https://habr.com/ru/company/ruvds/blog/473770/- Блог компании RUVDS.com
- Разработка веб-сайтов
- Python
Сегодня публикуем вторую часть перевода материала, посвящённого статическому анализу больших объёмов серверного Python-кода в Instagram.

→
Первая часть
Программисты, которые устали от линтинга
Учитывая то, что у нас имеется около сотни собственных правил линтинга, педантичный учёт рекомендаций, выдаваемых этими правилами, может быстро вылиться в пустую трату времени разработчиков. Время, которое уходит на выправление стиля кода или на избавление от устаревших паттернов, лучше было бы потратить на создание чего-то нового и на развитие проекта.
Мы обнаружили, что когда программисты видят слишком много уведомлений, поступающих от линтера, они начинают все эти сообщения игнорировать. Это относится и к важным уведомлениям.
Предположим, мы решили признать устаревшей функцию
fn и использовать вместо неё функцию с более удачным именем —
add. Если не сообщить об этом разработчикам — они не узнают о том, что функцию
fn им больше использовать не нужно. А ещё хуже то, что они не узнают о том, что нужно использовать вместо этой функции. В этой ситуации можно создать правило линтера. Но любая большая кодовая база уже будет содержать множество правил. В результате есть вероятность того, что важное уведомление линтера потеряется в куче уведомлений о мелких недочётах.
Линтер слишком сильно придирается к мелочам и «полезный сигнал» легко может потеряться в «шуме»
Что же нам с этим делать?
Можно автоматически исправить множество проблем, обнаруженных линтером. Если сам линтер можно сравнить с документацией, которая появляется там, где она нужна, то такие вот автоматические исправления — это нечто вроде рефакторинга кода, который выполняется там, где в нём возникает необходимость. Учитывая большое количество разработчиков, трудящихся в Instagram, практически невозможно обучить каждого из них нашим лучшим методикам написания кода. Добавление в систему возможностей по автоматическому исправлению кода позволяет нам обучать разработчиков новым методикам тогда, когда они об этих методиках не знают. Это помогает нам быстро вводить разработчиков в курс дела. Автоматические исправления, кроме того, позволили нам сделать так, чтобы программисты были бы сосредоточены на важных вещах, а не распыляли бы внимание на однообразные мелкие правки кода. В целом можно отметить, что автоматические исправления кода — это более эффективно и полезно в плане обучения разработчиков, нежели простые уведомления линтера.
Итак, как же создать систему автоматического исправления кода? Линтинг, основанный на синтаксическом дереве, даёт нам сведения о неблагополучном узле. В результате нам не нужно создавать логику для обнаружения проблем, так как у нас уже имеются соответствующие правила линтера! Так как мы знаем о том, какой именно узел нас не устраивает, и о том, где именно расположен его исходный код, мы можем, не рискуя что-то испортить, например, заменить имя функции
fn на
add. Это хорошо подходит для исправления единичных нарушений правил, выполняемого по мере обнаружения таких нарушений. А как быть, если мы вводим новое правило линтера, что означает, что в кодовой базе могут быть сотни фрагментов кода, которые этому правилу не соответствуют? Можно ли заблаговременно исправить все эти несоответствия?
Кодмоды
Кодмод (codemod) — это всего лишь способ поиска проблем и внесения изменений в исходный код. Кодмоды основаны на скриптах. Кодмод можно представить себе как «рефакторинг на стероидах». Диапазон задач, решаемых кодмодами, чрезвычайно широк: от простых, вроде переименования переменной в функции, до сложных, таких, как переписывание функции так, чтобы она принимала бы новый аргумент. При работе кодмода используются те же концепции, что и при работе линтера. Но вместо того, чтобы сообщать программисту о проблеме, как это делает линтер, кодмод автоматически эту проблему решает.
Как написать кодмод? Рассмотрим пример. Здесь мы хотим отказаться от использования
get_global. В этой ситуации можно использовать и линтер, но неизвестно будет — сколько времени уйдёт на исправление всего кода, к тому же, эта задача будет распределена между множеством разработчиков. При этом, даже если в проекте используется система автоматического исправления кода, на то, чтобы обработать весь код, может потребоваться некоторое время.
Мы хотим отойти от использования get_global и вместо этого пользоваться переменными экземпляра
Для решения этой проблемы мы можем, вместе с правилом линтера, её обнаруживающим, написать и кодмод. Мы полагаем, что если позволить устаревшим паттернам и API постепенно покидать код — это будет отвлекать разработчиков и ухудшать читабельность кода. Мы предпочитаем сразу убрать устаревший код, а не наблюдать за тем, как он постепенно исчезает из проекта.
Учитывая объёмы нашего кода и количество активных разработчиков, это часто означает автоматическое устранение устаревших конструкций. Если мы в состоянии быстро очищать код от устаревших паттернов, это значит, что мы можем поддерживать продуктивность всех разработчиков Instagram.
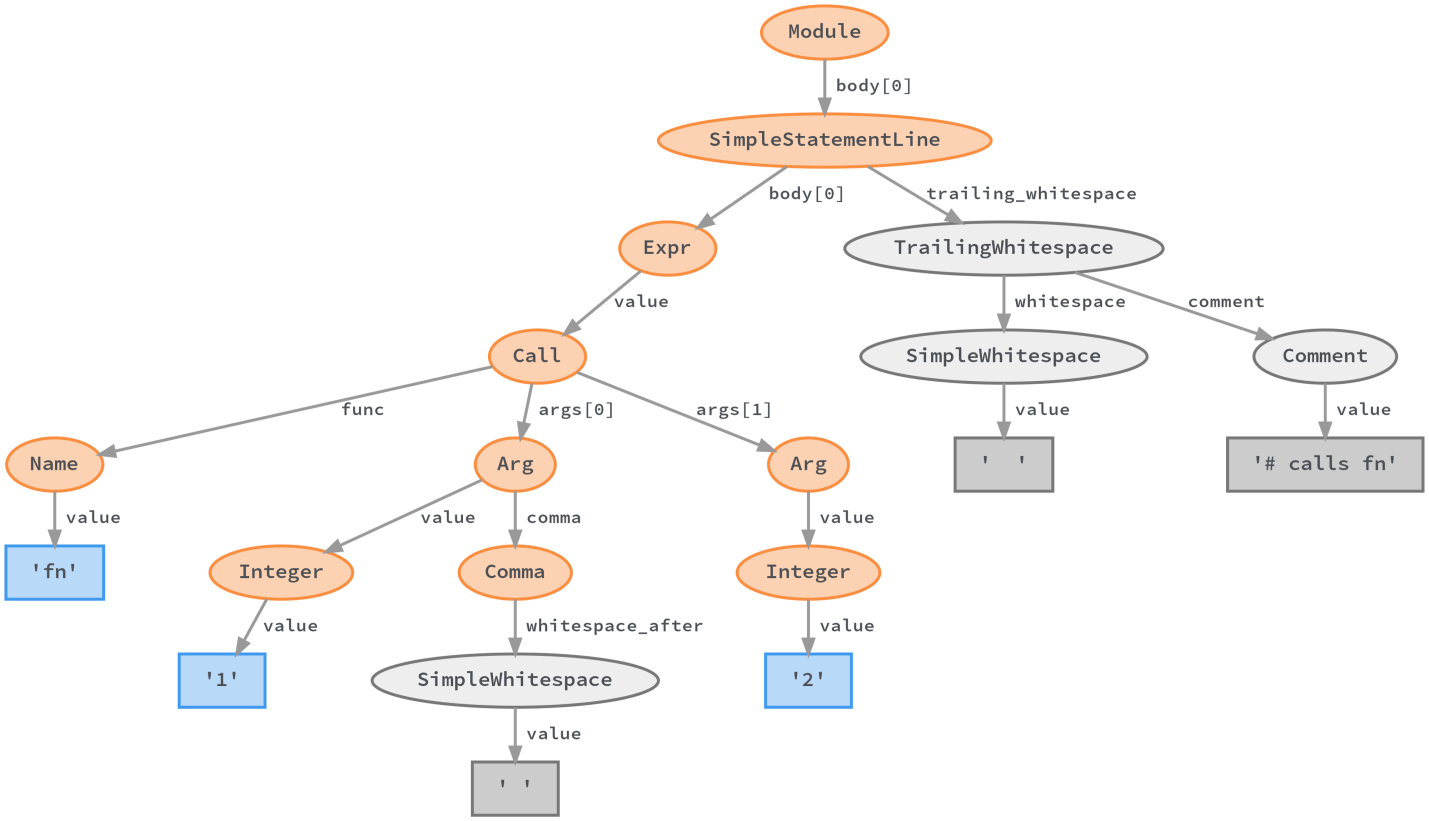
Итак, как же сделать кодмод? Как заменить лишь интересующий нас фрагмент кода, сохранив при этом комментарии, отступы и всё остальное? Существуют средства, основанные на конкретном синтаксическом дереве (вроде того, что создаёт LibCST), которые позволяют с хирургической точностью модифицировать код и сохранять в нём все вспомогательные конструкции. В результате, если нам надо поменять имя функции с
fn на
add в нижеприведённом дереве, то мы можем записать в узел
Name имя
add вместо
fn, а затем записать дерево на диск!
Кодмод можно сделать, записав в узел Name имя add вместо имени fn. Потом изменённое дерево можно записать на диск. Подробности об этом можно почитать в документации к LibCST
Теперь, когда мы немного познакомились с кодмодами, давайте взглянем на практический пример. Сотрудники Instagram упорно трудятся для того, чтобы сделать кодовую базу проекта полностью типизированной. Кодмоды серьёзно помогают им в этом деле.
Если у нас имеется некоторый набор нетипизированных функций, которые нужно типизировать, мы можем попытаться сгенерировать возвращаемые ими типы путём обычного вывода типов! Например, если функция возвращает значения лишь одного примитивного типа — мы просто назначаем функции этот тип возвращаемого значения. Если функция возвращает значения логического типа, например, если она что-то с чем-то сравнивает или что-то проверяет, то мы можем назначить ей тип возвращаемого значения
bool. Мы обнаружили, что в ходе практической работы с кодовой базой Instagram это — довольно-таки безопасная операция.
Выяснение типов значений, возвращаемых функциями
А что если функция явно никакого значения не возвращает, или неявно возвращает
None? Если функция ничего явно не возвращает — ей можно назначить тип
None.
Это, в отличие от предыдущего примера, может быть более опасным из-за существования распространённых паттернов, которые используют разработчики. Например, в методе базового класса можно выбросить исключение
NotImplemented, а в методах подклассов, переопределяющих этот метод можно вернуть строку. Важно отметить, что все эти техники являются эвристическими, но результаты их применения достаточно часто оказываются правильными. В результате их можно признать полезными.
Функции, которые ничего не возвращают
Расширение возможностей кодмодов с помощью Pyre
Продвинемся на шаг вперёд. В Instagram используется Pyre — полномасштабная система для статической проверки типов, похожая на mypy. Применение Pyre позволяет нам проверять типы в кодовой базе. Что если бы мы использовали данные, генерируемые Pyre, для того, чтобы расширить возможности кодмодов? Ниже приведён пример таких данных. Несложно заметить, что тут есть практически всё, что нужно для автоматического исправления аннотаций типов!
$ pyre
ƛ Found 2 type errors!
testing/utils.py:7:0 Missing return annotation [3]: Returning `SomeClass` but no return type is specified.
testing/utils.py:10:0 Missing return annotation [3]: Returning `testing.other.SomeOtherClass` but no return type is specified.
Pyre в ходе работы выполняет детальный анализ порядка выполнения каждой функции. В результате этот инструмент может иногда с очень высокой долей вероятности сделать предположение о том, что должна возвращать неаннотированная функция. Это означает, что если Pyre полагает, что функция возвращает простой тип — мы назначаем данной функции этот тип возвращаемого значения. Однако теперь нам, в потенциале, нужно обрабатывать и команды импорта. Это означает, что нам нужно знать, импортировано ли что-то или объявлено локально. Позже мы кратко затронем эту тему.
Какие преимущества мы получим от автоматического добавления в код сведений о типах, которые легко выводятся? Ну, типы — это документация! Если функция полностью типизирована, то разработчику не придётся читать её код для того, чтобы выяснить особенности её вызова и особенности использования того, что она возвращает.
def get_description(page: WikiPage) -> Optional[str]:
if page.draft:
return None
return page.metadata["description"] # <- что это за тип?
Многие из нас сталкивались с похожим Python-кодом. В кодовой базе Instagram тоже встречается нечто подобное. Если функция
get_description была бы нетипизирована, то понадобилось бы заглянуть в несколько модулей для того, чтобы выяснить то, что она возвращает. При этом, даже если речь идёт о более простых функциях, типы возвращаемых значений которых легко вывести, их типизированные варианты воспринимаются легче, чем нетипизированные.
Кроме того, Pyre не проверяет корректность работы тела функции в том случае, если функция не является полностью аннотированной. В следующем примере вызов
some_function окажется неудачным. Об этом хорошо было бы знать до того, как код попадёт в продакшн.
def some_function(in: int) -> bool:
return in > 0
def some_other_function():
if some_function("bla"): # <- тут должно быть обнаружено нарушение
print("Yay!")
В данном случае о подобной ошибке мы вполне можем узнать уже после того, как код ушёл в продакшн. Дело в том, что у
some_other_function нет аннотации типа возвращаемого значения. Если бы мы аннотировали её с помощью наших эвристических механизмов, используя автоматически выведенный тип
None, то мы обнаружили бы неувязку с типами ещё до того, как она могла бы вызвать какие-то проблемы. Это, конечно, искусственный пример, но в Instagram подобные проблемы — это серьёзно. Если у вас имеются миллионы строк кода, то вы, в процессе код-ревью, вполне можете упустить такие вот вещи, которые кажутся совершенно очевидными в простом примере.
В Instagram вышеописанные методики, основанные на автоматически выводимы типах, позволили типизировать около 10% функций. В результате людям больше не нужно было вручную править тысячи и тысячи функций. Преимущества типизированного кода очевидны, но это, в контексте нашего разговора, ведёт к ещё одному важному преимуществу. Полностью типизированная кодовая база открывает ещё более широкие возможности для обработки кода с помощью кодмодов.
Если мы доверяем аннотациям типов, это значит, что Pyre может открыть нам дополнительные возможности. Взглянем снова на тот пример, где мы переименовывали функции. Что если сущность, которую мы переименовываем, представлена методом класса, а не глобальной функцией?
Функция является методом класса
Если объединить информацию о типах, полученную от Pyre, и кодмод, выполняющий переименование функций, можно, неожиданно для себя, внести исправления и туда, где функция вызывается, и туда, где она объявлена! В данном примере, так как мы знаем о том, что располагается в левой части конструкции
a.fn, мы знаем и о том, что можно безопасно поменять эту конструкцию на
a.add.
Более продвинутый статический анализ
В Python есть четыре типа областей видимости: глобальная область видимости, области видимости уровня классов и функций, вложенная область видимости
Анализ областей видимости позволяет нам использовать ещё более мощные кодмоды. Помните один из вышеприведённых примеров, где мы говорили о том, что добавление аннотаций типов может означать и необходимость работы с командами импорта? Если в системе выполняется анализ областей видимости, это значит, что мы можем знать о том, какие типы, используемые в файле, присутствуют в нём благодаря командам импорта, какие объявлены локально, а какие — отсутствуют. Аналогично, если известно, что глобальная переменная перекрывается аргументом функции, можно избежать случайного изменения имени такого аргумента при переименовании глобальной переменной.
Итоги
В нашем стремлении к исправлению всех ошибок в коде Instagram мы поняли одну вещь. Она заключается в том, что поиск кода, который нужно исправить, часто важнее, чем само исправление. Программистам нередко приходится решать простые задачи — вроде переименования функций, добавления аргументов к методам или разделения модулей на части. Всё это — обычные дела, но размеры нашей кодовой базы означают, что человек не сможет найти каждую строку, которую нужно изменить. Именно поэтому так важно совмещение возможностей кодмодов с надёжным статическим анализом. Это позволяет нам увереннее находить те участки кода, которые нужно менять, а значит — позволяет делать кодмоды безопаснее и мощнее.
Уважаемые читатели! Используете ли вы кодмоды?