https://habr.com/ru/company/ruvds/blog/473766/- Блог компании RUVDS.com
- Разработка веб-сайтов
- Python
Серверный код в Instagram пишут исключительно на Python. Ну, в основном это именно так. Мы используем немного Cython, а в состав зависимостей входит немало C++-кода, с которым можно работать из Python как с C-расширениями.

Наше серверное приложение — это монолит, представляющий собой одну большую кодовую базу, состоящую из нескольких миллионов строк и включающую в себя несколько тысяч конечных точек Django (
вот выступление, посвящённое использованию Django в Instagram). Всё это загружается и обслуживается как единая сущность. Из монолита выделено несколько сервисов, но в наши планы не входит сильное разделение монолита.
Наша серверная система — это монолит, который очень часто меняется. Каждый день сотни программистов делают сотни коммитов в код. Мы непрерывно разворачиваем эти изменения, делая это каждые семь минут. В результате развёртывание проекта в продакшне выполняется около ста раз за сутки. Мы стремимся к тому, чтобы между попаданием коммита в ветку master и развёртыванием соответствующего кода в продакшне проходило бы менее часа (
вот выступление об этом, сделанное на PyCon 2019).
Очень сложно поддерживать эту огромную монолитную кодовую базу, делая в неё ежедневно сотни коммитов, и при этом не довести её до состояния полного хаоса. Мы хотим сделать Instagram местом, работая в котором, программисты могут быть продуктивными и способными быстро готовить к выходу новые полезные возможности системы.
Этот материал посвящён тому, как мы пользуемся линтингом и автоматическим рефакторингом для того чтобы облегчить управление кодовой базой, написанной на Python.
Если вам интересно будет опробовать некоторые идеи, упомянутые в этом материале, то знайте, что недавно мы перевели в разряд опенсорсных проект
LibCST, который лежит в основе многих наших внутренних инструментов, предназначенных для линтинга и автоматического рефакторинга кода.
Linting: документация, которая появляется там, где она нужна
Линтинг помогает программистам находить и диагностировать проблемы и антипаттерны, о которых сами разработчики могут и не знать, не замечая их в коде. Для нас это важно из-за того, что соответствующие идеи, касающиеся устройства кода, тем сложнее распространять, чем больше программистов трудится над проектом. В нашем случае речь идёт о сотнях специалистов.
Разновидности линтинга
Линтинг — это всего лишь одна из многих разновидностей статического анализа кода, которые мы используем в Instagram.
Самый примитивный способ реализации правил линтинга — это использование регулярных выражений. Регулярные выражения писать несложно, но Python — это
не «регулярный» язык. В результате очень сложно (а иногда и невозможно) надёжно искать паттерны в Python-коде с помощью регулярных выражений.
Если говорить о самых сложных и продвинутых способах реализации линтеров, то тут находятся инструменты вроде
mypy и
Pyre. Это — две системы для статической проверки типов Python-кода, которые могут выполнять глубокий анализ программ. В Instagram используется Pyre. Это — мощные инструменты, но их тяжело расширять и настраивать.
Когда мы говорим о линтинге в Instagram, мы обычно имеем в виду работу с простыми правилами, основанными на абстрактном синтаксическом дереве. Именно нечто подобное лежит в основе написания наших собственных правил линтинга для серверного кода.
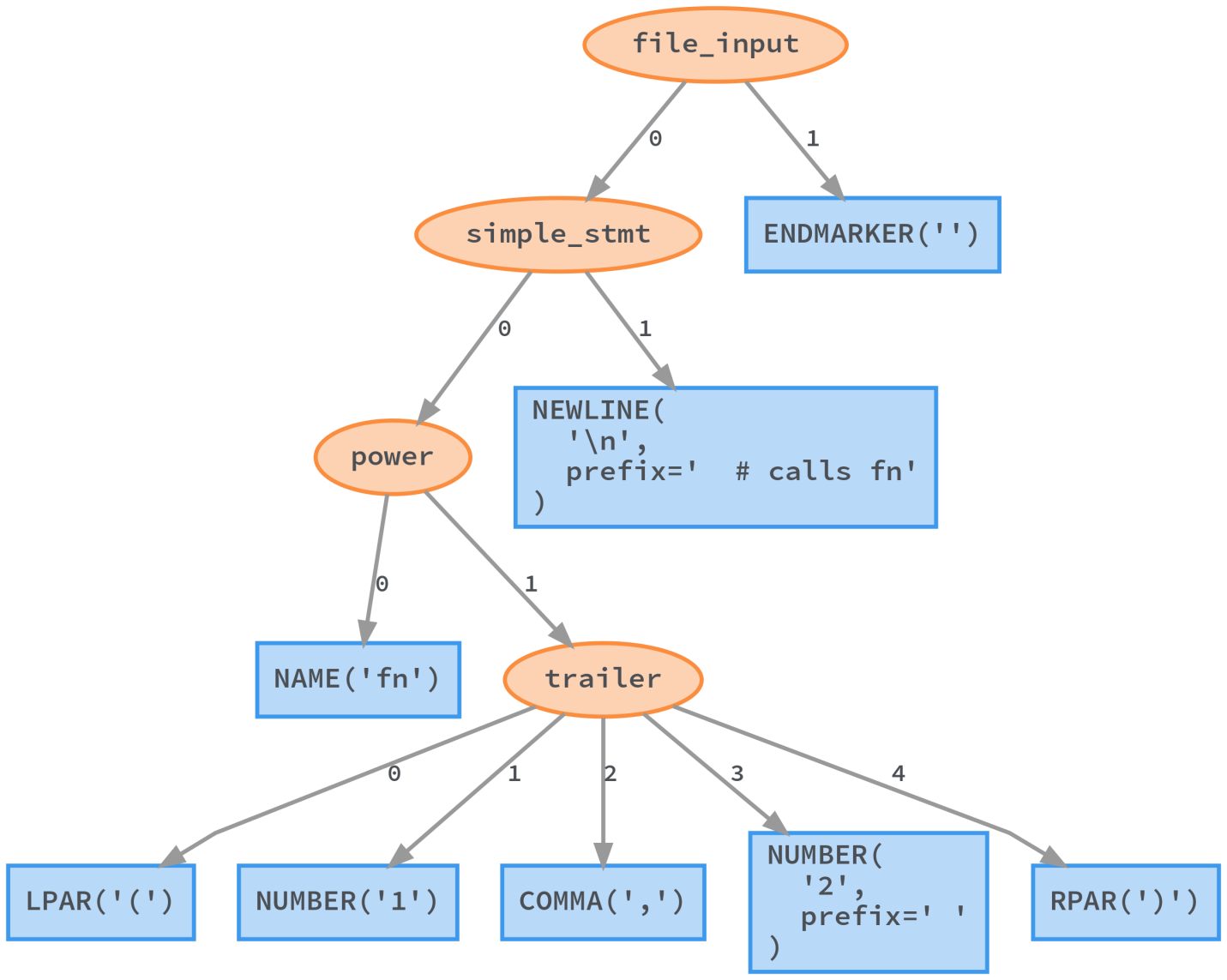
Когда Python выполняет модуль, он начинает работу с запуска парсера и с передачи ему исходного кода. Благодаря этому создаётся дерево разбора — разновидность конкретного синтаксического дерева (concrete syntax tree, CST). Это дерево представляет собой свободное от потерь представление входного исходного кода. В этом дереве сохранена каждая деталь вроде комментариев, скобок и запятых. На основе CST можно полностью восстановить изначальный код.
Дерево разбора Python (разновидность CST), сгенерированное lib2to3
К сожалению, подобный подход приводит к созданию сложного дерева, что затрудняет извлечение из него интересующих нас семантических сведений.
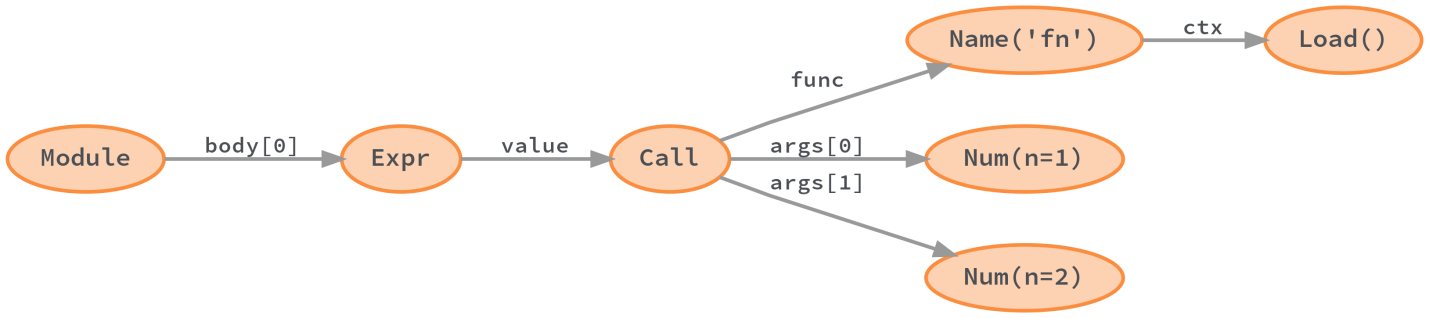
Python компилирует дерево разбора в абстрактное синтаксическое дерево (abstract syntax tree, AST). Некоторые сведения об исходном коде при таком преобразовании теряются. Речь идёт о «дополнительной синтаксической информации» — вроде комментариев, скобок, запятых. Однако семантика кода в AST сохраняется.
Абстрактное синтаксическое дерево Python, сгенерированное модулем ast
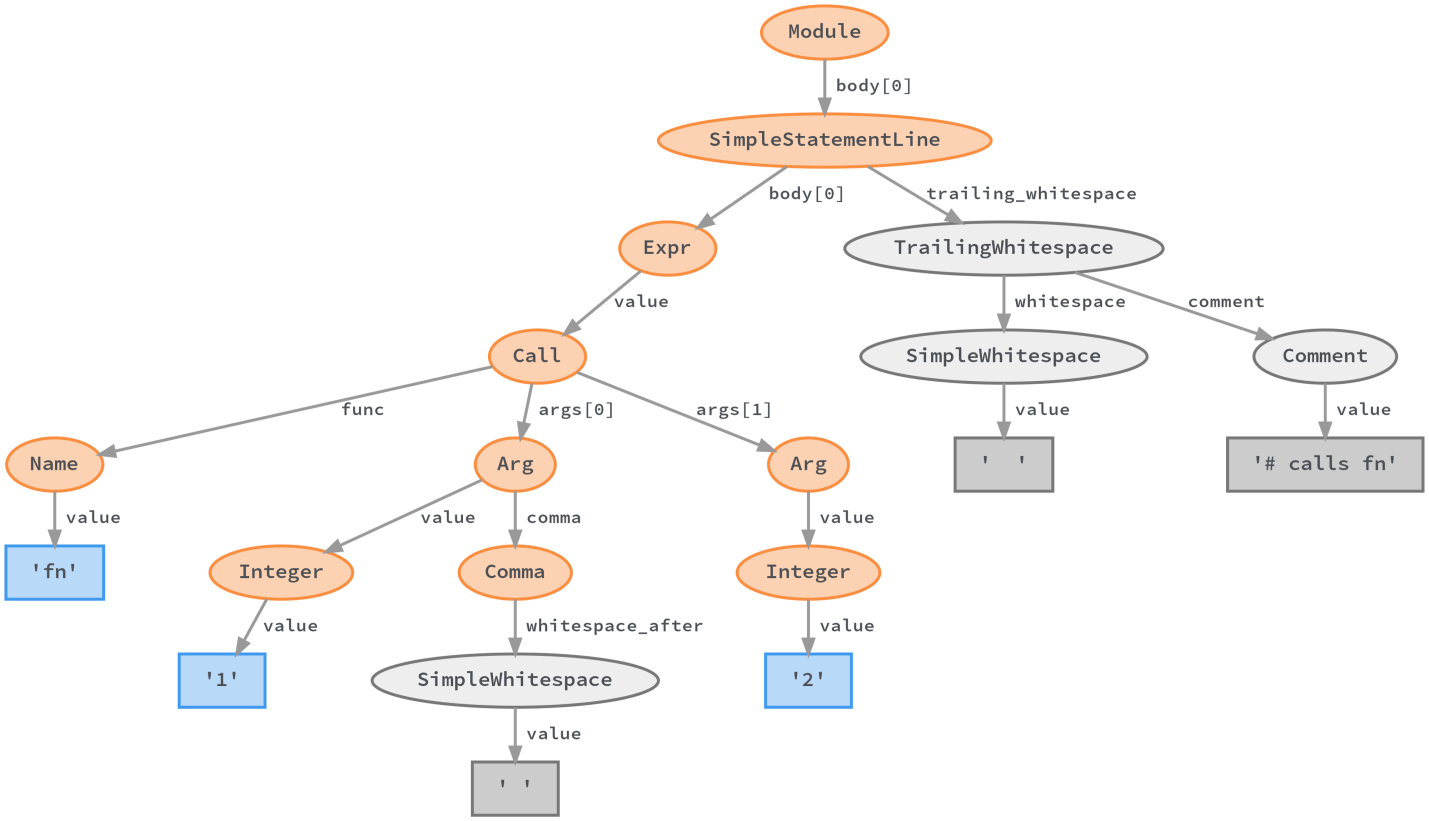
Мы разработали
LibCST — библиотеку, которая даёт нам лучшее из миров CST и AST. Она даёт представление кода, в котором сохраняется вся информация о нём (как в CST), но из такого представления кода легко извлекать семантические сведения о нём (как при работе с AST).
Представление конкретного синтаксического дерева LibCST
Наши правила линтинга используют
синтаксическое дерево LibCST для нахождения паттернов в коде. Это синтаксическое дерево, на высоком уровне, легко исследовать, оно позволяет избавиться от проблем, которые сопутствуют работе с «нерегулярным» языком.
Предположим, что в некоем модуле имеется циклическая зависимость из-за импорта типа. Python позволяет решить эту проблему, поместив команды импорта типов в блок
if TYPE_CHECKING. Это — защита от импорта чего-либо во время выполнения программы.
# команды импорта значений
from typing import TYPE_CHECKING
from util import helper_fn
# команды импорта типов
if TYPE_CHECKING:
from circular_dependency import CircularType
Позже кто-то добавил в код ещё один импорт типа и ещё один защитный блок
if. Однако тот, кто это сделал, мог не знать о том, что такой механизм в модуле уже есть.
# команды импорта значений
from typing import TYPE_CHECKING
from util import helper_fn
# команды импорта типов
if TYPE_CHECKING:
from circular_dependency import CircularType
if TYPE_CHECKING: # Дублирование защитного механизма!
from other_package import OtherType
От этой избыточности можно избавиться с помощью правила линтера!
Начнём с инициализации счётчика «защитных» блоков, найденных в коде.
class OnlyOneTypeCheckingIfBlockLintRule(CstLintRule):
def __init__(self, context: Context) -> None:
super().__init__(context)
self.__type_checking_blocks = 0
Затем, встречая соответствующее условие, мы инкрементируем счётчик, и проверяем, чтобы в коде было бы не более одного подобного блока. Если это условие не соблюдается — мы генерируем предупреждение в соответствующем месте кода, вызывая вспомогательный механизм, используемый для формирования подобных предупреждений.
def visit_If(self, node: cst.If) -> None:
if node.test.value == "TYPE_CHECKING":
self.__type_checking_blocks += 1
if self.__type_checking_blocks > 1:
self.context.report(
node,
"More than one 'if TYPE_CHECKING' section!"
)
Подобные правила линтинга работают, просматривая дерево LibCST и собирая информацию. В нашем линтере это реализовано с помощью паттерна «
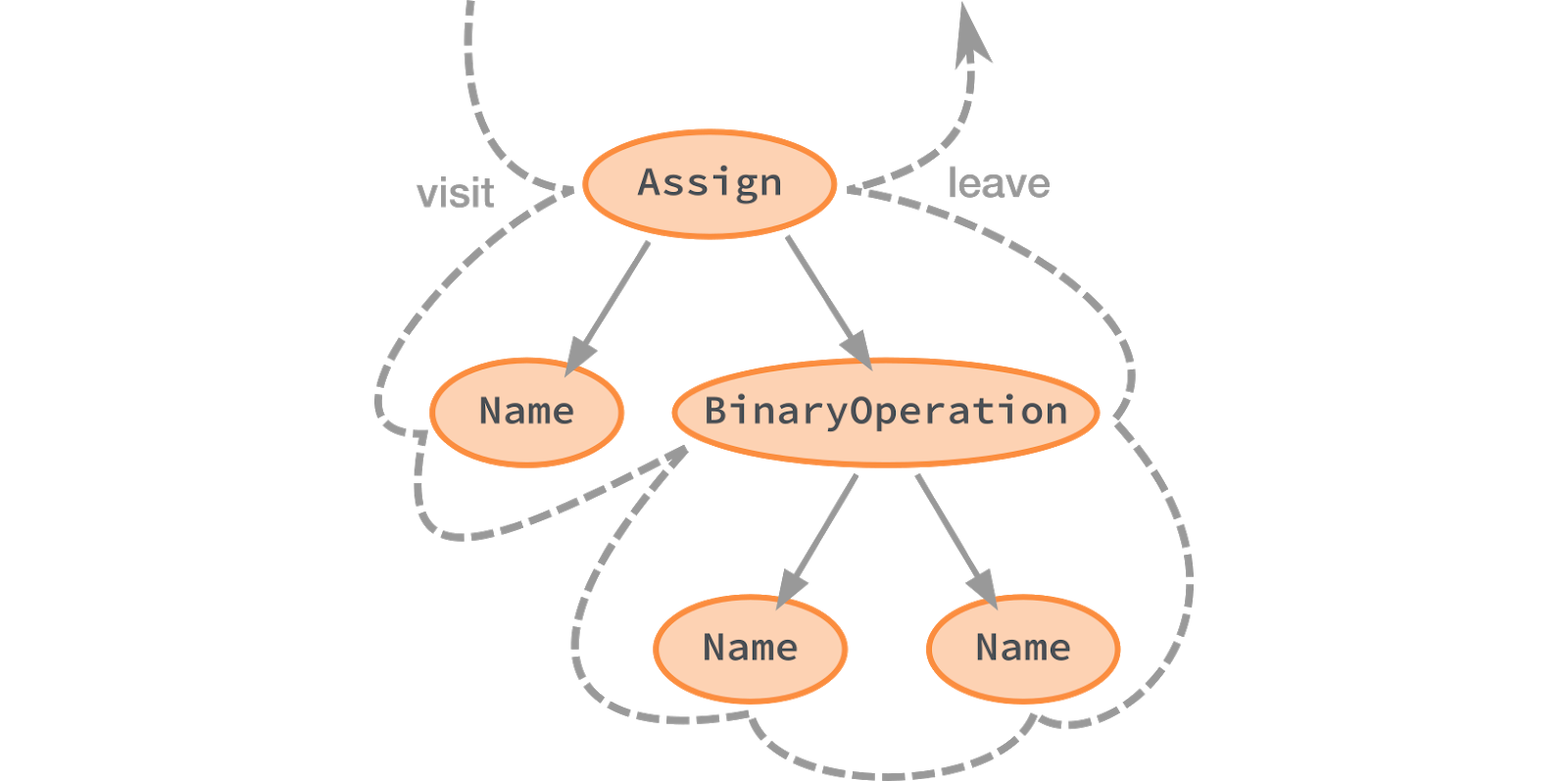
посетитель» (Visitor). Как вы могли заметить, правила переопределяют методы
visit и оставляют методы, связанные с типом узла. Эти «посетители» вызываются в определённом порядке.
class MyNewLintRule(CstLintRule):
def visit_Assign(self, node):
... # вызывается первым
def visit_Name(self, node):
... # вызывается для каждого потомка
def leave_Assign(self, name):
... # вызывается после обработки всех потомков
Методы visit вызываются до посещения потомков узлов. Методы leave вызываются после посещения всех потомков
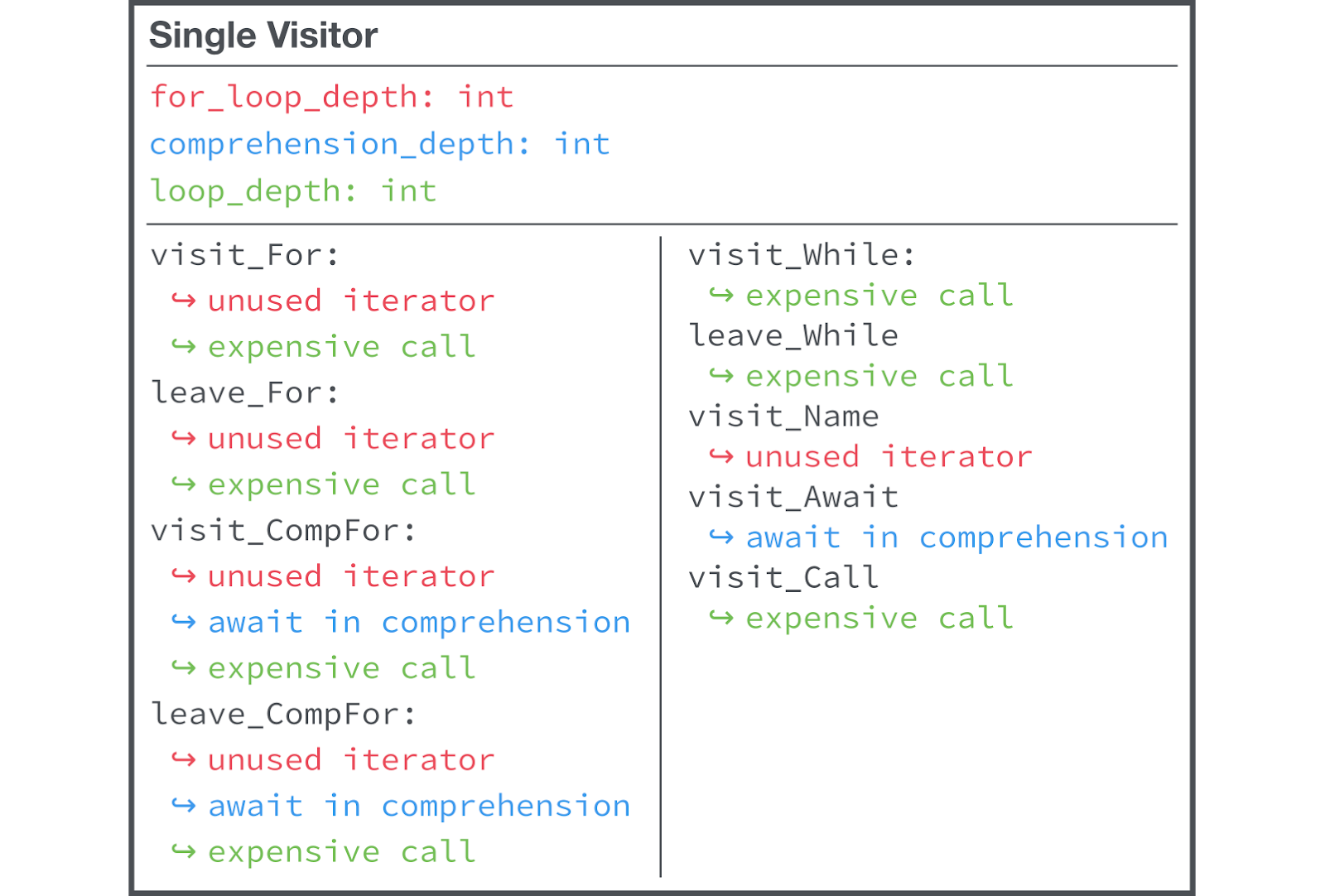
Мы придерживаемся принципов работы, в соответствии с которыми в первую очередь решаются простые задачи. Наше первое собственное правило линтера было реализовано в одном файле, содержало одного «посетителя» и использовало разделяемое состояние.
Один файл, один «посетитель», использование разделяемого состояния
Класс
Single Visitor должен иметь сведения о состоянии и о логике всех наших правил линтинга, не связанных с ним. При этом не всегда очевидно то, какое состояние соотносится с конкретным правилом. Такой подход хорошо показывает себя в ситуации, когда имеется буквально несколько собственных правил линтинга, но у нас таких правил около сотни, что крайне осложнило поддержку паттерна
single-visitor.
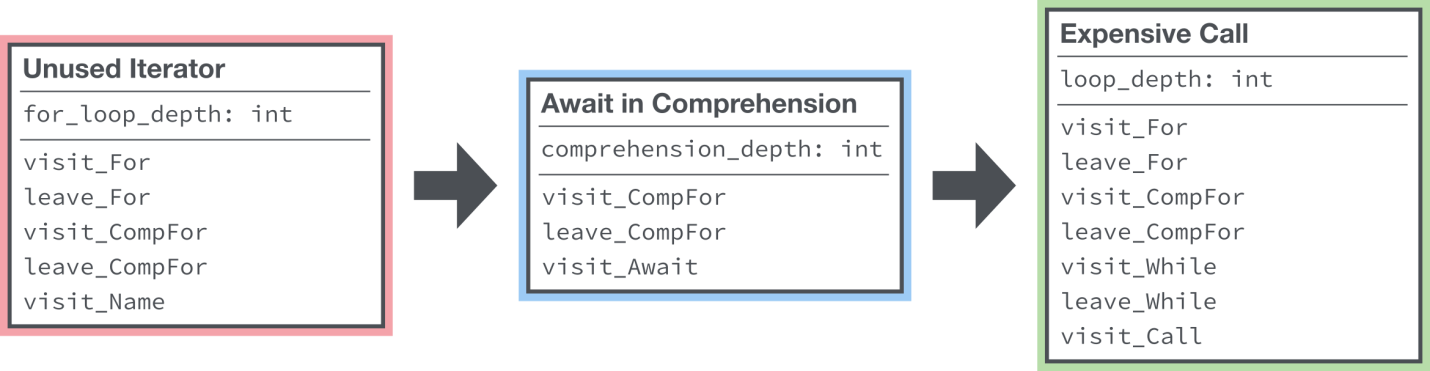
Сложно узнать о том, какое состояние и логика связаны с каждой из проводимых проверок
Конечно, в качестве одного из возможных решений этой проблемы можно было бы рассмотреть определение нескольких «посетителей» и организацию такой схемы работы, чтобы каждый из них каждый раз просматривал бы всё дерево. Однако это привело бы к серьёзному падению производительности, а линтер — это программа, которая должна работать быстро.
Каждое правило линтера может повторно обходить дерево. При обработке файла правила выполняются последовательно. Однако такой подход, при котором часто выполняется обход дерева, привёл бы к серьёзному падению производительности
Вместо того чтобы реализовать у себя нечто подобное, мы вдохновились линтерами, используемыми в экосистемах других языков программирования — вроде
ESLint из JavaScript, и создали централизованный реестр «посетителей» (Visitor Registry).
Централизованный реестр «посетителей». Мы можем эффективно определить то, какой узел интересует каждое правило линтера, экономя время на узлах, которые его не интересуют
Когда правило линтера инициализируют, все переопределения методов правила хранятся в реестре. Когда мы обходим дерево, мы смотрим на всех зарегистрированных «посетителей» и вызываем их. Если метод не реализован — это значит, что вызывать его не нужно.
Это снижает потребление системой вычислительных ресурсов при добавлении в неё новых правил линтинга. Обычно мы проверяем линтером небольшое количество недавно изменённых файлов. Но мы можем выполнить проверку всех правил на всей серверной кодовой базе Instagram в параллельном режиме всего за 26 секунд.
После того, как мы решили вопросы производительности, мы создали фреймворк для тестирования, который был нацелен на соблюдение передовых методик программирования, требуя наличия тестов и в ситуациях, в которых нечто должно обладать неким качеством, и в ситуациях, в которых нечто неким качеством обладать не должно.
class MyCustomLintRuleTest(CstLintRuleTest):
RULE = MyCustomLintRule
VALID = [
Valid("good_function('this should not generate a report')"),
Valid("foo.bad_function('nor should this')"),
]
INVALID = [
Invalid("bad_function('but this should')", "IG00"),
]
Продолжение следует…
Уважаемые читатели! Пользуетесь ли вы линтерами?