https://habrahabr.ru/post/334980/- Отладка
- Ненормальное программирование
- JavaScript
Недавно мне попался
этот твит от
@FakeUnicode. Там был сниппет JavaScript, который выглядел довольно безобидно, но выводил скрытое сообщение. Мне понадобилось некоторое время, чтобы понять происходящее. Думаю, что запись шагов моего расследования может быть кому-то интересна.
Вот тот сниппет:

Что бы вы ожидали от него?
Здесь используется цикл
for in, который проходит через перечислимые свойства объекта. Поскольку указано только свойство
A, можно предположить, что будет показано сообщение с буквой
А. Ну… я ошибался. :D
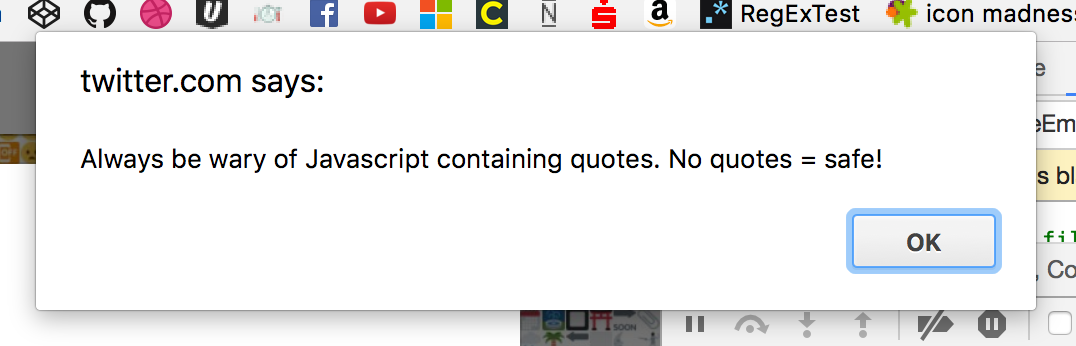
Это меня удивило, так что я запустил отладку через консоль Chrome.
Открытие скрытых кодов символов
Первым делом я упростил сниппет.
for(A in {A:0}){console.log(A)};
// A
Хмм… ладно, здесь ничего, пойдём дальше.
for(A in {A:0}){console.log(escape(A))};
// A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21
Матерь божья! Откуда это взялось?
Пришлось сделать шаг назад и посмотреть на длину строки.

Интересно. Затем я скопировал
А из объекта и сразу понял, что консоль Chrome работает с чем-то скрытым, потому что курсор «застыл» и не реагировал на несколько нажатий клавиш влево/вправо.
Но давайте посмотрим, что там внутри, и получим значения всех 129 кодовых единиц.

Здесь мы видим букву
А со значением кодовой единицы
65, за ней следуют несколько кодовых единиц в районе 55 тысяч и 56 тысяч, которые
console.log визуализирует хорошо знакомым знаком вопроса. Это означает, что система не знает, как обрабатывать эту кодовую единицу.
Суррогатные пары на JavaScript
Данные значения — части так называемых
суррогатных пар, которые представляют собой кодовые точки со значениями более 16 бит (то есть кодовые точки более
65536). Это нужно, потому что сам Юникод определяет 1 114 122 разных кодовых точек, а у JavaScript формат строки UTF-16. То есть только первые 65536 кодовых точек из Юникода можно представить одним элементом кодовой единицы JavaScript.
Бóльшие значения можно вычислить, применив к паре сумасшедшую формулу, в результате получается значение больше, чем
65536.
Наглая вставка: Я читал лекцию именно на эту тему, которая может помочь вам понять концепцию кодовых точек, эмодзи и суррогатных пар.
Итак, мы обнаружили 129 кодовых единиц, из которых 128 являются суррогатными парами, представляющими 64 кодовых точек. Так что это за кодовые точки?
Чтобы получить значение кодовой точки из строки, есть очень удобный цикл
for of, который прогоняет кодовые точки строки (не кодовые единицы, как первый цикл
for), а также оператор
..., который используется в
for of.

Поскольку
console.log даже не знает, как отображать эти кодовые точки, то нужно самим разобраться, с чем мы имеем дело.
 Примечание: учитывайте, что в JavaScript есть две функции для обработки кодовых единиц и кодовых точек charCodeAt и codePointAt. Они ведут себя немного по-разному, так что смотрите.
Примечание: учитывайте, что в JavaScript есть две функции для обработки кодовых единиц и кодовых точек charCodeAt и codePointAt. Они ведут себя немного по-разному, так что смотрите. Имена идентификаторов в объектах JavaScript
Кодовые точки
917868,
917879 и далее — это часть
Variation Selectors Supplement в Юникоде. Вариантные селекторы в Юникоде используются для указания стандартизированных вариантных последовательностей для математических символов, эмодзи, символов монгольского квадратного письма и восточных единых идеограмм, соответствующих восточным идеограммам совместимости. Они обычно не используются сами по себе.
Отлично, но при чём здесь это?
Если посмотреть
спецификации ECMAScript, то вы обнаружите, что имена идентификаторов свойств могут содержать не только «обычные символы».
Identifier ::
IdentifierName but not ReservedWord
IdentifierName ::
IdentifierStart
IdentifierName IdentifierPart
IdentifierStart ::
UnicodeLetter
$
_
\ UnicodeEscapeSequence
IdentifierPart ::
IdentifierStart
UnicodeCombiningMark
UnicodeDigit
UnicodeConnectorPunctuation
<ZWNJ>
<ZWJ>
Как видим, идентификатор может состоять из
IdentifierName и
IdentifierPart. Важным является определение
IdentifierPart. Кроме первого символа идентификатора, все остальные имена полностью валидны:
const examples = {
// UnicodeCombiningMark example
somethingî: 'LATIN SMALL LETTER I WITH CIRCUMFLEX',
somethingi\u0302: 'I + COMBINING CIRCUMFLEX ACCENT',
// UnicodeDigit example
something١: 'ARABIC-INDIC DIGIT ONE',
something\u0661: 'ARABIC-INDIC DIGIT ONE',
// UnicodeConnectorPunctuation example
something﹍: 'DASHED LOW LINE',
something\ufe4d: 'DASHED LOW LINE',
// ZWJ and ZWNJ example
something\u200c: 'ZERO WIDTH NON JOINER',
something\u200d: 'ZERO WIDTH JOINER'
}
Так что при вычислении этого выражения получается такой результат:
{
somethingî: "ARABIC-INDIC DIGIT ONE",
somethingî: "I + COMBINING CIRCUMFLEX ACCENT",
something١: "ARABIC-INDIC DIGIT ONE"
something﹍: "DASHED LOW LINE",
something: "ZERO-WIDTH NON-JOINER",
something: "ZERO-WIDTH JOINER"
}
Это привело меня к главному открытию дня.
В соответствии со спецификациями ECMAScript:
Два IdentifierName, канонически эквивалентные по стандарту Юникод, не являются одинаковыми, пока не представлены в точности той же последовательностью кодовых единиц.
Это значит, что два ключа идентификатора объекта могут выглядеть в точности одинаково, но состоять из разных кодовых единиц, а значит, они оба будут включены в объект. Как в случае символа
î, которому соответствует кодовая единица со значением
00ee и символ
i с циркумфлексом
COMBINING CIRCUMFLEX ACCENT. Так что это не одно и то же, и в объект включаются двойные свойства. То же самое с символами
Zero-Width joiner или
Zero-Width non-joiner. Они выглядят одинаково, но не являются таковыми!
Но вернёмся к теме: найденные значения вариантных селекторов принадлежат категории
UnicodeCombiningMark, что делает их валидными именами идентификаторов (даже если они невидимы). Они невидимы, потому что с высокой вероятностью система покажет результат, только если они используются в валидном сочетании.
Функция escape и замена строки
Что делает функция
escape, так это
проходит по всем кодовым единицам и обрабатывает их как escape. То есть она берёт первую букву
А и все части суррогатных пар — и просто преобразует их снова в строки. Невидимые значения «преобразуются в строковую форму». Так появляется та длинная последовательность, которую вы видели в начале статьи.
A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21
Хитрость в том, что
@FakeUnicode выбрал специфические вариантные селекторы — те, что заканчиваются числом, которое отсылает обратно к настоящему символу. Посмотрим на пример.
// a valid surrogate pair sequence
'%uDB40%uDD6C'.replace(/u.{8}/g,[]);
// %6C 6C (hex) === 108 (dec) LATIN SMALL LETTER L
unescape('%6C')
// 'l'
Единственное, в этом примере остаётся немного непонятным использование пустого массива
[] в качестве замены строки. Она будет вычисляться через
toString(), то есть преобразуется в
''.
Пустая строка тоже делает своё дело. Смысл
[] в том, что таким образом
вы можете обойти фильтр кавычек или нечто подобное.
Таким образом можно закодировать целое сообщение невидимыми символами.
Общая функциональность
Так что если снова посмотреть на пример:

Происходит следующее:
A:0 — здесь A включает в себя много «скрытых кодовых единиц»- эти символы становятся видимыми с помощью
escape
- отображение выполняется с помощью
replace
- результат будет снова unescaped и готов к выводу в окно уведомления
Мне кажется, это довольно круто!
Дополнительные ресурсы
Этот маленький пример покрывает много тем Юникода. Если хотите узнать больше, настоятельно рекомендую почитать статьи
Матиаса Биненса по Юникоду и JavaScript: