http://habrahabr.ru/company/webzilla/blog/227927/
Вступление
Коллеги с соседнего отдела (
UCDN) обратились с довольно интересной и неожиданной проблемой: при тестировании raid0 на большом числе SSD, производительность менялась вот таким вот печальным образом:
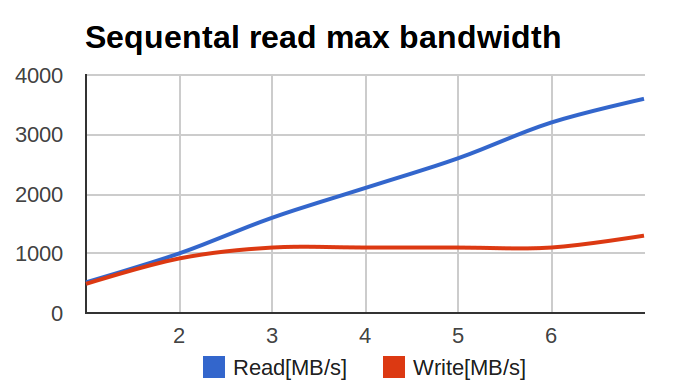
По оси X — число дисков в массиве, по оси Y — мегабайтов в секунду.
Я начал изучать проблему. Первичный диагноз был простой — аппаратный рейд не справился с большим числом SSD и упёрся в свой собственный потолок по производительности.
После того, как аппаратный рейд выкинули и на его место поставили HBA, а диски собрали в raid0 с помощью linux-raid (его часто называют 'mdadm' по названию утилиты командной строки), ситуация улучшилась. Но не прошла полностью -цифры возросли, но всё ещё были ниже рассчётных. При этом ключевым параметром были не IOPS'ы, а многопоточная линейная запись (то есть большие куски данных, записываемых в случайные места).
Ситуация для меня была необычной — я никогда не гонялся за чистым bandwidth рейдов. IOPS'ы — наше всё. А тут — надо многомногомного в секунду и побольше.
Адские графики
Я начал с определения baseline, то есть производительности единичного диска. Делал я это, скорее, для очистки совести.
Вот график линейного чтения с одной SSD.
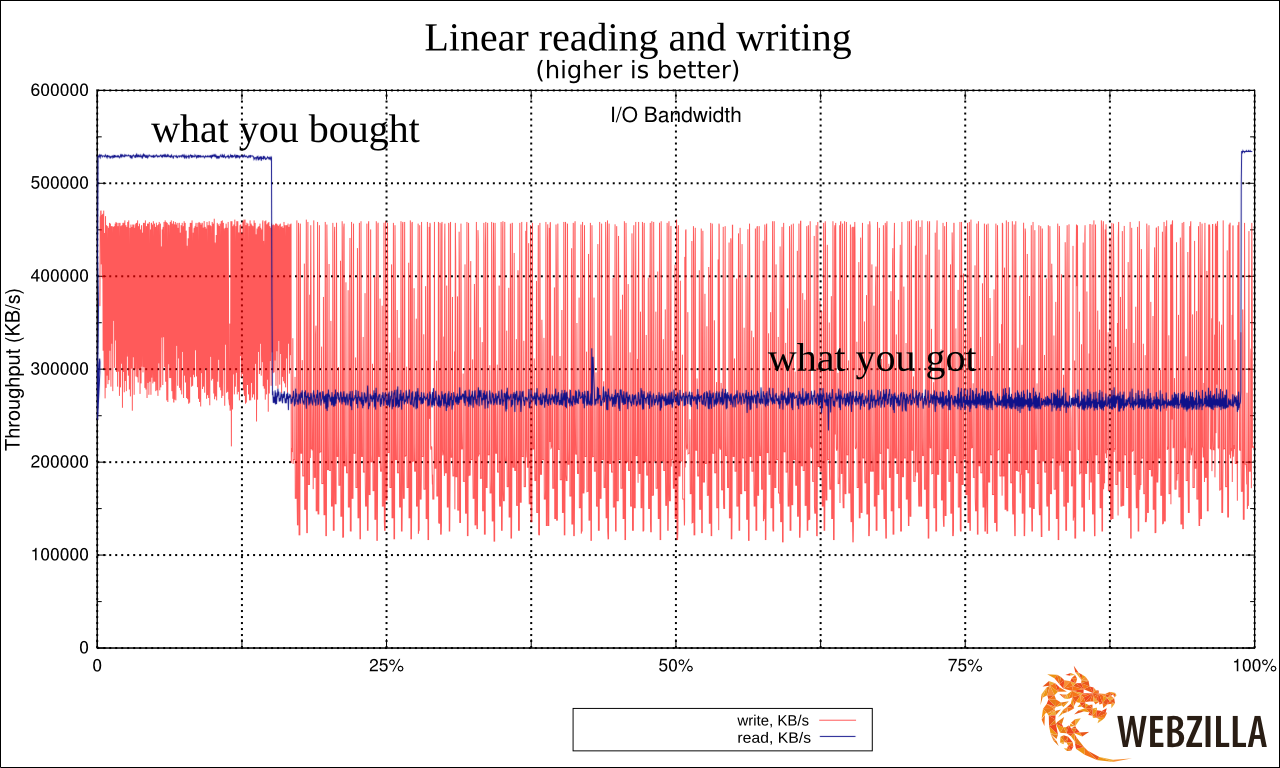
Увидев результат я реально взвился. Потому что это очень сильно напоминало ухищрения, на которые идут производители дешёвых USB-флешек. Они помещают быструю память в районы размещения FAT (таблицы) в FAT32 (файловой системе) и более медленную — в район хранения данных. Это позволяет чуть-чуть выиграть по производительности при работе с мелкими операциями с метаданными, при этом предполагая, что пользователи, копирующие большие файлы во-первых готовы подождать, а во вторых сами операции будут происходить крупными блоками. Подробнее про это душераздирающее явление:
lwn.net/Articles/428584/
Я был уверен в том, что нашёл причину и корень всех проблем и уже готовил язвительное послание (см. подписи на картинке), объясняющее, какое унылое некачественное оборудование класса «удобрение» оказалось на тесте, и многие другие слова, которые лучше не повторять.
Хотя меня смутила версия ядра на стенде — 3.2. По своему предыдущему опыту зная прискорбные особенности LSI, меняющие в драйверах (mpt2sas) от версии к версии буквально всё, я подумал, «а вдруг»?
Немного предыстории. mpt2sas — драйвер LSI для HBA. Живёт невероятно бурной жизнью, начав с версии с версии v00.100.11.15 через версии 01.100.0x.00 дойдя аж до версии 16.100.00.00 (интересно, что означает цифра «100»?). За это время драйвер отличился перестановкой имён букв дисков при обновлении минорной версии ядра, отличающемся от аносируемого биосом порядком дисков, падениями на «неожиданных» конфигурациях LUN'ов, на таймаутах бэкплейна, на неожиданном числе дисков, логгинг ошибок в dmesg со скоростью бесконечного цикла в самом ядре (де-факто это эквивалент зависания системы) и тому подобные весёлые вещи.
Обновились, запустили тест. И этот «вдруг» случился. Вот как выглядит тот же график на 3.14. А ведь я чуть-чуть было не забраковал невинные SSD'шки.

После того, как производительность дисков стабилизировалась, был проведён второй тест: на все диски запустили независимые тесты параллельно. Цель была проста — проверить, нет ли бутылочного горлышка где-то на шине или HBA. Производительность дисков оказалась вполне приличной, «затыка» по шине не было. Основная задача была решена. Однако, график производительности всё-таки отличался. Не сильно, но явно с намёком на хуже чем линейную скорость записи.
Почему запись так себя ведёт по мере увеличения числа дисков в массиве? График (в начале статьи) очень сильно напоминал график производительности многопоточных приложений по мере роста числа потоков, на которые обычно показывают программисты и Intel'овцы, когда говорят о проблемах у взаимных блокировок тредов…
Во время теста в
blktop наблюдалось что-то странное: часть дисков загружена в потолок, часть почти простаивает. Причём загружены в потолок те, кто показывает низкую производительность, а «быстрые» диски простаивают. Более того, диски иногда меняются местами — то есть раньше загруженный на 100% диск вдруг показывает бОльшую скорость и меньшую загрузку, и наоборот, диск, который был загружен на 50%, вдруг оказывается загружен на 100% и при этом показывает меньшую скорость. Почему?
И тут до меня дошло.
raid0 зависит от latency худшего из дисков
Если мы пишем много данных, то запись обычно идёт большими кусками. Эти куски разделяются на меньшие куски драйвером raid0, который записывает их одновременно на все диски из raid0. За счёт этого мы получаем N-кратное увеличение производительности. (В raid0 на N дисков).
Но давайте рассмотрим запись подробнее…
Допустим, у нас raid использует chunk'и размером в 512k. В массиве 8 дисков. Приложение хочет записать много данных, и мы пишем на raid кусками по 4Мб.
Теперь следите за руками:
- raid0 получает запрос на запись, делит данные на 8 кусков по 512кб каждый
- raid0 отправляет (параллельно) 8 запросов на 8 устройств по записи 512кб (каждый своё)
- raid0 ожидает подтверждение от всех 8 устройств о завершении записи
- raid0 отвечает приложению «записал» (то есть возвращает управление из вызова write())
Представим теперь, что у дисков запись произошла за такое время (в милисекундах):
| Диск 1 |
Диск 2 |
Диск 3 |
Диск 4 |
Диск 5 |
Диск 6 |
Диск 7 |
Диск 8 |
| 4.1 |
2.2 |
1.9 |
1.4 |
1.0 |
9.7 |
5.4 |
8.6 |
Вопрос: за какое время произойдёт запись блока в 4Мб на этот массив? Ответ: за 9.7 мс. Вопрос: какая будет в это время утилизация у диска №4? Ответ: порядка 10%. А у диска №6? 100%. Заметим, для примера я выбрал наиболее экстремальные значения из лога операций, но и при меньшем расхождении проблема будет сохраняться. Сравните график чтения и записи (привожу ту же картинку ещё раз):
Видите, как неровно гуляет запись в сравнении с чтением?
У SSD дисков latency на запись очень неровная. Связано это с их внутренним устройством (когда за раз записывается блок большого размера, при необходимости, перемещая и перенося данные с места на место). Чем больше этот блок, тем сильнее пики latency (то есть сиюминутные провалы в производительности). У обычных магнитных дисков графики совсем другие — они напоминают ровную линию практически без отклонений. В случае линейного последовательного IO эта линия проходит высоко, в случае постоянного случайного IO — постоянно низко, но, ключевое — постоянно. Latency у жёстких дисков предсказуема, latency у SSD — нет. Заметим, это свойство есть у всех дисков. У самых дорогих latency оказывается смещена (либо очень быстро, либо очень-очень быстро) — но разнобой всё равно сохраняется.
При подобных колебаниях latency производительность у SSD, в среднем, отличная, но в отдельные моменты времени запись может занять чуть больше, чем в другое время. У тестируемых дисков она падала в этот момент до позорных величин порядка 50Мб/с (что ниже, чем линейная запись у современных HDD раза в два).
Когда на устройство запросы идут стопкой и независимо, это не влияет. Ну да, один запрос выполнился быстро, другой медленно, в среднем всё хорошо.
Но если запись зависит от всех дисков в массиве? В этом случае, любой «тормознувший» диск тормозит всю операцию целиком. В результате, чем больше дисков массиве, тем больше вероятность, что хотя бы один диск отработает медленно. Чем больше дисков, тем больше кривая производительности их суммы в raid0 начинает приближаться к сумме производительности их минимумов (а не средних значений, как хотелось бы).
Вот график реальной производительности в зависимости от числа дисков. Розовая линия — предсказания, базирующиеся на средней производительности дисков, синяя — фактические результаты.

В случае 7 дисков различия составили около 10%.
Простое математическое симулирование (с данными по latency реального диска для ситуации множества дисков в массиве) позволило предсказать, что по мере увеличения числа дисков деградация может дойти до 20-25%.
В отличие от замены HBA или версии драйвера, в этом случае ничего существенно поменять уже нельзя было, и информацию просто приняли к сведению.
Что лучше — HDD или SSD?
Сразу скажу: худшее ожидание от SSD оказывается лучше, чем постоянное от HDD (если прозвучало слишком сложно: SSD лучше, чем HDD).
Другое дело, что массив из 20-30 HDD — это нормально. 30 SSD в raid0 вызовут слюнки у гиков и приступ печёночной колики у финансового отдела. То есть обычно сравнивают множество HDD c несколькими HDD. Если же мы отнормируем цифры по IOPS'ам (охохо), то есть добьёмся от HDD тех же попугаев, что от SSD, то цифры станут, внезапно, другими — массив из большого числа HDD будет сильно обгонять массив из нескольких SSD по скорости записи.
Другое дело, что крупный массив из HDD — это уже экстрим другого рода, и там ждут сюрпризы из-за общего использования шины, производительности HBA и особенностей поведения бэкплейнов.
А raid1/5/6?
Легко понять, что для всех этих массивов проблема с ожиданием «самого медленного» сохраняется, и даже слегка усиливается (то есть проблема возникает при меньшем размере блока и меньшей интенсивности нагрузки).
Заключение
Админское: Не люблю LSI. При обнаружении каких-либо нареканий в работе дисков при участии LSI в системе отладку следует начинать с сравнения поведения разных версий дравйера mpt2sas. Это как раз тот случай, когда смена версии может влиять на производительность и стабильность самым драматичным образом.
Академическое: При планировании высоконагруженных систем с использованием SSD в raid0 следует учитывать, что чем больше в массиве SSD, тем сильнее становится эффект от неравномерной latency. По мере роста числа устройств в raid0 производительность устройства начинает стремиться к произведению числа устройств на минимальную производительность дисков (а не среднюю, как хотелось бы ожидать).
Рекомендации: в случае с подобным типом нагрузки следует стараться выбирать устройства с наименьшим разбросом по latency на запись, по возможности использовать устройства с большей ёмкостью (для уменьшения числа устройств).
Особое внимание стоит обратить на конфигурации, в которых часть или все диски подключаются по сети с неравномерной задержкой, такая конфигурация вызовет значительно ольшие затруднения и деградацию, чем локальные диски.
