http://habrahabr.ru/post/241103/
Недавно в нашем проекте потребовалось настроить мониторинг качества кода. Качество кода — понятие субъективное, однако давным-давно придумали множество метрик, позволяющих провести мало-мальски количественный анализ. К примеру, цикломатическая сложность или индекс поддерживаемости (maintainability index). Измерение подобного рода показателей — обычное дело для языков вроде Java или C++, однако (складывается впечатление) в питоньем сообществе редко когда кто-то об этом задумывается. К счастью, существует замечательный
radon с
xenon-ом, который быстро и качественно вычисляет упомянутые выше метрики и даже некоторые другие. Конечно, для профессиональных enterprise инструментов маловато, но все необходимое присутствует.
Кроме вычисления метрик, бывает также полезно провести анализ зависимостей. Если в проекте задекларирована архитектура, то между отдельными частями должны существовать определенные связи. Самый частый пример: приложение построено вокруг библиотеки, предоставляющей API, и весьма нежелательно выполнять действия в обход этого API. Другими словами, нехорошо ioctl-ить в ядро когда libc есть. Для питона есть несколько пакетов, строящих граф зависимостей между модулями, и
snakefood показался мне самым удачным.
Помимо анализа зависимостей, не менее полезно определять копипасту, особенно, если в проекте задействованы джуниоры или другие люди, любящие «срезать углы болгаркой». Об этом собственно и пойдет речь в статье.
clonedigger
Наверняка науке известны коммерческие инструменты определения копипасты для Python, но основным критерием выбора была бесплатность. Первая же ссылка в поисковике вывела на
clonedigger. За этот замечательный пакет говорим спасибо
peter_bulychev. В
статье 6-летней давности можно посмотреть
презентацию, в ней находится описание алгоритма и пересказывать его смысла нет. Самое важное с прикладной точки зрения: pip install clonedigger, поддержки тройки нет, 3 года не обновлялся, есть
дохленький форк на гитхабе. Ну и ладно! На 2.7.8 работает нормально, а мой проект всё равно насквозь пропитан six-ом.
Диггер представляет собой одноименную консольную утилиту, которой на вход подаются опции и путь к корню подопытного проекта. Умеет выплёвывать машиночитаемый XML по схеме
CPD, если передать --cpd-output. Тем самым делает счастливым Violations Plugin в Jenkins-е.
Скрытый текстЕсли посмотреть список языков, с которыми работает «don't shoot the messenger», в глаза сразу бросается несправедливость: всякие PHP есть, а Python-а нет! И так со многими инструментами. Отсюда и ремарка в начале статьи про сообщество.
Также у clonedigger есть супер крутая фича «не сканировать избранные директории» (--ignore-dir), позволяющая
не краснеть за говнокод в тестах исключить из анализа сторонний код. Правда, реализована она самобытно:
def walk(dirname):
for dirpath, dirs, files in os.walk(file_name):
dirs[:] = (not options.ignore_dirs and dirs) or [d for d in dirs if d not in options.ignore_dirs]
...
Пояснение: исключаются не относительные пути, а имена. Передавая, к примеру, «ext», вы исключите разом и «root/ext», и «root/foo/bar/ext», и «root/tests/ext» — пришлось потратить некоторое время, чтобы это осознать, и даже залезть в исходники.
Итак, после завершения работы диггера с нужной опцией появится XML с найденными клонами. Структура примерно такова:
<pmd-cpd>
<duplication lines="13" tokens="40">
<file line="853" path="tornado/auth.py"/>
<file line="735" path="tornado/auth.py"/>
<codefragment>
<![CDATA[
def _on_friendfeed_request(self, future, response):
if response.error:
future.set_exception(AuthError(
"Error response %s fetching %s" % (response.error,
response.request.url)))
return
future.set_result(escape.json_decode(response.body))
def _oauth_consumer_token(self):
self.require_setting("friendfeed_consumer_key", "FriendFeed OAuth")
self.require_setting("friendfeed_consumer_secret", "FriendFeed OAuth")
return dict(
key=self.settings["friendfeed_consumer_key"],
secret=self.settings["friendfeed_consumer_secret"])
]]>
</codefragment>
</duplication>
<duplication>
...
</pmd-cpd>
Здорово, когда можно в любой момент получить список клонов в CI, но для мониторинга, пожалуй, недостаточно. Нет пресловутой картинки, глядя на которую, менеджер проекта сможет составить мнение о масштабе бедствия.
Визуализация
Представляю на суд общественности
скрипт для отображения величины взаимной копипасты в модулях проекта. На вход подаются имена двух файлов — XML от clonedigger и создаваемое изображение. Зависимости: matplotlib, scipy, xmltodict, cairo. Алгоритм работы:
- Распарсить cpd
- Построить матрицу величины клонирования между модулями
- Кластеризовать модули по обратной матрице (т.е., по матрице расстояния между файлами)
- Применить найденный порядок следования модулей к исходной матрице
- Долго и нудно рисовать на matplotlib-е
Парсинг
with open(sys.argv[1], 'r') as fin:
data = xmltodict.parse(fin.read())
Парсинг по сути выполняется в одну строку моим любимым xmltodict-ом: никакого SAX, никаких знаний xml, это даже проще чем XDocument в шарпе. Если xmltodict встречает несколько одинаковых тегов на одном уровне, то он создает массив, а атрибуты отличаются от вложенных элементов "@" в в начале имени. Конечно, это не самый быстрый метод и не самый универсальный, но в данном случае работает на все сто.
Матрица клонов
Далее получаем список уникальных путей и строим индекс:
files = list(sorted(set.union({dup['file'][i]['@path']
for dup in data['pmd-cpd']['duplication']
for i in (0, 1)})))
findex = {f: i for i, f in enumerate(files)}
Пробегаем по распарсенному дереву и строим треугольную матрицу, в ячейках которой лежат просуммированные количества строк в найденных клонах:
mat = numpy.zeros((len(files), len(files)))
for dup in data['pmd-cpd']['duplication']:
mat[tuple(findex[dup['file'][i]['@path']] for i in (0, 1))] += \
int(dup['@lines'])
Прибавляем к нашей треугольной матрице такую же, но транспонированную, тем самым создаем полноценную матрицу:
mat += mat.transpose()
Кластеризация
Если прямо сейчас нарисовать нашу матрицу, будет не очень понятно, какие группы файлов копируют друг друга. В случае единичных пар все ясно, но клоны имеют мерзкое свойство тащиться сразу во много модулей одновременно, например, из-за некачественного рефакторинга. Поэтому лучше сначала сгруппировать файлы по похожести между собой, формируя квадратные попарно непересекающиеся области. Строго говоря, если модуль A похож на модуль B, а B похож на C, то это еще совсем не значит, что A похож на C (отношение не транзитивно), однако
очень часто это именно так.
Строим матрицу расстояний как обратную к матрице клонирования, не забывая, что делить на ноль нельзя, затем кластеризуем:
mat[mat == 0] = 0.001
order = leaves_list(linkage(1 / mat))
Вот за это я люблю scipy! Одна строка, а как много внутри! Кстати, вместо linkage можно попробовать и другой метод из
доступных. Ах да, кластеризация должна быть иерархичной (см., например,
вот эту статью что это такое), т.к. мы хотим упорядочить файлы (функция leaves_list). Если захотите сами поиграться, удобно использовать dendrogram для отображения результирующей иерархии.
Применяем найденный порядок к именам файлов и матрице:
mat = mat[numpy.ix_(order, order)]
files = [files[i] for i in order]
Изобразительное искусство
Я не спец по научной визуализации, и код собрал на коленке, используя старый добрый
stackoverflow driven development. Для начала выберем палитру в градациях красного и белого:
cdict = {'red': ((0.0, 1.0, 1.0),
(1.0, 1.0, 1.0)),
'green': ((0.0, 1.0, 1.0),
(1.0, 0.0, 0.0)),
'blue': ((0.0, 1.0, 1.0),
(1.0, 0.0, 0.0))}
reds = LinearSegmentedColormap('Reds', cdict)
Можно выбрать любую другую из коллекции matplotlib.cm. Дальше создаем фигуру и оси и долго их полируем напильником:
fig = pyplot.figure()
ax = fig.add_subplot(111)
ax.pcolor(mat, cmap=reds)
# uncomment the following to remove the frame around the map
# ax.set_frame_on(False)
ax.set_xlim((0, len(files)))
ax.set_ylim((0, len(files)))
ax.set_xticks(numpy.arange(len(files)) + 0.5, minor=False)
ax.set_yticks(numpy.arange(len(files)) + 0.5, minor=False)
ax.invert_yaxis()
ax.xaxis.tick_top()
ax.set_xticklabels([os.path.basename(f) for f in files], minor=False,
rotation=90)
ax.set_yticklabels([os.path.basename(f) for f in files], minor=False)
ax.grid(False)
ax.set_aspect(1)
for t in ax.xaxis.get_major_ticks():
t.tick1On = False
t.tick2On = False
for t in ax.yaxis.get_major_ticks():
t.tick1On = False
t.tick2On = False
Как видите, имена файлов берутся базовые, без пути, т.к. иначе для ветвистых проектов не будут помещаться в области для рисования. Ок, осталось совсем мало: задать адекватный размер и собственно выполнить рендер:
fig_size = 16 * len(files) / 55
fig.set_size_inches(fig_size, fig_size)
pyplot.savefig(sys.argv[2], bbox_inches='tight', transparent=False, dpi=100,
pad_inches=0.1)
Размер подобран на глазок, чтобы имена файлов не слипались. Формат файла определяется по его расширению автоматически, как минимум, cairo поддерживает png и svg.
Тестирование
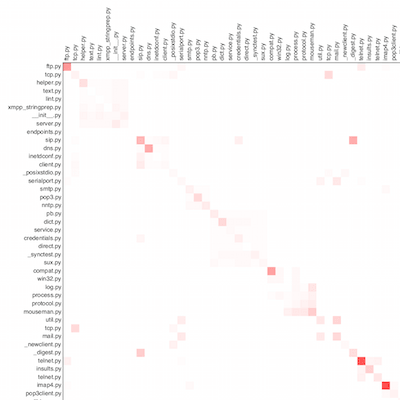
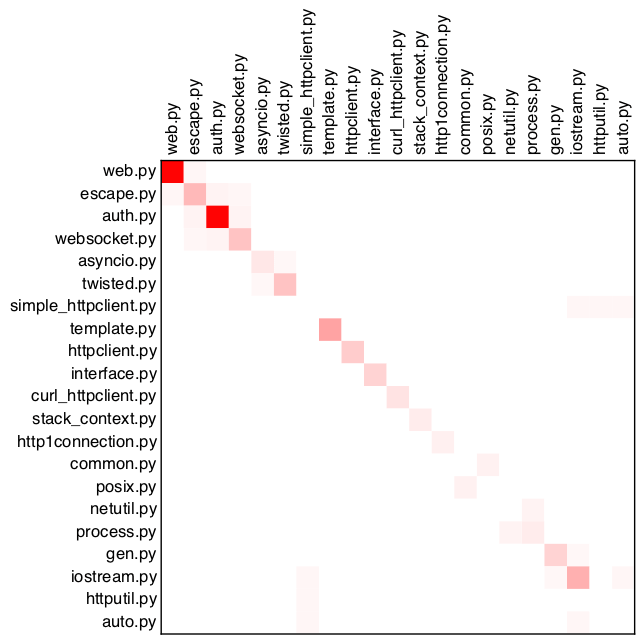
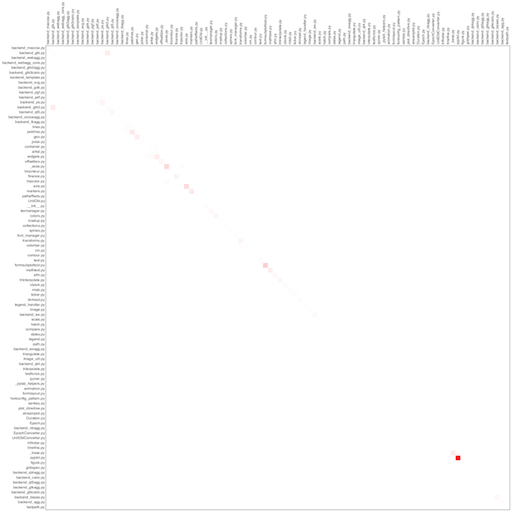
Для демонстрации я взял три открытых проекта: tornado, matplotlib и twisted. Из анализа были исключены тесты. Кстати, КДПВ — левый верхний угол из twisted.
tornado
matplotlib
twisted
Как видим, у всех проектов прослеживается главная диагональ, т.е. чаще всего файлы копируют самих себя. Возможно, это связано с особенностями языка, возможно, с отсутствием макросов. Тем не менее, яркие красные точки заслуживают пристального внимания и являются кандидатами на рефакторинг — доказано нашими собственными проектами.
Буду рад замечаниям и исправлениям, спасибо за внимание.



