http://habrahabr.ru/company/yandex/blog/234335/
Привет! Меня зовут Андрей Степачев. В конце прошлого года я выступил перед коллегами с небольшим рассказом о том, что такое
ZooKeeper, и как его можно использовать. Доклад изначально был рассчитан на широкий круг аудитории и может быть полезен и разработчикам, и админам, желающим разобраться, как все это примерно работает.
Начнем, пожалуй, с истории появления ZooKeeper. Сначала, как известно, в Google написали сервис
Chubby для управления своими серверами и их конфигурацией. Заодно решили задачу с распределенными блокировками. Но у Chubby была одна особенность: для захвата локов необходимо открывать объект, потом закрывать. От этого страдала производительность. В Yahoo посчитали, что им нужен инструмент, при помощи которого они могли бы строить различные системы для конфигураций своих кластеров. Именно в этом основная цель ZooKeeper — хранение и управление конфигурациями определенных систем, а локи получились как побочный продукт. В итоге вся эта система была создана для построения различных примитивных синхронизаций клиентским кодом. В самом ZooKeeper явных понятий подобных очередям нет, все это реализуется на стороне клиентских библиотек.
Основа ZooKeeper — виртуальная файловая система, которая состоит из взаимосвязанных узлов, которые представляют собой совмещенное понятие файла и директории. Каждый узел этого дерева может одновременно хранить данные и иметь подчиненные узлы. Помимо этого в системе существует два типа нод: есть так называемые persistent-ноды, которые сохраняются на диск и никогда не пропадают, и есть эфемерные ноды, которые принадлежат какой-то конкретной сессии и существуют, пока существует она.
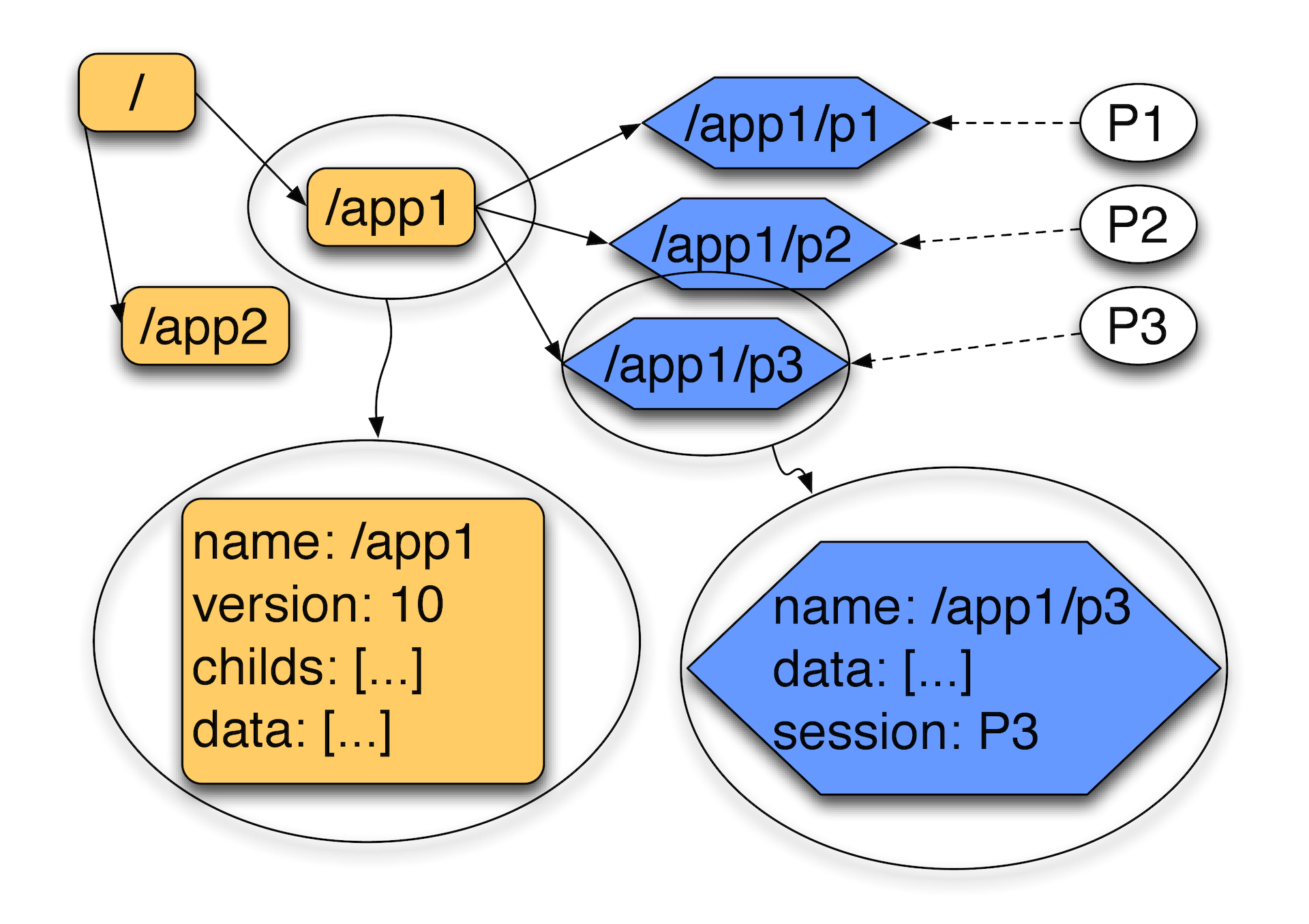
На картинке буквами Р —обозначены клиенты. Они устанавливают сессии — активные соединения с ZooKeeper-сервером, в рамках которого происходят обмен heartbeat-пакетами. Если в течение одной трети от тайм-аута мы не услышали хартбита, по истечении двух третей тайм-аута, клиентская библиотека присоединится к другому ZooKeeper-серверу, пока сессия на сервере не успела пропасть. Если сессия пропадает, эфемерные ноды (на схеме обозначены синим) пропадают. У них обычно есть атрибут, который указывает, какая из сессий ими владеет. Такие узлы не могут иметь детей, это строго объект, в который можно сохранить какие-то данные, но нельзя сделать зависимые.
Разработчики ZooKeeper посчитали, что очень удобно было бы иметь это все в виде файловой системы.
Вторая базисная для ZooKeeper вещь — это так называемая синхронная реализация записи и
FIFO-обработка сообщений. Идея заключается в том, что вся последовательность команд в ZooKeeper проходит строго упорядоченно т.е. данная система поддерживает total ordering.
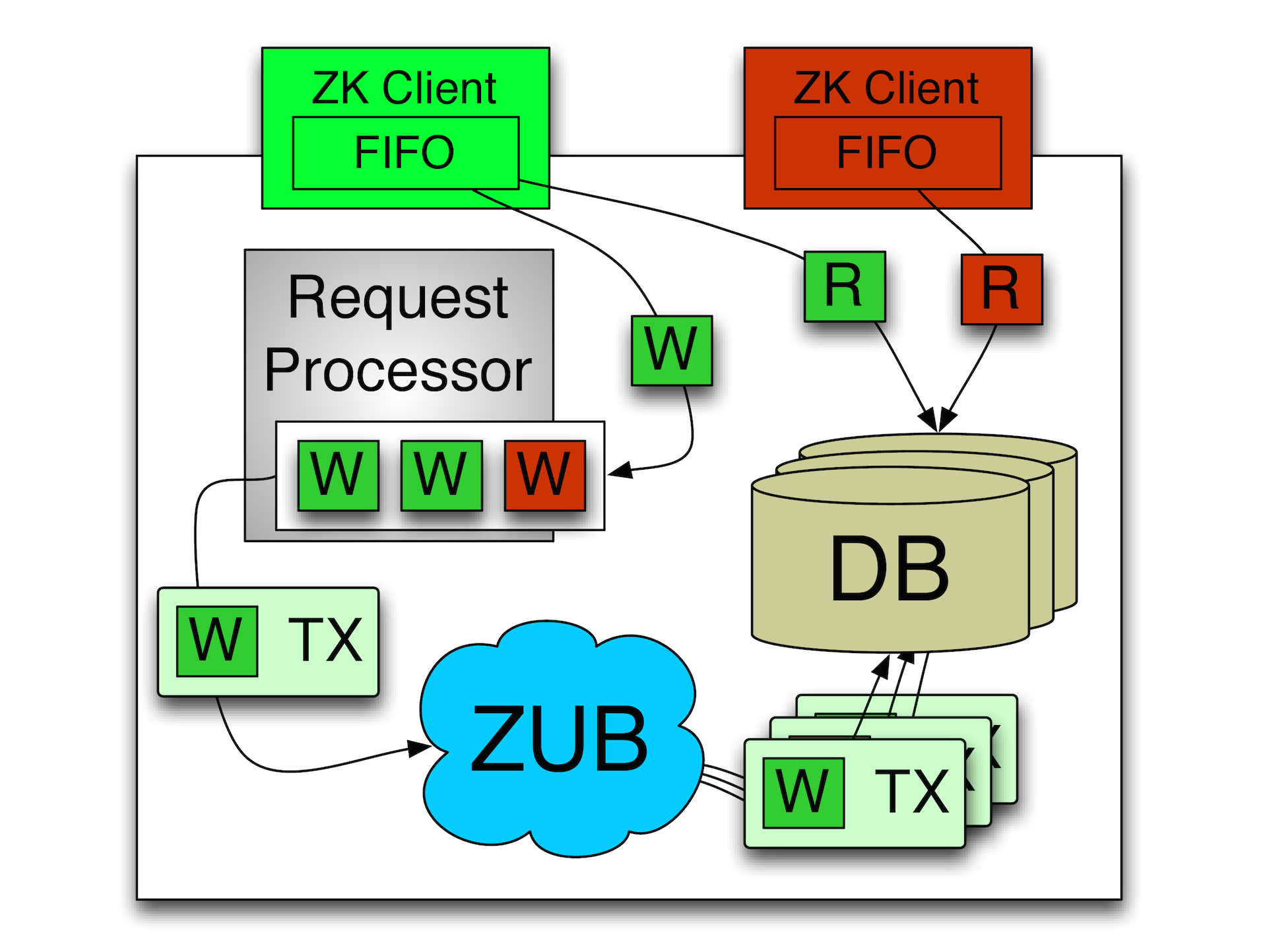
Все операции в ZooKeeper превращается в эту идемпотентную операцию. Если мы хотим изменить какую-то ноду, то мы создаем запись о том, что мы ее изменили, при этом запоминаем ту версию ноды, которая была и которая будет. За счет этого мы можем много раз получать одно и то же сообщение, при этом мы будем точно знать, в какой момент можно его применить. Соответственно, любые операции на запись осуществляются строго последовательно в одном потоке, в одном сервере (мастере). Есть лидер, который выбирается между несколькими машинками, и только он выполняет все операции на запись. Чтения могут происходить с реплики. При этом у клиента выполняется строгая последовательность его операций. Т.е. если он послал операцию на запись и на чтение, то сначала выполнится запись. Даже несмотря на то, что операцию чтения можно было бы выполнить не блокируясь, операция на чтение будет выполнена только после того как выполнена предыдущая операция на запись. За счет этого можно реализовывать предсказуемые системы асинхронной работы с ZooKeeper. Сама система в основном ориентирована на асинхронную работу. То что клиентские библиотеки реализуют синхронный интерфейс — это для удобства программиста. На самом деле, высокую производительность ZooKeeper обеспечивает именно при асинхронной работе, как обычно и бывает.
Каким образом это все работает? Есть один лидер плюс несколько фолловеров. Изменения применяются с использованием двухфазного коммита. Оновное, на что ориентируется ZooKeeper — это то, что он работает по TСP плюс total ordering. В целом целом протокол ZAB (ZooKeeper Atomic Broadcast) — это упрощенная версия
Паксоса, которая, как известно, переживает переупорядочивание сообщений, умеет с этим бороться. ZAB с этим бороться не умеет, он изначально ориентирован на полностью упорядоченный поток событий. Параллельной обработки нет, но часто она и не требуется, потому что система ориентирована больше на чтение, чем на запись.
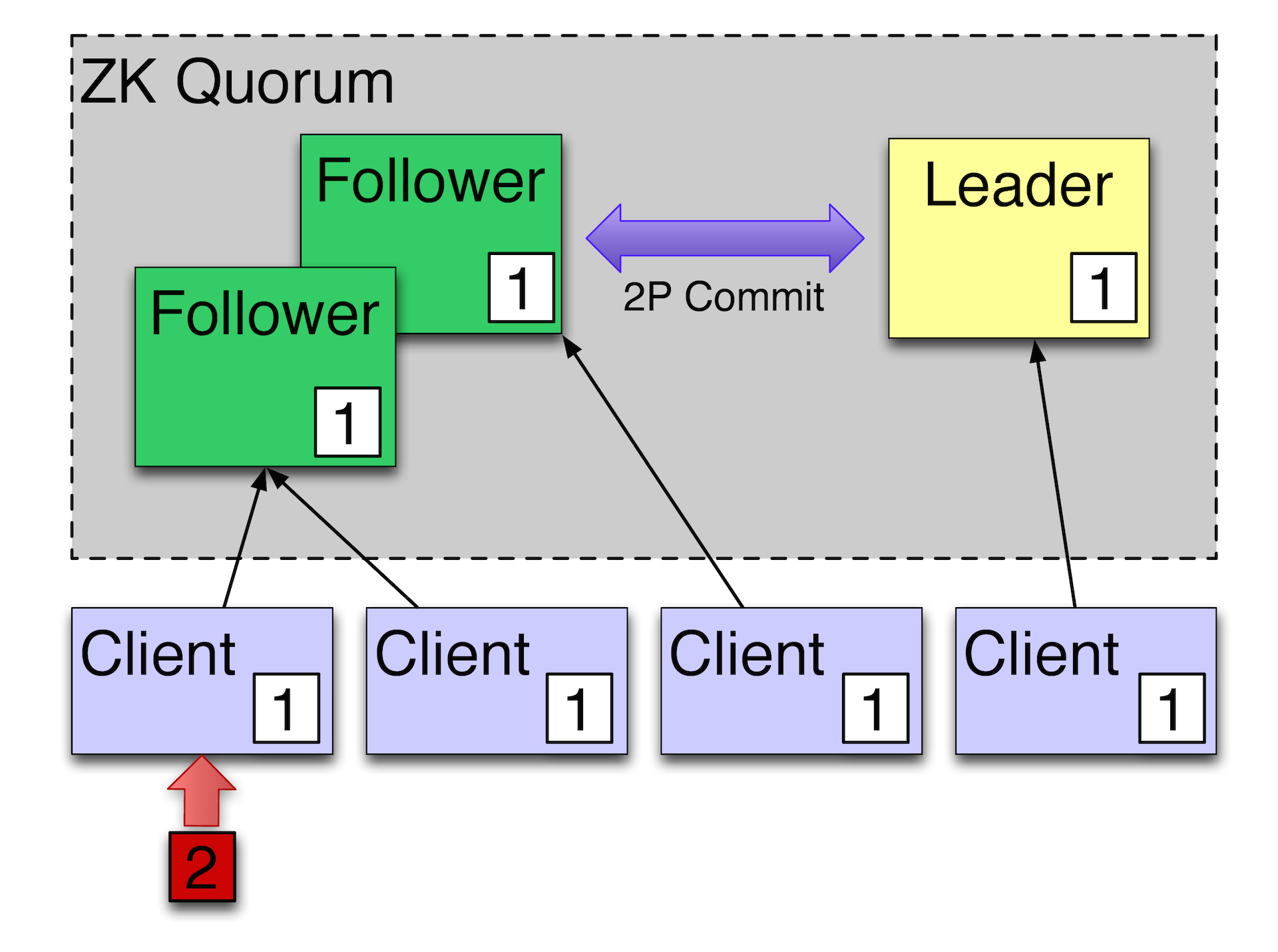
Например, у нас есть такой кластер, есть клиенты. Если сейчас клиенты сделают чтение они увидят то значение, которое сейчас сейчас видят фолловеры, считают, что сейчас значение у некого поля сейчас 1. Если мы в каком-то клиенте запишем 2, то фолловер выполнит операцию через лидера и получит в результате новое состояние.

Лидеру для того чтобы запись считалась успешной, нужно, чтобы как минимум 2 из 3 машин подтвердили то, что они эти данные надежно сохранили. Представьте, что у нас вот тот фолловер, который с 1, сейчас, например в каком-нибудь Амстердаме или другом удаленном ДЦ. Он отстает от остальных фолловеров. Следовательно, локальные машины уже будут видеть 2, а тот удаленный фолловер, если клиент произведет с него чтение до того, как фолловер успеет догнать мастера, увидит отстающее значение. Для того чтобы ему прочитать правильное значение, нужно послать специальную команду, чтобы ZooKeeper принудительно синхронизировался с мастером. Т.е. как минимум на момент выполнения команды sync будет точно известно, что мы получили состояние достаточно свежее по отношению к мастеру. Это называется slow read — медленное чтение. Обычно мы читаем очень быстро, но если все будут пользоваться медленным чтением, то понятно, что весь кластер будут читать всегда с мастера. Соответственно, масштабирования не будет. Если мы читаем быстро, позволяем себе отставать, то мы можем масштабироваться на чтение довольно хорошо.
Рецепты применения
Управление конфигурацией
Первое и самое основное применение — это управление конфигурацией. Записываем в Zookeper какую-то настройку, например, URL коннекта с базой или просто флажок, который запрещает или разрешает работу какому-то сервису внутри нашего кластера. Соответственно, участники кластера подписываются на раздел с конфигурацией и отслеживают ее модификации.
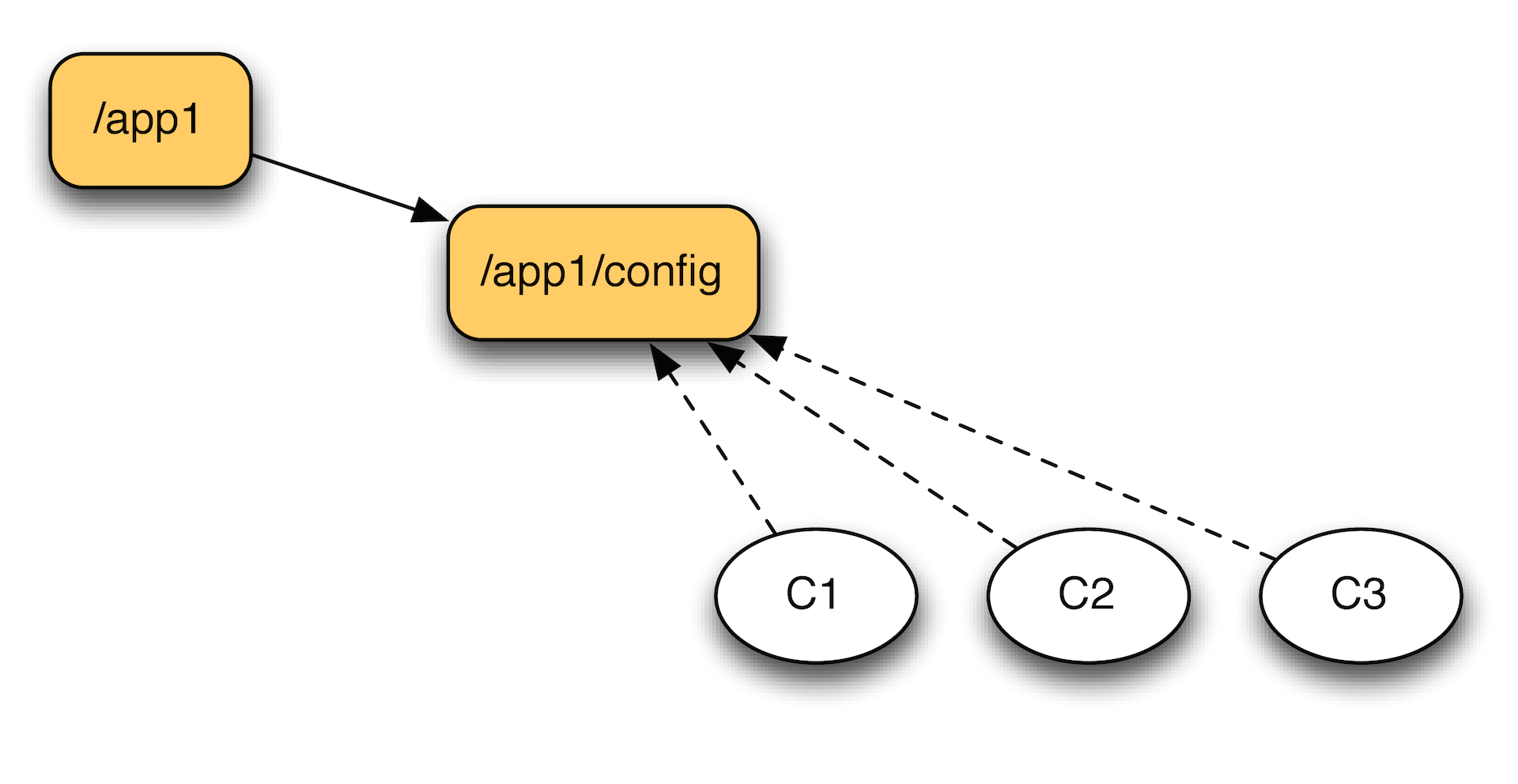
Если они зафиксировали изменение, они могут его прочитать и как-то отреагировать на это. За счет т.н. эфемерных нод можно отслеживать, например, жива ли еще машинка. Или получить список активных машин. Если у нас есть набор воркеров, то мы можем зарегистрировать каждого из них. И в зукипере мы будем видеть все машины, которые реально на связи. За счет наличия таймстемпа последней модификации или списка сессий, мы можем даже предсказывать, насколько машинки у нас отстают. Если мы видим, что машина начинает приближаться к тайм-ауту, можно предпринимать какие-то действия.
Рандеву
Еще один вариант — так называемое рандеву. Идея заключается в том, что есть некий путь воркеров и дилер, который раздает им задачи.
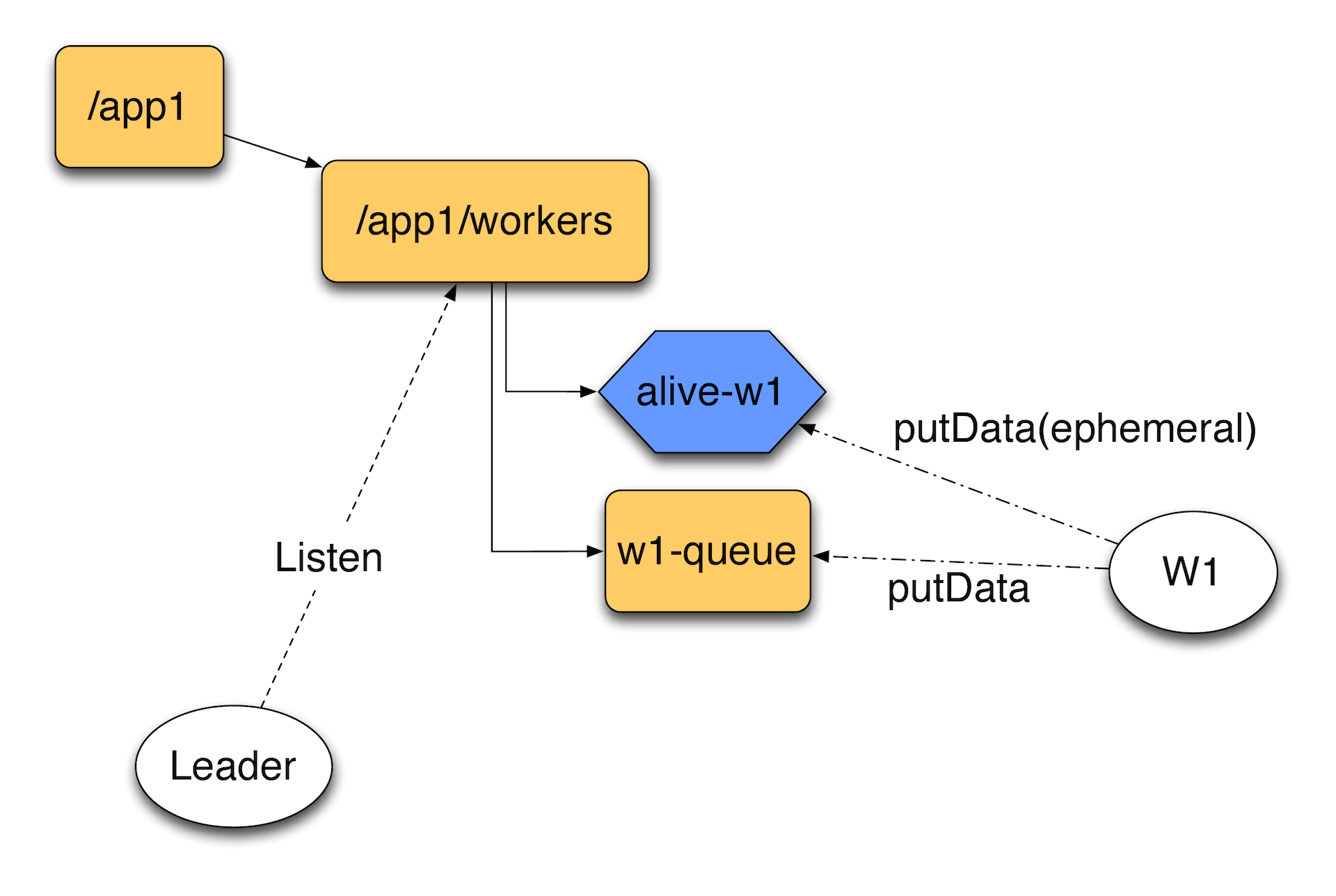
Мы не знаем, заранее, сколько у нас воркеров, они могут подключаться и отключаться, мы этот процесс не контролируем. Для этого можно создать каталог workers. И когда у нас появляется новый воркер, он регистрирует эфемерную ноду, которая будет сообщать о том, что воркер все еще жив, и, например, свой каталог, куда будут попадать задания для него. Лидер будет отслеживать каталог workers. Он заметит, если один из воркеров отвалится в какой-то момент. Обнаружив это он может, например, перенести задачи из queue к другому воркеру. Таким образом, мы можем построить на ZooKeeper несложную систему обработки заданий.
Блокировки
Допустим, пришел один клиент. Он создает эфемерную ноду. Тут нужно оговориться, что в ZooKeeper помимо обычных есть sequential-ноды. К ним в конце может приписываться некий атомарно растущий сиквенс.
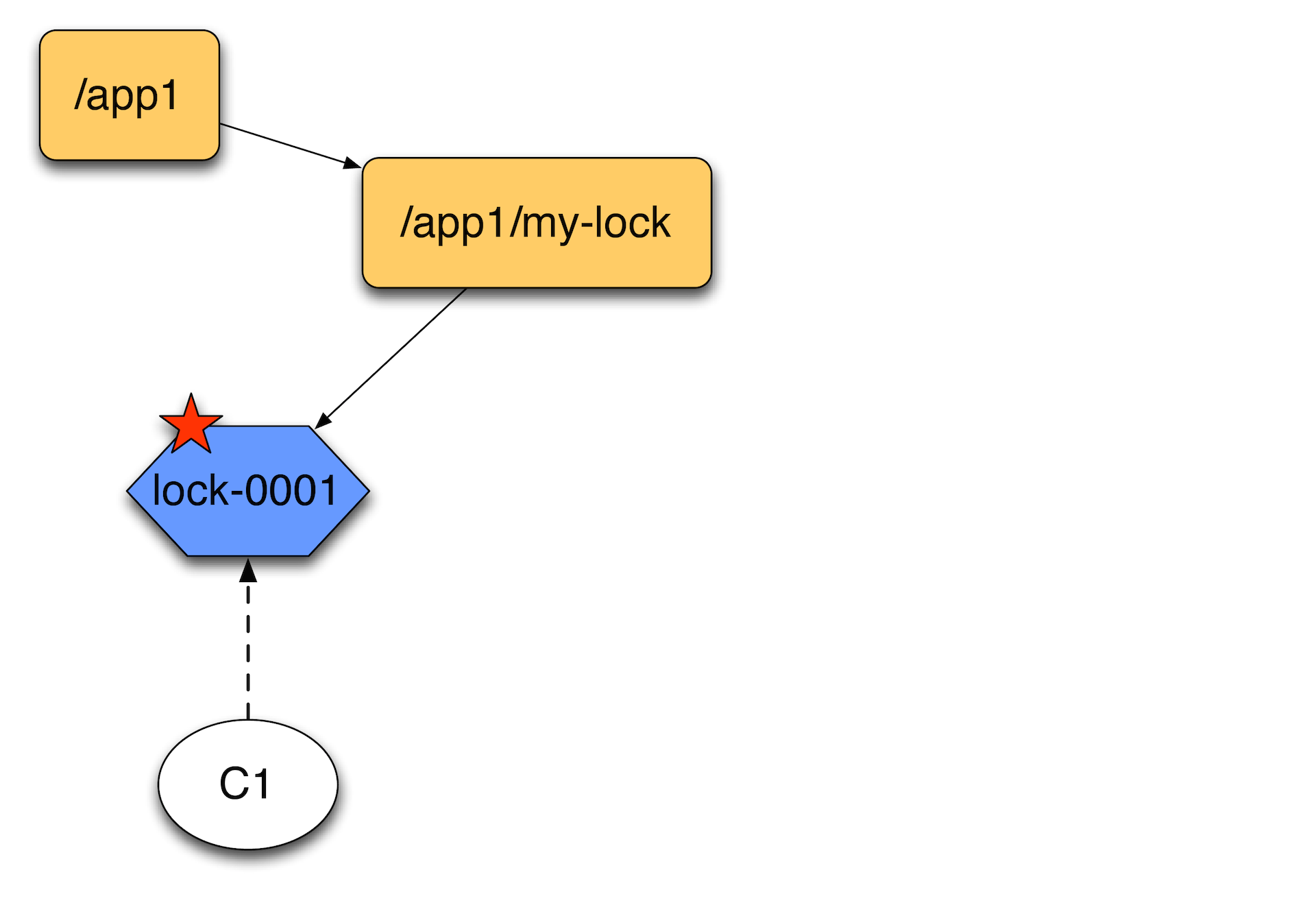
Второй клиент, приходя создает еще одну эфемерную ноду, получает список детей и отсортировав их, смотрит, является ли он первым. Он видит, что он не первый, вешает обработчик событий на первый и ждет, пока он исчезнет.
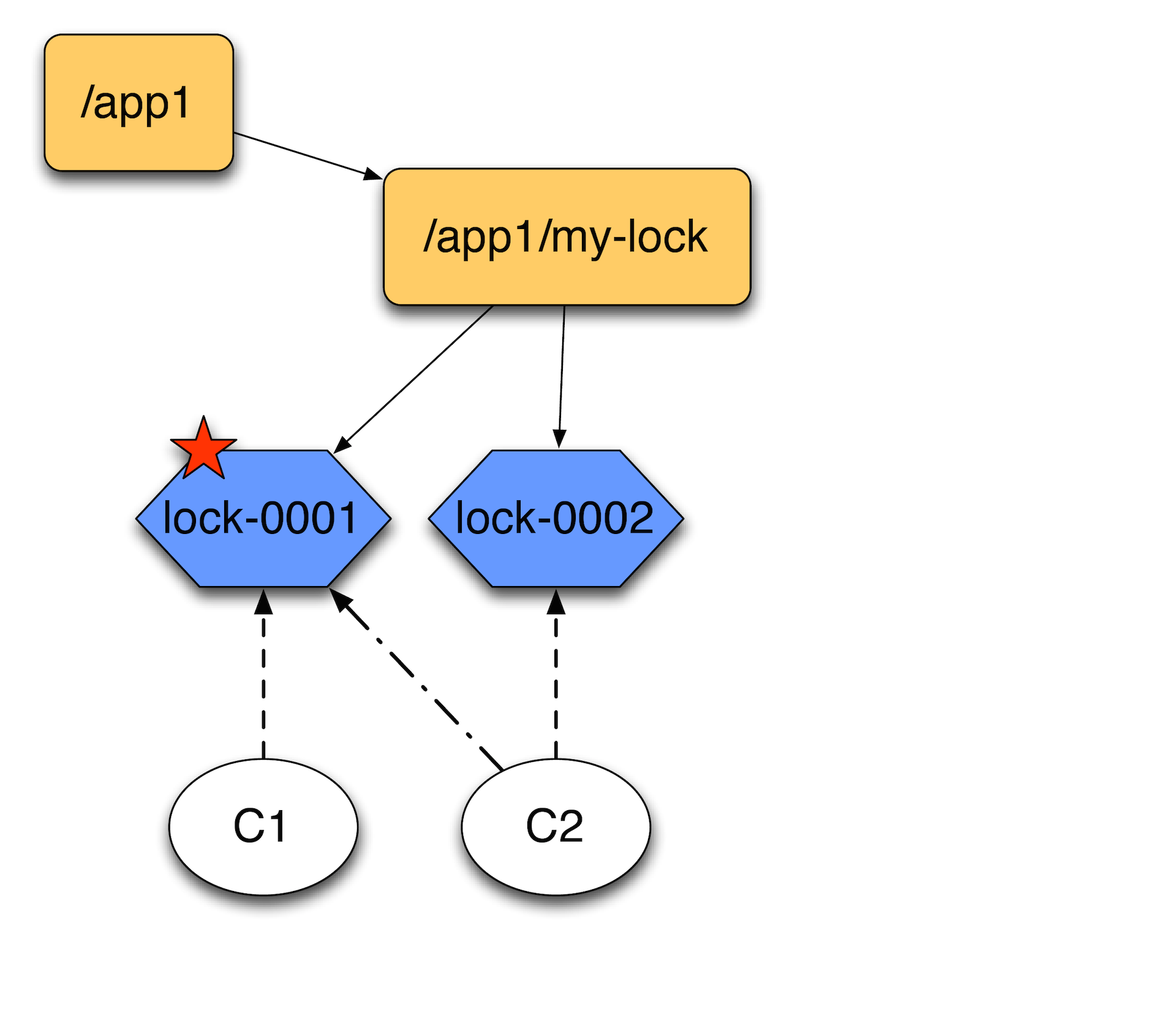
Почему не нужно вешать на сам каталог my-lock и ждать когда там все исчезнет? Потому что, если у вас много машин, которые пытаются что-то заблокировать, то когда пропадет lock–0001, у вас будет шторм уведомлений. Мастер будет просто занят рассылкой уведомлений об одном конкретном локе. Поэтому лучше их сцеплять именно таким образом — друг за другом, чтобы они следили только за предыдущей нодой. Они выстраиваются в цепочку.
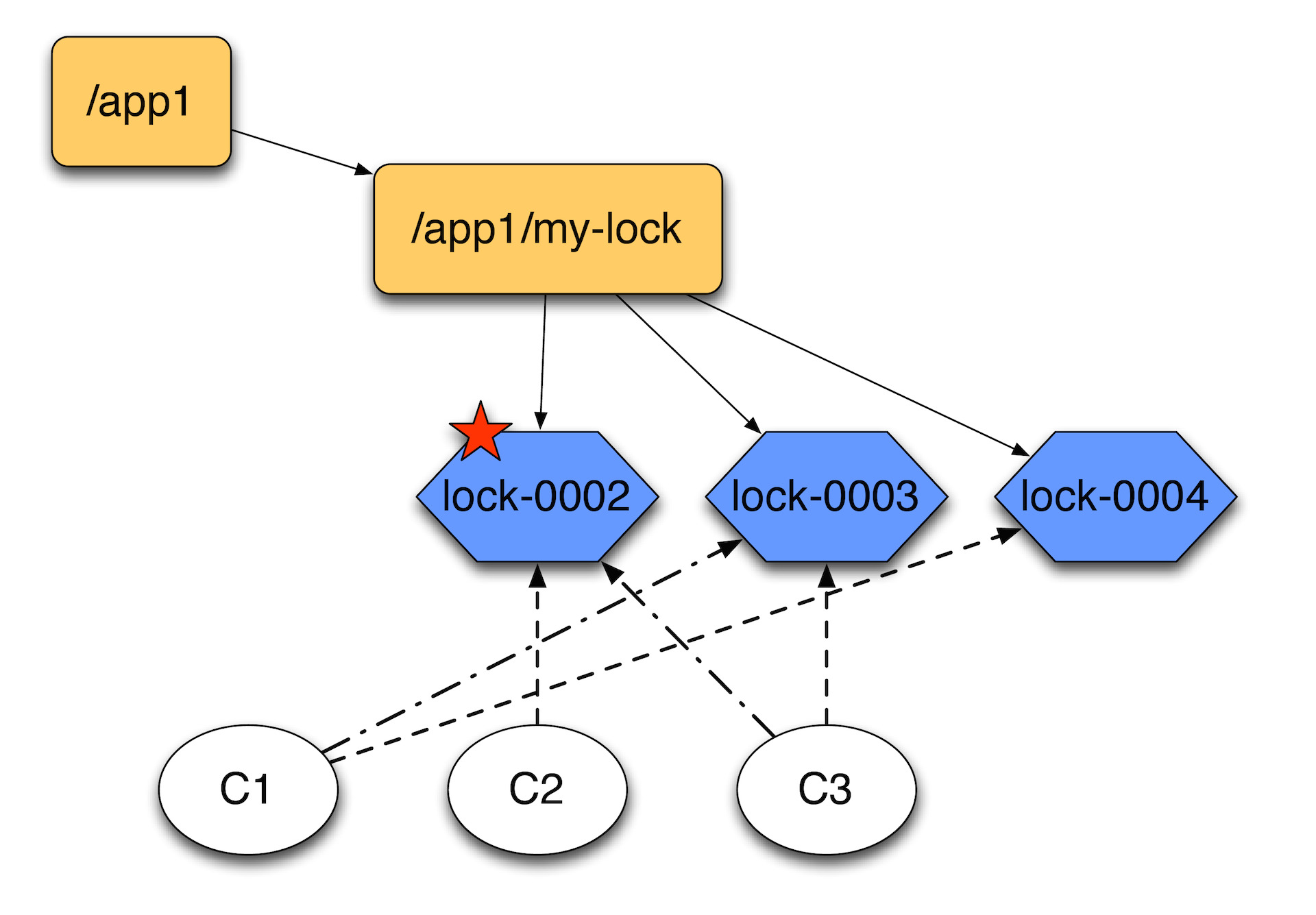
Когда первый клиент отпускает лок, удаляет эту запись, второй клиент видит это и считает, что теперь он является владельцем лока, т.к. впереди никого нет. За счет сиквенса никто вперед него гарантированно не залезет. Соответственно, если первый клиент придет снова, он создаст ноду уже в конце цепочки.
Производительность
На графике ниже по оси x отображено отношение записи к чтению. Заметно, что с ростом количества операций записи в процентном отношении, производительность сильно проседает.
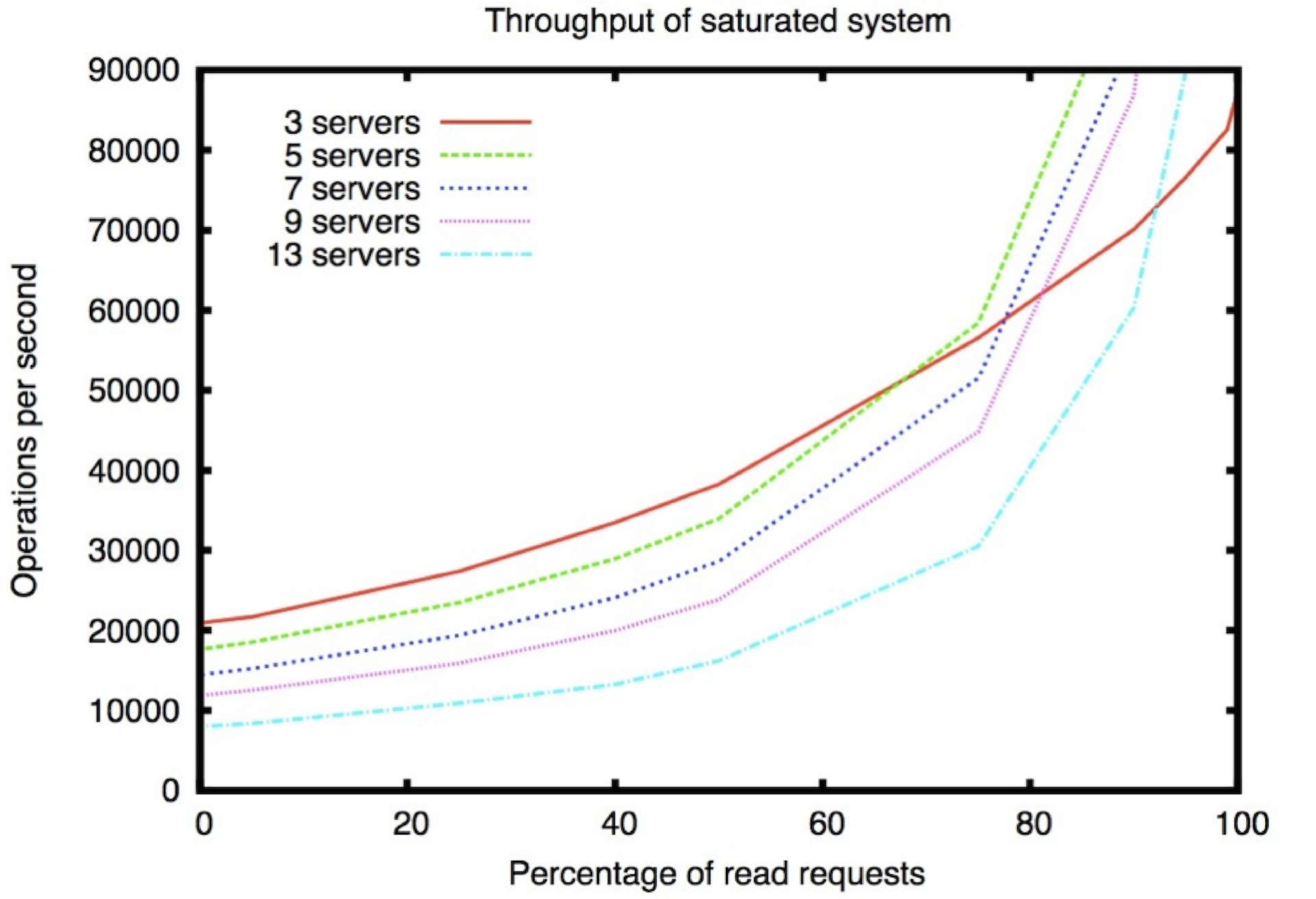
Это результаты работы в асинхронном режиме. Т.е. операции шлются по 100. Если бы они слались по одной, числа по оси y нужно поделить на 100. На чтение можно расти лучше. В ZooKeeper помимо возможности построить кворум из, скажем, пяти машин, которые будут гарантировать сохранение данных, можно еще делать неголосующие машины, которые работают как репитеры: просто читают события, но сами в записи не участвуют. За счет этого и получается преимущество в записи.
| Servers |
100% reads |
0% reads |
| 13 |
460k |
8k |
| 9 |
296k |
12k |
| 7 |
257k |
14k |
| 5 |
165k |
18k |
| 3 |
87k |
21k |
Таблица выше демонстрирует, как добавление серверов влияет на чтение и запись. Видно, что скорость чтения растет вместе с количеством, а если мы увеличиваем кворум на запись, производительность падает.
На картинке ниже можно посмотреть, как ZooKeeper реагирует на различные сбои. Первый случай — выпадение реплики. Второй — выпадение реплики, к которой мы не присоединены.
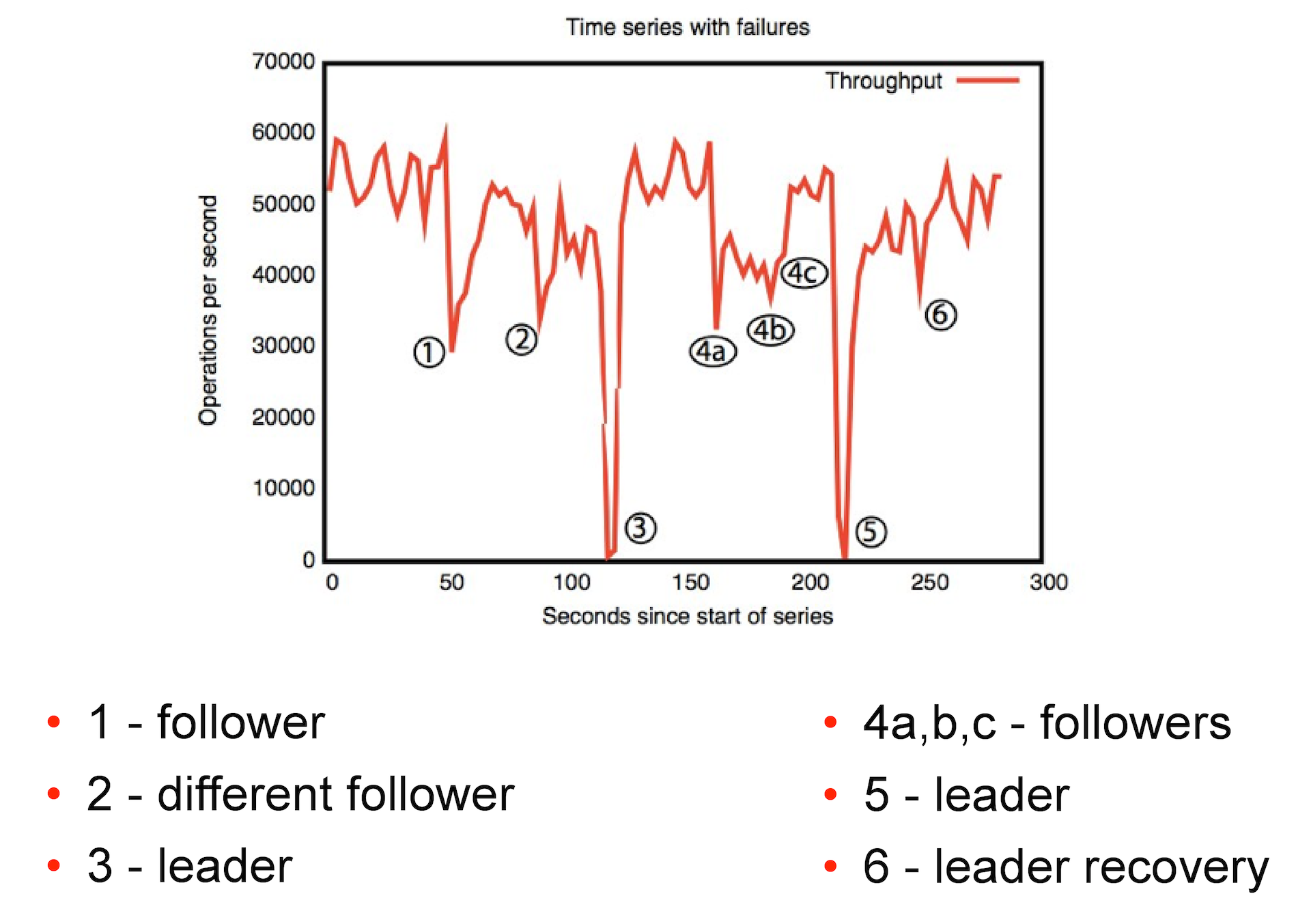
Падение лидера для зукипера условно критично. При хорошей сети ZooKeeper может восстановить его примерно за 200 мс. Иногда лидер может выбираться и несколько минут. И в этот момент если мы пытаемся захватить lock, любые попытки записи без активного лидера ни к чему не приведут, мы будем вынуждены ждать его появления.
Задержки
| severs / workers |
3 |
5 |
7 |
9 |
| 1 |
776 |
748 |
758 |
711 |
| 10 |
1831 |
1831 |
1572 |
1540 |
| 20 |
2470 |
2336 |
1934 |
1890 |
Время в таблице выше представлено в наносекундах. Соответственно по скорости чтения ZooKeeper приближается к in-memory-базам. Фактически это такой кэш, который всегда читает из памяти. Вообще у ZooKeeper база данных всегда находится в памяти. Запись происходит примерно так: ZooKeeper пишет лог событий, он в соответствии с настройками тика сбрасывается на диск и периодически система делает снэпшот всей базы. Соответственно, при слишком большой базе или слишком загруженных дисках задержки могут быть сравнимы с тайм-аутом. Этот тест моделирует создание некой конфигурации: у нас есть 1килобайт данных, сначала идет один синхронный create, потом асинхронный delete, все это повторяется 50 000 раз.