table-driven testing в Go
- пятница, 16 июня 2023 г. в 00:00:20


IBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет Хабр!
Продолжая тему тестирования на Go, сегодня поговорим про table-driven тестирование.
У нас есть основная проблема: дублированный тестовый код.
Иногда вы будете писать тесты, использующие ту же логику тестирования, но с другим набором тестовых данных. Давайте посмотрим на пример. Допустим, вы хотите протестировать дополнительную функциональность калькулятора с различными входными данными, а также с разными результатами и ожидаемыми результатами. В следующей таблице показаны данные, которые вы, возможно, захотите определить: два разных аргумента, фактическая вызываемая функция и ожидаемый результат операции:
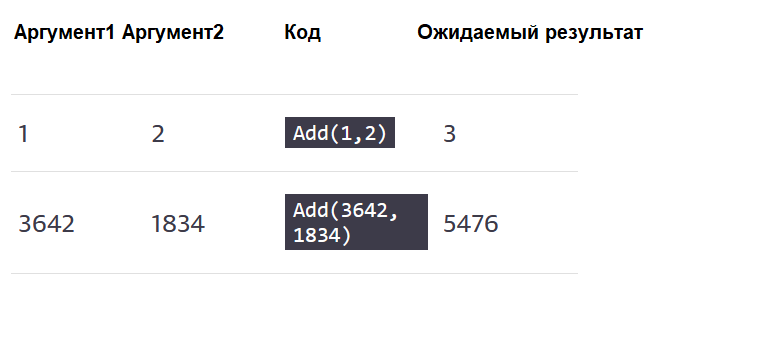
Вы можете видеть, что мы имеем дело с матричной комбинацией данных. Обычно каждая тестовая итерация представлялась как новая функция с большим количеством дублированного кода. Есть лучший способ смоделировать этот сценарий в Go. Ответ — табличные тесты.
Прежде чем мы поговорим о деталях тестов, управляемых таблицами, взглянем на существующий тестовый код на books_test.go. В текущем состоянии код считывает тестовые данные из CSV-файла testdata/valid.csv.
package main
import (
"os"
"testing"
)
func TestReadBooks(t *testing.T) {
csvFile, err := os.Open("testdata/valid.csv")
if err != nil {
t.Fatal("Can't open CSV file")
}
expectedBooksLen := 3
books, err := ReadBooks(csvFile)
if err != nil {
t.Fatal("Can't read CSV data")
}
actualBooksLen := len(books)
if expectedBooksLen != actualBooksLen {
t.Errorf("Unexpected number of books, got: %d, want: %d.", actualBooksLen, expectedBooksLen)
}
expectedBooks := []Book{
{
title: "The Guardians",
author: "John Grisham",
year: 2019,
},
{
title: "To Kill a Mockingbird",
author: "Harper Lee",
year: 2005,
},
{
title: "War and Peace",
author: "Leo Tolstoy",
year: 1982,
},
}
for i, b := range books {
if expectedBooks[i].title != b.title {
t.Errorf("Unexpected title, got: %s, want: %s.", b.title, expectedBooks[i].title)
}
if expectedBooks[i].author != b.author {
t.Errorf("Unexpected author, got: %s, want: %s.", b.author, expectedBooks[i].author)
}
if expectedBooks[i].year != b.year {
t.Errorf("Unexpected year, got: %d, want: %d.", b.year, expectedBooks[i].year)
}
}
}Прогоним тест
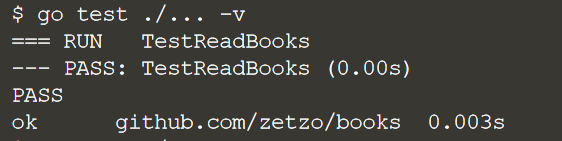
Отлично, все проходит. Далее мы добавим больше тестовых случаев с помощью табличных тестов.
Табличные тесты позволяют выполнять несколько тестовых случаев с различным набором тестовых данных. Функциональность, которую я описываю, не является встроенной функцией пакета тестирования Go. Скорее это модель, которая естественным образом развилась в сообществе.
Табличные тесты состоят из двух частей:
Данные, представленные в виде структур, таких как входы и выходы,
Цикл, который вызывает тестируемый код для каждого набора данных и проверяет ожидаемый результат.
Теперь предположим, что мы хотели также реализовать другие тестовые случаи:
Ожидаемое поведение тестируемого кода для пустого файла CSV ( testdata/empty.csv),
Ожидаемое поведение тестируемого кода для недопустимой файловой структуры CVS ( testdata/invalid.csv).
В следующей таблице представлены тестовые случаи:
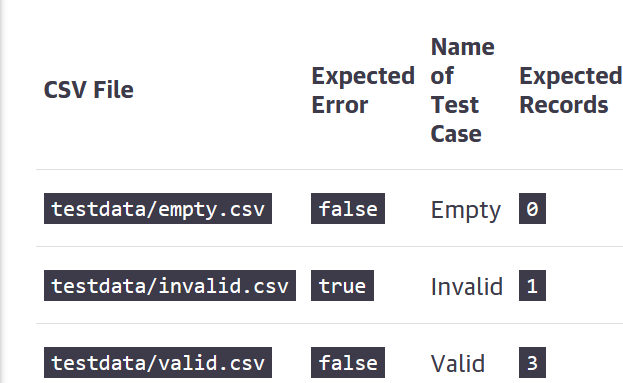
Для каждого теста мы укажем структуру, указывающую на соответствующий файл тестовых данных. Его выполнение определит, можно ли без ошибок обработать синтаксический анализ данных и сколько записей ожидать. Мы будем запускать каждый тестовый пример как подтест. Подтест выполняет каждую итерацию в goroutine. Чтобы сохранить простоту логики утверждений, вы только убедитесь, что правильное количество ожидаемых записей может быть проанализировано без ошибок:
package main
import (
"os"
"testing"
)
func TestReadBooks(t *testing.T) {
cases := []struct {
fixture string
err bool
name string
records int
}{
{
fixture: "testdata/empty.csv",
err: false,
name: "Empty",
records: 0,
},
{
fixture: "testdata/invalid.csv",
err: true,
name: "Invalid",
records: 1,
},
{
fixture: "testdata/valid.csv",
err: false,
name: "Valid",
records: 3,
},
}
for _, tc := range cases {
t.Run(tc.name, func(t *testing.T) {
csvFile, err := os.Open(tc.fixture)
if err != nil {
t.Fatal("Can't open CSV file")
}
books, err := ReadBooks(csvFile)
if err != nil && !tc.err {
t.Errorf("Expected an error for file %s", tc.fixture)
}
if tc.records != len(books) {
t.Errorf("Unexpected number of books, got: %d, want: %d.", len(books), tc.records)
}
})
}
}
Запустим тест
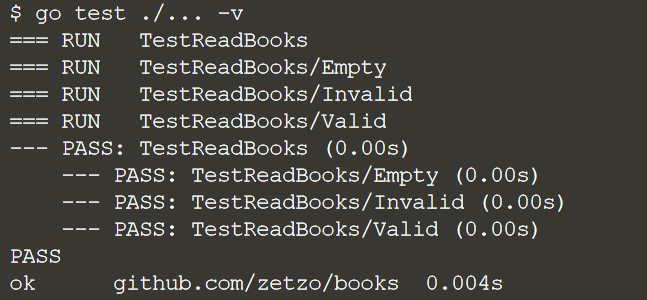
Go выполняет тестовые случаи последовательно, что может значительно увеличить время выполнения теста. На следующем шаге будем выполнять тестовые случаи параллельно.
Параллельное выполнение подтестов относительно просто. Просто вызывайте функцию t.Parallel() для каждой итерации. Есть небольшая ошибка, которую вы должны учитывать при написании тестов с горутинами. Горутины, вероятно, не начнут выполняться, пока не будет выполнен весь итерационный цикл. Результат: вы всегда будете использовать последнее значение диапазона для каждого теста. Дополнительные сведения см. в документации Go по использованию горутин для переменных итератора цикла.
Есть решение проблемы. Вам нужно будет захватить переменную диапазона и использовать ее для выполнения горутины. В приведенном ниже примере кода эта переменная называется tc. Вы также обнаружите, что мы выполняем табличный тест параллельно:
package main
import (
"os"
"testing"
)
func TestReadBooks(t *testing.T) {
cases := []struct {
fixture string
err bool
name string
records int
}{
{
fixture: "testdata/empty.csv",
err: false,
name: "Empty",
records: 0,
},
{
fixture: "testdata/invalid.csv",
err: true,
name: "Invalid",
records: 1,
},
{
fixture: "testdata/valid.csv",
err: false,
name: "Valid",
records: 3,
},
}
for _, tc := range cases {
tc := tc
t.Run(tc.name, func(t *testing.T) {
t.Parallel()
csvFile, err := os.Open(tc.fixture)
if err != nil {
t.Fatal("Can't open CSV file")
}
books, err := ReadBooks(csvFile)
if err != nil && !tc.err {
t.Errorf("Expected an error for file %s", tc.fixture)
}
if tc.records != len(books) {
t.Errorf("Unexpected number of books, got: %d, want: %d.", len(books), tc.records)
}
})
}
}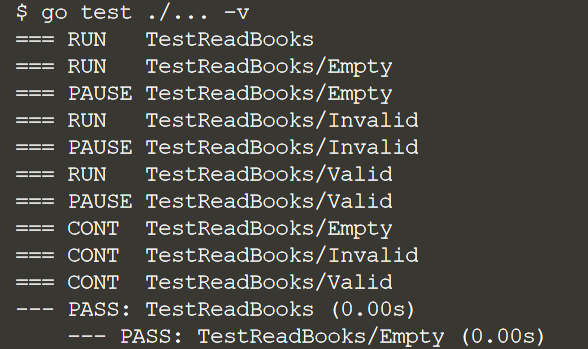
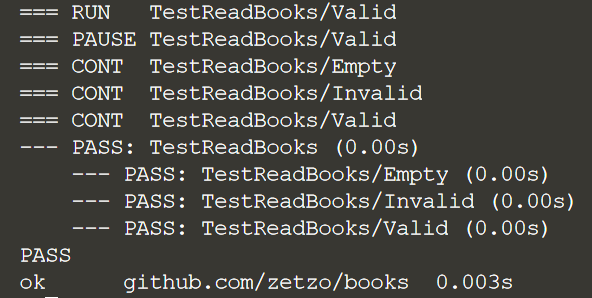
Мы видим, что результат выполнения теста выглядит немного иначе, чем раньше. Он будет четко указывать, когда была запущена горутина.
Мы узнали, как передать несколько итераций тестовых данных одному и тому же фрагменту тестовой логики. Табличные тесты предотвращают необходимость дублирования кода. Итерации можно запускать параллельно с помощью горутин, чтобы ускорить общее время выполнения.
В завершение хочу порекомендовать бесплатный вебинар, который будет полезен тем, кто мечтает о новой интересной карьере в актуальной профессии и интересуется тестированием, но испытывает страх перед будущими интервью.