https://habr.com/ru/post/503954/- Python
- Big Data
- Data Engineering
Небольшое вступительное слово
Я считаю, что бОльшее количество дел мы бы могли совершать, если бы нам предоставляли пошаговые инструкции, которые скажут что и как делать. Сам же вспоминаю в своей жизни такие моменты, когда не мог начаться какое-то дело из-за того, что было просто сложно понять, с чего нужно начинать. Быть может, когда-то давно в интернете ты увидел слова «Data Science» и решил, что тебе до этого далеко, а люди, которые этим занимаются где-то там, в другом мире. Так нет же, они прямо здесь. И, возможно, благодаря людям из этой сферы тебе в ленту попала статья. Существует полно курсов, которые помогут тебе освоится с этим ремеслом, здесь же я помогу тебе сделать первый шаг.
Ну что, ты готов? Сразу скажу, что тебе придется знать Python 3, поскольку его я буду использовать здесь. А также советую заранее установить на Jupyter Notebook или посмотреть, как использовать google colab.
Шаг первый

Kaggle — твой значительный помощник в этом деле. В принципе, можно и обойтись без него, но об этом я расскажу в другой статье. Это такая платформа, в которой размещаются соревнования по Data Science. В каждом таком соревновании на ранних этапах ты будешь получать нереальное количество опыта решения задач разного рода, опыта разработки и опыта работы в команде, что важно в наше время.
Нашу задачу мы возьмём оттуда. Называется она так: «Титаник». Условие таково: спрогнозировать, выживет каждый отдельно взятый человек. В целом говоря, задача человека, занимающегося DS, это сбор данных, их обработка, обучение модели, прогноз и так далее. В kaggle же нам позволяют пропустить этап сбора данных — они представлены на платформе. Нам нужно их загрузить и можно начать работу!
Сделать это можно следующим образом:
во вкладке Data расположены файлы, в которых содержатся данные


Загрузили данные, подготовили наши Jupyter тетрадки и…
Шаг второй
Как нам теперь загрузить эти данные?
Во-первых, импортируем необходимые библиотеки:
import pandas as pd
import numpy as np
Pandas позволит нам загрузить .csv файлы для дальнейшем обработки.
Numpy нужен для того, чтобы представить нашу таблицу данных в виде матрицы с числами.
Идём дальше. Возьмём файл train.csv и загрузим его к нам:
dataset = pd.read_csv('train.csv')
Мы будем ссылаться к нашей выборке train.csv данных через переменную dataset. Давайте глянем, что там находится:
dataset.head()

Функция head() позволяет нам просмотреть первые несколько строк датафрейма.
Стобцы Survived — это, как раз, наши результаты, которые в этом датафрейме известны. По вопросу задачи нам нужно предсказать столбец Survived для данных test.csv. В этих данных хранится информация о других пассажирах Титаника, для которых нам, решающим задачу, неизвестны исходы.
Итак, разделим нашу таблицу на зависимые и независимые данные. Тут всё просто. Зависимые данные — это
те данные, которые зависят от независимых то, что находится в исходах. Независимые данные — это те данные, которые влияют на исход.
К примеру, у нас есть такой набор данных:
«Вова учил информатику — нет.
Вова получил по информатике 2.»
Оценка по информатике зависит от ответа на вопрос: учил ли Вова информатику? Ясненько? Двигаемся дальше, мы уже ближе к цели!
Традиционная переменная для независимых данных — Х. Для зависимых — у.
Делаем следующее:
X = dataset.iloc[ : , 2 : ]
y = dataset.iloc[ : , 1 : 2 ]
Что это такое? Функцией iloc[:, 2: ] мы говорим питону: хочу видеть в переменной Х данные, начинающиеся со второй столбца (включительно и при условии, что счёт начинается с нуля). Во второй строке говорим, что хотим видеть в у данные первого столбца.
[ a:b, c:d ] — это конструкция того, что мы используем в скобках. Если не указывать какие-то переменные, то они будут сохраняться дефолтными. То есть мы можем указать [:,: d] и тогда мы получим в датафрейме все столбцы, кроме тех, которые идут, начиная с номера d и дальше. Переменные a и b определяют строки, но они нам все нужны, поэтому это оставляем дефолтным.
Посмотрим, что у нас вышло:
X.head()
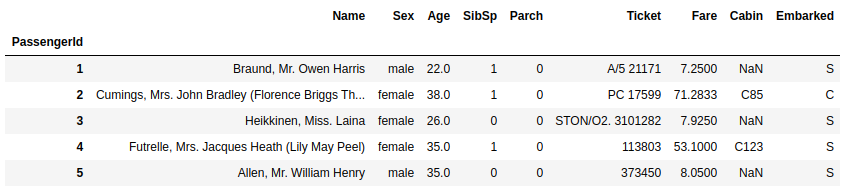
y.head()
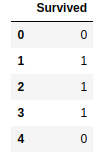
Для того, чтобы упростить этот небольшой урок, мы удалим столбцы, которые требуют особого «ухода», либо вообще не влияют на выживаемость. В них содержатся данные типа str.
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X.drop(count, inplace=True, axis=1)
Супер! Идём к следующему шагу.
Шаг третий
Тут нам потребуется закодировать наши данные, чтобы машина лучше понимала, как эти данные влияют на результат. Но кодировать будем не все, а только данные типа str, которые мы оставили. Столбец «Sex». Как мы хотим закодировать? Представим данные о поле человека вектором: 10 — мужской пол, 01 — женский пол.
Для начала наши таблицы переведем в матрицу NumPy:
X = np.array(X)
y = np.array(y)
А теперь глядим:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X = np.array(ct.fit_transform(X))
Библиотека sklearn — это такая крутая библиотека, которая позволяет нам проводить полную работу в Data Science. Она содержит большое количество интересных моделей машинного обучения, а также позволяет нам заняться подготовкой данных.
OneHotEncoder позволит нам закодировать пол человека в том представлении, как мы и описали. Будет создано 2 класса: мужской, женский. Если человек — мужчина, то в столбец «мужской» будет записана 1, а в «женский», соответственно, 0.
После OneHotEncoder() cтоит [1] — это значит, что хотим закодировать столбец номер 1 (счёт с нуля).
Супер. Двигаемся еще дальше!
Как правило, такое случается, что некоторые данные остаются незаполненными(то есть NaN — not a number). Например, есть информация о человеке: его имя, пол. А вот данных о его возрасте нет. В таком случае мы применим такой метод: найдем среднее арифметическое по всем столбцам и, если данные какие-то в столбце пропущены, то заполним пустоту средним арифметическим.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X)
X = imputer.transform(X)
А теперь возьмем в счет, что случаются такие ситуации, когда данные очень сильно разросаны. Какие-то данные находятся в отрезке [0:1], а какие-то могут заходить за сотни и тысячи. Чтобы исключить такой разброс и компьютер был точнее в расчётах, мы проскалируем данные, отмасштабируем. Пусть все числа не будут превышать трёх. Для этого воспользуемся функцией StandartScaler.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X[:, 2:] = sc.fit_transform(X[:, 2:])
Теперь наши данные выглядят так:
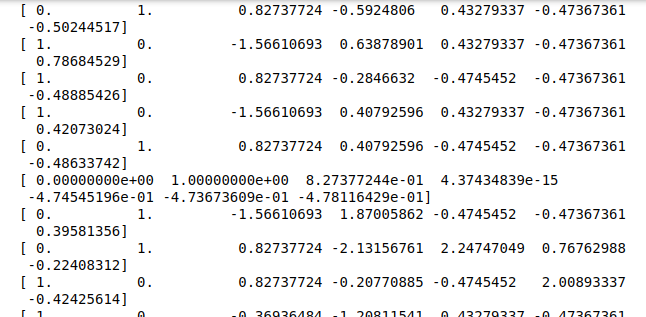
Класс. Мы уже близко к нашей цели!
Шаг четвёртый
Обучим нашу первую модель! Из библиотеки sklearn мы можем найти огромное количество интересностей. Я применил к данной задаче модель Gradient Boosting Classifier Classifier — поскольку наша задача — это задача классификации. Нужно прогноз отнести к 1 (выжил) или 0(не выжил)
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier(learning_rate=0.5, max_depth=5, n_estimators=150)
gbc.fit(X, y)
Функция fit говорит питону: Пусть модель ищет зависимости между X и у.
Меньше секунды и модель готова

Как её применить? Сейчас увидим!
Шаг пятый. Заключение
Теперь нам нужно загрузить таблицу с нашими тестовыми данными, для которых нужно составить прогноз. С этой таблицей проделаем все те же самые действия, которые мы делали для X.
X_test = pd.read_csv('test.csv', index_col=0)
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X_test.drop(count, inplace=True, axis=1)
X_test = np.array(X_test)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X_test = np.array(ct.fit_transform(X_test))
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X_test)
X_test = imputer.transform(X_test)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_test[:, 2:] = sc.fit_transform(X_test[:, 2:])
Применим же уже нашу модель!
gbc_predict = gbc.predict(X_test)
Всё. Мы составили прогноз. Теперь его нужно записать в csv и отправить на сайт.
np.savetxt('my_gbc_predict.csv', gbc_predict, delimiter=",", header = 'Survived')
Готово. Такое примитивное решение даёт не только 74% правильных ответов на паблике, но также и некоторый толчок в Data Science. Всем спасибо!