https://habrahabr.ru/post/283538/- Разработка веб-сайтов
- Программирование
- Python
Всем привет! Наверняка многим из вас знакома проблема уставших глаз из-за длительной работой за компьютером. К сожалению, из-за этого приходится ограничивать себя в других занятиях. Одним из них есть чтение книг. В связи с этим, я уже более 5 лет почти каждый день слушаю аудиокниги. За это время научился параллельно заниматься чем-то и вникать в суть озвучки. Сейчас я даже в спортзале слушаю книги! Представьте как это удобно: час дороги пешком туда и обратно + полтора часа упражнений. Средняя книга в районе 10-15 часов записи.
Со временем все чаще и чаще появлялась проблема выбора материала. Ведь довольно большую роль играет чтец, жанр книги. Часто возникает ситуация, когда кто-то советует книгу (или в той же статье на хабре в читальном зале), а аудио-версии банально нет еще. Все эти проблемы я попытался решить отдельным сайтом. Сейчас есть парочка довольно больших и раскрученных по аудиокнигам, где вы можете прямо онлайн слушать их. Такие сайты обладают достаточно слабым фильтром по книгам. И, по сути, являются чисто каталогом.
Источник информации
За все время я заметил, что рутрекер является одним из самых масштабных хранилищ аудиокниг. Если книга существует в таком формате, то почти наверняка она есть в раздачах. Многие чтецы даже вручную делают релизы торрентов. Первым заданием было полной синхронизацией всех доступных аудиокниг с рутрекера.
Выбор книги
Следующей целью было создание широкого фильтра для подбора книги. Удобные фильтры помогут сменить подход к выбору книги. Если раньше вы просто находили себе вариант, а потом искали его аудиокнигу (которой могло не оказаться), то теперь вы исключаете первый пункт и ищете в базе максимально всех существующих книг. Конкретно сейчас у меня получилось сделать следующий набор фильтров:
- Семантический глобальный поиск по всей базе по всем текстовым полям
- Сортировка (asc/desc) по дате создания торрента, количеству просмотров (на сайте), рейтингу (из внешних источников), количество загрузок (по данным рутрекера), ну и наугад
- Фильтр по автору произведения, автору озвучки, жанрам, и возможность исключить книги, которые вы отметили как «прочитанное»
- Возможность подписки на авторов книг или озвучки. Да-да! Вы можете выбрать понравившегося исполнителя и подписаться на все его обновления. Я, например, мониторю все книги Игоря Князева
База рутрекера
Итак, первый пункт это анализ публикаций рутрекера и формирование базы. Для хранилища выбрал MongoDB. Во-первых, идеально для кучи не особо связанных данных, во-вторых, идеально показала себя в плане производительности. Да и вообще разрабатывать сайт с простым «пробрасыванием» json с UI на базу очень просто и занимает минимальное время. Кстати, в MongoDB 3.2 добавили left outer join.
Основной сложностью было унифицирование информации. Рутрекер хоть и заставляет оформлять раздачи (за что им спасибо), но все равно за 10 лет (именно столько времени прошло с момента публикации первой аудиокниги) оформление отличается. Пришлось открывать наугад разные разделы и собирать возможные варианты.
Скрипт парсера написан на питоне, для эмуляции браузера библиотека mechanize, для работы с DOM — BeautifulSoup.
Метод, который возвращает объект максимально эмулирующий поведение обычного браузера. Второй метод получает объект браузера, авторизируется на рутрекере и возвращает этот самый объект, внутри которого уже хранятся cookies авторизации.
def getBrowser():
br = mechanize.Browser()
cj = cookielib.LWPCookieJar()
br.set_cookiejar(cj)
br.set_handle_equiv(True)
br.set_handle_gzip(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
br.addheaders = [
('User-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2327.5 Safari/537.36'),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'),
('Accept-Encoding', 'gzip, deflate, sdch'),
('Accept-Language', 'ru,en;q=0.8'),
]
return br
def rutrackerAuth():
params = {u'login_username': '...', u'login_password': '...', u'login' : ''}
data = urllib.urlencode(params)
url = 'http://rutracker.org/forum/login.php'
browser = getBrowser()
browser.open(url, data)
return browser
Сам по себе сбор данных выглядит как набор регулярных выражений в разных вариациях:
yearRegex = r'Год .*(\d{4}?)'
result['year'] = int(re.search(yearRegex, descContent, re.IGNORECASE).group(1))
# Пример разбора даты создания торрента, где дата указана в русской локали
timeData = soupHandle.find('div', {'id' : 'tor-reged'}).find('span').encode_contents()
import locale
locale.setlocale(locale.LC_ALL, 'ru_RU.UTF-8')
result['creationTime'] = datetime.datetime.strptime(timeData, u'[ %d-%b-%y %H:%M ]')
Очень важно использовать BULK-запросы в mongo, чтобы парсер не нагружал единичными вставками базу. К счастью, все это делается очень просто:
BULK = tableHandle.initialize_unordered_bulk_op()
# Цикл...
BULK.find({'_id' : book['_id']}).upsert().update({'$set' : result})
BULK.execute()
Поле slug генерируется пакетом slugify (pip install slugify).
Вот список всех полей для каждой из книг, которые я в итоге собрал:
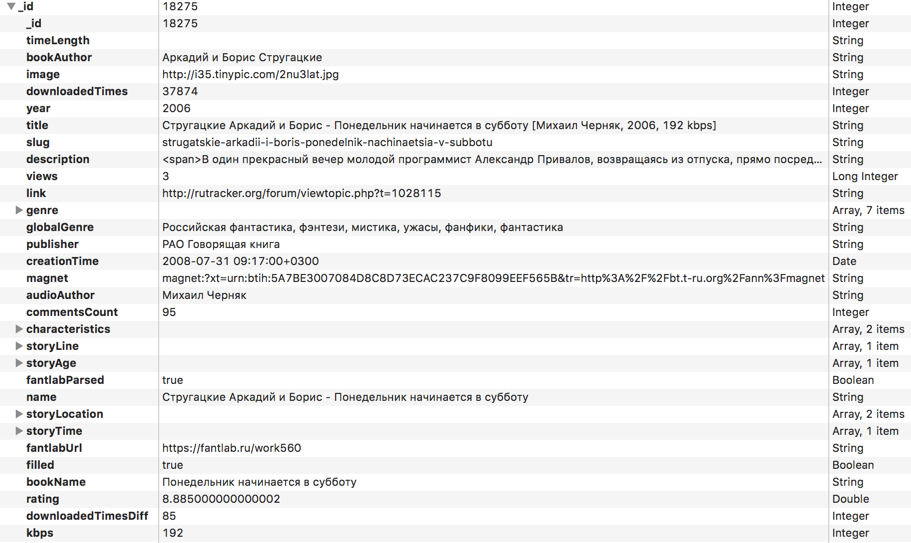
Сразу же не забываем создать индекс для всех полей, по которым будет идти сортировка или фильтрация:

Это замедлит время вставки, но очень ускорит выборку. Синхронизация базы происходит раз в день, поэтому второй вариант для сайта предпочтительней.
Загрузка данных происходит по всем подфорумам аудиокниг:
forums = [
{'id' : '1036'}, {'id' : '400'}, {'id' : '574'},
{'id' : '2387'}, {'id' : '2388'}, {'id' : '695'},
{'id' : '399'}, {'id' : '402'}, {'id' : '490'},
{'id' : '499'}, {'id' : '2325'}, {'id' : '2342'},
{'id' : '530'}, {'id' : '2152'}, {'id' : '403'},
{'id' : '716'}, {'id' : '2165'}
]
for i in xrange(pagesCount):
url = 'http://rutracker.org/forum/viewforum.php?f='+forum['id']+'&start=' + str(i*50) + '&sort=2&order=1'
Нормализация базы
Данные мы скачали, но есть проблема: нет точности в указанных данных. Кто-то напишет «В. Герасимов», кто-то «Вячеслав Герасимов». В одном месте укажут полное или альтернативное название произведение. Также появился вопрос в получении независимой оценки произведения. Погуглил пару заголовков книг и посмотрел на выдачу первых сайтов. Одним из них оказался fantlab.ru, который строит оценку по голосам пользователей, имеет довольно внушительную базу книг, содержит полное описание жанра и поджанров книг, точное имя автора и произведения.
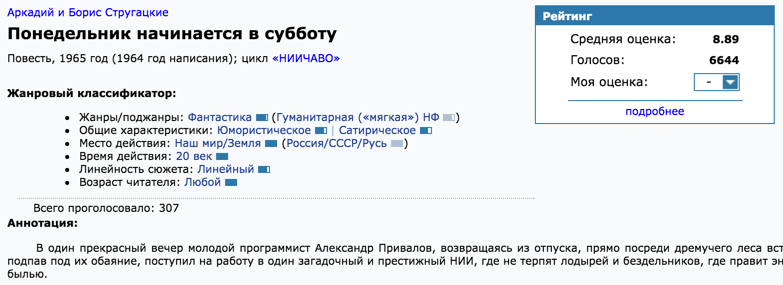
Имя автора, название книги
Абсолютно вся информация из скриншота парсится и вносится в базу. Все поля вручную проверяются членами сообщества fantlab. Все идеально, но есть одна проблема: как связать раздачу с рутрекера и определенную запись с fantlab? В раздачах не указывают отдельно названия произведения. Иногда даже автора неверно пишут (или не указывают). По сути, полным источником информации есть заголовок. Всю боль можно увидеть в следующем скриншоте раздач:

Стоит ли говорить, что даже исключив весь текст в угловых скобках встроенный поиск на fantlab не справляется и не находит ничего. Выход я нашел, хоть и не совсем изящный: phantomjs(selenium) + google.
У меня довольно много проектов используют эту связку, поэтому настроенный headless-браузер и базовые скрипты для selenium готовы были для использования. По сути, я брал заголовок с рутрекера, добавлял к нему приставку " fantlab" и гуглил. Первый результат, который по шаблону подходил по адресу произведения парсился. Оставлю пару замечаний по поводу phantomjs: очень сильно течет память. Я давно уже сделал для себя пару «костылей», которые позволяют процессу жить месяцами на сервере и не падать по причине нехватки памяти:
def resourceRequestedLogic(self):
driver.execute('executePhantomScript', {'script': '''
var page = this;
page.onResourceRequested = function(request, networkRequest) {
if (/\.(jpg|jpeg|png|gif|tif|tiff|mov|css)/i.test(request.url))
{
//console.log('Final with css! Suppressing image: ' + request.url);
networkRequest.abort();
return;
}
}
''', 'args': []})
Эта функция выполняется в момент запроса какого-то ресурса и проверяет его по маске медиа-файлов. Все картинки и видео исключаются. Т.е. они даже не загружаются в память. Вторая функция принудительно сбрасывает кеш. Вызывать нужно по таймеру раз в ~час:
def clearDriverCache(self):
driver.execute('executePhantomScript', {'script': '''
var page = this;
page.clearMemoryCache();
''', 'args': []})
Открываем гугл и вбиваем ему в поле поиска любой текст, чтобы сменить UI (получить результат выдачи). Все дальнейшие запросы будут происходить на этой же странице.
driver.get('http://google.ru')
driver.find_element_by_css_selector('input[type="text"]').send_keys(u"Имя книги fantlab")
driver.find_element_by_css_selector('button').click()
Так как запросы все аяксовые, нам нужно вручную проверять факт загрузки. В selenium для этого есть некоторые методы, которые ожидают пока определенный элемент не появится на странице.
count = 0
while True:
count += 1
time.sleep(0.25)
if count >= 3:
break
try:
link = driver.find_element_by_css_selector('a[href*="fantlab.ru/work"]')
if link:
return link.get_attribute('href')
except:
continue
Жанры
Следующий шаг: приведение к одному виду всех имен авторов и всех жанров. В некоторых раздачах писали «ужас», в других «ужасы». Здесь на помощь пришла библиотека pymorphy2: позволяет получить начальную форму слова.
# Убираем все спец символы из строки жанров
fullGenre = fullGenre.replace('/', ',').replace(';', ',').replace('--', '-').replace(u'ё', u'е')
fullGenre = re.sub(r'[\.|"«»]', '',fullGenre)
fullGenre = re.sub(r'\[.*?\]', '',fullGenre)
# Разбиваем жанры по запятой, убираем пустые поля и начальные/конечные пробелы
allGenres = filter(None, fullGenre.split(','))
allGenres = [item.strip() for item in allGenres]
# Делаем список уникальным (убираем дубликаты)
allGenres = list(set(allGenres))
insertGenresList = []
for genre in allGenres:
# Проходим по каждому жанру, получаем его начальную форму
morphology = morph.parse(genre)[0]
genre = morphology.normal_form
insertGenresList.append(genre)
Имена авторов
С авторами можно было бы тоже что-то придумать с библиотекой pymorphy2: разбивать на слова, проверять вхождения слов и их совпадение. Но тут я вспомнил пункт про глобальный поиск всего по всем полям. Это и будет решением. Для полнотекстового поиска взял sphinx. Он напрямую не дружит с mongodb, поэтому нужно написать скрипт, который будет выбрасывать xml с данными по указанной схеме.
docset = ET.Element("sphinx:docset")
schema = ET.SubElement(docset, "sphinx:schema")
# Храним ID записи в базе, чтобы потом вытаскивать информацию
idAttribute = ET.SubElement(schema, "sphinx:attr")
idAttribute.set("name", "mongoid")
idAttribute.set("type", "int")
# Дальше перечисляем все поля, которые должны индексироваться
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "audioauthor")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "bookauthor")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "title")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "publisher")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "description")
# Мы должны вручную генерировать индекс для каждой записи книги и это обязательно должен быть атрибут с имением id
globalIterator = 0
all = bookTable.find()
# Убираем то, что может сломать xml разметку
def safeText(data):
data = re.sub('<[^<]+?>', ' ', data)
data = "".join([c for c in data if c.isalpha() or c.isdigit() or c==' ']).rstrip()
return data
for card in all:
document = ET.SubElement(docset, "sphinx:document")
globalIterator += 1
# Этот самый обязательный id
document.set("id", str(globalIterator))
mongoid = ET.SubElement(document, "mongoid")
mongoid.text = str(card["_id"])
title = ET.SubElement(document, "audioauthor")
title.text = safeText(card["audioAuthor"])
# И далее все то же для всех полей...
Параметры в sphinx.conf:
source src_bookaudio
{
type = xmlpipe2
xmlpipe_command = python /path/to/sphinx.py
sql_attr_uint = mongoid
}
index bookaudio
{
morphology = stem_enru
charset_type = utf-8
source = src_bookaudio
path = /var/lib/sphinxsearch/data/bookaudio.main
}
И команда:
indexer bookaudio --rotate
Как же использовать поиск для унификации полей? Берем список всех авторов книг, и складываем одинаковые вхождения. Получится что-то типа:
Вячеслав Герасимов — 1324
Игорь Князев — 432
...
authors = {}
for book in allBooks:
author = book['audioAuthor']
if author in authors:
authors[author] += 1
else:
authors[author] = 1
То, что используется максимально часто наверняка есть наиболее правильной формой. Берем топовые вхождения и делаем глобальный поиск по всем авторам.
import sphinxapi
client = sphinxapi.SphinxClient()
client.SetServer('localhost', 9312)
client.SetMatchMode(sphinxapi.SPH_MATCH_ALL)
client.SetLimits(0, 10000, 10000)
import operator
sorted_x = reversed(sorted(authors.items(), key=operator.itemgetter(1)))
counter = 0
for i in sorted_x:
print i[0].encode('utf-8'),
print ' - ' + str(i[1])
searchData = client.Query(i[0], 'bookaudio')
for match in searchData['matches']:
mongoId = int(match['attrs']['mongoid'])
BULK.find({'_id' : mongoId}).upsert().update({'$set' : {'audioAuthor' : i[0]}})
Все похожие вхождения (в том числе «В. Герасимов», например) будут заменены на наиболее используемые формы.
Интерфейс
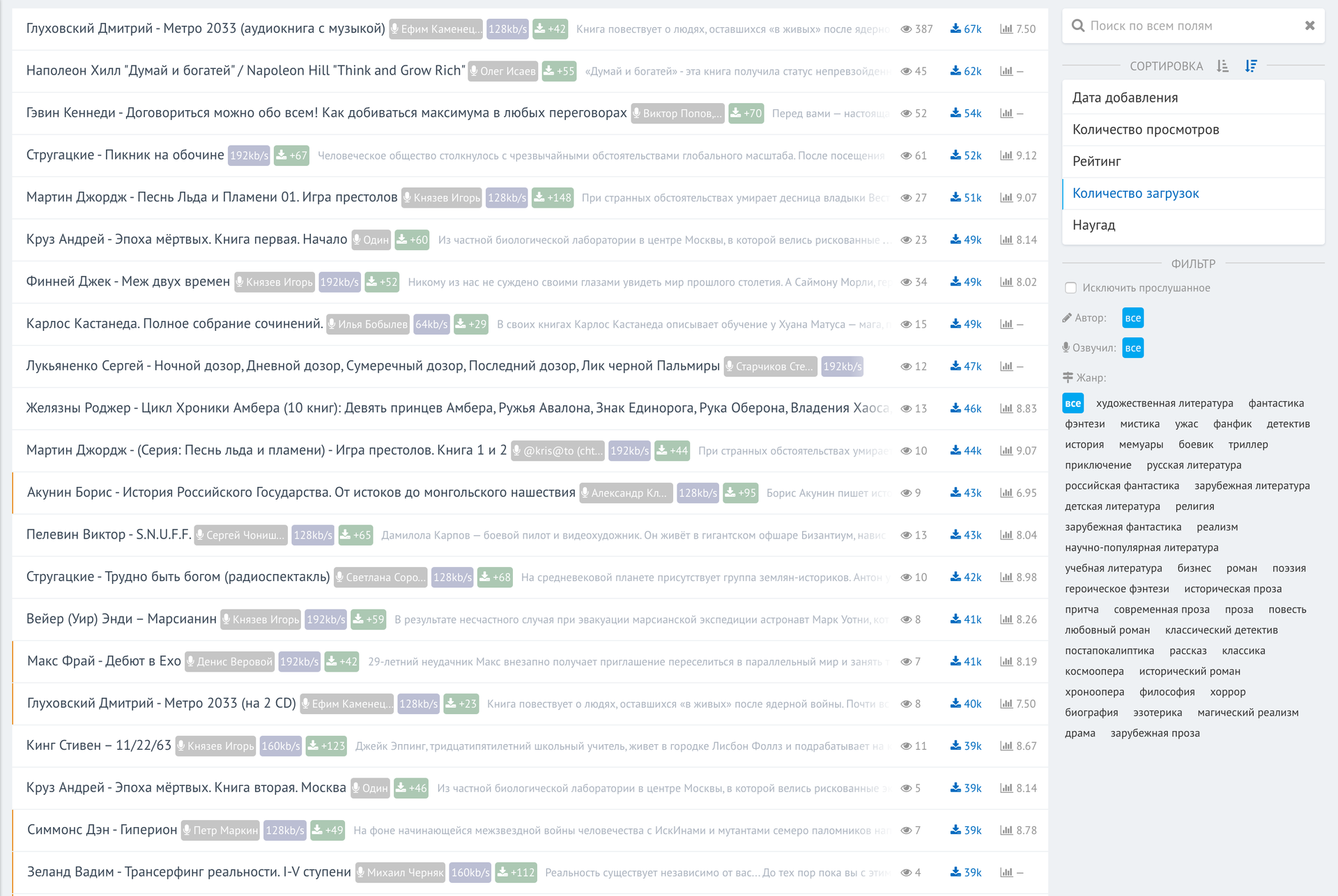
Написание веб-интерфейса для всего этого не несет никакой технической сложности. По сути, это надстройка для доступа к базе. Вот что у меня получилось. Список самых скачиваемых аудиокниг за всю историю трекера:
И работа с фильтрами:
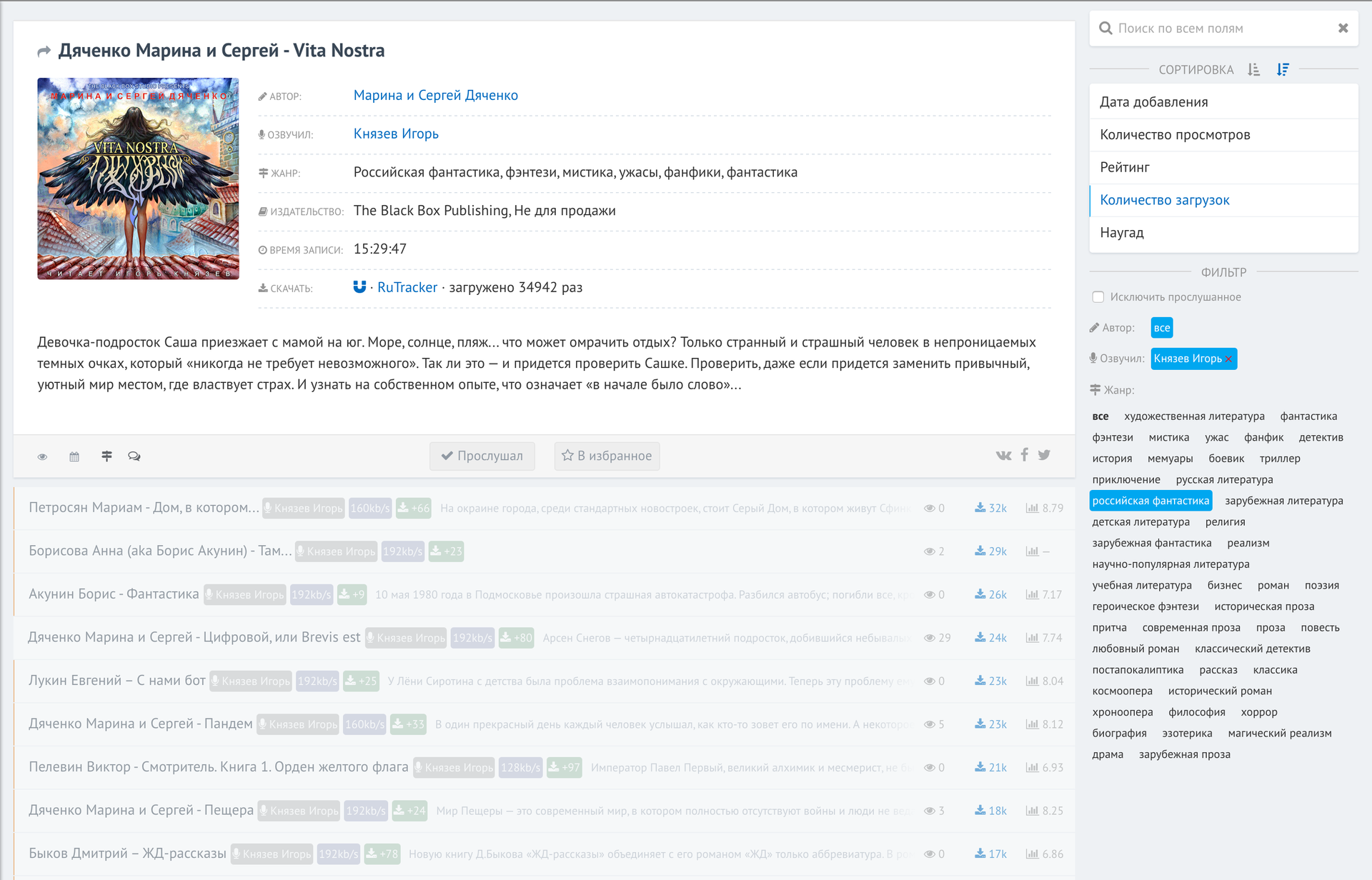
Как видите, я захотел посмотреть все книги, озвученные Игорем Князевым по жанру «российская фантастика», отсортированные по количеству загрузок на рутрекере (вверху самые скачиваемые).
Пробелом или нажатием на карточки внизу раскрывается информация о книге. Благодаря mongodb все фильтры отрабатывают мгновенно по базе в 30к книг.
Завершение
Не все идеально: база не везде точная, интерфейс можно улучшить. Фильтр по жанрам нужно перевести в древовидную структуру. Все это работа за 3 дня и для личного пользования и выбора книг мне хватает. Вы бы пользовались таким сервисом?
