http://habrahabr.ru/post/265783/
Цены на жильё формируются из многочисленных факторов, основные из которых — это близость к центру города и наличие рядом различной инфраструктуры. Но реальные цены только в бумажных газетах и риэлторских сайтах. Мы будем строить свою карту с ценами на недвижимость в Москве при помощи python, яндекс API и matplotlib, специальный репортаж с места событий под катом.
Гипотеза
Как человек, не проживающий в москве, характер цен в москве оцениваю следующим образом:
- очень дорого — в пределах садового кольца
- дорого — от садового кольца до ТТК
- не очень дорого — между ТТК и МКАД, а цена линейно убывает в сторону МКАДа
- дешево — за МКАДом
На карте будут присутствовать локальные максимумы и минимумы в связи с близостью важных объектов или промышленных зон. А также будет разрыв в ценах до МКАДа и после, т.к. это кольцо в основном совпадает с административной границей города.
Сотни строчек великолепного и не очень python-кода будут доступны в конце статьи по ссылке.
Для исследований я взял два сайта о недвижимости с данными за лето этого года. Всего в выборке участвовали 24,000 записей о новостройках и вторичном жилье, причём разные объявления с одним адресом усреднялись по цене.
Объявления парсились скриптом и хранились в sqlite базе данных в формате:
широта, долгота, цена за кв.м.
О веб паукахДа, из-за недостатка знаний, никаких сторонних библиотек не было использовано и это повлекло за собой создание двух отдельных скриптов по одному на каждый сайт, дёргающих адреса, метраж и стоимость квартир. Адреса волшебным образом превращались в координаты посредством Google Geocoder API. Но из-за довольно низкой планки
квоты на использование был вынужден запускать скрипт каждый день в течении недели. Геокодер яндекса в 10 раз
бесплатнее .
Строим функцию
Для обобщения функции на всю плоскость её необходимо проинтерполировать по имеющимся точкам. Для этого подойдёт функция
LinearNDInterpolator из модуля scipy. Для этого только необходимо установить python с наобором научных библиотек, известный как scipy. В случае, когда данные очень разнородны, практически невозможно подобрать правдоподобную функцию на плоскости. Метод
LinearNDInterpolator использует триангуляцию
Делоне, разбивая всю плоскость на множество треугольников.
Важный фактор, который нужно учитывать при построении функций — разброс значений функции. Среди объявлений попадаются настоящие монстры с ценой за квадратный метр больше 10 млн. рублей
внутри кремля, они испортят график и вы увидите лишь однородное поле с яркой точкой. Для того, чтобы на графике можно было различить практически все данные, такие значения нужно отфильтровывать границей, подбираемой эмпирическим путём. Для статистической модели эти значения не несут полезной информации.
А тем временем, результат интерполяции выглядит как градиентный ад (кликабельно):
Чтобы получить удобную для восприятия карту, нужно распределить полученные значения на дискретные уровни. После чего карта становится похожей на страничку из атласа за 7й класс (кликабельно):
О дискретизации на картеВ зависимости от того, хотим мы видеть общую картину цен или флуктуации вблизи среднего значения, необходимо применить
компадирование данных, т.е. распределение данных равномернее на шкалу значений, уменьшая больше значения и увеличивая маленькие. В коде это выглядит так:
zz = np.array(map(lambda x: map(lambda y: int(2*(0.956657*math.log(y) - 10.6288)) , x), zz)) #HARD
zz = np.array(map(lambda x: map(lambda y: int(2*(0.708516*math.log(y) - 7.12526)) , x), zz)) #MEDIUM
zz = np.array(map(lambda x: map(lambda y: int(2*(0.568065*math.log(y) - 5.10212)) , x), zz)) #LOW
Функции подбирались эмпирическим путём при помощи аппроксимации по 3м-4м точкам на
wolframalpha.
Стоит заметить, что метод линейной интерполяции не может делать расчёт значений за пределами граничных точек. Тем самым на графике с достаточном большим масштабом мы увидим оченьмногоугольник. Масштаб необходимо выбрать таким образом, чтобы график был полностью вписан в получившуюся фигуру.
Другим взглядом на статистику может послужить карта с областями низких и высоких цен. Динамически варьируя границу разбиения на низкие и высокие цены мы сможем увидеть положение цен в динамике. Значение цены в каждой точке уже не будет играть роли, вклад вносит только кучность точек той или иной группы (кликабельно).
Расчёты похожи на расчёт гравитационного поля в точке. Для оптимизации будем брать в расчёт только те точки, которые действительно вносят вклад в конечное значение поля. После расчётов, результат напоминает брызги (кликабельно).
Какое ещё преобразование?При строгом построении графика поля, на нём видно россыпь точек, соответствующих локальному преобладанию “дорогого” поля над “недорогим” и наоборот. Эти точки похожи на шум и портят график. Убрать их можно, например, медианным фильтром над изображением с достаточном большим значением. Для этого я использовал командный интерфейс программы IrfanView.
Визуализация
Совмести полученные изображения со схематичной картой Москвы. Яндекс API позволяет взять карту по координатам и указать для неё угловые размеры по долготе и широте, а так же желаемый размер изображения.
Пример запроса:
http://static-maps.yandex.ru/1.x/?ll=37.5946002,55.7622764&spn=0.25,0.25&size=400,400&l=map
Проблема заключается только в том, что указанные угловые размеры определяют не границы видимой области, а её гарантируемый размер. Это значит, что мы получим картинку с угловыми размерами >= 0.25. Способа совладать с границами видимых координат обнаружено не было, и они искались вручную.
О подгонианеВыровнять карты друг относительно друга можно при помощи яндекс меток, рисуя точки на карте с заданными координатами и получая карту с метками.
За пару вызовов из библиотеки PIL изображения совмещаются с комфортными для наблюдения уровнями прозрачности.
map_img = Image.open(map_img_name, 'r').convert('RGBA')
price_img = Image.open(prices_img_name, 'r').convert('RGBA')
if price_img.size == map_img.size:
result_img = Image.blend(map_img, price_img, 0.5)
Результаты
Три изображения с разными уровнями компандирования и анимация варианта с полем.
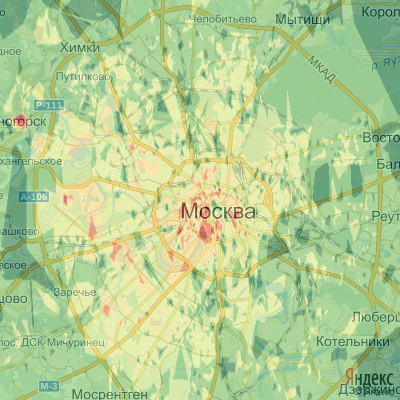
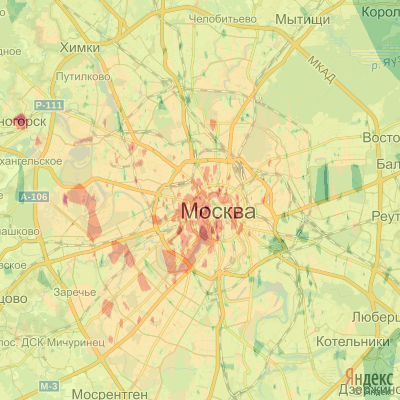

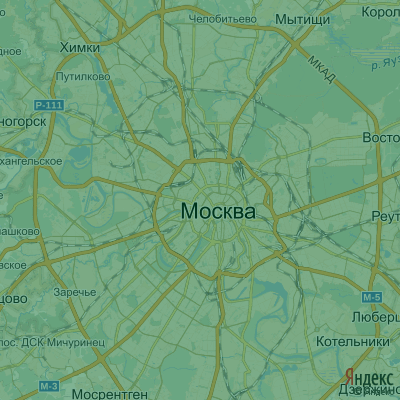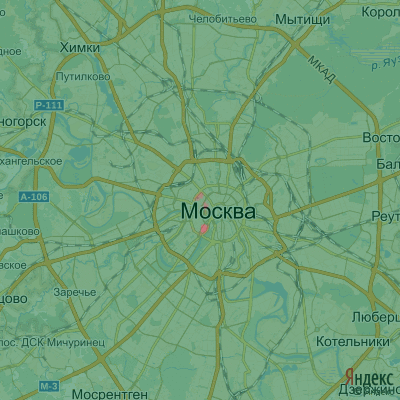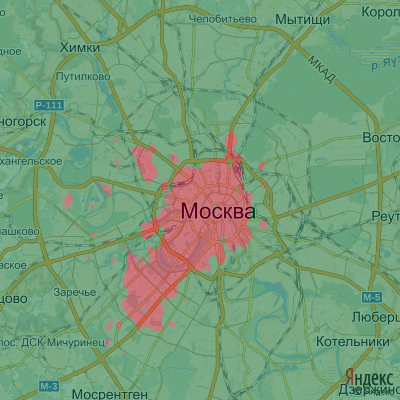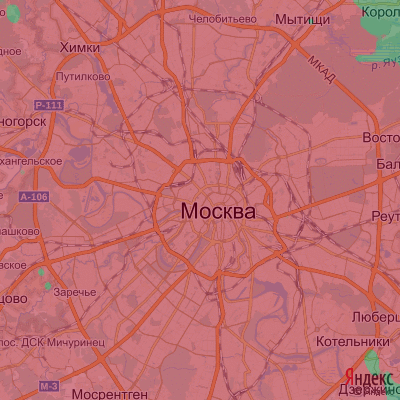
Немного аналитики:
В целом, как и предсказывала гипотеза, внутри садового кольца и кольца ТТК цены на жильё максимальны и убывают по мере удаления от центра. Однако в пределах МКАД, средняя цена сохраняется в западной и юго-западной частях. За пределами МКАД, а так же в восточной части за ТТК цена ниже средней.
В деталях всё намного интересней, отметим основные области:
В лужниках и воробьёвых горах жить довольно дорого жилой недвижимости в области воробьёвых гор нет, скорее все область была построена по граничным значениям сверху и снизу- Жилые массивы вблизи фундаментальной библиотеки МГУ, строящиеся и построенные высотки у мосфильмовского пруда стоят дороже предположительно из-за активной стройки и обширных лесопарковых участков. Высокая цена на территории от мемориальной синагоги и сквером им. Анны Герман так же обусловлена окружающими ценами и своим местоположением среди парков и заказника.
- В районе между станцией метро “Крылатское” и проспектом Маршала Жукова жильё так же считается дорогим
- Несмотря на положение за МКАДом и близостью к кладбищу, дома вдоль улицы Генерала Белобородова отличаются высокой ценой.
Как видно на картах, теория вполне подтверждается практикой и удачное сочетание инфраструктуры, расстояния до центра и близости к известным московским сооружениям будет выявлено функцией линейной интерполяции над координатами.
К сожалению, проделанная работа во многом не автоматизируется, но если статья будет интересной хабровчанам, я построю подобные карты остальных больших городов нашей страны.
Код веб пауков, самой программы, а так же использованные базы данных доступны через
GitHub.



