http://habrahabr.ru/post/250811/
Привет, хабр!

В прошлый раз мы рассмотрели замечательный инструмент
Vowpal Wabbit, который бывает полезен в случаях, когда приходится обучаться на выборках, не помещающихся в оперативную память. Напомним, что особенностью данного инструмента является то, что он позволяет строить в первую очередь линейные модели (которые, к слову, имеют хорошую обобщающую способность), а высокое качество алгоритмов достигается за счет отбора и генерации признаков, регуляризации и прочих дополнительных приемов. Сегодня рассмотрим инструмент, который более популярен и предназначен для обработки больших обьемов данных —
Apache Spark.
Не будем вдаваться в подробности истории возникновения данного инструмента, а также его внутреннего устройства. Сосредоточимся на практических вещах. В этой статье мы рассмотрим базовые операции и основные вещи, которые можно делать в Spark'е, а в следующий раз рассмотрим подробнее библиотеку
MlLib машинного обучения, а также
GraphX для обработки графов (автор данного поста в основном для этого и использует данный инструмент — это как раз тот случай, когда зачастую граф необходимо держать в оперативной памяти на кластере, в то время как для машинного обучения очень часто достаточно Vowpal Wabbit'а). В этом мануале не будет много кода, т.к. рассматриваются основные понятия и философия Spark'а. В следующих статьях (про MlLib и GraphX) мы возьмем какой-нибудь датасет и подробнее рассмотрим Spark на практике.
Сразу скажем, что нативно Spark поддерживает
Scala,
Python и
Java. Примеры будем рассматривать на Python, т.к. очень удобно работать непосредственно в
IPython Notebook, выгружая небольшую часть данных из кластера и обрабатывая, например, пакетом
Pandas — получается довольно удобная связка
Итак, начнем с того, что основным понятием в Spark'е является
RDD (Resilient Distributed Dataset), который представляет собой Dataset, над которым можно делать преобразования двух типов (и, соответственно, вся работа с этими структурами заключается в последовательности этих двух действий).
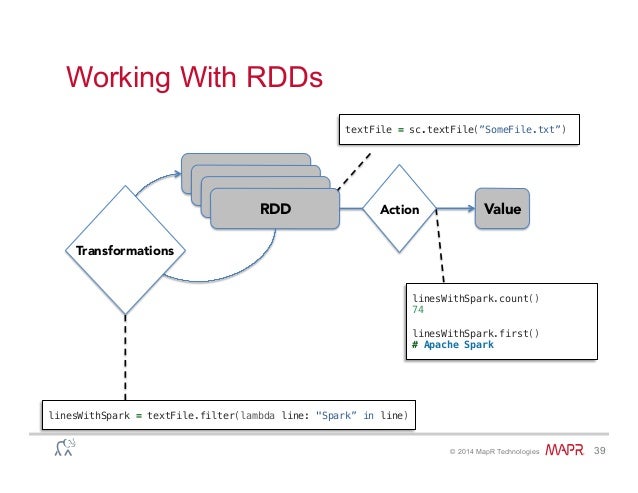
Трансформации
Результатом применения данной операции к RDD является новый RDD. Как правило, это операции, которые каким-либо образом преобразовывают элементы данного датасета. Вот неполный самых распространенных преобразований, каждое из которых возвращает новый датасет (RDD):
.map(function) — применяет функцию function к каждому элементу датасета
.filter(function) — возвращает все элементы датасета, на которых функция function вернула истинное значение
.distinct([numTasks]) — возвращает датасет, который содержит уникальные элементы исходного датасета
Также стоит отметить об операциях над множествами, смысл которых понятен из названий:
.union(otherDataset).intersection(otherDataset).cartesian(otherDataset) — новый датасет содержит в себе всевозможные пары (A,B), где первый элемент принадлежит исходному датасету, а второй — датасету-аргументу
Действия
Действия применяются тогда, когда необходимо материализовать результат — как правило, сохранить данные на диск, либо вывести часть данных в консоль. Вот список самых распространенных действий, которые можно применять над RDD:
.saveAsTextFile(path) — сохраняет данные в текстовый файл (в hdfs, на локальную машину или в любую другую поддерживаемую файловую систему — полный список можно посмотреть в документации)
.collect() — возвращает элементы датасета в виде массива. Как правило, это применяется в случаях, когда данных в датасете уже мало (применены различные фильтры и преобразования) — и необходима визуализация, либо дополнительный анализ данных, например средствами пакета Pandas
.take(n) — возвращает в виде массива первые n элементов датасета
.count() — возвращает количество элементов в датасете
.reduce(function) — знакомая операция для тех, кто знаком с
MapReduce. Из механизма этой операции следует, что функция function (которая принимает на вход 2 аргумента возвращает одно значение) должна быть обязательно коммутативной и ассоциативной
Это основы, которые необходимо знать при работе с инструментом. Теперь немного займемся практикой и покажем, как загружать данные в Spark и делать с ними простые вычисления
При запуске Spark, первое, что необходимо сделать — это создать
SparkContext (если говорить простыми словами — это обьект, который отвечает за реализацию более низкоуровневых операций с кластером — подробнее — см. документацию), который при запуске
Spark-Shell создается автоматически и доступен сразу (обьект
sc)
Загрузка данных
Загружать данные в Spark можно двумя путями:
а). Непосредственно из локальной программы с помощью функции
.parallelize(data)localData = [5,7,1,12,10,25]
ourFirstRDD = sc.parallelize(localData)
б). Из поддерживаемых хранилищ (например, hdfs) с помощью функции
.textFile(path)ourSecondRDD = sc.textFile("path to some data on the cluster")
В этом пункте важно отметить одну особенность хранения данных в Spark'e и в тоже время самую полезную функцию
.cache() (отчасти благодаря которой Spark стал так популярен), которая позволяет закэшировать данные в оперативной памяти (с учетом доступности последней). Это позволяет производить итеративные вычисления в оперативной памяти, тем самым избавившись от IO-overhead'а. Это особенно важно в контексте машинного обучения и вычислений на графах, т.к. большинство алгоритмов итеративные — начиная от градиентных методов, заканчивая такими алгоритмами, как
PageRankРабота с данными
После загрузки данных в RDD мы можем делать над ним различные трансформации и действия, о которых говорилось выше. Например:
Посмотрим первые несколько элементов:
for item in ourRDD.top(10):
print item
Либо сразу загрузим эти элементы в Pandas и будем работать с DataFrame'ом:
import pandas as pd
pd.DataFrame(ourRDD.map(lambda x: x.split(";")[:]).top(10))
Вообще, как видно, Spark настолько удобен, что дальше, наверное нет смысла писать различные примеры, а можно просто оставить это упражнение читателю — многие вычисления пишутся буквально в несколько строк
Напоследок, покажем лишь пример трансформации, а именно, вычислим максимальный и минимальный элементы нашего датасета. Как легко догадаться, сделать это можно, например, с помощью функции
.reduce():
localData = [5,7,1,12,10,25]
ourRDD = sc.parallelize(localData)
print ourRDD.reduce(max)
print ourRDD.reduce(min)
Итак, мы рассмотрели основные понятия, необходимые для работы с инструментом. Мы не рассматривали работу с SQL, работу с парами
<ключ, значение> (что делается легко — для этого достаточно сначала применить к RDD, например, фильтр, чтобы выделить, ключ, а дальше — уже легко пользоваться встроенными функциями, вроде
sortByKey,
countByKey,
join и др.) — читателю предлагается ознакомиться с этим самостоятельно, а при возникновении вопросов — написать в комментарии. Как уже было отмечено, в следующий раз мы рассмотрим подробно библиотеку MlLib и отдельно — GraphX