https://habrahabr.ru/post/334668/Введение
Обратил внимание на перевод публикации под названием «Тематическое моделирование репозиториев на GitHub» [1]. В публикации много теоретических данных и очень хорошо описаны темы, понятия, использование естественных языков и многие другие приложения модели BigARTM.
Однако, обычному пользователю без знаний в области тематического моделирования для практического использования достаточно знаний интерфейса и чёткой последовательности действий при подготовке текстовых исходных данных.Разработке прогамного обеспечения для подготовки текстовых данных и выбору среды разработки и посвящена данная публикация.
Установка BigARTM в Windows и подготовка исходных данных
Установка BigARTM хорошо изложена в видео презентации [2], поэтому я на ней останавливаться не буду, отмечу только что приведенные в документации программы рассчитаны на определённую версию и на скаченной версии могут не работать. В статье используется версия_v 0.8.1.
Программа BigARTM работает только на Python 2.7. Поэтому для создания единого программного комплекса все вспомогательные программы и примеры написаны на Python 2.7, что привело к некоторому усложнению кода.
Текстовые данные для тематического моделирования должны пройти обработку в соответствии со следующими этапами [4].
- Лемматизация или стемминг;
- Удаление стоп-слов и слишком редких слов;
- Выделение терминов и словосочетаний.
Рассмотрим как можно реализовать на Python указанные требования.
Что лучше применять: лемматизацию или стемминг?
Ответ на этот вопрос мы получим из следующего листинга, в котором в качестве примера использован первый абзац текста из статьи [5]. Здесь и дальше части листинга и результат их работы буду представлять как они выводятся в формате среды jupyter notebook.
Листинг лемматизации с lemmatize# In[1]:
#!/usr/bin/env python
# coding: utf-8
# In[2]:
text=u' На практике очень часто возникают задачи для решения\
которых используются методы оптимизации в обычной жизни при \
множественном выборе например подарков к новому году мы интуитивно \
решаем задачу минимальных затрат при заданном качестве покупок '
# In[3]:
import time
start = time.time()
import pymystem3
mystem = pymystem3 . Mystem ( )
z=text.split()
lem=""
for i in range(0,len(z)):
lem =lem + " "+ mystem. lemmatize (z[i])[0]
stop = time.time()
print u"Время, затраченное lemmatize- %f на обработку %i слов "%(stop - start,len(z))
Результат роботы листинга по лемматизации.
на практика очень часто возникать задача для решение который использоваться метод оптимизация в обычный жизнь при множественный выбор например подарок к новый год мы интуитивно решать задача минимальный затрата при задавать качество покупка
Время, затраченное lemmatize — 56.763000 на обработку 33 слов
Листинг стемминга с stemmer NLTK#In [4]:
start = time.time()
import nltk
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer('russian')
stem=[stemmer.stem(w) for w in text.split()]
stem= ' '.join(stem)
stop = time.time()
print u"Время, затраченное stemmer NLTK- %f на обработку %i слов "%(stop - start,len(z))
Результат роботы листинга.
на практик очен част возника задачи, для решен котор использ метод оптимизац в обычн жизн при множествен выборе, например, подарк к нов год мы интуитивн реша задач минимальн затрат при зада качеств покупок
Время, затраченное stemmer NLTK- 0.627000 на обработку 33 слов
Листинг стемминга с модулем Stemmer#In [5]:
start = time.time()
from Stemmer import Stemmer
stemmer = Stemmer('russian')
text = ' '.join( stemmer.stemWords( text.split() ) )
stop = time.time()
print u"Время, затраченное Stemmer- %f на обработку %i слов"%(stop - start,len(z))
Результат роботы листинга
на практик очен част возника задачи, для решен котор использ метод оптимизац в обычн жизн при множествен выборе, например, подарк к нов год мы интуитивн реша задач минимальн затрат при зада качеств покупок
Время, затраченное Stemmer- 0.093000 на обработку 33 слов
Вывод
Когда время на подготовку данных для тематического моделирования не критично, следует применять лемматизацию при помощи модулей pymystem3 и mystem, в противном случаи следует применить стемминг при помощи модуля Stemmer.
Где взять список стоп-слов для их последующего удаления?
Стоп-слова по определению слова не несущих смысловой нагрузки. Список таких слов нужно составлять с учётом специфики текста, однако должна быть основа. Основу можно получить при помощи корпуса brown.
Листинг получения stop-words#In [6]:
import nltk
from nltk.corpus import brown
stop_words= nltk.corpus.stopwords.words('russian')
stop_word=" "
for i in stop_words:
stop_word= stop_word+" "+i
print stop_word
Результат роботы листинга.
и в во не что он на я с со как а то все она так его но да ты к у же вы за бы по только ее мне было вот от меня еще нет о из ему теперь когда даже ну вдруг ли если уже или ни быть был него до вас нибудь опять уж вам ведь там потом себя ничего ей может они тут где есть надо ней для мы тебя их чем была сам чтоб без будто чего раз тоже себе под будет ж тогда кто этот того потому этого какой совсем ним здесь этом один почти мой тем чтобы нее сейчас были куда зачем всех никогда можно при наконец два об другой хоть после над больше тот через эти нас про всего них какая много разве три эту моя впрочем хорошо свою этой перед иногда лучше чуть том нельзя такой им более всегда конечно всю между
Получить список стоп-слов можно и в сетевом сервисе [6] по заданному тексту.
Вывод
Рационально сначала использовать основу стоп-слов, например, из корпуса brown и уже после анализа результатов обработки изменять или дополнять список стоп-слов.
Как выделить из текста термины и ngram?
В публикации [7] для тематического моделирования с применением программы BigARTM рекомендуют «После лемматизации по коллекции можно собирать n-граммы. Биграммы можно добавлять в основной словарь, разделив слова специальным символом, отсутствующим в Ваших данных:
- русский_общение;
- украинский_родной;
- засылать_казачок;
- русский_больница
»
Приводим листинг для выделения из текста bigrams, trigrams, fourgrams, fivegrams.
Листинг адаптирован под Python 2.7.10 и настроен на выделение bigrams, trigrams,fourgrams ,fivegrams из текста.В качестве специального символа использован — "_".
Листинг получения bigrams,trigrams, fourgrams , fivegrams#In [6]:
#!/usr/bin/env python
# -*- coding: utf-8 -*
from __future__ import unicode_literals
import nltk
from nltk import word_tokenize
from nltk.util import ngrams
from collections import Counter
text = "На практике очень часто возникают задачи для решения которых используются методы\ оптимизации в обычной жизни при множественном выборе например подарков к новому\
году мы интуитивно решаем задачу минимальных затрат при заданном качестве покупок"
#In [7]:
token = nltk.word_tokenize(text)
bigrams = ngrams(token,2)
trigrams = ngrams(token,3)
fourgrams = ngrams(token,4)
fivegrams = ngrams(token,5)
#In [8]:
for k1, k2 in Counter(bigrams):
print (k1+"_"+k2)
#In [9]:
for k1, k2,k3 in Counter(trigrams):
print (k1+"_"+k2+"_"+k3)
#In [10]:
for k1, k2,k3,k4 in Counter(fourgrams):
print (k1+"_"+k2+"_"+k3+"_"+k4)
#In [11]:
for k1, k2,k3,k4,k5 in Counter(fivegrams):
print (k1+"_"+k2+"_"+k3+"_"+k4+"_"+k5)
Результат роботы листинга.Для сокращения привожу только по одному значению из каждой ngram.
bigrams — новому_году
trigrams — заданном_качестве_покупок
fourgrams — которых_используются_методы_оптимизации
fivegrams- затрат_при_заданном_качестве_покупок
Вывод
Приведенную программу можно использовать для выделения устойчиво повторяющихся в тексте NGram учитывая каждую как одно слово.
Что должна содержать программа для подготовки текстовых данных к тематическому моделированию ?
Чаще копии документов располагают по одному в отдельном текстовом файле. При этом исходными данными для тематического моделирования является так называемый «мешок слов», в котором слова, относящиеся к определённому документу, начинаются с новой строки после тега -|text.
Следует отметить, что даже при полном выполнении приведенных выше требований высока вероятность того, что наиболее часто употребляемые слова не отражают содержание документа.
Такие слова могут быть удалены из копии исходного документа. При этом необходимо контролировать распределение слов по документам.
Для ускорения моделирования, после каждого слова через двоеточие указывается частота его употребления в данном документе.
Исходными данными для тестирования программы были 10 статей из Википедии. Названия статей следующие.
- География
- Математика
- Биология
- Астрономия
- Физика
- Химия
- Ботаника
- История
- Физиология
- Информатика
Листинг получения готового для моделирования текста#In [12]:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import codecs
import os
import nltk
import numpy as np
from nltk.corpus import brown
stop_words= nltk.corpus.stopwords.words('russian')
import pymystem3
mystem = pymystem3.Mystem()
path='Texts_habrahabr'
f=open('habrahabr.txt','a')
x=[];y=[]; s=[]
for i in range(1,len(os.listdir(path))+1): #перебор файлов с документами по номерам i
filename=path+'/'+str(i)+".txt"
text=" "
with codecs.open(filename, encoding = 'UTF-8') as file_object:# сбор текста из файла i-го документа
for line in file_object:
if len(line)!=0:
text=text+" "+line
word=nltk.word_tokenize(text)# токинезация текста i-го документа
word_ws=[w.lower() for w in word if w.isalpha() ]#исключение слов и символов
word_w=[w for w in word_ws if w not in stop_words ]#нижний регистр
lem = mystem . lemmatize ((" ").join(word_w))# лемматизация i -го документа
lema=[w for w in lem if w.isalpha() and len(w)>1]
freq=nltk.FreqDist(lema)# распределение слов в i -м документе по частоте
z=[]# обновление списка для нового документа
z=[(key+":"+str(val)) for key,val in freq.items() if val>1] # частота упоминания через : от слова
f.write("|text" +" "+(" ").join(z).encode('utf-8')+'\n')# запись в мешок слов с меткой |text
c=[];d=[]
for key,val in freq.items():#подготовка к сортировке слов по убыванию частоты в i -м документе
if val>1:
c.append(val); d.append(key)
a=[];b=[]
for k in np.arange(0,len(c),1):#сортировка слов по убыванию частоты в i -м документе
ind=c.index(max(c)); a.append(c[ind])
b.append(d[ind]); del c[ind]; del d[ind]
x.append(i)#список номеров документов
y.append(len(a))#список количества слов в документах
a=a[0:10];b=b[0:10]# TOP-10 для частот a и слов b в i -м документе
y_pos = np.arange(1,len(a)+1,1)#построение TOP-10 диаграмм
performance =a
plt.barh(y_pos, a)
plt.yticks(y_pos, b)
plt.xlabel(u'Количество слов')
plt.title(u'Частоты слов в документе № %i'%i, size=12)
plt.grid(True)
plt.show()
plt.title(u'Количество слов в документах', size=12)
plt.xlabel(u'Номера документов', size=12)
plt.ylabel(u'Количество слов', size=12)
plt.bar(x,y, 1)
plt.grid(True)
plt.show()
f.close()
Результат роботы листинга по генерации вспомогательных диаграмм.Для сокращения привожу только одну диаграмму для TOP-10 слов из одного документа и одну диаграмму распределение слов по документам.

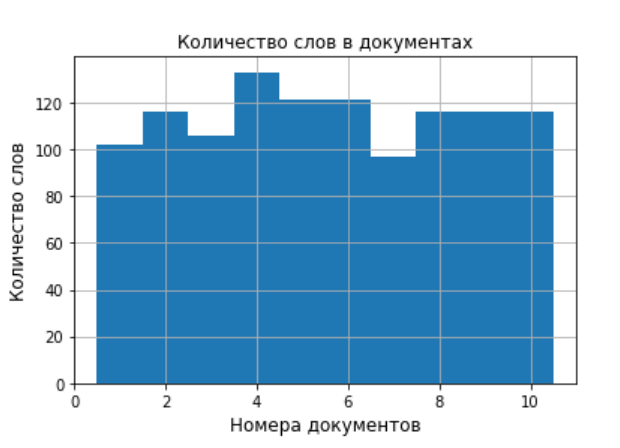
В результате работы программы мы получили десять диаграмм на которых отобраны по частоте употребления 10 слов.Кроме этого программа строит диаграмму распределения количества слов по документам. Это удобно для предварительного анализа исходных данных.При большом количестве документов частотные диаграммы можно сохранять в отдельной папке.
Результат роботы листинга по генерации «мешка слов».Для сокращения привожу данные из созданного текстового файла habrahabr.txt только по первому документу.
|text земной:3 кругом:2 страна:4 перекипелый: 2 человек:2 традиция:2 строение:2 появление:2 некоторый:2 имя:2 первый:4 создавать:2 находить:2 греческий:3 иметь:4 форма:2 ii:2 обитаемый:4 содержать:3 река:4 восточный:2 море:6 место:2 эратосфен:3 сведение:2 вид:3 геродот:3 смысл:4 картография:2 известный:2 весь:2 воображать:2 немало:2 наука:4 современный:2 достижение:2 период:2 шар:3 определение:2 предположение:2 закладывать:2 представление:7 составлять:3 изображать:2 страбометр:3 термин:2 круглый:7 употребляться:2 берег:2 южный:2 координата:2 земля:16 посвящать:2 доходить:2 карта:7 дисциплина:2 меридиан:2 диск:2 аристотель:4 должный:2 описание:6 отдельный:2 географический:12 оно:2 окружать:3 анаксимандра:2 название:8 тот:2 автор:2 сочинение:3 древний:8 поздний:4 опыт:2 птолемей:2 география:10 время:3 труд:2 также:6 объезд:3 свой:2 подходить:2 круг:2 омывать:3 средиземное:2 греков:2 китай:2 век:6 ее:2 океан:3 северный:2 сторона:2 эпоха:3 внутренний:2 плоский:2 красный:2 аррианин:2 который:8 другой:2 пользоваться:3 этот:5 основа:3 жить:2
Была использована одна текстовая модальность обозначенная в начале каждого документа как |text. После каждого слова через двоеточие введено число его употребления в тексте. Последнее ускоряет как процесс создания batch так и заполнение словаря.
Как можно упростить работу с BigARTM для создания и анализа topic ?
Для этого нужно во первых готовить текстовые документы и проводить их анализ с использованием предложных программных решений, а во вторых использовать среду разработки jupyter notebook.
В директории notebooks размещаются все необходимые для работы программы папки и файлы.
Части программного кода отлаживаются в отдельных файлах и после отладки собираются в общий файл.
Предложенная подготовка текстовых документов позволяет провести тематическое моделирование на упрощённом варианте BigARTM без регуляризаторов и фильтров.
Листинг для создания batch#In [1]:
#!/usr/bin/env python
# -*- coding: utf-8 -*
import artm
# создание частотной матрицы из batch
batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr.txt',# путь к "мешку слов"
data_format='vowpal_wabbit',# формат данных
target_folder='habrahabr', #папка с частотной матрицей из batch
batch_size=10)# количество документов в одном batch
Из файла habrahabr.txt программа в папке habrahab создаёт один batch из десяти документов, количество которых приведено в переменной batch_size=10. Если данные не изменяются и частотная матрица уже создана, то указанную выше часть программы можно пропустить.
Листинг для заполнения словаря и создания модели#In [2]:
batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr',data_format='batches')
dictionary = artm.Dictionary(data_path='habrahabr')# загрузка данных в словарь
model = artm.ARTM(num_topics=10,
num_document_passes=10,#10 проходов по документу
dictionary=dictionary,
scores=[artm.TopTokensScore(name='top_tokens_score')])
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=10)#10 проходов по коллекции
top_tokens = model.score_tracker['top_tokens_score']
Программа BigARTM после загрузки данных в словарь dictionary генерирует 10 тем (по числу документов), количество которых приведено в переменной num_topics=10.Количество проходов по документу и по коллекции указаны в переменных num_document_passes=10, num_collection_passes=10.
Листинг для создания и анализа topics#In [3]:
for topic_name in model.topic_names:
print (topic_name)
for (token, weight) in zip(top_tokens.last_tokens[topic_name],
top_tokens.last_weights[topic_name]):
print token, '-', round(weight,3)
Результат роботы программы BigARTM
topic_0
растение — 0.088
ботаника — 0.032
век — 0.022
мир — 0.022
линней — 0.022
год — 0.019
который — 0.019
развитие — 0.019
аристотель — 0.019
природа — 0.019
topic_1
астрономия — 0.064
небесный — 0.051
тело — 0.046
задача — 0.022
движение — 0.018
изучать — 0.016
метод — 0.015
звезда — 0.015
система — 0.015
который — 0.014
topic_2
земля — 0.049
географический — 0.037
география — 0.031
древний — 0.025
который — 0.025
название — 0.025
представление — 0.022
круглый — 0.022
карта — 0.022
также — 0.019
topic_3
физика — 0.037
физический — 0.036
явление — 0.027
теория — 0.022
который — 0.022
закон — 0.022
общий — 0.019
новый — 0.017
основа — 0.017
наука — 0.017
topic_4
изучать — 0.071
общий — 0.068
раздел — 0.065
теоретический — 0.062
вещество — 0.047
видимый — 0.047
физический — 0.044
движение — 0.035
гипотеза — 0.034
закономерность — 0.031
topic_5
физиология — 0.069
щитовидный — 0.037
человек — 0.034
организм — 0.032
латы — 0.03
артерия — 0.025
железа — 0.023
клетка — 0.021
изучать — 0.021
жизнедеятельность — 0.018
topic_6
математика — 0.038
клетка — 0.022
наука — 0.021
организм — 0.02
общий — 0.02
который — 0.018
математический — 0.017
живой — 0.017
объект — 0.016
ген — 0.015
topic_7
история — 0.079
исторический — 0.041
слово — 0.033
событие — 0.03
наука — 0.023
который — 0.023
источник — 0.018
историография — 0.018
исследование — 0.015
философия — 0.015
topic_8
термин — 0.055
информатика — 0.05
научный — 0.031
язык — 0.029
год — 0.029
наука — 0.024
информация — 0.022
вычислительный — 0.017
название — 0.017
science — 0.014
topic_9
век — 0.022
который — 0.022
наука — 0.019
химический — 0.019
вещество — 0.019
химия — 0.019
также — 0.017
развитие — 0.017
время — 0.017
элемент — 0.017
Полученные результаты в целом отвечают темам и результат моделирования можно считать удовлетворительным. При необходимости в программу можно добавить регуляризаторы и фильтры.
Выводы по результатам работы
Мы рассмотрели все этапы подготовки текстовых документов к тематическому моделированию. На конкретных примерах провели простой сравнительный анализ модулей для лемматизации и стемминга. Рассмотрели возможность использования NLTK для получения списка стоп-слов и поиска словосочетаний для русского языка. Рассмотрены листинги, написанные на Python 2.7.10 и адаптированные для русского языка, что позволяет их интегрировать в единый прогамный комплекс. Разобран пример тематического моделирования в среде jupyter-notebook, которая предоставляет дополнительные возможности для работы с BigARTM.
Используемые ссылки
1. Тематическое моделирование репозиториев на GitHub.
https://habrahabr.ru/post/312596/
2. Lecture 49 — Установка BigARTM в Windows
https://www.coursera.org/learn/unsupervised-
learning/lecture/qmsFm/ustanovka-bigartm-v-windows
3. bigartm/bigartm
https://github.com/bigartm/bigartm/releases
4. Основы обработки текстов.
http://docplayer.ru/40376022-Osnovy-obrabotki-tekstov.html
5. Решение задач линейного программирования с использованием Python.
https://habrahabr.ru/post/330648/
6. Испытываем новый алгоритм проверки. Вопросы и предложения
https://glvrd.ru/
7. Использование библиотеки для тематического моделирования BigARTM.
http://www.machinelearning.ru/wiki/images/f/f5/MelLain_Python_API_slides.pdf