https://habrahabr.ru/post/276745/
Сегодня мы попробуем найти самый дешевый и самый дорогой интернет магазин книг.
Сравнивать будем бумажные книги, которые есть в наличии. В разных магазинах очень разное количество книг. Где-то менее 1000, а где-то более 200 000 книг.
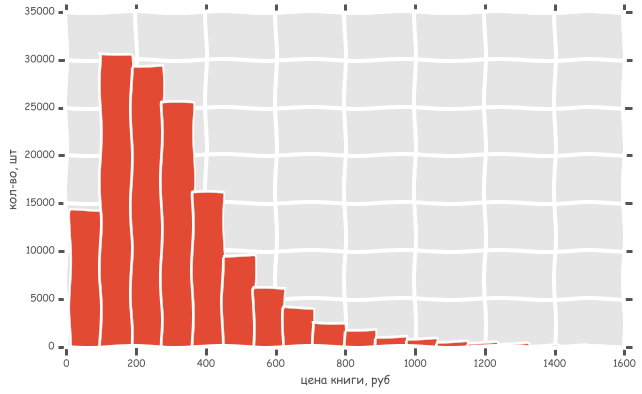
Кстати, гистограмма настоящая. Как она построена и другие интересные закономерности под катом.
Для начала нужно найти список книг, которые есть во всех магазинах.
Я выгрузил базу с сайта
bookradar.org, в виде csv файла. Конечно не просто выгрузил, а специальным образом обработал с помощью Python, чтобы удобно было анализировать. Столбцы у нас — магазины, строки — это книги, ячейки строк — цены на эту книгу в конкретном магазине. Если книги в магазине нет, то пустое значение (NaN).
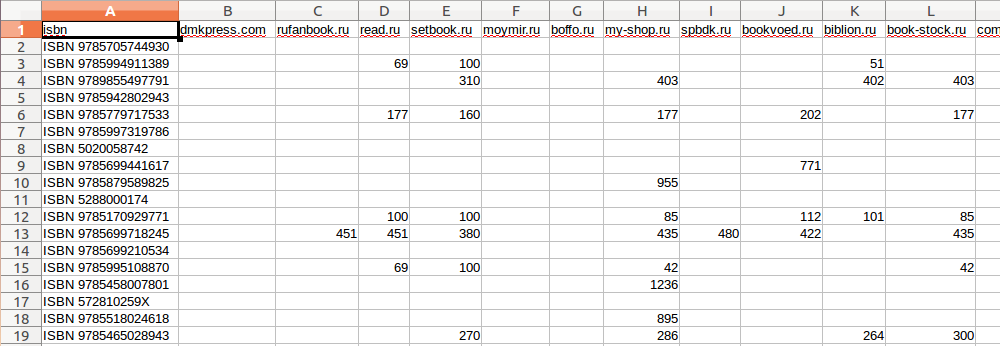
Выгружены только бумажные книги, у которых указан ISBN. Книги у которых ISBN не указан нет возможности понять, что это одна и та же книга. Даже книги которые называются одинаково и выглядят одинаково могут отличаться ценой, если например это издания разных лет. Поэтому для упрощения анализа используем только те книги которые легко можно сопоставить.
Когда первый раз рисовал графики, масштаб был совершенно нечитаемый, т.к. есть отдельные экземпляры, которые стоят 30-50 тыс руб. Поэтому при выгрузке я удалил книги которые стоят дороже 1500 руб.
Выбираем магазины для анализа
Сделаем необходимые импорты и загрузим файл в DataFrame:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import HTML
plt.style.use('ggplot')
%matplotlib inline
filename = 'books.csv'
data = pd.read_csv(filename, header=0, na_values=None, low_memory=False)
data.head()
Так выглядят первые несколько строк нашего DataFrame.
|
isbn |
dmkpress.com |
rufanbook.ru |
read.ru |
setbook.ru |
moymir.ru |
boffo.ru |
my-shop.ru |
... |
|---|
| 1 |
9785994911389 |
NaN |
NaN |
69 |
100 |
NaN |
NaN |
NaN |
... |
|---|
| 2 |
9789855497791 |
NaN |
NaN |
NaN |
310 |
NaN |
NaN |
403 |
... |
|---|
| 3 |
9785942802943 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
... |
|---|
| 4 |
9785779717533 |
NaN |
NaN |
177 |
160 |
NaN |
NaN |
177 |
... |
|---|
Посчитаем сколько книг к каждом магазине:
desc = data.describe()
l = []
for colname in desc:
count = desc[colname][0]
l.append((count, colname))
for t in sorted(l, reverse=True):
print("{:16} {}".format(t[1], int(t[0])))
магазин кол-во книг
ozon.ru 220962
setbook.ru 208039
my-shop.ru 203200
books.ru 181817
book-stock.ru 124308
bookvoed.ru 117494
labirint.ru 114803
read.ru 93720
spbdk.ru 43714
chaconne.ru 42993
biblion.ru 41898
eksmo.ru 40582
knigosvet.com 34645
rufanbook.ru 6071
combook.ru 4716
bookmail.ru 2356
boffo.ru 2341
moymir.ru 740
dmkpress.com 722
Совсем маленькие магазины смысла брать нет, т.к. пересекающихся книг будет очень мало или вовсе ноль. Выберем магазины примерно от 100 тыс книг или чуть меньше
# Оставляем нужные магазины
stores = ['books.ru', 'labirint.ru', 'ozon.ru', 'my-shop.ru',
'read.ru', 'bookvoed.ru', 'book-stock.ru', 'setbook.ru']
data = data[stores]
# Удаляем строки в которых есть пустые значения.
# Т.е. оставляем только те книги, которые присутствуют во всех магазинах.
data = data.dropna(axis=0)
# Посмотрим, что осталось
data.describe()
Получили сводную информацию о таблице:
|
books.ru |
labirint.ru |
ozon.ru |
my-shop.ru |
read.ru |
bookvoed.ru |
book-stock.ru |
setbook.ru |
|---|
| count |
17834.000000 |
17834.000000 |
17834.000000 |
17834.000000 |
17834.000000 |
17834.000000 |
17834.000000 |
17834.000000 |
|---|
| mean |
340.154312 |
343.349333 |
308.639677 |
294.602108 |
309.796400 |
315.771504 |
291.266794 |
286.433722 |
|---|
| std |
189.347516 |
235.526318 |
209.594445 |
206.383899 |
208.093532 |
208.651959 |
204.553104 |
191.038253 |
|---|
| min |
40.000000 |
17.000000 |
26.000000 |
14.000000 |
69.000000 |
13.000000 |
14.000000 |
77.000000 |
|---|
| 25% |
210.000000 |
169.250000 |
153.000000 |
142.000000 |
155.000000 |
162.000000 |
142.000000 |
140.000000 |
|---|
| 50% |
308.000000 |
293.500000 |
264.000000 |
248.000000 |
267.000000 |
271.000000 |
248.000000 |
240.000000 |
|---|
| 75% |
429.000000 |
435.000000 |
391.000000 |
380.750000 |
391.000000 |
402.000000 |
373.000000 |
360.000000 |
|---|
| max |
1460.000000 |
1497.000000 |
1478.000000 |
1474.000000 |
1485.000000 |
1456.000000 |
1474.000000 |
1490.000000 |
|---|
Книг, которые есть во всех магазинах, у нас нашлось 17834.
Некоторые пояснения:
- mean — среднее
- std — стандартное отклонение
- 50%, 25% и 75% — медианы среднего, нижнего и верхнего кванитилей
По этим данным уже можно сделать какие-то выводы. Если смотреть по медиане, то лучшую цену предлагает setbook.ru с 240, затем идут my-shop.ru и book-stock.ru с медианой 248.
Распределение цен
Построим гистограмму и посмотрим, в каком диапазоне больше всего книг. Эта гистограмма аналогична картинке в начале поста, только здесь больше столбиков.
plt.figure(figsize=(10, 6))
plt.xlabel('цена книги, руб')
plt.ylabel('кол-во, шт')
data3 = data[stores]
x = data3.as_matrix().reshape(data3.size) # склеиваем столбцы с ценами в одномерный массив
count, bins, ignored = plt.hist(x, bins=30)
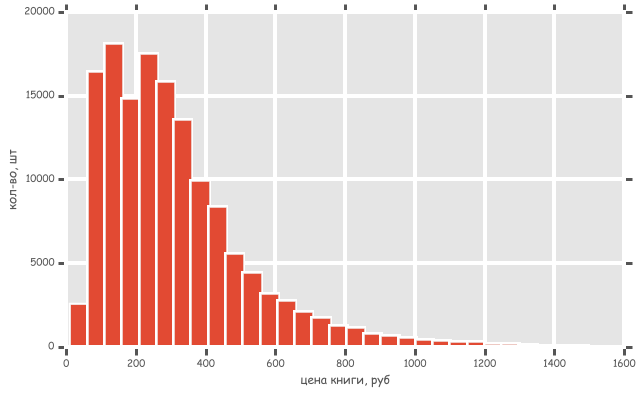
Интересно, получилось два пика, примерно в 75 руб и 215 руб.
А искаженный вид я получил добавлением пары строк вначале предыдущего куска кода:
plt.xkcd() # искаженный стиль отображения
plt.style.use('ggplot') # сбрасываем цветовые настроки xkcd, т.к. цветовая схема xkcd синяя
Корреляция цен
Теперь посмотрим корреляцию цен в магазинах:
data.corr()
|
books.ru |
labirint.ru |
ozon.ru |
my-shop.ru |
read.ru |
bookvoed.ru |
book-stock.ru |
setbook.ru |
|---|
| books.ru |
1.000000 |
0.971108 |
0.969906 |
0.965291 |
0.978453 |
0.970747 |
0.965809 |
0.966226 |
|---|
| labirint.ru |
0.971108 |
1.000000 |
0.973731 |
0.968637 |
0.979923 |
0.970600 |
0.969971 |
0.965970 |
|---|
| ozon.ru |
0.969906 |
0.973731 |
1.000000 |
0.973783 |
0.979620 |
0.967151 |
0.974792 |
0.971946 |
|---|
| my-shop.ru |
0.965291 |
0.968637 |
0.973783 |
1.000000 |
0.976491 |
0.956980 |
0.996946 |
0.970588 |
|---|
| read.ru |
0.978453 |
0.979923 |
0.979620 |
0.976491 |
1.000000 |
0.974892 |
0.976164 |
0.974129 |
|---|
| bookvoed.ru |
0.970747 |
0.970600 |
0.967151 |
0.956980 |
0.974892 |
1.000000 |
0.958787 |
0.961217 |
|---|
| book-stock.ru |
0.965809 |
0.969971 |
0.974792 |
0.996946 |
0.976164 |
0.958787 |
1.000000 |
0.972701 |
|---|
| setbook.ru |
0.966226 |
0.965970 |
0.971946 |
0.970588 |
0.974129 |
0.961217 |
0.972701 |
1.000000 |
|---|
Видна хорошая корреляция между ценами всех магазинов. А если посмотреть на пару my-shop.ru и book-stock.ru, то тут корреляция аж 0.996946, т.е. цены в них почти одинаковые.
Построим гистограмму распределения цены на книги в каждом магазине и диаграмму рассеяния для каждой пары магазинов:
from pandas.tools.plotting import scatter_matrix
scatter_matrix(data, alpha=0.05, figsize=(14, 14));

По диаграммам рассеяния опять видим ту же картину, что и в таблице корреляции. Корреляция явно есть, ее хорошо видно. Увеличим пару магазинов для наглядности.
scatter_matrix(data[['ozon.ru', 'labirint.ru']], alpha=0.05, figsize=(14, 14));

А теперь посмотрим на нашу пару магазинов с очень похожими ценами:
scatter_matrix(data[['my-shop.ru', 'book-stock.ru']], alpha=0.05, figsize=(14, 14));

Получилась почти идеальная прямая. Но все таки есть точки которые расположились вне ее, т.е. не 100% цен одинаковы.
График со всеми ценами
Попробуем изобразить нашу таблицу графически.
plt.figure(figsize=(14, 6))
# просто порядковые номера по горизонтальной оси
x = list(range(data['books.ru'].count()))
colors = ['red', 'blue', 'green', 'orange', 'yellow', 'pink', 'brown', 'purple']
for index,store in enumerate(stores):
plt.scatter(x,
data[store],
alpha=0.5,
color=colors[index],
label=store)
plt.xlabel('n')
plt.ylabel('price')
plt.legend(loc='best');
Диаграмма красивая, но бесполезная. Точки просто перекрывают друг друга. Последний слой фиолетовый, явно закрасил все предыдущие.
Количество книг по минимальной цене
Давайте теперь определим количество книг по минимальной цене в каждом магазине. Нужно учесть, что минимальная цена на конкретную книгу может быть сразу в нескольких магазинах. Поэтому добавим колонки вида «min_ozon.ru» — если в данном магазине на данную книга установлена минимальная цена среди всех магазинов, устанавливаем 1 иначе NaN. Такие значения выбраны для удобства подсчета.
import random
def has_min_price(store):
def inner(row):
prices = list(row[:len(stores)])
min_price = min(prices)
store_price = prices[stores.index(store)]
return 1 if store_price == min_price else np.nan
return inner
# немножко копипасты для разовой аналитики не повредит ;)
def has_max_price(store):
def inner(row):
prices = list(row[:len(stores)])
max_price = max(prices)
store_price = prices[stores.index(store)]
return 1 if store_price == max_price else np.nan
return inner
for store in stores:
data['min_' + store] = data.apply(has_min_price(store), axis=1)
data['max_' + store] = data.apply(has_max_price(store), axis=1)
HTML(data.head(10).to_html())
Получилась такая таблица
Теперь выведем количество книг по минимальной и максимальной цене в каждом магазине:
desc = data.describe()
def show_count(prefix):
l = []
for column_name in desc:
if prefix in column_name:
cnt = desc[column_name][0]
l.append((cnt, column_name))
for t in sorted(l, reverse=True):
print(t[1].replace(prefix, ''), int(t[0]))
print('Всего книг:', desc[stores[0]][0])
print()
print('Количество книг по минимальной цене:')
show_count('min_')
print()
print('Количество книг по максимальной цене:')
show_count('max_')
Всего книг: 17834.0
Количество книг по минимальной цене:
book-stock.ru 8411
my-shop.ru 7735
setbook.ru 6359
bookvoed.ru 1884
ozon.ru 1015
read.ru 914
books.ru 379
labirint.ru 335
Количество книг по максимальной цене:
books.ru 10323
labirint.ru 4383
bookvoed.ru 1143
setbook.ru 1052
ozon.ru 676
book-stock.ru 372
my-shop.ru 351
read.ru 265
По количеству книг с минимальной ценой лидируют book-stock.ru, my-shop.ru, setbook.ru. Что похоже на то, что мы уже видели из медиан, но порядок поменялся.
И по максимальным ценам лидриуют books.ru, labirint.ru и bookvoed.ru.
Отсортируем по минимальной цене
Для того чтобы точки не затирали друг друга, ограничимся небольшим количеством книг.
def get_min(row):
prices = list(row[:len(stores)])
return min(prices)
# добавляем столбец с минимальной ценой для книги
data['min'] = data.apply(get_min, axis=1)
# Сортируем данные по этому столбцу,
# Возьмем только каждую 300-ю книгу, иначе множество точек у нас на график опять не влезут
data2 = data.sort_values(['min'])[::300]
# Рисуем графики
plt.figure(figsize=(14, 10))
colors = ['red', 'blue', 'green', 'orange', 'yellow', 'pink', 'brown', 'purple']
for index,store in enumerate(stores):
plt.scatter(x[:len(data2)],
data2[store],
alpha=1.0,
color=colors[index],
label=store)
plt.xlabel('n')
plt.ylabel('price')
plt.legend(loc='upper left');
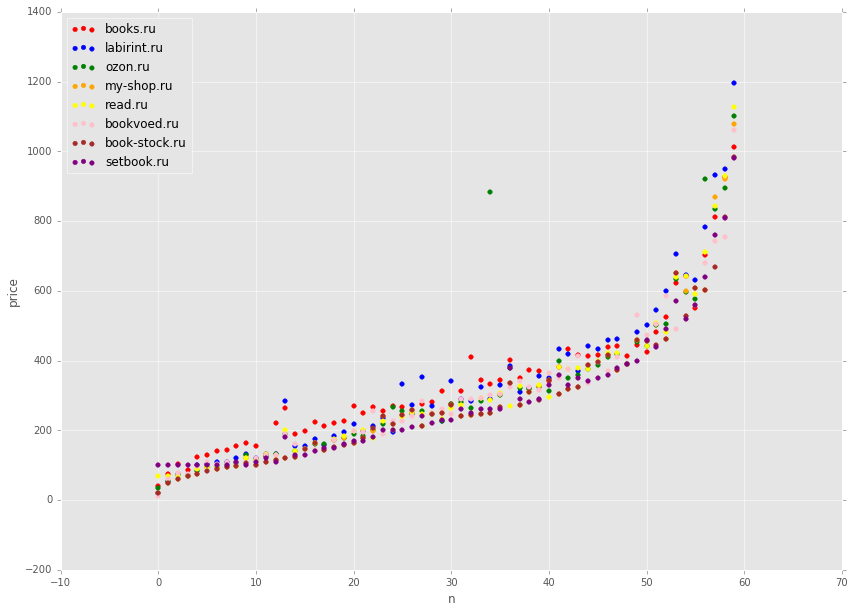
На графике отображены цены на ~60 книг, взятых из отсортированного набора на равных интервалах. Видно что цены в среднем достаточно похожи. Однако если посмотреть на отдельную зеленую точку, то цена там явно непомерно завышена. Если бы мы отобразили не 60 точек, а все 17 тыс. То таких выбросов было бы явно больше.
Выводы
Получается, что в среднем цена на книги в магазинах отличается не очень сильно, грубо говоря из последнего графика в диапазоне 100-150 руб. С другой стороны — это как средняя температура по больнице. Цены вроде почти одинаковые, а за конкретную книгу того и гляди сдерут в 3 раза дороже. Актуальную информацию по цене на ту ли иную книгу, всегда можно посмотреть
на сайте.
Также мы не учитывали условия доставки (цену и удобство) и персональные скидки.