https://habrahabr.ru/company/microsoft/blog/343604/- Программирование
- Машинное обучение
- Алгоритмы
- Python
- Блог компании Microsoft
Всегда приятно осознавать, что применение технологий сводится не только к финансовой выгоде, бывают ещё и идеи, делающие мир лучше. Об одном из проектов с такой идеей мы и расскажем в этот морозный пятничный день. Вы узнаете о решении, которое позволило увеличить точность экспресс-анализа крови, с помощью применения алгоритмов машинного обучения для выявления связей между микро-РНК и генами. Также, стоит отметить, что методы, описанные ниже можно использовать не только в биологии.

Цикл статей «Digital Transformation»
Технологические статьи:
1. Начало.
2. Лотерея в облаке.
3. Блокчейн в банке.
4. Учим машину разбираться в генах человека.
5. Loading…
Серия интервью с Дмитрием Завалишиным на канале DZ Online:
1. Александр Ложечкин из Microsoft: Нужны ли разработчики в будущем?
Недавно мы заключили партнерское соглашение с Miroculus, молодой перспективной компанией в сфере медицинских исследований. Miroculus разрабатывает недорогие наборы для экспресс-анализа крови. В рамках данного проекта мы сосредоточили внимание на проблеме выявления связей между микро-РНК и генами путем анализа научно-медицинской документации, найдя решение, которое может применяться во многих других сферах.
Проблема
Задача системы
Miroculus — выявлять взаимосвязь отдельных
микро-РНК с определенными генами или заболеваниями. На основе этих данных разрабатывается и постоянно совершенствуется инструмент, с помощью которого исследователи смогут быстро выявлять связи между микро-РНК, генами и типами заболеваний (например, онкологическими).
Хотя в медицинской литературе доступна масса исследований касательно взаимозависимости между отдельными микро-РНК, генами и заболеваниями, единая централизованная база данных, которая содержала бы такую информацию в упорядоченной структурированной форме, отсутствует.
Между микро-РНК и генами могут существовать зависимости различного типа, однако из-за нехватки данных проблема извлечения связей свелась к двоичной классификации, цель которой — просто определить наличие связи между микро-РНК и геном.
Выявление связей между объектами в неструктурированном тексте называется
извлечением отношений.
Строго говоря, задача получает неструктурированные текстовые входные данные и группу объектов, а затем выводит результирующую группу триад вида «первый объект, второй объект, тип связи». То есть это подзадача в рамках более крупной задачи
извлечения информации.
Поскольку мы имеем дело с двоичной классификацией, нам необходимо создать классификатор, который получает предложение и пару объектов, а затем выводит результирующий балл в диапазоне от 0 до 1, отражающий вероятность наличия связи между этими двумя объектами.
Например, можно передать классификатору предложение «mir-335 регулирует BRCA1» и пару объектов (mir-335, BRCA1), и классификатор выдаст результат «0,9».
Исходный код для этого проекта доступен на
странице.
Создание набора данных
Мы использовали текст медицинских статей из двух источников данных:
PMC и
PubMed.
Текст документов, загруженных из указанных источников, был разделен на предложения с помощью библиотеки
TextBlob.
Каждое предложение было передано в инструмент распознавания объектов
GNAT, чтобы извлечь названия микро-РНК и генов, которые содержатся в предложении.
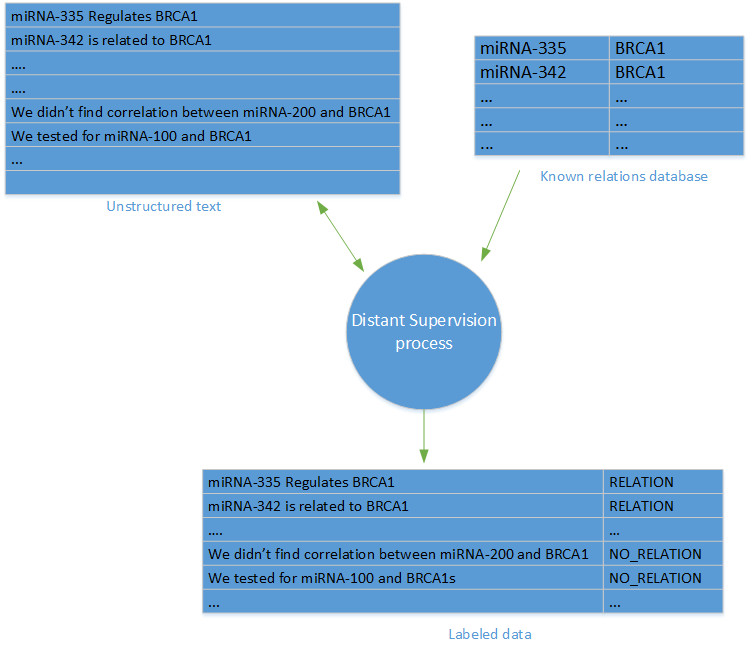
Одна из самых сложных задач, связанных с извлечением отношений (или с базовыми задачами машинного обучения) — наличие данных с метками. В нашем проекте такие данные были недоступны. К счастью, мы могли использовать метод «дистанционного наблюдения».
Дистанционное наблюдение
Термин «дистанционное наблюдение» был впервые введен в
исследовании «Дистанционное наблюдение при извлечении отношений без использования данных с метками» Минцем и соавторами. Метод дистанционного наблюдения предполагает создание набора данных с метками на основе базы данных известных связей между объектами и базы данных статей, в которых эти объекты упоминаются.
Для каждой пары объектов и каждой связи в базе данных объектов созданы метки связи для всех предложений в статьях БД, где упоминаются объекты.
Чтобы сгенерировать отрицательные образцы (отсутствие связи), мы произвольно отобрали предложения, содержащие связи, которые не отображаются в базе данных связей. Стоит отметить, что основная критика метода дистанционного наблюдения опирается на возможную неточность отрицательных образцов, поскольку в отдельных случаях в результате случайного отбора образцов данных можно получить ложноотрицательный результат.
Преобразование текста
После создания обучающего множества с метками создается классификатор связей с помощью библиотеки Python
scikit-learn и нескольких библиотек Python на базе технологий обработки естественного языка (NLP). В порядке эксперимента мы попробовали использовать несколько разных отличительных признаков и классификаторов.
Прежде чем испытать методы и отличительные признаки на практике, мы выполнили преобразование текста, состоящее из описанных далее этапов.
Замена объекта
Идея в том, что обучение модели не требуется в соответствии с именем конкретного объекта, однако оно необходимо в соответствии со структурой текста.
Пример:
miRNA-335 was found to regulate BRCA1
Выполняется преобразование в:
ENTITY1 was found to regulate ENTITY2
То есть мы практически взяли все пары объектов из каждого предложения и для каждой из них заменили искомые объекты местозаполнителями. При этом ОБЪЕКТ1 всегда заменяет микро-РНК, а ОБЪЕКТ2 — ген. Мы также использовали еще один специальный местозаполнитель, чтобы помечать объекты, которые являются частью предложения, но не участвуют в искомой связи.
Итак, для следующего предложения:
High levels of expression of miRNA-335 and miRNA-342 were found together with low levels of BRCA1
мы получили следующий набор преобразованных предложений:
High levels of expression of ENTITY1 and OTHER_ENTITY were found together with low levels of ENTITY2
High levels of expression of OTHER_ENTITY and ENTITY1 were found together with low levels of ENTITY2
На этом этапе можно использовать метод Python string.replace(), если требуется заменить объекты, а также методы itertools.combinations или itertools.product, если необходимо просмотреть все возможные комбинации.
Разметка
Разметка — это процесс разделения последовательности слов на сегменты меньшего размера. В данном случае мы разделяем предложения на слова.
Для этого мы используем библиотеку
nltk:
import nltk
tokens = nltk.word_tokenize(sentence)
Усечение
В соответствии с рекомендациями, представленными в научной литературе, мы усекали каждое предложение до сегмента меньшего размера, в котором содержатся два объекта, слова между объектами и несколько слов до и после объекта. Цель такого усечения — удалить те части предложения, которые не являются значимыми при извлечении отношений.
Мы создали срез массива слов, для которого на предыдущем этапе выполнена разметка, снабдив его соответствующими индексами:
WINDOW_SIZE = 3
# make sure that we don't overflow but using the min and max methods
FIRST_INDEX = max(tokens.index("ENTITY1") - WINDOW_SIZE , 0)
SECOND_INDEX = min(sentence.index("ENTITY2") + WINDOW_SIZE, len(tokens))
trimmed_tokens = tokens[FIRST_INDEX : SECOND_INDEX]
Нормализация
Мы выполнили нормализацию предложений, просто преобразовав все буквы в строчные. Хотя метод создание кейсов целесообразно использовать для решения таких задач, как анализ настроений и эмоций, в рамках извлечения отношений он не является показательным. Нас интересует информация и структура текста, а не акцентирование отдельных слов в предложении.
Удаление стоп-слов/чисел
В данном случае мы используем стандартный процесс удаления стоп-слов и чисел из предложения. Стоп-словами называются слова с высокой частотностью, например, предлоги «в», «к» и «на». Поскольку эти слова встречаются в предложениях очень часто, они не несут в себе смысловой нагрузки о связях между объектами в предложении.
По той же причине мы удаляем лексемы, состоящие только из чисел, и короткие лексемы, содержащие менее двух символов.
Выделение корней
Выделение корней — это процесс сокращения отдельного слова до корня.
В результате объем семантического пространства для слова сокращается, что позволяет сосредоточиться собственно на значении слова.
На практике этот шаг не особенно эффективен в плане повышения точности. По этой причине, а также из-за относительно низкого уровня производительности данного процесса (по времени выполнения) выделение корней не вошло в конечную модель.
Нормализация, удаление слов и выделение корней выполняются путем итерации размеченных и усеченных предложений; при необходимости выполняется нормализации и удаление слов.
cleaned_tokens = []
porter = nltk.PorterStemmer()
for t in trimmed_tokens:
normalized = t.lower()
if (normalized in nltk.corpus.stopwords.words('english')
or normalized.isdigit() or len(normalized) < 2):
continue
stemmed = porter.stem(t)
processed_tokens.append(stemmed)
Представление отличительных признаков
По завершении указанных ниже преобразований мы решили поэкспериментировать с разными типами отличительных признаков.
Мы использовали три типа признаков: мультимножество слов, синтаксические признаки и векторное представление слов.
Мультимножество слов
Модель мультимножества слов (МС) — распространенный метод, используемый в задачах обработки естественного языка (NLP) для преобразования текста в числовое векторное пространство.
В модели МС каждому слову в словаре назначается уникальный числовой идентификатор. Затем каждое предложение преобразуется в вектор в объеме словаря. Положение в векторе выражено значением «1» в том случае, если слово с таким идентификатором является текстом, или значением «0» в противном случае. В качестве альтернативного подхода можно настроить отображение в каждом элементе вектора количества вхождений данного слова в тексте. С примером можно ознакомиться
здесь.
Тем не менее описанная выше модель не учитывает порядок различных слов в предложении, а только вхождение каждого отдельного слова. Чтобы включить порядок слов в модель, мы использовали популярную модель
N-граммы, которая оценивает совокупность последовательных слов длиной в
N слов и обрабатывает каждую такую совокупность как отдельное слово.
Дополнительные сведения об использовании N-грамм в текстовом анализе см. в
разделе «Представление отличительных признаков для текстового анализа: однограмма, двуграмма, триграмма… сколько же всего?».
К счастью для нас, модели МС и N-граммы реализованы в scikit-learn посредством класса
CountVectorizer.
В следующем примере показано преобразование текста в представление МС 1/0 с помощью модели триграммы.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer = "word", binary = True,
ngram_range=(3,3))
# note that 'samples' should be a list/iterable of strings
# so you might need to convert the processes tokens back to sentence
# by using " ".join(...)
data_features = vectorizer.fit_transform(samples)
Синтаксические признаки
Мы использовали два типа синтаксических признаков:
маркеры части речи (ЧР) и
деревья синтаксического разбора с зависимостями.
Мы решили использовать
spacy.io, чтобы извлечь и маркеры ЧР, и графы зависимости, поскольку эта технология превосходит существующие библиотеки Python в плане скорости, а точность сопоставима с другими системами NLP.
Следующий фрагмент кода извлекает ЧР для данного предложения:
from spacy.en import English
parser = English()
parsed = parser(" ".join(processed_tokens))
pos_tags = [s.pos_ for s in parsed]
После преобразования всех предложений можно использовать описанный выше класс CountVectorizer и модель мультимножества слов для маркеров ЧР, чтобы преобразовать их в числовое векторное пространство.
Аналогичный метод использовался для обработки отличительных признаков дерева синтаксического анализа с зависимостями, поиск которых выполнялся на отрезке между двумя объектами в каждом предложении, и их преобразование выполнялось также с помощью класса CountVectorizer.
Векторные представления слов
Метод векторного представления слов в последнее время стал весьма популярным для решения проблем, связанных с NLP. Суть этого метода заключается в использовании нейронных моделей для преобразования слов в пространство отличительных признаков таким образом, чтобы похожие слова были представлены векторами на незначительном расстоянии друг от друга.
Дополнительные сведения о векторном представлении слов см. в следующей
статье блога.
Мы применили подход, описанный в документе
Paragraph Vector: внедрение предложений (или документов) в высокоразмерное пространство отличительных признаков. Мы использовали реализацию Doc2Vec библиотеки
Gensim. Дополнительные сведения доступны в этом
учебном пособии.
Как параметры, так и размер используемых выходных векторов соответствуют рекомендациям, приведенным в документе Paragraph Vector и учебном пособии по Gensim.
Обратите внимание, что помимо данных с метками мы использовали в модели Doc2Vec большой набор предложений без меток, чтобы обеспечить дополнительный контекст для модели и расширить язык и отличительные признаки, применяемые для обучения модели.
После создания модели каждое из предложений было представлено более чем 200 размерными векторами, которые можно использовать в качестве входных данных для классификатора.
Оценка моделей классификации
Завершив преобразование текста и извлечение отличительных признаков, можно переходить к следующему этапу: выбору и оценке модели классификации.
Для классификации использовался алгоритм
логистической регрессии. Мы опробовали и такие алгоритмы, как машина опорных векторов и случайный лес, однако логистическая регрессия показала лучшие результаты в плане скорости и точности.
Прежде чем приступить к оценке точности данного метода, необходимо
разделить набор данных на обучающее множество и тестовый набор. Для этого достаточно просто использовать метод train_test_split:
from sklearn.cross_validation import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.25)
Этот метод разделяет набор данных произвольно, причем 75 % данных относится к обучающему множеству, а 25 % — к тестовому набору.
Чтобы обучить классификатор на основе логистической регрессии, мы использовали класс scikit-learn
LogisticRegression. Для оценки производительности классификатора мы применяем класс
classification_report, который выводит на печать данные о
точности,
полноте возврата и
балл F1-Score для классификации.
В следующем фрагменте кода показано обучение классификатора логистической регрессии и вывод на печать отчета о классификации:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
clf = linear_model.LogisticRegression(C=1e5)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print classification_report(y_test, y_pred)
Пример результата выполнения фрагмента кода, описанного выше, выглядит следующим образом:
precision recall f1-score support
0 0.82 0.88 0.85 1415
1 0.89 0.83 0.86 1660
avg / total 0.86 0.85 0.85 3075
Обратите внимание, что параметр C (он обозначает степень регуляризации) выбран для этого примера произвольно, однако его необходимо настроить с помощью перекрестной проверки на достоверность, как показано ниже.
Результаты
Мы объединили все описанные выше методы и приемы и сравнили различные отличительные признаки и преобразования, чтобы выбрать оптимальную модель.
Мы использовали класс
LogisticRegressionCV для создания двоичного классификатора с настраиваемыми параметрами, а затем проанализировали другой тестовый набор, чтобы оценить производительность модели.
Обратите внимание, что для простого и удобного тестирования различных параметров разных отличительных признаков можно использовать класс
GridSearch.
В следующей таблице приведены основные результаты сравнения различных отличительных признаков.
Для проверки точности модели использовалась шкала
F1-Score, поскольку она позволяет оценить как точность, так и полноту возврата в модели.
| Возможности |
F1-Score |
|---|
| Одно-триграммы (мультимножество слов) |
0,87 |
| Одно-триграммы (МС) и триграммы (маркеры ЧР) |
0,87 |
| Одно-триграммы (МС) и Doc2Vec |
0,87 |
| Однограммы (мультимножество слов) |
0,8 |
| Двуграммы (мультимножество слов) |
0,85 |
| Триграммы (мультимножество слов) |
0,83 |
| Doc2Vec |
0,65 |
| Триграммы (маркеры ЧР) |
0,62 |
В целом представляется, что при использовании мультимножества слов в одно-триграммах обеспечивается максимальная точность по сравнению с другими методами.
Хотя модель Doc2Vec отличается максимальной производительностью при определении схожести слов, она не гарантирует достойных результатов в плане извлечения отношений.
Варианты использования
В этой статье мы рассмотрели метод, который использовался для создания классификатора извлечения отношений для обработки связей между микро-РНК и генами.
Хотя рассмотренные в этой статье проблематика и образцы относятся к области биологии, изученное решение и методы можно применять и в других областях для создания графов отношений на основе неструктурированных текстовых данных.