https://habr.com/ru/company/ruvds/blog/479276/- Блог компании RUVDS.com
- Разработка веб-сайтов
- Python
- Программирование
Автор статьи, перевод которой мы сегодня публикуем, говорит, что когда он узнал о тех методах библиотеки Pandas, о которых хочет тут рассказать, он почувствовал себя совершенно некомпетентным программистом. Почему? Дело в том, что ему, когда он до этого писал код, лень было заглянуть в поисковик и узнать, существуют ли некие эффективные способы решения некоторых задач. Как результат, он даже и не знал о существовании целого ряда весьма полезных методов Pandas. Он, не пользуясь этими методами, всё же смог реализовать необходимую логику, но это потребовало от него нескольких часов работы, это заставило его понервничать. И, конечно, он по ходу дела написал кучу ненужного кода. Эту статью он подготовил для тех, кто не хотел бы оказаться в его ситуации.

Методы idxmin() и idxmax()
Я уже
писал о методах
idxmin() и
idxmax(), но если я не расскажу о них здесь — вам непросто будет понять то, о чём речь пойдёт дальше.
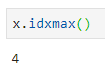
Эти методы, если описать их в двух словах, возвращают индекс (положение указателя) для нужной записи. Предположим, я создал следующий объект
Series Pandas.
x = pd.Series ([
1, 3, 2, 8, 124, 4, 2, 1
])
Мне нужно найти индекс минимального и максимального элемента. Конечно, это не сложно узнать, просто глядя на описание объекта, но в реальных проектах никогда (именно так — «никогда») не встречаются наборы данных, состоящие из столь малого количества элементов.
Что делать? Воспользоваться методами
idxmin() и
idxmax(). Вот как это выглядит:
Пользуясь этими методами нужно не забывать о том, что они возвращают индекс первого вхождения минимального или максимального значения.
Метод ne()
Метод
ne() стал для меня огромным открытием. Некоторое время тому назад я работал с временными рядами данных и столкнулся с проблемой, когда первые
n наблюдений равнялись 0.
Представьте, что вы что-то купили, но в течение определённого периода времени это не потребили. То, что вы купили, находится в вашем распоряжении, но, так как вы этим не пользуетесь, уровень потребления этого на некую дату равняется 0. Так как мне были интересны данные по потреблению, полученные тогда, когда началось реальное использование того, что было «куплено», оказалось, что метод
ne() — это именно то, что мне было нужно.
Рассмотрим следующий сценарий. У нас имеется объект Pandas
DataFrame, в котором находятся результаты некоторых наблюдений, которые, в начале списка, представлены значениями 0.
df = pd.DataFrame()
Метод
ne() вернёт
True только в том случае, если текущее значение не является тем, которое указано при вызове этого метода (например, при его вызове может быть указано значение 0), а в противном случае вернёт
False:
df['X'].ne(0)
Сам по себе этот метод нельзя назвать особенно полезным. А теперь вспомните, как в начале материала я говорил, что для понимания статьи вам нужно ознакомиться с методом
idxmax(). Я тогда не шутил. К вышеприведённому вызову
ne() можно присоединить вызов
idxmax(). В результате получится следующее:
df['X'].ne(0).idxmax()
Это говорит нам о том, что первый ненулевой результат наблюдения находится в позиции 6. Опять же, это может показаться не такой уж и важной находкой. Но самое главное тут то, что эту информацию можно использовать для выбора подмножества объекта
DataFrame и для отображения только тех значений, которые появляются начиная с обнаруженной позиции:
df.loc[df['X'].ne(0).idxmax():]
Этот приём оказывается весьма полезным во множестве ситуаций, в которых приходится работать с временными рядами данных.
Методы nsmallest() и nlargest()
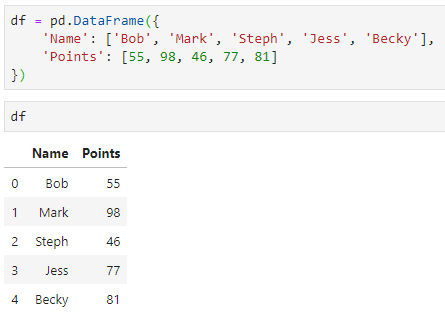
Я подозреваю, что уже только увидев имена этих методов, вы можете догадаться об их предназначении. Предположим, я создал следующий объект
DataFrame:
df = pd/DataFrame({
'Name': ['Bob', 'Mark', 'Steph', 'Jess', 'Becky'],
'Points': [55, 98, 46, 77, 81]
})
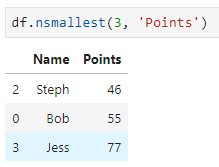
Чтобы было интереснее — предположим, что тут находятся результаты теста, который прошли некие студенты. Мы хотим найти трёх студентов, которые справились с тестом хуже всего:
df.nsmallest(3, 'Points')
Или — узнать о том, кто вошёл в тройку лучших:
df.nlargest(3, 'Points')
Эти методы представляют собой очень хорошие заменители методов наподобие
sort_values().
Итоги
Здесь мы рассмотрели несколько полезных методов Pandas. Тем, кто о них знает, их применение может показаться совершенно естественным, а для тех, кто только что о них узнал, они могут выглядеть как настоящая находка. Надеемся, они сослужат вам хорошую службу.
Уважаемые читатели! Знаете о каких-нибудь полезных методах Pandas, о которых, возможно, не знают другие?