https://habr.com/ru/post/464959/- Python
- Алгоритмы
- Natural Language Processing
В данной статье описывается процесс синтаксического анализа предложения русского языка с использованием контекстно-свободной грамматики и алгоритма LR-анализа.
Обработка естественного языка — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков.
В общем, процесс анализа предложения естественного языка выглядит следующим образом: (1) разбиение предложения на синтаксические единицы — слова и словосочетания; (2) определение грамматических параметров каждой единицы; (3) определение синтаксической связи между единицами. На выходе — абстрактное дерево разбора.
1. Разбиение предложения на синтаксические единицы
Предложение естественного языка состоит из словоформ и устойчивых словосочетаний. Ряд словоформ данного слова называется парадигмой.
Например,
Парадигма слова "рука": [рука, руки, руке, руку, рукой, о руке]
Словосочетания — составные союзы, предикативы или устойчивые выражения — не изменяются и не могут быть разложены на меньшие единицы без потери смысла. Далее под словом будем понимать любую синтаксическую единицу — словоформу или словосочетание.
Каждое слово в предложении определяется тройкой:
- строка словоформы/словосочетания («писал»)
- нормальная форма слова («писать»)
- набор грамматических параметров ( ['VERB', 'sing', 'musc', 'tran', 'past'] )
Таким образом, разбиение предложения "
Ясно дело, он не придет на встречу" будет иметь следующий вид:
['Ясно дело', 'он', 'не', 'придет', 'на', 'встречу']
здесь 'ясно дело' - устойчивое выражение, неизменяемое
2. Определение грамматических параметров (граммем)
Граммемой называется элемент грамматической категории; различные граммемы одной категории исключают друг друга и не могут быть выражены вместе. Для каждой словоформы определяем набор из семи граммем:
[ ЧАСТЬ РЕЧИ, ЧИСЛО, ЛИЦО, РОД, ПАДЕЖ, ВАЛЕНТНОСТЬ, ВРЕМЯ ]
В качестве источника будем использовать словарь
OpenCorpora и интерфейс к нему -
pymorphy2. Для поиска правила в грамматике по данному набору граммем будем представлять их в общем виде:
'яблоки' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None]
здесь '?' означает, что параметр может принимать произвольное значение
3. Определение синтаксической связи между словами
Для определения синтаксической связи между словами будем использовать контекстно-свободную грамматику и LR-анализ.
Грамматика и LR-анализ
Формальная грамматика — способ описания языка в виде так называемых продукций. Например:
a -> ab | ac
означает, что правило 'a' порождает 'ab' ИЛИ 'ac'.
Нетерминалами называются объекты, обозначающие какую-либо сущность языка (предложение, формула и т.д.).
Терминалы — объекты непосредственно присутствующие в языке, соответствующего грамматике, и имеющий конкретное, неизменяемое значение (буквы, слова, формулы и др.). Контекстно-свободные грамматики, это такие грамматики, у которых левые части всех продукций являются одиночными нетерминалами.
Для описания русского языка будем использовать теорию грамматики составляющих (
phrase structure grammar), которая утверждает что всякая сложная грамматическая единица складывается из двух более простых и не пересекающихся единиц, называемых её непосредственными составляющими. Выделяют следующие составляющие:
(1) Именная группа (NP)
NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
То есть номинативная именная группа — это существительное в номинативном падеже ИЛИ прилагательное в номинативном падеже + номинативная именная группа ИЛИ другое.
(2) Глагольная группа (VP)
VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
Другими словами, транзитивная глагольная группа — это транзитивный глагол + аблативная именная группа ИЛИ краткое прилагательное + транзитивная глагольная группа ИЛИ другое.
(3) Предложная группа (PP)
PP -> PREP NP[case='datv'] | ...
Предложная группа — это предлог + именная дативная группа ИЛИ другое.
(4) Полное предложение (S)
S -> NP[case='nomn'] VP[tran]
Полное предложение существует тогда и только тогда, когда именная и глагольная группы согласованы в числе, лице и роде.
def agreement(self, node_left, node_right):
...
if (numb1 and numb2):
if (numb1 != numb2): return False;
if (per1 and per2):
if (per1 != per2): return False;
if (gend1 and gend2):
if (gend1 != gend2): return False;
return True;
Неполным предложением называется такое предложение, где опущена именная часть. Как правило, в таких предложениях глагольная группа выражена безличным глаголом. Например, "
Мне хочется гулять", "
Светает". Эллептическим предложением называется предложение, где опущена глагольная часть, она заменяется знаком тире. Например, "
За спиной – лес. Справа и слева – болота".
Для того, чтобы определить принадлежность данного предложения к языку грамматики будем использовать алгоритм LR-анализа. Данный алгоритм предполагает построение дерева разбора снизу вверх (от листьев к корню). Ключевым элементов алгоритма является метод «переноса-свертки» (англ.
shift-reduce):
(1) читаем символы входной строки до тех пор, пока найдется цепочка, совпадающая с правой частью какого-нибудь из правил, найденную цепочку положить в стэк (перенос);
(2) заменим найденную цепочку правилом из грамматики (свертка).
Если все цепочки строки были перенесены, то данное предложение принадлежит языку грамматики, и по крайней мере одно дерево разбора существует.
Дерево
Для представления синтаксической связи в предложении используется бинарное дерево, где листья — это слова (терминалы) с набором граммем, а узлы — правила (претерминалы). Корнем является предложение (нетерминал).
Узел дерева определяется следующим образом:
class Node:
def __init__(self, word=None, tag=None, grammemes=None, leaf=False):
self.word = word; # строка слова
self.tag = tag; # здесь тэг - претерминал,
который соотвествует промежуточному правилу грамматики
self.grammemes = grammemes; # набор граммем
self.leaf = leaf;
self.l = None;
self.r = None;
self.p = None;
Построение дерева начинается с листьев, которым присваивается строка слова или словосочетания, а также набор ее граммем.
def build(self, sent):
for word in sent:
new_node = Node(word[0], word[1], word[2], leaf=True)
self.nodes.append(new_node)
Далее осуществляется LR-анализ. Каждой свертке соответствует объединение двух узлов или листьев под общим предком. Узлу предка присваивается тэг-претерминал, который соответствует правилу грамматики, кроме того предок принимает граммемы главного члена группы, например, в глагольной группе V[tran] PRCL (e.g.
«хотел бы») признаки будут приняты от транзитивного глагола V[tran], а не от частицы PRCL; а в именной группе NP[case='nomn'] NP[case='gent'] (e.g.
«отец детей») признаки будут приняты от существительного в номинативе.
Важно заметить, что свертка происходит в установленном порядке:
def reduce(self):
self.reduce_ADJ() # прилагательные
self.reduce_NP() # именные группы
self.reduce_PP() # предложные
self.reduce_VP() # глагольные
self.reduce_S() # полные и неполные предложения
Такой порядок важен, так как исключает возможность «упустить» некоторые член предложения. Сначала формируются прилагательные вмести с модификаторами (e.g.
безумно красивый), затем именные группы, предложные и наконец глагольные. После этого идет поиск полных/неполных предложений, если таковы отсутствуют, то дерево не имеет корня, а значит и предложение не принадлежит языку грамматики.
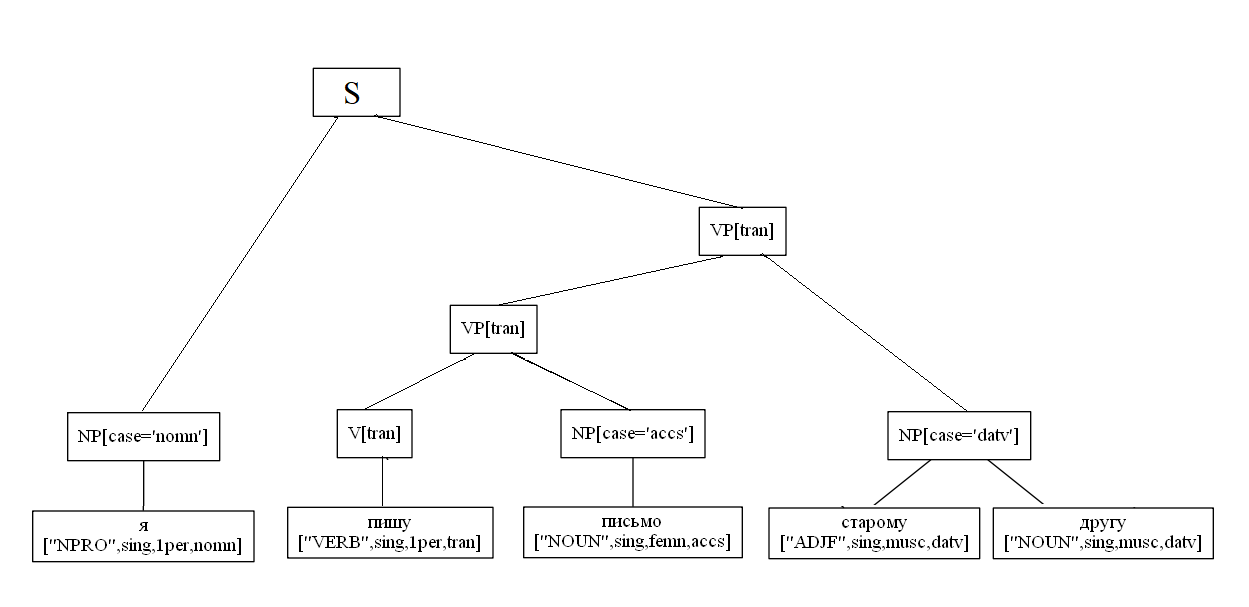
Рассмотрим условный пример построение дерева:
sent = "Я пишу письмо старому другу"
def build(self, sent):
for word in sent:
new_node = Node(word[0], word[1], word[2], leaf=True)
self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn']
NP[case='accs'] -> N[case='accs']
NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
Конкретный пример разбора двусоставного предложения:
import analyzer
parser = analyzer.Parser()
sent = "Пустыня внемлет богу, и здвезда с звездою говорит."
t = parser.parse(sent)
t[0].display()
S
NP[case='nomn']
Пустыня ['NOUN', 'sing', 'femn', 'nomn']
VP[tran]
VP[tran]
внемлет ['VERB', 'sing', '3per', 'tran', 'pres']
NP[case='datv']
богу ['NOUN', 'sing', 'datv']
S
NP[case='nomn']
звезда ['NOUN', 'sing', 'femn', 'nomn']
VP[tran]
PP
PREP
с ['PREP']
NP[case='ablt']
звездою ['NOUN', 'sing', 'femn', 'ablt']
VP[tran]
говорит ['VERB', 'sing', '3per', 'tran', 'pres']
Проблемы
Естественный язык неоднозначен, его понимание зависит от ряда факторов — от особенностей грамматического строя языка, от национальной культуры, от говорящего и т.д. Перечислим основные проблемы машинной обработки языка.
- Раскрытие анафор. Живой человек понимает анафору исходя из здравого смысла и контекста, а для компьютера это, очевидно, не всегда просто.
- Омонимия — совпадение в звучании и написании языковых единиц, значения которых не связаны друг с другом. Один из способ решения — вероятностные методы. В предложении "Я знаю это хорошо" вероятность того, что "это" является местоимением, а не частицей будет больше. Для таких методов требуется достаточный большой корпус.
- Свободный порядок слов приводит к тому, что толкование предложения может быть неоднозначным. Например, «Бытие определяет сознание» — что определяет что? В русском языке свободный порядок слов компенсируется развитой морфологией, служебными словами и знаками препинания, но в большинстве случаев для компьютера это представляет дополнительную проблему.
- Не все люди пишут грамотно. В сети люди склоны использовать сокращения, неологизмы, эллипсы и другие вещи, которые могут противоречить литературной норме. Из-за этого использование контекстно-свободных грамматик и словарей не всегда возможно.
Заключение
Проект
доступен для использования и редактирования. Он содержит сам анализатор, дерево разбора, а также кс-грамматику русского языка и небольшой словарь составных союзов и предикатов, которые отсутствуют в словаре OpenCorpora. На данный момент для длинных сложных предложений парсер может находить 3 и более деревьев, для решение этой проблемы вносятся изменения в грамматику, а также планируется использование вероятностных методов.