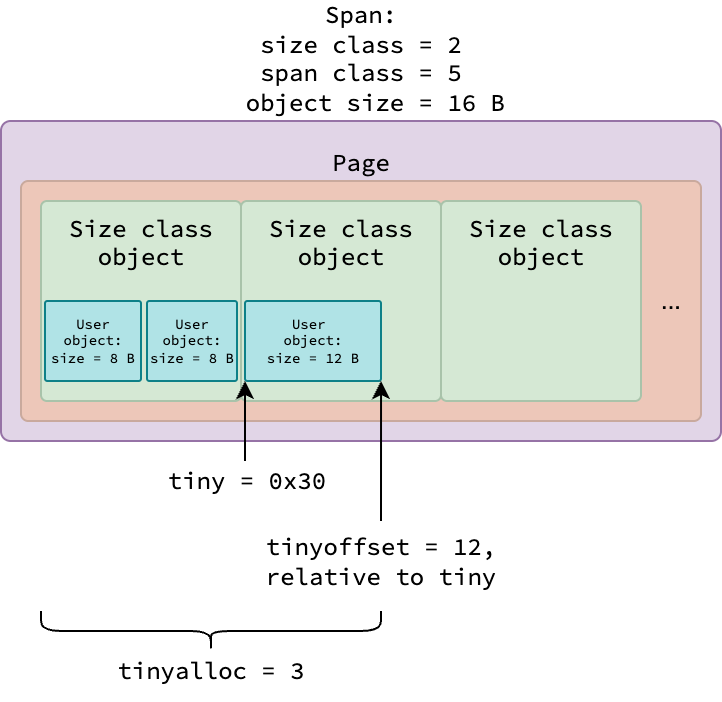
Рисунок выше иллюстрирует спан, используемый для выделений крошечных объектов, где 0x30 — это пример начального адреса объекта класса размера. Подробная логика выделения будет описана ниже.
Таким образом, распределитель памяти Go — это сложная система, состоящая из трех компонентов, работающих вместе для эффективного управления памятью: mheap, mcentral и mcache. Рисунок ниже показывает, как эти компоненты взаимодействуют между собой для выделения памяти для наших Go-программ.
Одним из распространенных заблуждений в Go является то, что выделение объектов в куче требует new(T) или &T{}. Это не всегда так по нескольким причинам. Во-первых, если объект небольшой, живет только в области видимости функции и не ссылается на внешние значения, компилятор может выделить его в стеке, а не в куче. Во-вторых, даже примитив, объявленный с помощью var n int, может оказаться в куче, в зависимости от анализа выхода (escape analysis). В-третьих, создание составных типов, таких как срезы, карты или каналы с помощью make, часто помещает нижележащие структуры данных в кучу.
Решение о выделении объекта в куче принимается компилятором и будет описано позже. В этом разделе мы сфокусируемся на mallocgc — методе, который используется средой выполнения для выделения объектов в куче. Этот метод косвенно вызывается разными встроенными функциями и операторами, такими как new, make и &T{}.
mallocgc разделяет объекты на три категории по размеру: крошечные (менее 16 байт), малые (от 16 до 32760 байт) и крупные (более 32760 байт). Также принимается во внимание, содержит ли объектный тип указатели, влияющие на сборку мусора. На основе этого критерия он вызывает разные пути (paths) выделения памяти, как показано на рисунке ниже, для оптимизации использования памяти и производительности.
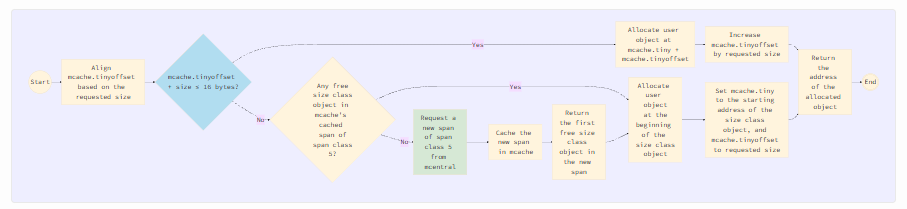
Крошечные объекты выделяются mcache для каждого процессора с помощью трех свойств, описанных в разделе «Распределитель памяти крошечных объектов». Логика выделения показана на следующем рисунке.
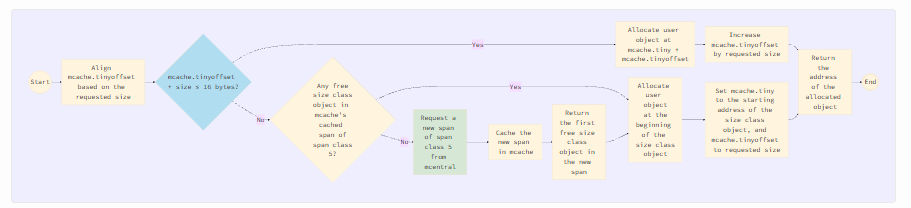
Выравнивание tinyoffset выполняется в соответствии с запрошенным размером: 8-байтовое выравнивание, если размер делится на 8, 4-байтовое, если делится на 4, 2-байтовое, если делится на 2, и без выравнивания — в остальных случаях. Проверка/условие в синем ромбе означает, может ли пользовательский объект запрошенного size, начиная с tinyoffset, поместиться в текущий объект класса размера. Если да, то новый объект пользователя может быть выделен внутри этого объекта класса размера. Логика зеленого блока Request a new span of span class 5 from mcentral описана в разделе «Подготовка спана».
Обратите внимание, что выделение крошечных объектов выполняется mcache каждого процессора. Это делает выделение потокобезопасным и свободным от блокировок, за исключением случаев, когда новый спан должен быть запрошен из mheap через mcentral.
Спаны, используемые для выделения крошечных объектов, принадлежат классу спана 5 или классу размера 2. Согласно таблице классов размера, спан класса размера 2 вмещает 512 объектов этого класса. Поскольку каждый объект класса размера может содержать несколько пользовательских объектов в выделении крошечных объектов, один спан может обслуживать, как минимум, 512 выделений крошечных объектов пользователя без каких-либо блокировок.
Для того, чтобы сборщик мусора мог эффективно идентифицировать «живые» объекты и пропускать трассировку объектов, которые не содержат ссылок на другие объекты, Go делит малые объекты на классы спана scan и noscan (описано в разделе «Класс спана»). Класс scan далее также делится на 2 категории: с битами кучи и с заголовком malloc (описано в разделе «Биты кучи и заголовок malloc»). Go реализует разные функции для выделения малых объектов на основе этих классификаций.
Малые объекты, не содержащие указатели, выделяются функцией mallocgcSmallNoscan. Запрошенный size сначала округляется до класса размера. Поскольку выделение является noscan, класс спана вычисляется как 2*sizeclass+1. Например, если пользователь запрашивает объект размером 365 байт, он округляется к ближайшему классу размера 384 байта или классу размера 22. Соответствующим классом спана будет 45 (2*22+1).
Затем функция проверяет, имеется ли свободный объект в кэшированном спане вычисленного класса спана в mcache текущего процессора. Если нет, она запрашивает свободный объект класса размера через запрос нового спана у mcentral и кэширует его в mcache. После получения свободного объекта, она обновляет информацию для сборщика мусора и профилировщика и возвращает адрес выделенного объекта.
В зависимости от размера, малые объекты, содержащие указатели, выделяются функцией mallocgcSmallScanNoHeader или mallocgcSmallScanHeader. Если запрошенный size меньше 512 байт, выделение осуществляется первой функцией, иначе — второй. Логика этих двух функций похожа на логику mallocgcSmallNoscan, за исключением класса спана, структуры спана и структуры объектов класса размера внутри спана.
Спаны, используемые mallocgcSmallScanNoHeader, отличаются от спанов, используемых mallocgcSmallNoscan - они содержат специальные данные в конце, называемые битами кучи (см. раздел «Биты кучи и заголовок malloc»). Поскольку эти спаны должны удерживать место для хранения битов кучи, они вмещают меньше объектов класса размера, чем определено в таблице классов размера. Логика резервирования реализована в методе mheap.initSpan.
Структура объектов класса размера внутри спана, используемого mallocgcSmallScanHeader также отличается - каждый объект содержит заголовок malloc (см. раздел «Биты кучи и заголовок malloc»). Для того, чтобы объект пользователя и заголовок malloc помещались в объект класса размера, запрошенный size увеличивается на 8 байт перед округлением до ближайшего класса размера. Например, предположим, что запрашивается объект размером 636 байт, содержащий указатели. Обычно, такой объект будет соответстветствовать классу размера 28 (640 байт). Однако, поскольку объект содержит указатели, в него должен быть добавлен заголовок malloc, поэтому его размер увеличивается до 644 байт. Это передвигает выделение к классу размера 29 (704 байта).
Поскольку mcache и mcentral управляют только спанами класса размера до 32 КБ, крупные объекты (больше 32760 байт) выделяются напрямую из mheap (см. раздел «Выделение спана»). Спаны, вмещающие крупные объекты, также могут быть scan и noscan. В отличие от малых объектов, крупные не варьируются по классу спана: спаны scan всегда принадлежат классу 0, спаны noscan - 1.
При выделении крупного объекта, например, среза с 1 миллионом больших структур, ядро не выделяет (commit) физическую память сразу. Вместо этого, для выделения резервируется виртуальное адрессное пространство. Физические страницы выделяются только при первой записи в соответствующую область благодаря пейджингу по требованию.
Как упоминалось в статье «Планировщик Go», и код среды выполнения, и пользовательский код выполняются в потоках, управляемых ядром. Каждый поток обладает собственным стеком — непрерывным блоком памяти, содержащим кадры стека (stack frames), которые, в свою очередь, хранят параметры функций, локальные переменные и адреса возврата. Поскольку выделение переменных в стеке — это просто перемещение указателя стека (stack pointer), мы сфокусируемся на том, как стеки выделяются и управляются в Go.
В Go стек потока называется системным стеком (system stack), а стек горутины — просто стеком. Для управления контекстами выполнения среда выполнения представляет абстракции m (поток) и g (горутина). У каждого g есть поле stack для записи начального и конечного адресов ее стека. У каждого m есть специальная горутина g0, чей стек представляет собой системный стек. Среда выполнения использует g0 для операций, которые должны выполняться в системном стеке, а не в стеке горутины, таких как расширение и сокращение стека горутины.
Системный стек основного потока выделяется ядром при запуске процесса Go. Стеки других потоков выделяются либо ядром, либо средой выполнения Go, в зависимости от ОС и того, используется ли CGO. На Darwin и Windows системные стеки всегда выделяются ядром. На Linux это делает среда выполнения при условии, что не используется CGO.
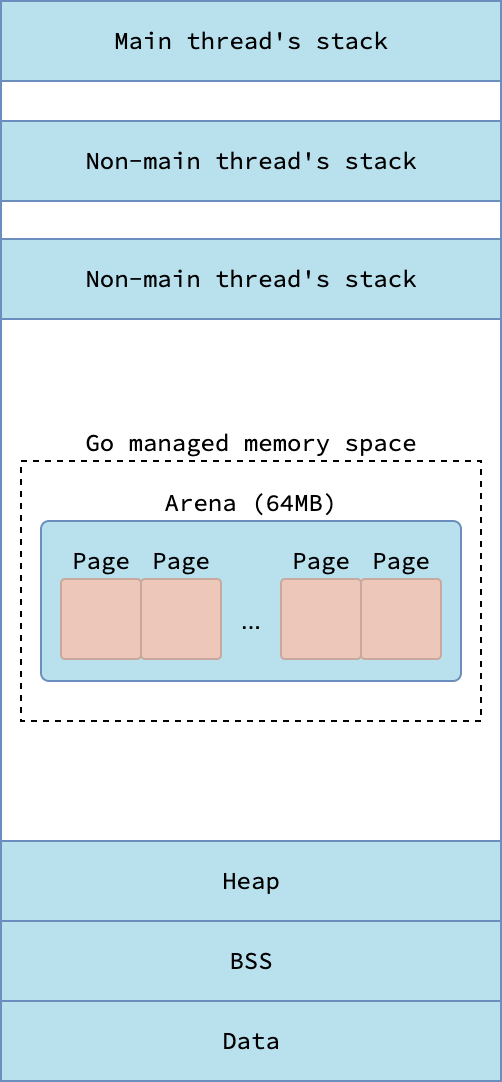
Структура виртуальной памяти процессов в Darwin/Windows
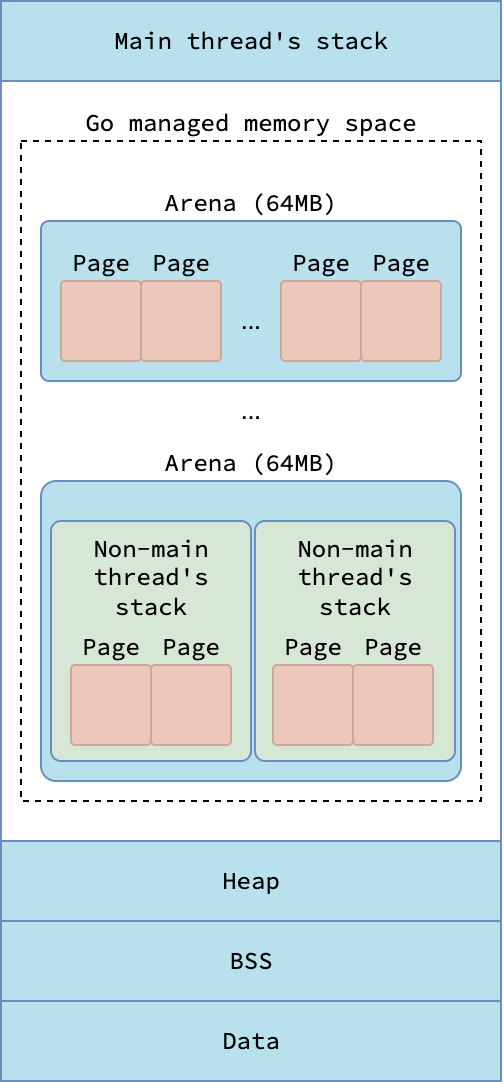
Структура виртуальной памяти процессов в Linux
Системный стек, выделяемый ядром, находится за пределами виртуального адрессного пространства, управляемого средой выполнения Go, а системный стек, выделяемый средой выполнения, создается внутри нее. Ядро обеспечивает отсутствие конфликтов между его системными стеками и памятью, которой управлет Go. Ядро выделяет системные стеки в диапазоне от 512 КБ до нескольких МБ, а системные стеки, выделяемые Go, имеют фиксированный размер в 16 КБ. Стеки горутин же начинаются с 2 КБ и могут расширяться или сокращаться динамически по мере необходимости.
Стеки, управляемые средой выполнения, будь то системные стеки или стеки горутин, размещаются в спанах, прямо как объекты кучи. Вы можете думать о стеке как о специальном виде объектов кучи, предназначенных для хранения локальных переменных и кадров вызовов функций в процессе выполнения кода среды выполнения или пользователя.
Как правило, стеки выделяются из mcache текущего процессора. При сборке мусора, при изменении количества процессоров, а также при отключении текущего потока от его процессора при выполнении системного вызова, стеки выделяются из глобальных пулов. Существует 2 таких пула: малый для стеков меньше 32 КБ и крупный для стеков, равных или больших 32 КБ.
Горутинам сначала выделяется малый стек (из малого пула). Когда стек горутины начинает превышать 32 КБ из-за вызова дополнительных функций или выделения дополнительных переменных стека, используется крупный пул. Мы вернемся к этому позже.
Пул малых стеков — это массив из четырех двусвязных списков mspan, где каждый спан содержит метаданные для блока виртуальной памяти. Все спаны в этом пуле принадлежат классу спана 0 и охватывают 4 смежные страницы, следовательно, каждый спан занимает до 32 КБ. Каждая сущность в массиве соответствует порядку стека (stack order), который определяет размер стека: порядок 0 → каждый стек имеет размер 2 КБ, порядок 1 → 4 КБ, порядок 2 → 8 КБ и порядок 3 → 16 КБ.
Почему стеки классифицируются по порядку и размеру именно таким образом? Причина в том, что стеки горутин представляют собой непрерывные области памяти, размер которых удваивается при увеличении. Мы вернемся к этому позже.
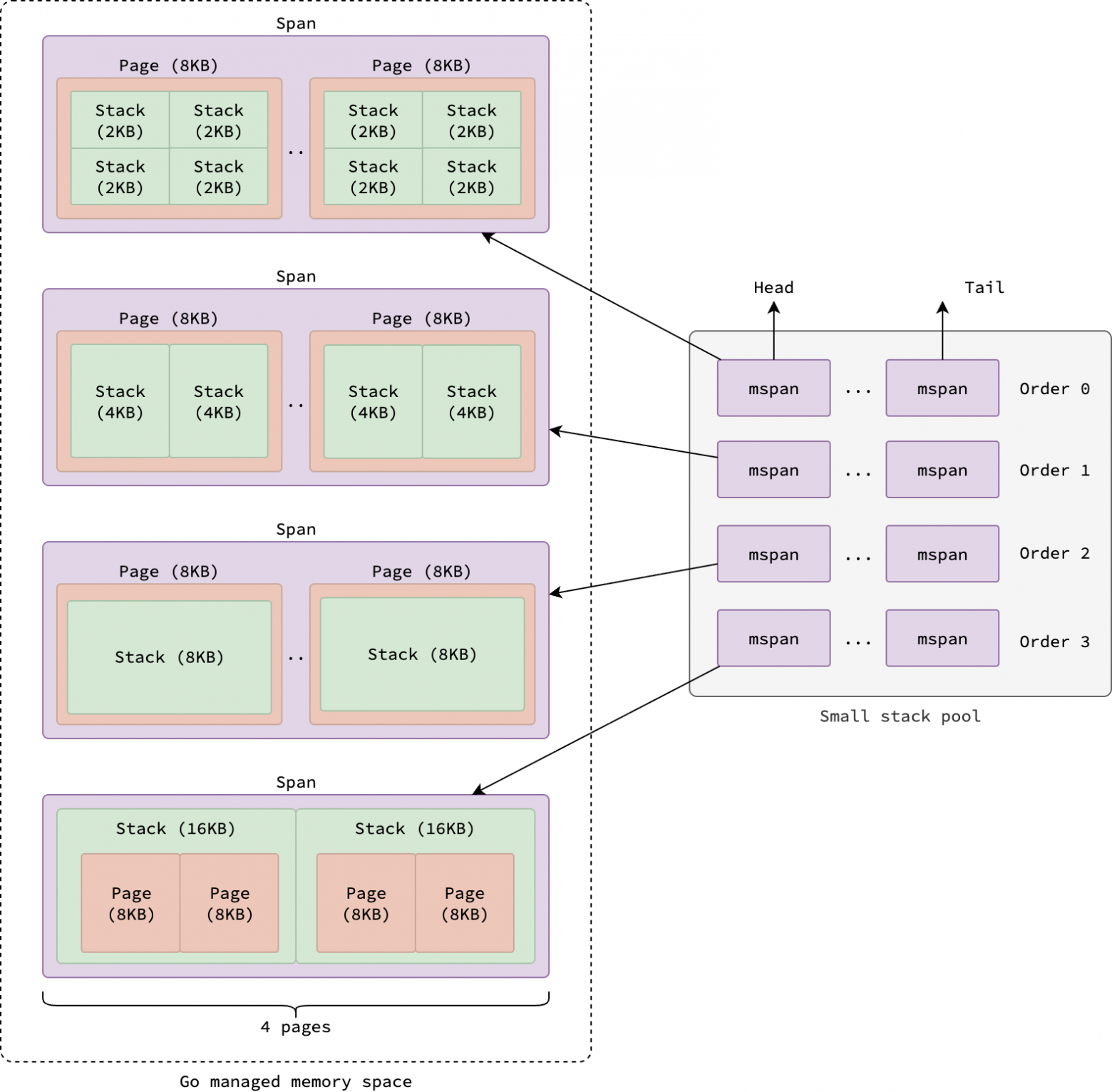
Когда запрашивается стек, размером менее 32 КБ, среда выполнения сначала определяет соответствующий порядок на основе запрошенного размера. Затем она проверяет начало связанного списка для этого порядка, чтобы найти доступный спан. Если доступного спана нет, она запрашивает его у mheap (см. раздел «Выделение спана») и разбивает его на стеки требуемого порядка. Как только спан готов, среда выполнения берет первый доступный стек, обновляет метаданные спана и возвращает стек.
Крупный пул стеков — это просто связный список стеков разных размеров, каждый стек содержится в классе спана 0. Когда запрашивается стек, равный или больший 32 КБ, из списка извлекается первый стек и возвращается. Если список пуст, новый спан запрашивается у mheap (см. раздел «Выделение спана»).
Обратите внимание, что поскольку пулы стеков являются глобальными, они могут быть доступны несколько потокам одновременно. Поэтому они защищены блокировкой мьютекса для обеспечения потокобезопасности в ущерб пропускной способности.
Для уменьшения конфликтов блокировок при выделении стека, каждый процессор поддерживает собственный кэш стеков (stack cache) в своем mcache. Подобно малому пулу стеков, кэш стеков представляет собой массив из четырех элементов, состоящий из односвязных списков свободных стеков, каждый элемент которого соответствует порядку стека.
При обработке запроса на выделение малого стека, среда выполнения сначала проверяет кэш стеков текущего процессора на наличие свободного стека. Если такого стека нет, она пополняет кэш, запрашивая несколько стеков из малого пула, кэширует их и возвращает первый. Крупные стеки не обслуживаются из кэша стеков, они всегда выделяются непосредственно из крупного пула.
Исторически в Go использовался сегментированный (segmented) стек. Каждая горутина начинает с малого стека. Если вызов функции требует больше стекового пространства, чем доступно в текущем, выделяется новый стек и связывается с предыдущим. После возврата функции, новый стек освобождается, а выполнение кода продолжается на предыдущем стеке. Этот процесс называется разделением стека (stack split).
Сниппет кода и рисунок ниже иллюстрируют сценарий, когда функция ingest обрабатывает данные из файла построчно, где кадры стека read разбросаны по двум стекам. Если указатель стека достигает определенного лимита (защиты стека (stack guard), о которой мы поговорим позже), вызовы read или process могут привести к разделению стека. Пожалуйста, обратите внимание, что стек горутины при таком подходе может состоять из несмежных областей памяти.
func ingest(path string) { ... for { line, err := read(file) // Приводит к разделению стека. if err == io.EOF { break } process(line) } ... }
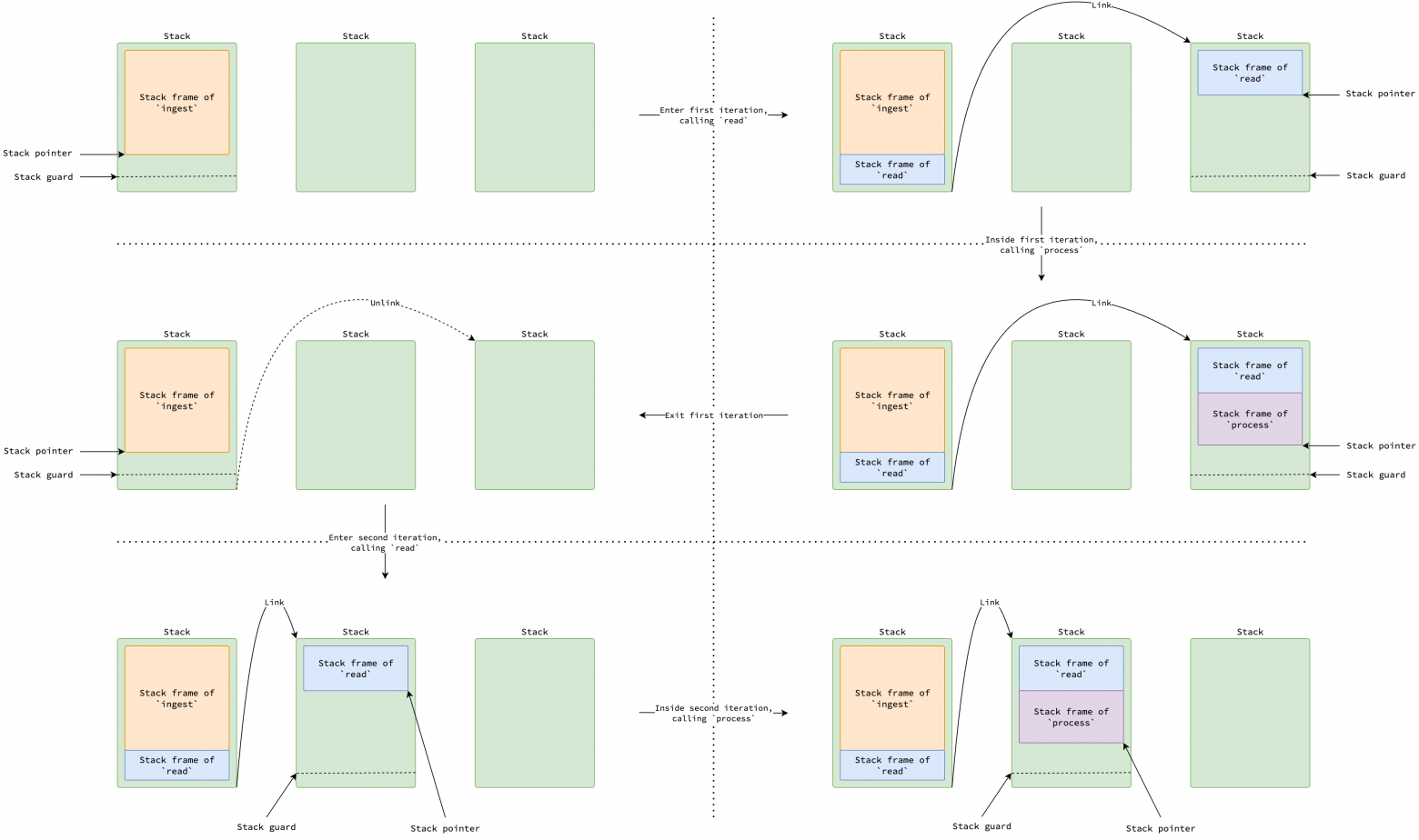
Однако у подхода с сегментированным стеком была проблема производительности, известная как проблема горячего разделения стека (hot stack split). Если функции требуется многократное выделение и освобождение стеков в рамках плотного цикла, весь процесс приводит к значительному снижению производительности. После возврата функции, вновь выделенный стек освобождается. Поскольку каждое разделение стека занимает 60 наносекунд, эта проблема приводит к значительным накладным расходам, так как происходит на каждой итерации цикла.
Один из способов избежать этой проблемы — добавить заполнение (padding) в стек функций, которые часто вызываются внутри циклов. Мы можем выделить фиктивные локальные переменные, чтобы увеличить размер стека и тем самым уменьшить вероятность разделения стека. Но с точки зрения разработки, это чревато ошибками и снижает читаемость кода.
Для решения проблемы горячего разделения стека, Go после версии 1.4 переходит к подходу, называемому непрерывными стеками (contiguous stacks). Когда необходимо увеличить стек горутины, выделяется новый стек, вдвое больший, чем текущий. Содержимое текущего стека копируется в новый, и горутина переключается на его использование.
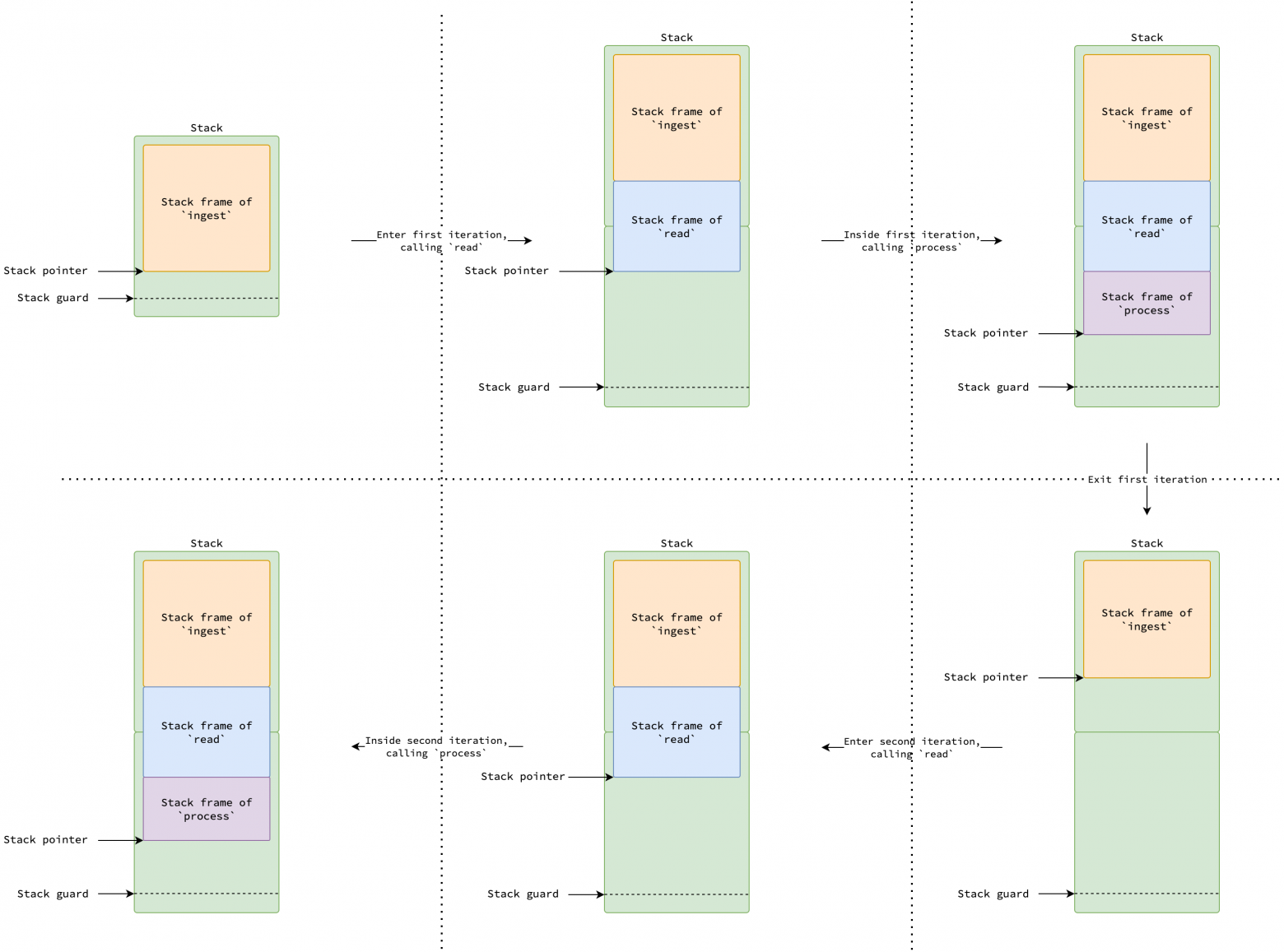
На рисунке выше показан непрерывный стек, который не уменьшается при недостаточном использовании (например, после завершения первой итерации). Такое поведение помогает смягчить проблему горячего разделения.
Однако, если стеки горутин никогда не уменьшаются, память может быть потрачена впустую, когда она значительно увеличивается во время пиковой нагрузки, но позже большая ее часть остается неиспользованной. Фактически, при использовании схемы непрерывного стека стек горутин уменьшается во время сборки мусора, а не при возврате функции. Если общий размер используемого стека меньше четверти текущего размера стека, выделяется новый стек, вдвое меньший, чем текущий. Содержимое текущего стека копируется в новый, и горутина переключается на его использование. См. shrinkstack.
Как упоминалось в статье «Планировщик Go», для увеличения стека в прологи функций добавляются некоторые проверки. Эта проверка, по сути, представляет собой инструкцию ЦП и потребляет ресурсы ЦП при выполнении. Для небольших часто вызываемых функций эти накладные расходы могут быть значительными. Для уменьшения этих расходов небольшие функции помечаются директивой //go:nosplit, которая указывает компилятору не вставлять проверки на увеличение размера стека в их прологи.
Не путайте. Split (разделение) в
//go:nosplitзвучит похоже на разделение стека в подходе с сегментированным стеком, но на самом деле это означает проверку на увеличение стека в подходе с непрерывным стеком.
При вызове функции указатель стека уменьшается на размер кадра стека функции. Затем он сравнивается с защитой стека (stack guard), определяющей необходимость расширения стека. Защита стека состоит из двух частей: StackNosplitBase и StackSmall. В Linux это размещает защиту на расстоянии 928 байт над дном стека — 800 байт для StackNosplitBase и 128 байт для StackSmall.
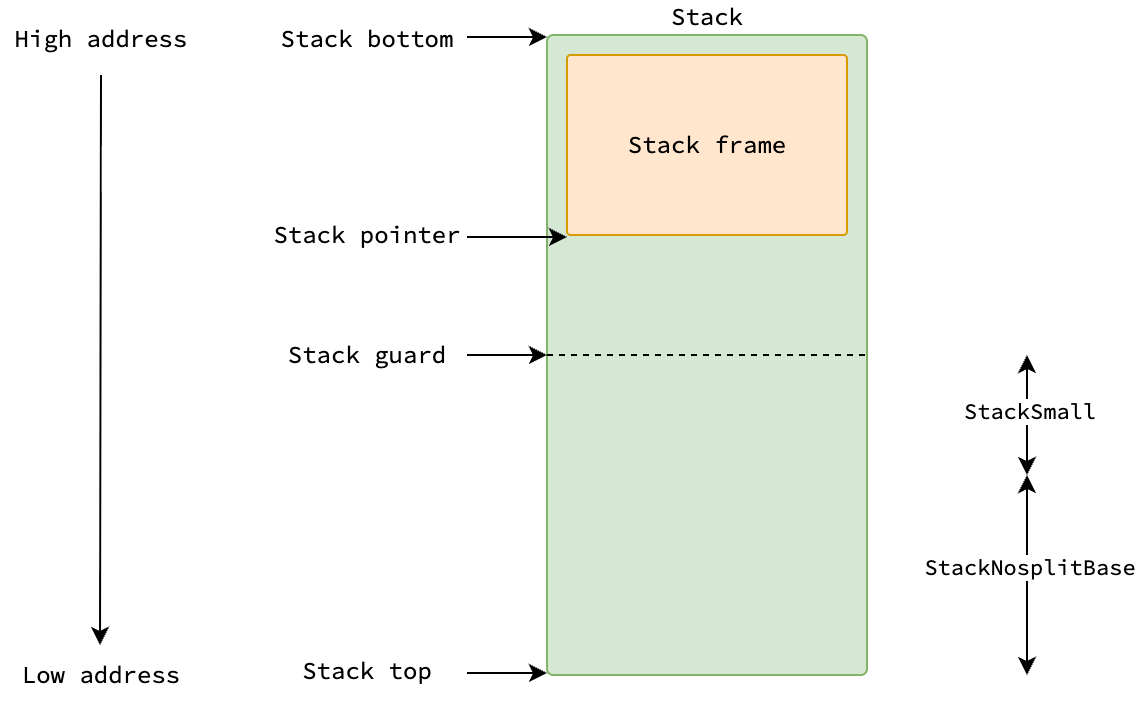
Но переполнение (overflow) означает, что указатель стека выходит за пределы стека, так почему указатель стека сравнивается с защитой стека, а не с его дном? Причины объясняются в этом комментарии к исходному кода среды выполнения Go. Позвольте мне изложить их простыми словами.
Во-первых, поскольку Go позволяет функциям не выполнять проверки увеличения стека, помечая их с помощью //go:nosplit, необходимо зарезервировать пространство, равное StackNosplitBase, чтобы обеспечить их безопасное выполнение без обращения к недействительным адресам. Например, весь кадр стека morestack, которая обрабатывает увеличение стека, должен помещаться в выделенном стеке.
Во-вторых, это является оптимизацией для небольших функций, кадр стека которых меньше StackSmall. При вызове таких функций Go не утруждает себя уменьшением указателя стека и его сравнением с защитой стека. Вместо этого, он просто проверяет, находится ли текущий указатель стека ниже защиты, экономя одну инструкцию ЦП на каждый вызов функции за счет пропуска корректировки указателя стека.
После завершения выполнения горутины, уменьшении стека горутины из-за избытка свободного пространства или выходе системного потока, управляемого Go, их стеки помечаются как повторно используемые (reusable). Если горутина подключена к процессору P, и кэш стека P достаточно маленький, ее стек возвращается в кэш стека P. Иначе, стек возвращается в глобальный пул: либо в малый с соответствующим порядком, либо в крупный, в зависимости от размера стека.
После возврата стека в глобальный пул, соответствующая страница памяти возвращается ядру, если не выполняется сборка мусора. См. этот комментарий к исходному коду среды выполнения.
Вы можете думать, что var n T всегда выделяется в стеке, а new(T) или &T{} всегда выделяет объект типа T в куче. Но это не всегда так. Рассмотрим несколько гипотетических примеров.
Рассмотрим следующую программу, которая определяет функцию getUserByID, извлекающую данные пользователя по его идентификатору. Предположительно, getUserByID выделяет структуру User в стеке, извлекает данные пользователя из базы данных и возвращает адрес этой структуры (указатель на нее).
func getUserByID(id int64) *User { var user User user = db.FindUserByID(id) return &user } func main() { var userID int64 = 1 var user *User = getUserByID(userID) var userAge = user.age user.age = userAge + 1 }
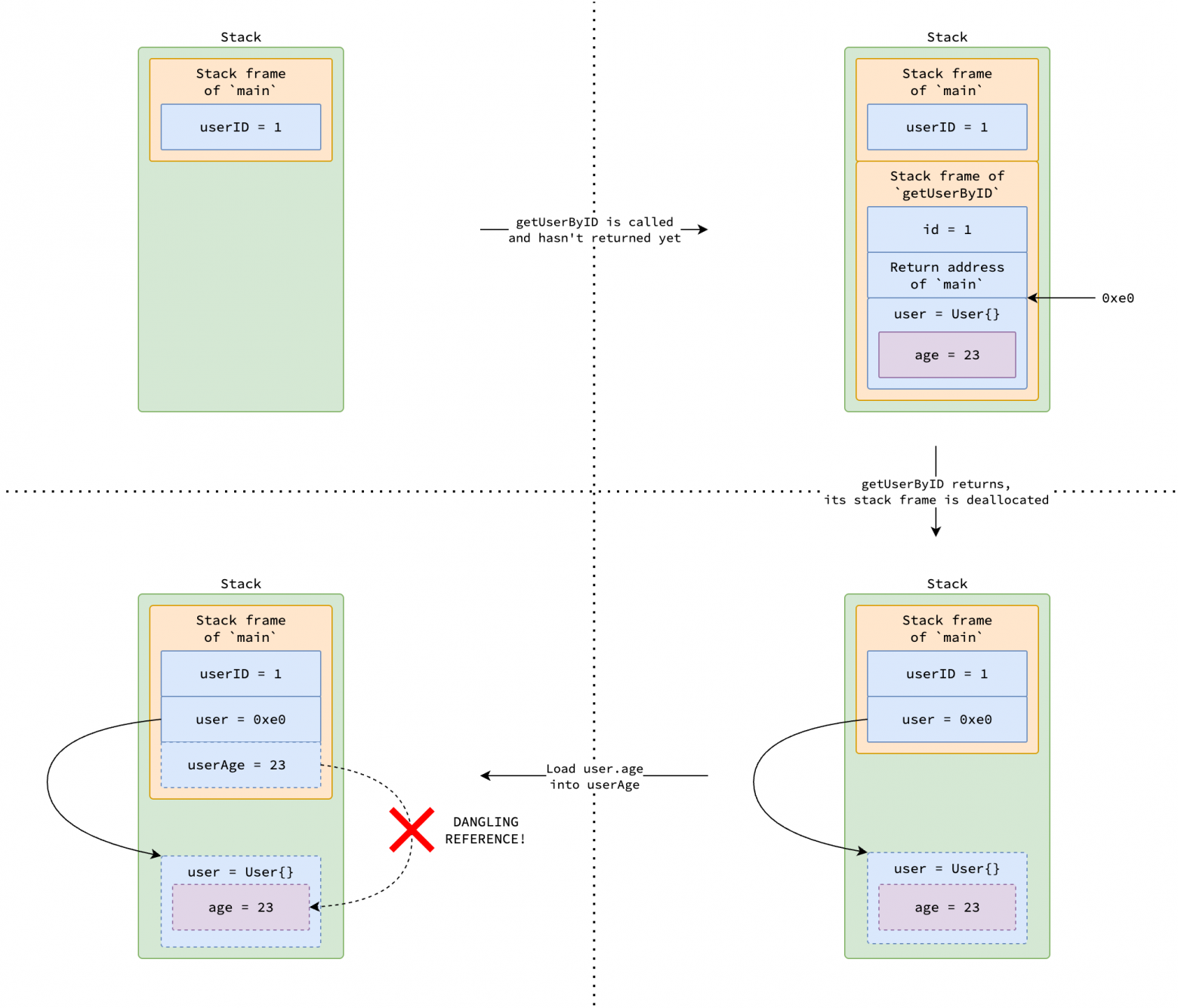
Проблема висячего указателя
При вызове функции getUserByID, переменная user помещается по адресу 0xe0 в ее кадре стека. После возврата функции, user по-прежнему удерживает 0xe0, но этот адрес больше не является валидным, поскольку кадр стека getUserByID был удален (popped). Когда main пытается получить user.age, происходит разыменование (deferencing) невалидного адреса, что приводит к проблеме висячего указателя и неопределенному поведению.
Для предотвращения таких проблем Go применяет технику под названием «анализ выхода» (escape analysis) в процессе компиляции. Анализ выхода определяет, может ли переменная (объявленная с помощью var n T, new(T), &T{} или make(T)) быть безопасно выделена в стеке горутины или должна «уйти» (escape) в кучу. Если выясняется, что на переменную ссылаются вне ее функции, она выделяется в куче, чтобы гарантировать безопасный доступ к ней после возврата функции.
В примере выше переменная user распознается, как «уходящая» в кучу, поскольку ее адрес возвращается и используется в main. Поэтому компилятор выделяет user в куче для предотвращения проблемы висячего указателя.
Анализ выхода также пытается держать переменные в стеке, даже если обычно они выделяются в куче (например, переменные, создаваемые с помощью new(T), &T{} или make(T)), до тех пор, пока они используются только внутри своей функции и потребляемая ими память не превышает MaxImplicitStackVarSize во время компиляции.
Вы можете убедиться в таком поведении, скомпилировав программу с настройкой -gcflags="-m", которая укажет компилятору напечатать решения по оптимизации, включая результаты анализа выхода.
package main type User struct { ID int64 } func newUser(id int64) *User { user := User{ID: id} return &user } func main() { _ = newUser(20250603) _ = make([]User, 100) } // $ go build -gcflags="-m" main.go // ./main.go:6:2: moved to heap: user // ./main.go:12:10: make([]User, 100) does not escape
Мы видим, что переменная user перемещена в кучу, поскольку она используется в функции main после возврата функции newUser, а срез, созданный с помощью make([]User, 100) оставлен в стеке, поскольку он используется только в main и его размер меньше, чем MaxImplicitStackVarSize.
Теперь, когда мы разобрались, как Go выделяет память для объектов в куче и стеках, давайте рассмотрим несколько реальных примеров, чтобы понять, как Go выделяет память на практике и как оптимизировать выделение памяти в куче.
Как вы можете знать, срез в Go — это дескриптор, содержащий указатель на базовый (underlying) массив, его длину (length) и емкость (capacity). При создании нового среза с помощью make([]T, length, capacity), компилятор заменяет ключевое слово make на вызов makeslice в среде выполнения. makeslice затем вызывает mallocgc с размером, равным capacity*sizeof(T) для выделения базового массива в куче. Другим словами, capacity отслеживает размер базового массива, а length — количество используемых элементов массива.
Функция append добавляет новые элементы в конец среза, увеличивая его длину. Если новая длина превышает текущую емкость, append вызывает mallocgc для выделения нового вдвое большего базового массива, копирует существующие элементы в новый массив и обновляет дескриптор среза ссылкой на него.
Срез в Go можно повторно «нарезать» (reslice) с помощью синтаксиса [start:end]. Повторная нарезка создает новый заголовок среза, который указывает на поддиапазон (subrange) элементов в том же базовом массиве, что и оригинальный срез. Важно: эта операция не копирует данные и не выделяет дополнительную память — новый срез просто повторно использует существующий массив. См. «Введение в срезы».
Мы можем использовать повторную нарезку для оптимизации выделения памяти в куче, повторно используя базовый массив среза вместо создания нового. Рассмотрим следующую программу, которая обрабатывает CSV-файл построчно, причем, каждая строка может содержать большое количество полей:
package main import ( "bufio" "os" ) func parse(line string) []string { start := 0 var row []string for i := 0; i < len(line); i++ { if line[i] == ',' { row = append(row, line[start:i]) start = i + 1 } } row = append(row, line[start:]) return row } func process(row []string) { // Обрабатываем строку. } func main() { file, _ := os.Open("input.csv") defer file.Close() scanner := bufio.NewScanner(file) for scanner.Scan() { line := scanner.Text() row := parse(line) process(row) } }
Поскольку функция parse создает пустой срез для каждой строки, она выделяет новый базовый массив в куче при каждом вызове. К тому же, поскольку функция append вызывается для каждого поля в строке, это может привести к множественным выделениям в куче, если количество полей превысит начальную емкость базового массива. Тот же путь (path) в mallocgc выполняется повторно, приводя к множеству лишних выделений кучи.
Оптимизируем программу путем повторного использования базового массива среза row. Путем повторной нарезки с помощью row[:0] мы сбрасываем длину среза, сохраняя емкость неизменной. Выделения кучи происходят только при первом вызове parse, т.е. только при разборе первой строки. Для файла CSV, содержащего 1024 поля и 1000000 строк, количество выделений кучи уменьшается с 1000000*log₂(1024)=10⁷ до log₂(1024)=10 благодаря одной только повторной нарезке.
package main import ( "bufio" "os" ) func parse(line string, row []string) []string { start := 0 for i := 0; i < len(line); i++ { if line[i] == ',' { row = append(row, line[start:i]) start = i + 1 } } row = append(row, line[start:]) return row } func process(row []string) { // Обрабатываем строку. } func main() { file, _ := os.Open("input.csv") defer file.Close() var row []string scanner := bufio.NewScanner(file) for scanner.Scan() { line := scanner.Text() row = row[:0] // Повторно используем базовый массив. row = parse(line, row) process(row) } }
Недавно в пакет iter был сделан коммит, который объединил несколько скалярных переменных в единую структуру.
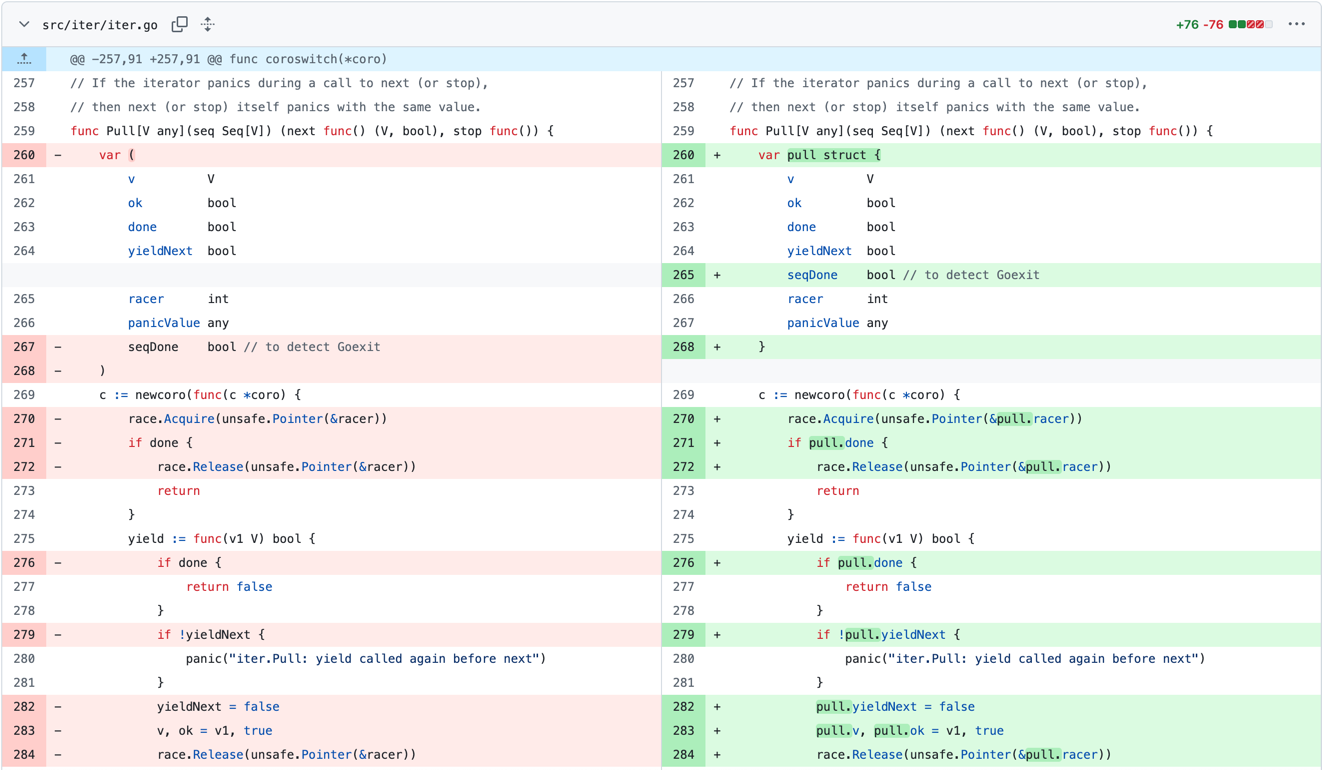
Изначально, поскольку эти 7 переменных выходят за пределы области видимости функции, все они выделяются в куче отдельно, что приводит к 7 вызовам функции mallocgc. Хотя некоторые из этих переменных меньше 16 байт и могут быть выделены с помощью распределителя памяти крошечных объектов, накладные расходы от 7 вызовов функции mallocgc все равно значительны, если часто вызывается метод Pull.
Группировка этих переменных в единую структуру позволяет выделить структуру в куче всего одним вызовом mallocgc, что повышает эффективность выделения памяти. Однако у такого подхода есть и недостаток: он связывает несвязанные объекты, что препятствует сборщику мусора освобождать отдельные ненужные объекты. Тем не менее, в данном конкретном случае, поскольку большинство этих переменных используются вместе, компромисс приемлем.
Результаты бенчмарка в исходном запросе на слияние (скопированном ниже) показывают, что количество выделений памяти в куче сократилось с 11 до 5. Разница соответствует приведенному выше анализу, где 7 переменных сгруппированы в одну структуру, что позволяет сэкономить 6 вызовов функции mallocgc. Кроме того, потребление памяти и время выделения памяти сократились примерно на треть.
│ /tmp/bench.old │ /tmp/bench.new │ │ sec/op │ sec/op vs base │ Pull-12 218.6n ± 7% 146.1n ± 0% -33.19% (p=0.000 n=10) │ /tmp/bench.old │ /tmp/bench.new │ │ B/op │ B/op vs base │ Pull-12 288.0 ± 0% 176.0 ± 0% -38.89% (p=0.000 n=10) │ /tmp/bench.old │ /tmp/bench.new │ │ allocs/op │ allocs/op vs base │ Pull-12 11.000 ± 0% 5.000 ± 0% -54.55% (p=0.000 n=10)
В некоторых приложениях часто создаются и удаляются многочисленные недолговечные невладеющие состоянием (stateless) объекты одного типа. Типичным примером является объект pp, который широко используется в пакете fmt для форматирования строк в часто используемых функциях, таких как Fprintf и Sprintf.
Если эти функции выделяют новый объект pp, используют его для форматирования, а затем удаляют, то при записи 10000 логов в секунду каждую секунду будет выделяться и сканироваться сборщиком мусора 10000 объектов pp. Такая схема приводит к значительным накладным расходам из-за частого выделения памяти в куче и сборки мусора.
Для уменьшения этих накладных расходов Go предоставляет sync.Pool - механизм кэширования и повторного использования объектов одного типа. При обработке запроса Get, sync.Pool сначала ищет свободный объект в своем пуле. Если не находит, вызывает для его создания пользовательскую функцию New, которая в конечном счете вызывает mallocgc для выделения объекта в куче. После освобождения объекта, он может быть возвращен в пул с помощью метода Put. За счет повторного использования объектов sync.Pool снижается как количество выделений кучи, так и количество объектов, подлежащих сканированию сборщиком мусора, что повышает производительность.
sync.Pool спроектирован быть свободным от блокировок и эффективным в условиях высокой паралелльности. Для достижения этого используется техника под названием «закрепление» (pinning), которая предотвращает вытеснение (preempting) горутины при извлечении или добавлении объекта в пул. Поскольку sync.Pool является локальным для каждого процессора, закрепление обеспечивает принадлежность горутины тому же процессору во время выполнения операции.
Распределитель памяти Go разработан с четкой целью — быть эффективным в приложениях с высоким уровнем параллелизма. Благодаря многоуровневой стратегии распределения памяти между mheap, mcentral и mcache, среда выполнения балансирует между глобальной координацией и кэшированием на уровне отдельных процессоров, минимизируя конфликты блокировок и обеспечивая быстрое выделение памяти. Стеки, хотя и управляются иначе, чем объекты в куче, следуют аналогичным принципам эффективного распределения и адаптивного роста.
Для большинства Go-разработчиков эти детали остаются скрытыми за простыми конструкциями, вроде &T{}, new(T) и make(T). Тем не менее, понимание внутреннего устройства дает ценную информацию о том, почему одни шаблоны работают лучше других, как сборщик мусора взаимодействует с выделением памяти и на какие компромиссы идет среда выполнения для достижения высокой скорости параллельной обработки в масштабе. При создании и оптимизации приложений на Go помните, что каждая созданная вами переменная или горутина в конечном итоге поддерживается этими механизмами.
Надеюсь, эти знания пригодятся вам для написания более эффективных и надежных программ на Go.
sobyte.net. Go Memory Allocation, Go Stack Management
Michael Knyszek, Austin Clements. Scaling the Go Page Allocator
Dmitry Vyukov. Go Scheduler: Implementing Language with Lightweight Concurrency

Перед оплатой в разделе «Бонусы и промокоды» в панели управления активируйте промокод и получите кэшбэк на баланс.