Создание системы антифрода в такси с нуля
- среда, 29 июля 2020 г. в 00:24:19
Добрый день. Меня зовут Никита Башун, работаю дата-аналитиком в группе компаний «Везёт». Мой рассказ будет о том, как мы командой из трёх человек с нуля создавали систему антифрода для сервиса заказа поездок.

Кто раз умеет обмануть, тот много раз еще обманет.
Лопе де Вега
Фрод в нашем случае — это ситуация, когда водитель обманывает компанию. Мошенничество с целью получения денег.
Первый код в компании был написан еще в те времена, когда о мобильных приложениях никто не слышал, доллар был по 25, а в университетах изучали Delphi. Все ловили такси на улице или заказывали по телефону. Менеджеры и кураторы городов вручную искали поездки, похожие на фрод. Процент успеха был крайне низким, и безнаказанные водители продолжали свою криминальную деятельность. Но всему в этом мире рано или поздно приходит конец…
Первоначальная цель — создать MVP, который за минимум времени разработки даст максимальный результат.
После консультаций с директорами городов, кураторами и менеджерами были выявлены самые частые схемы мошенничества:

Функции в нашей команде распределены так:
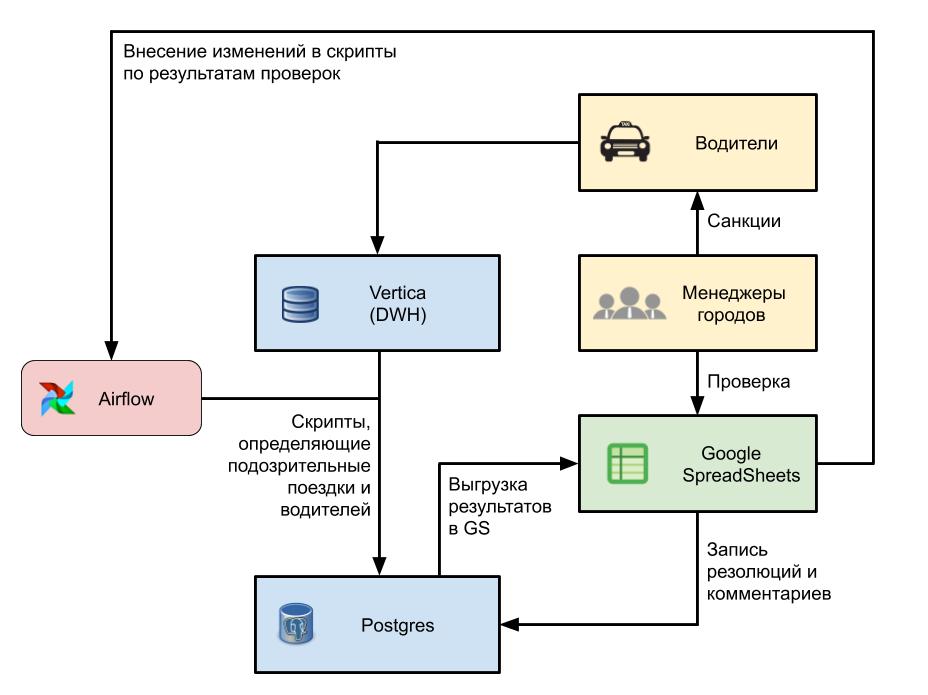
Основную задачу выполняет SQL-запрос в DWH, который возвращает подозрительные поездки и водителей. Те должны обладать набором заранее рассчитанных признаков. Вот, например, как выглядит фильтрация по паттерну «Доплаты»:
WHERE susp = 1 -- Флаг на подозрительность
AND finished_orders >= 3 -- Три и более УСПЕШНЫЕ поездки с одним водителем
AND cancelled >= 3 -- Три и более водителя, с которыми у номера телефона были только ОТМЕНЫ
AND dist_fin_drivers <= 2 -- Успешные поездки максимум с ДВУМЯ водителями
AND ok <= 2 -- Не больше 2-х УСПЕШНЫХ поездок с другими водителямиПризнаки определяются статистически на основании исторических данных, а также путём консультаций с опытными управленцами на местах.
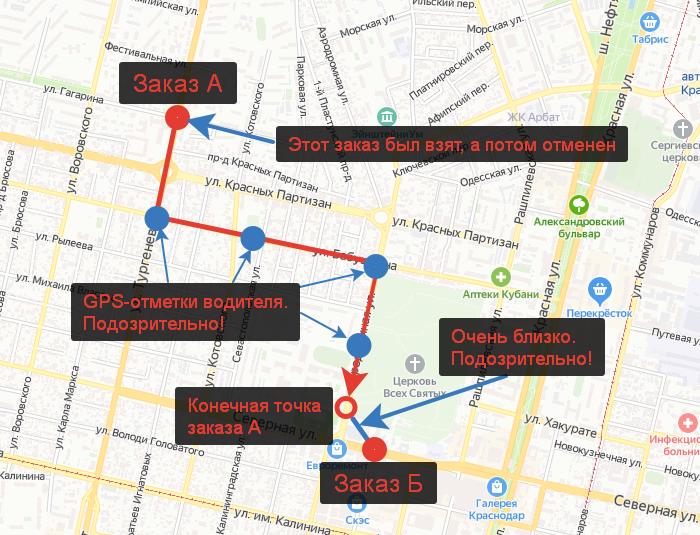
Еще пример. В паттерне «Воровство комиссии» ключевую роль играют координаты водителя. Отменил заказ, но отметился на всём его протяжении? Ну-ну. Считаем расстояния, добавляем ещё несколько важных фильтров и выгружаем такие поездки.
Далее в работу вступает скрипт на python. Он оборачивает выгрузку в pandas, сохраняет ее в postgres, преобразует в нужный вид и выгружает на проверку в листы Google (о них мы еще поговорим подробнее). Часть скрипта, выгружающая поездки, запускается автоматически дважды в день с помощью Apache Airflow.
Рассмотрим работу с API на примере.
Считываем креды и коннектимся:
credentials = ServiceAccountCredentials.from_json_keyfile_dict(
config.crd,
['https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'])
httpAuth = credentials.authorize(httplib2.Http())
service = googleapiclient.discovery.build('sheets', 'v4', http=httpAuth)
sheet = service.spreadsheets()Добавляем данные на лист:
base_range = f'{city_name}!A{ss_row + 1}:Z{ss_row + reserved_rows}'
sheet.values().append(spreadsheetId=spreadsheetid,
range=base_range,
body={"values": df_pos.values.tolist()},
valueInputOption='RAW').execute()Забираем резолюции:
range_from_ss = f'{city_name}!A{ss_row}:S{ss_row + reserved_rows}'
data_from_ss = service.spreadsheets().values().get(
spreadsheetId=spreadsheetid,
range=range_from_ss).execute().get('values', [])
data_from_ss = pd.DataFrame(data_from_ss)
data_from_ss_cols = ['id', 'Резолюция', 'Комментарий']
data_from_ss = data_from_ss.loc[1:, data_from_ss_cols]Заносим их в PG:
vls_ss = ','.join([f"""({', '.join([f(d[c]) for c in data_from_ss_cols])}
)""" for d in data_from_ss.to_dict('rows')])
sql_update = f"""
WITH updated as (
UPDATE fraud_billing
SET resolution = tb.resolution,
comment=tb.comment,
dt = NOW()
FROM (VALUES {vls_ss}) AS tb(fraud_billing_id, resolution, comment)
WHERE fraud_billing.fraud_billing_id = CAST(tb.fraud_billing_id AS INTEGER)
AND ((fraud_billing.resolution IS NULL AND tb.resolution IS NOT NULL)
OR (fraud_billing.comment IS NULL AND tb.comment IS NOT NULL)
OR (fraud_billing.comment IS NOT NULL AND tb.comment IS NOT NULL
AND fraud_billing.comment <> tb.comment)
OR (fraud_billing.resolution IS NOT NULL AND tb.resolution IS NOT NULL
AND fraud_billing.resolution <> tb.resolution)
)
RETURNING {alias_cols_text_with_id}
)
INSERT INTO fraud_billing_history ({cols_text_with_id})
SELECT {cols_text_with_id}
FROM updated;
"""
crs_postgres.execute(sql_update)
con_postgres.commit()В самой postgres для каждого паттерна реализовано две таблицы:
Логи скрипта:
Менеджеры на местах проверяют поездки на наличие ошибок первого рода (казнить нельзя, помиловать).
Пример того, как выглядит работа менеджера с листом:

Иногда по всем признакам сразу видно — водитель фродил.
Иногда приходится копать глубже: смотреть трекинг, вызывать водителя в офис, созваниваться с пассажиром.
И так для каждого паттерна.
К сожалению, без ручной проверки на данный момент никак не обойтись. Очень часто встречаются две идентичные поездки, но одна из них оказывается фродом, а вторая — нет. Для максимизации доли «пойманного» фрода приходится идти на жертвы и подозревать честных водителей.
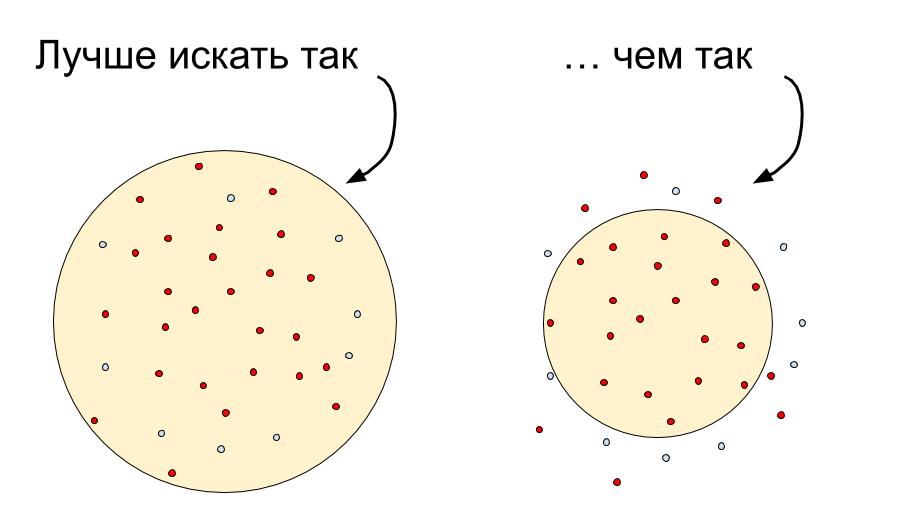
На картинке справа наша FP-ошибка будет равна нулю, но мы не поймаем многих мошенников.
На картинке слева — поймаем всех, но нужна дополнительная проверка, чтобы определить невиновных. Это наш выбор.
После подтверждения факта фрода в игру вступает «карательная машина правосудия». В зависимости от степени тяжести, рецедивов и общей ситуации в городе, водителя:
На данном этапе мы лишь наблюдаем и логируем информацию.
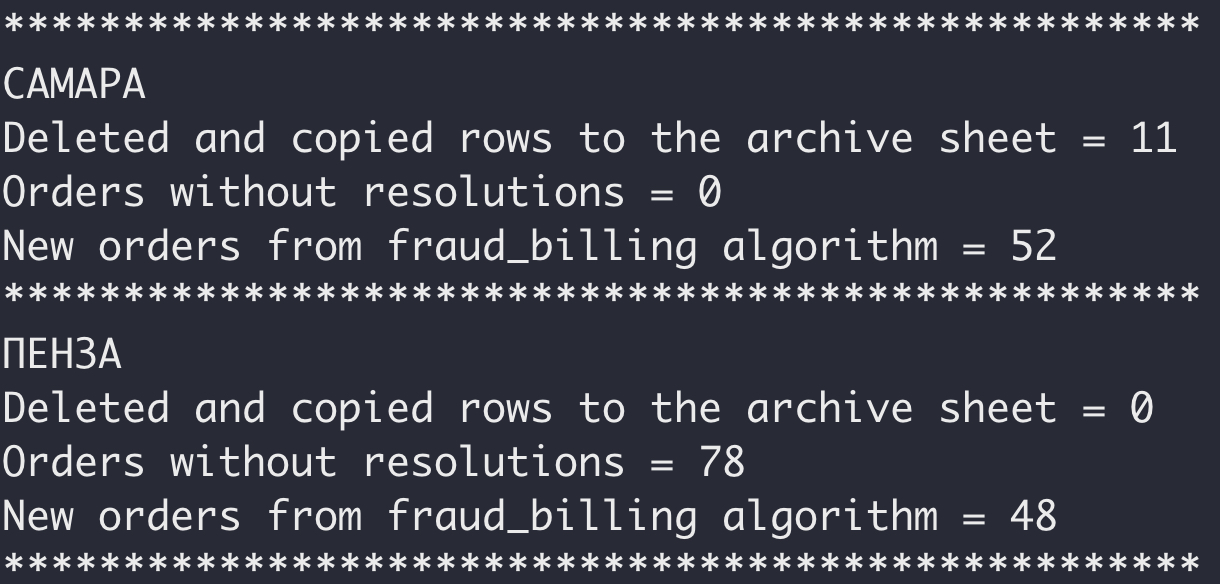
Отмечу, что результат работы зависит от населённого пункта. Города различаются по населению, площади, уровню конкуренции, условиям для водителей, менеджменту. Для примера сравним кол-во подозрений и фрода за последние недели:
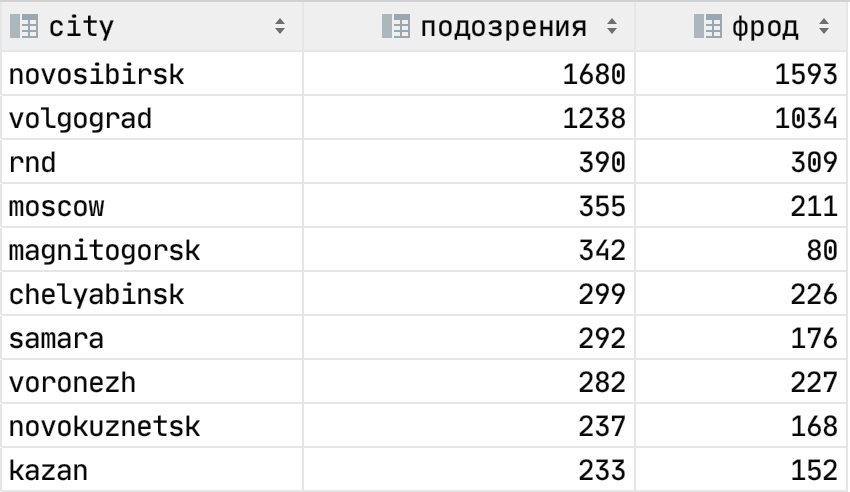
Как видите, подобрать универсальные правила и для Новосибирска, и для Магнитогорска — нетривиальная задача.
Важную роль во всей системе играют Google Spreadsheets. Они выступают интерфейсом между бэкэндом и конечными пользователями. Несколько лет назад я скептически относился к их использованию в проектах, но на практике они показывают себя очень хорошо:
Ручная проверка является важной частью системы антифрода. А там, где люди — там ищи проблемы:
Для борьбы с подобным отношением мы, вместе с кураторами, разрабатываем уголовный кодекс строгий набор правил. Он будет обязательным для всех, оставляя минимум возможностей для «творчества».
Описанное выше — стандартный рабочий процесс, рутина. Все без исключения наши коллеги — ответственные профессионалы, которые качественно выполняют свой этап работы и помогают нам совершенствовать систему. Спасибо им за это!
Как мы совершенствуем алгоритмы, то есть снижаем ошибки?
В начале нашего пути ошибка по самому масштабному паттерну (воровство комиссии) в среднем составляла около 35%. Сейчас — меньше 25%. В то же время, по другому паттерну — доплатам — удалось не только свести ошибку к нулю, но и в десятки раз уменьшить количество таких случаев. Выдвинем гипотезу: водители поняли, что теперь за подобное наказывают, и решили, что риск не стоит свеч. И придумали другие схемы.
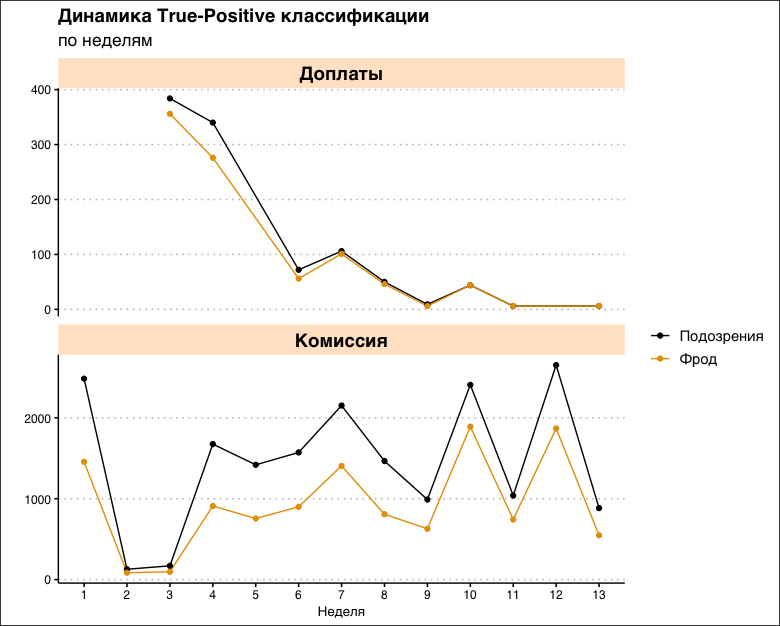
За первые месяцы работы удалось достичь следующих результатов:
Но самый главный успех — это постепенное снижение самих случаев подозрения во многих городах. Ведь, в идеале, мы не хотим ловить больше, мы хотим, чтобы ловить было нечего.
Я постарался описать основной функционал и принципы работы системы антифрода, а также сложности, с которыми мы столкнулись. В планах: использование ML для оптимизации поиска, создание системы мониторинга санкций (сейчас она на начальном этапе), улучшение интерфейса для работы менеджеров, создание динамической отчетности, разработка новых паттернов и многое другое.
В конце концов, мы лишь в начале пути.