Сертификация по программе IBM Data Science Professional Certificate
- суббота, 8 февраля 2020 г. в 00:24:40
Статья является кратким обзором о сертификации по программе IBM Data Science Professional Certificate.
Будучи новичком в Python, мне пришлось столкнуться с реализацией задач:
В ходе сертификации необходимо было пройти 9 курсов:
Первые 3 курса носили повествовательный характер.
Курсы «Python for Data Science and AI» и «Databases and SQL for Data Science» ориентированы на новичков в программировании, и не требуют существенных начальных знаний.
Курсы «Data Analysis with Python», «Data Visualization with Python», «Machine Learning with Python» были значительно интереснее. Они отлично подготовлены и содержат большое количество лабораторных работ на Python.
А вот курс Applied Data Science Capstone заставил реально напрячься – нужно было придумать реальную задачу, связанную с анализом пространственных данных на Python, реализовать и грамотно оформить отчет.
Дальнейшая часть статьи оформлена в виде отчета о выполненном исследовании в ходе курса Applied Data Science Capstone.
Для читателей кому интересен программный код — ссылка на Github.
Общий объем кода исследования сравнительно невелик — около 700 строк.
Вопрос реальной практической ценности результатов исследования оставляю открытым.
Москва — одна из крупнейших столиц мира с население более 12 миллионов человек. Площадь Москвы более 2561.5 км², средняя плотность населения 4924.96 человек/км² 1.
Москва разделена на 12 административных округов (125 районов, 2 городских округа, 19 поселений) и имеет очень неоднородное население от 30429 человек/км² для района "Зябликово", до 560 человек/км² для района "Молжаниновский" 2.
Средняя стоимость жилой недвижимости колеблется от 68,768 рублей/м² для района "Кленовское" до 438,568 рублей/м² для района "Арбат" 3.
Владельцы кафе, фитнес центров и других социальных мест, ожидаемо, будут предпочитать районы с высокой плотностью населения. Для инвесторов будут важны стоимость недвижимости (аренды) и низкая конкурентная среда.
С другой стороны жители, большинстве, будут предпочитать районы с низкой стоимостью жилья, хорошей транспортной доступностью и доступностью социальных объектов.
В своем исследовании, я ставлю задачу определить оптимальные места для расположения фитнес центров в районах Москвы, принимая во внимание количество проживающего населения, стоимость недвижимости и плотность расположения других фитнес объектов.
Ключевыми критериями моего исследования будут:
Основываясь на формулировке проблемы и установленных критерия исследования, мне необходимо было собрать следующую информацию:
основной набор данных со списком районов Москвы, содержащий:
географические координаты центра каждого района
географические границы районов в формате GEOJSON
список объектов (фитнес центров, кафе, ...), размещенных в каждом районе с указанием их географических координат и классификационных категорий
Данные со списком районов Москвы были загружены с нескольких HTML страниц и объединены в общий набор данных.
Географические координаты центра района запрашивались через службу Nominatim. Которая, к сожалению, отличается некоторой нестабильностью, что потребовало делать большое количество итераций.
Географические границы районов в формате GEOJSON были загружены со страницы
Для поиска объектов на карте (фитнес центров, кафе и т.п.) был использован сервис Foursquare API. Весьма удачный сервис, который имеет одно существенное ограничение. В одном запросе можно получить не более 100 объектов в радиусе 1000 м. Для получения списка всех объектов в Москве был использован следующий подход:
Поскольку список районов Москвы был загружен с нескольких HTML страниц, то необходимо было выполнить существенный объем очистки данных. В частности:
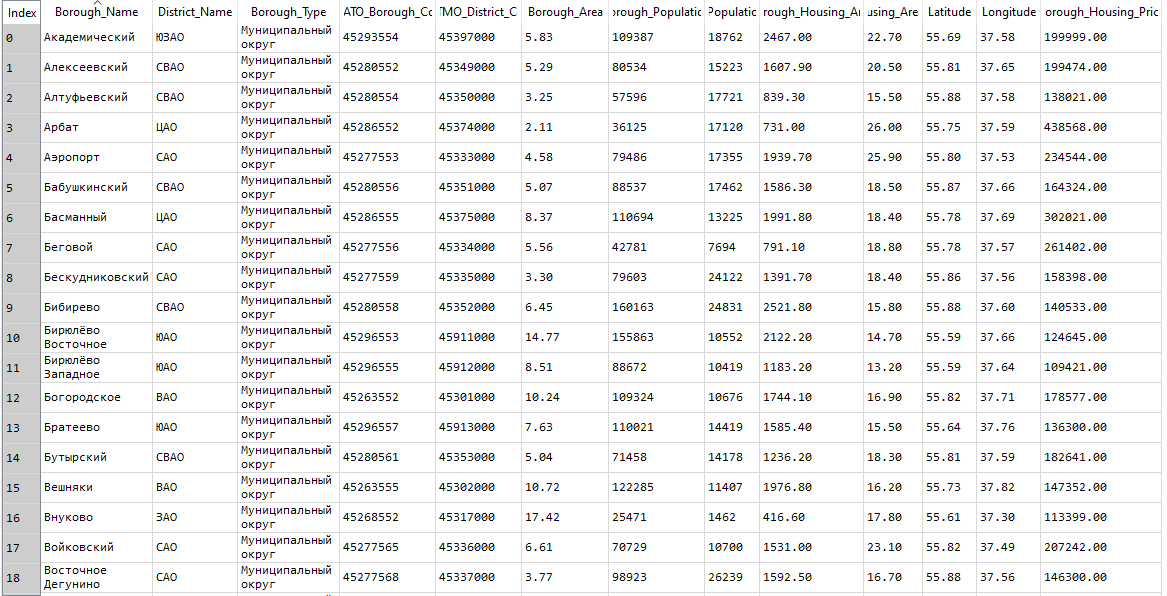
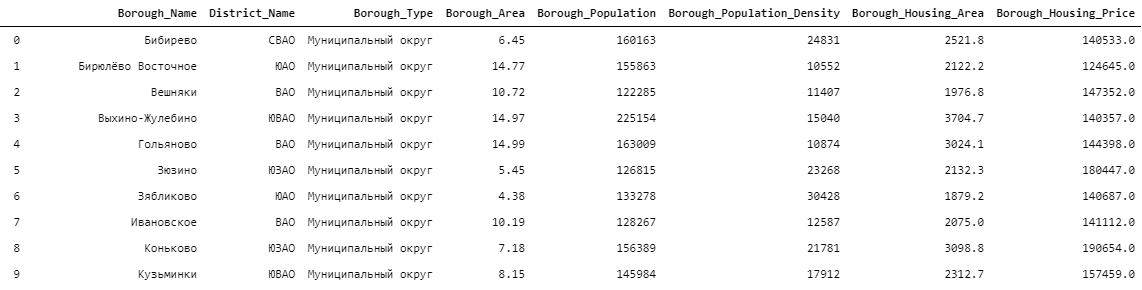
Результирующий очищенный набор данных содержит следующую информацию о 146 районах Москвы:
Подготовленный и очищенный набор данных со списком районов Москвы доступен по ссылке
Таблица ниже демонстрирует выборку из этого набора.
Сервис Nominatim, использованный для определения географических координат Москвы отличается нестабильностью при работе с русской буквой ё, поэтому для части районов (около 10 штук) координаты были собраны вручную.
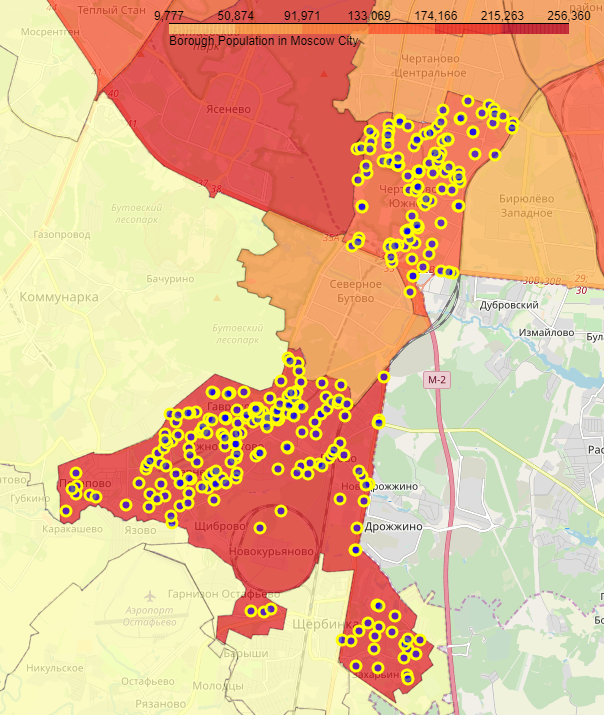
На рисунке ниже показана фоновая картограмма распределения количества населения по районам Москвы. Точками обозначены центры районов, окружности показывают максимальный радиус поиска с использованием сервиса Foursquare API.
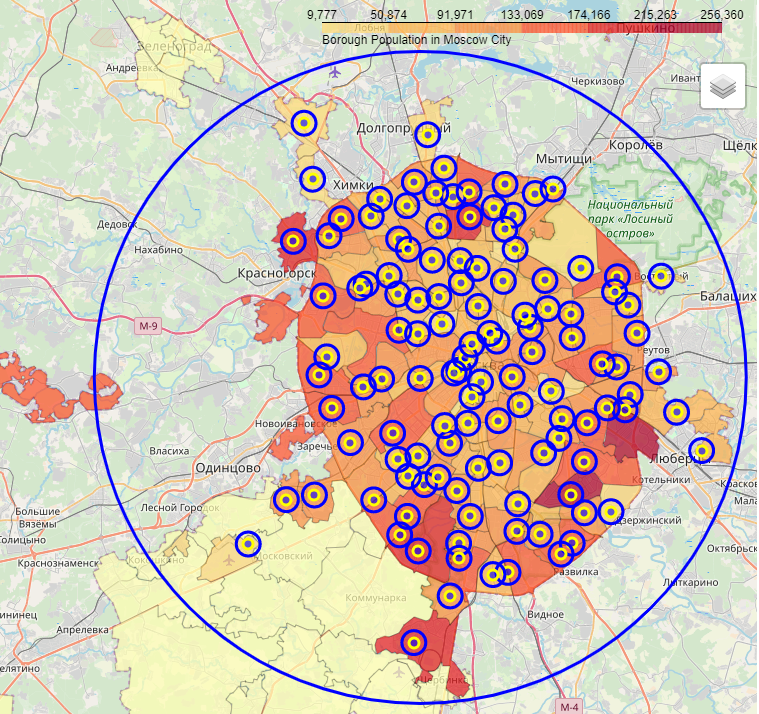
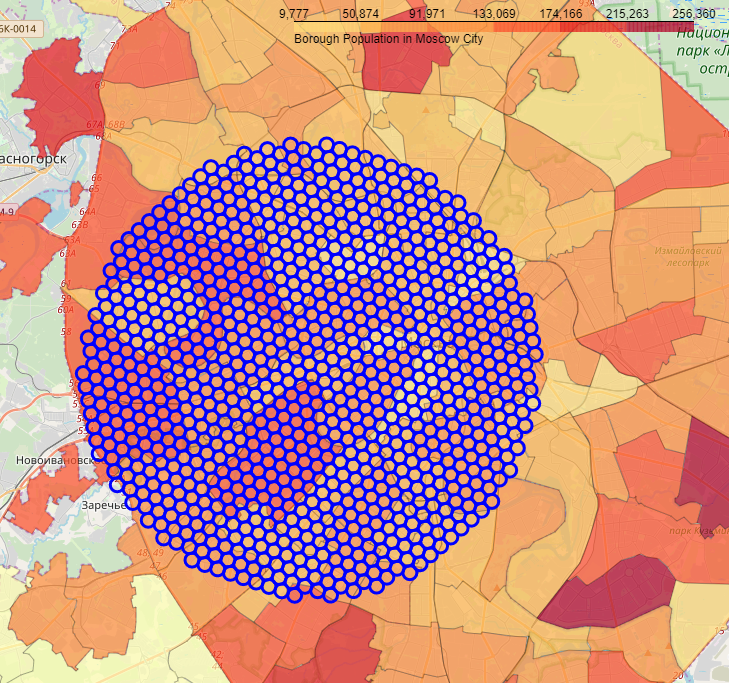
Как мы видим, использование географических координат районов для поиска объектов (фитнес центров, кафе, ...), совершенно бесполезно, так как каждый район имеет очень сложную форму. Поэтому была подготовлена сетка окружностей небольшого радиуса в пределах 28 000 метров от центра Москвы.
Рисунок ниже демонстрирует пример такой сетки. Координаты центра каждой окружности из сетки использовалась для запроса к сервису Foursquare API.
Используя Forsquare API, было было получено 34460 объектов (фитнес центров, кафе, ...) в 7899 ячейках сетки.
Поскольку для поиска объектов использовался радиус (350 метров) больше, чем радиус ячейки сетки (300 метров), возникла необходимость в удалении дубликатов.
После удаления дубликатов осталось 27622 уникальных объекта в радиусе 28 000 метров вокруг Москвы.
Вторая задача состояла в том, чтобы привязать каждый объект к району Москвы, в границах которого он располагается. Для выполнения этой задачи использовались географические координаты объектов и координаты границ каждого района в из GEOJSON файла.
Третья задача заключалась в том, чтобы исключить объекты, которые располагались за пределами границ исследования.
Четвертой задачей было получить основную категорию классификации для каждого объекта, чтобы отфильтровать фитнес центры от остальных объектов.
В результате был подготовлен набор данных для анализа из 20864 объектов (фитнес центров, кафе, ...), расположенных в 120 районах с их географическими координатами и категориями. Набор доступен по ссылке.
Таблица ниже демонстрирует выборку из этого набора.
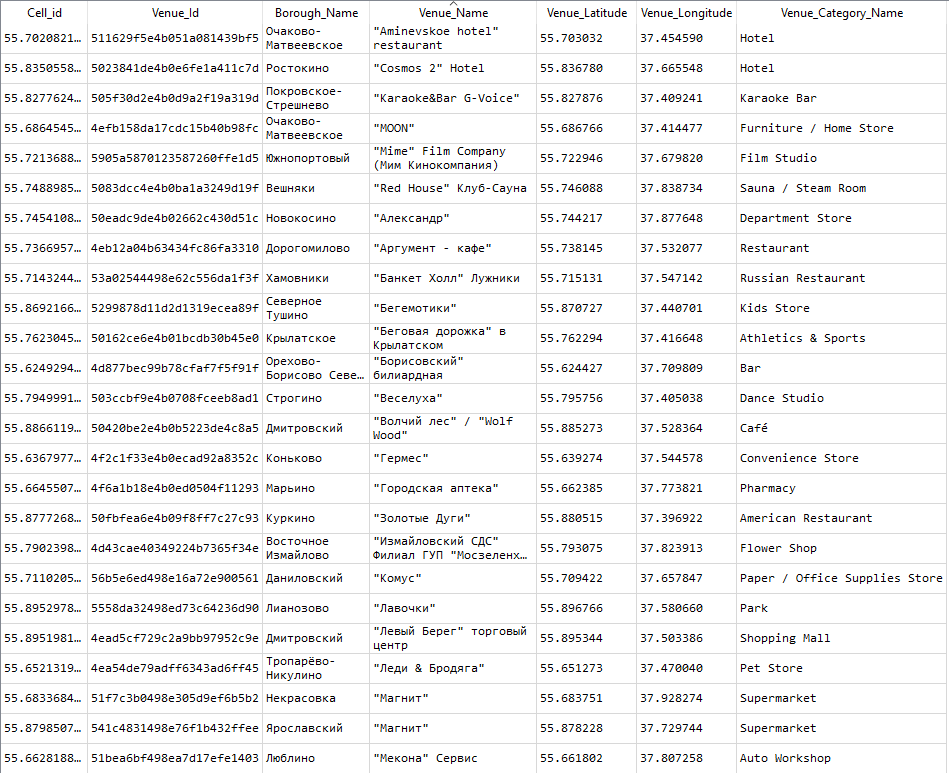
Рисунок ниже демонстрирует пример расположения объектов в районах "Чертаново Южное" и "Южное Бутово".
В соответствии с ключевыми критериями исследования необходимо:
Для первой задачи мной были использованы следующие подходы и методы машинного обучения:
Для решения второй задачи мной был использован подход, состоящий в отображении существующих фитнес объектов на интерактивной тепловой географической карте. Этот подход позволил визуально анализировать близость фитнес центров в каждом районе.
Набор данных со списком районов Москвы включает следующие ключевые переменные:
Таблица ниже показывает ключевую описательную статистику по укажанным переменным.
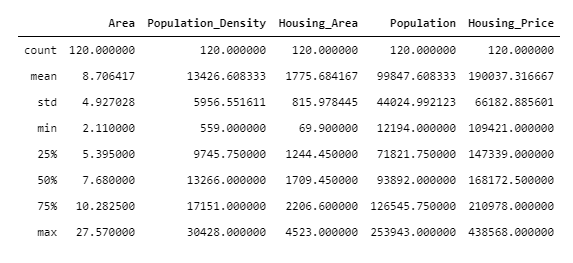
Как мы можем видеть, районы Москвы имеют очень неоднородную плотность населения от 12 194 до 253 943 человек.
Средняя стоимость недвижимости колеблется от 109 421 рублей/м² до 438 568 рублей/м².
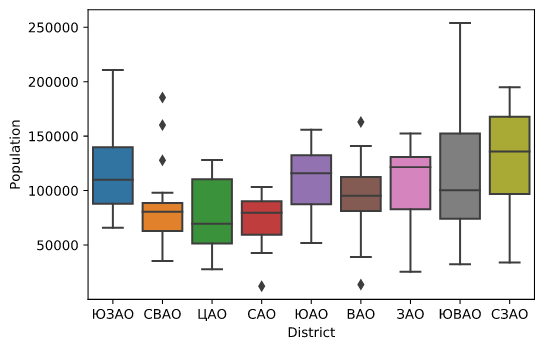
На рисунке ниже показана взаимосвязь между категориальной переменной District_Name и Borough_Population. Распределение населения между районами в разных округах существенно перекрываются, что не позволяет использовать переменную District_Name для классификации, но мы можем оценить, что наиболее густонаселенные районы расположены в районах «ЮЗАО», «ЮАО», «СЗАО» и «ЗАО».
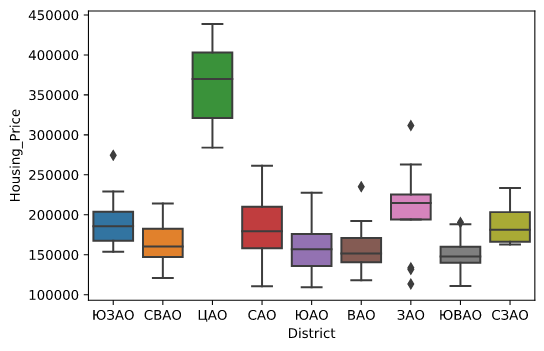
На следующем рисунке показана взаимосвязь между категориальной переменной District_Name и Borough_Housing_Price. Распределение цен на жилье между районами в разных округах имеет сильную дифференциацию, что позволяет предположить, что переменная District_Name будет хорошим потенциальным предиктором цены на жилье и может быть использована для задачи сегментации районов по стоимости недвижимости.
Детальный регрессионный анализ выходит за границы настоящего исследования.
Корреляционная зависимость между ключевыми переменными приводится для демонстрации подхода к понимания взаимного влияния переменных.
На рисунке ниже показана корреляционная зависимость между ключевыми переменными. Для настоящего исследования были приняты следующие типовые показатели статистической значимости корреляции (p-value):
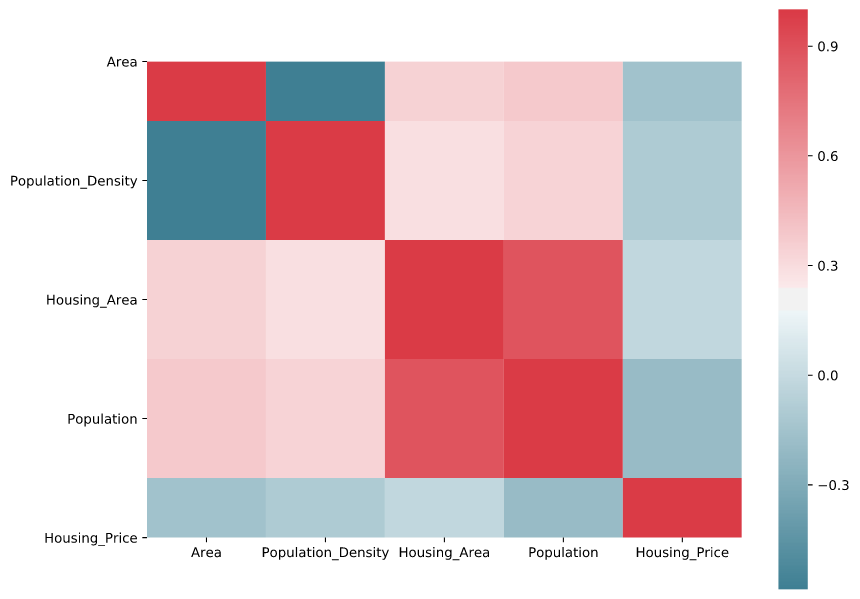
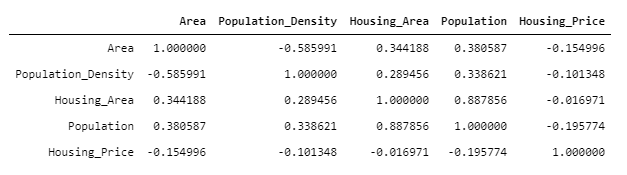
Описательная статистика и регрессионный анализ не позволяют, для моего исследования, провести качественную сегментацию районов с самым высоким населением и наименьшей ценой недвижимости.
Для этих целей, в исследовании была использована K-Means кластеризация с применением Elbow метода, который позволяет определить оптимальное количество кластеров, на которые будет выполнена сегментация.
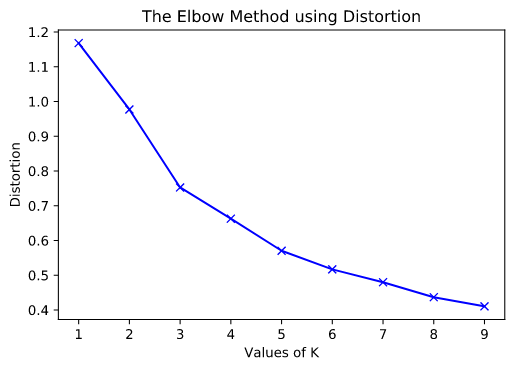
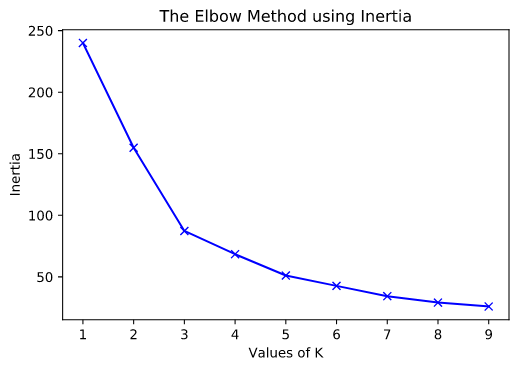
Для применения Elbow метода, была выполнена пробная кластеризация с различным количеством центроидов (от 1 до 10). Для каждого варианта были посчитаны искажение (distortion) и инертность (inertia).
Ниже приведены графики зависимости Distortion и Inertia от количества центроидов.
На графиках отчетливо заметны переломы (elbows) на 3 и 5 центроидах.
В своем исследовании я решил остановиться только на одном варианте кластеризации с 3-мя центроидами.
Для анализа кластеров, полученных в ходе K-Means сегментации, была собрана дополнительная статистика:
В следующей таблице показана собранная статистика

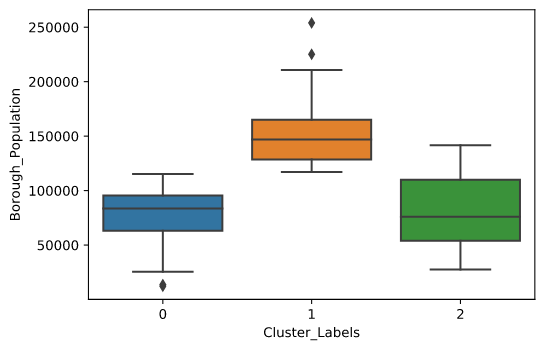
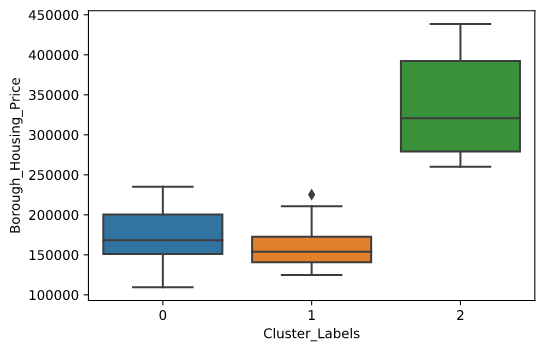
Сформированные кластеры имеют следующие отличительные особенности:
"1" кластер отлично соответствует критериям моего исследования:
Следующие схемы наглядно показывают сформированные кластеры в виде boxplot диаграмм.
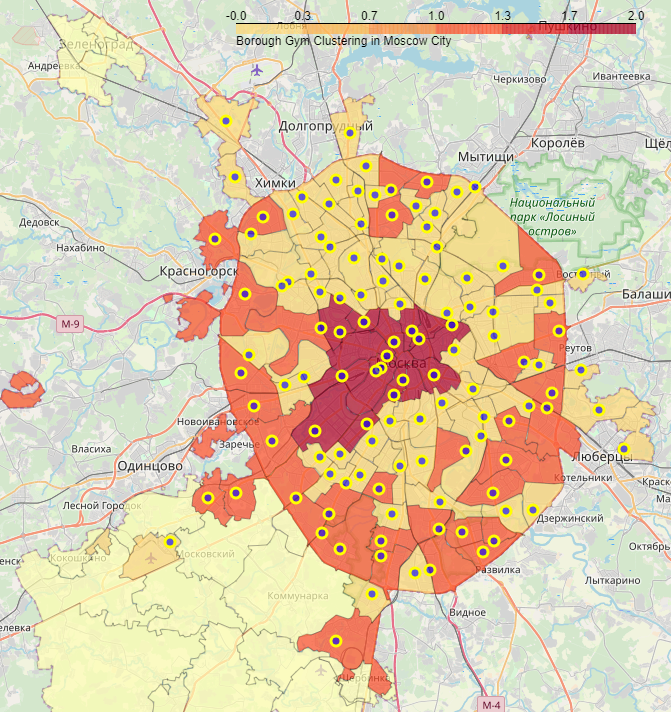
На следующем рисунке показана фоновая картограмма (choropleth map) построенных кластеров
Как можно видеть, районы в целевом "1" кластере в основном расположены на периферии города Москвы.
Но не все районы периферии хорошо населены, поэтому не соответствуют нашим критериям.
Результат моего исследования представлен в виде:
Набор данных со списком оптимальных районов доступен по ссылке.
Таблица ниже демонстрирует выборку из этого набора.
Из 20864 найденных объектов (фитнес центров, кафе, ...), 928 соответствуют категории "Gym / Fitness Center", из которых 259 расположены в районах из оптимального списка.
Набор данных со списком конкурирующих фитнес объектов доступен по ссылке
Таблица ниже демонстрирует выборку из этого набора.
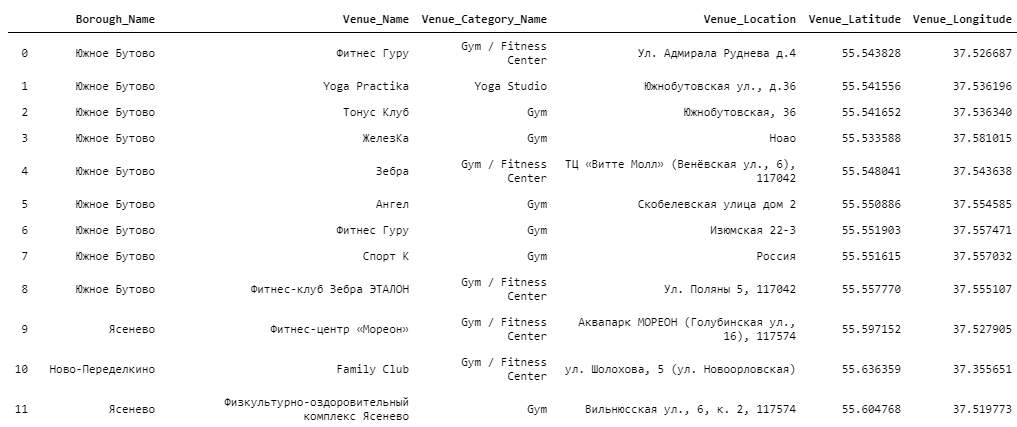
Интерактивная тепловая карта (heat map) и фоновая картограмма (choropleth map) доступна по ссылке (HTML в zip архиве) Interactive map
На рисунках ниже показаны фрагменты карты.
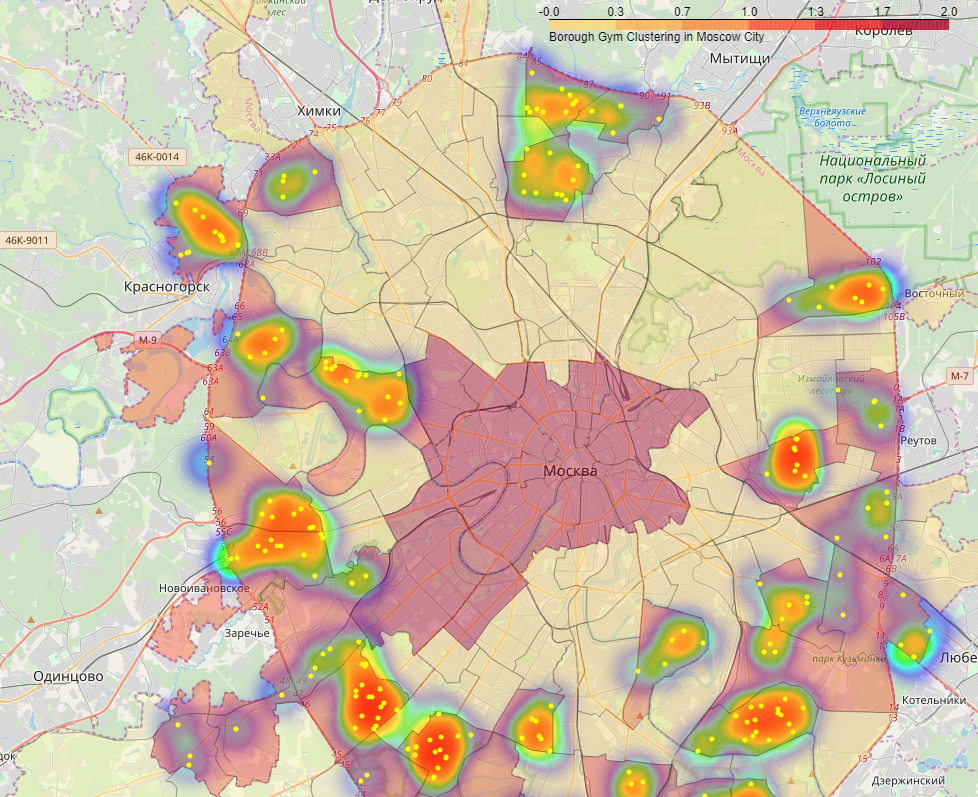
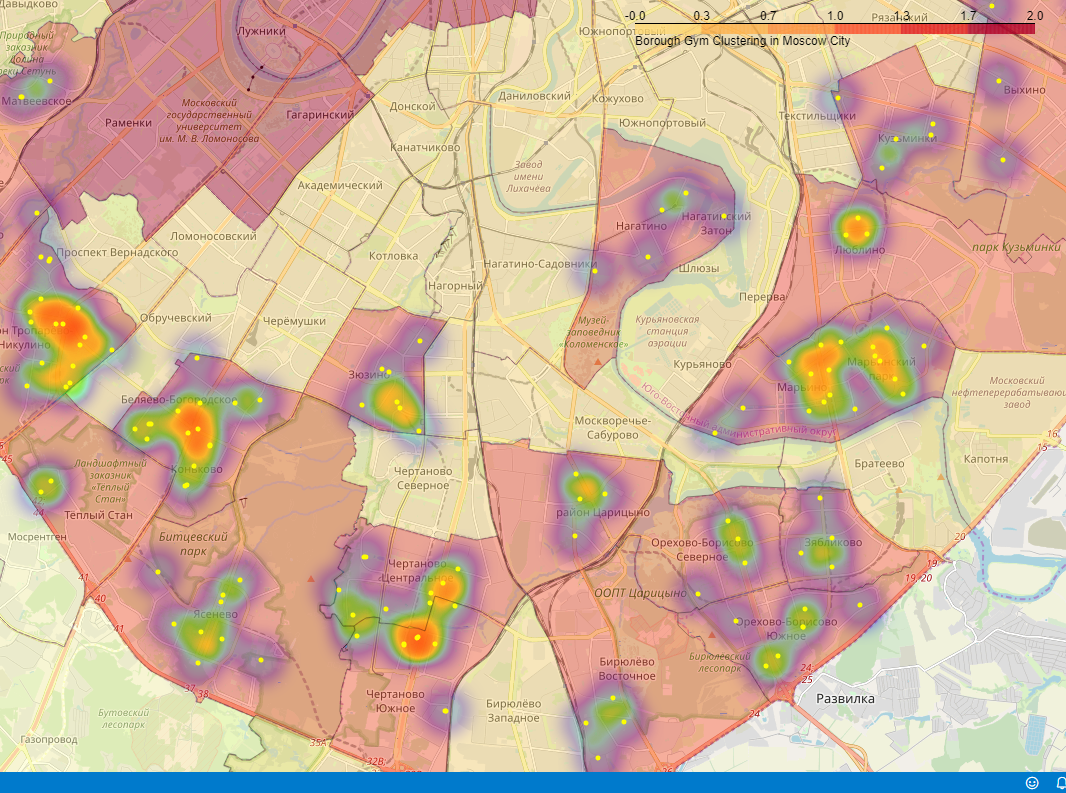
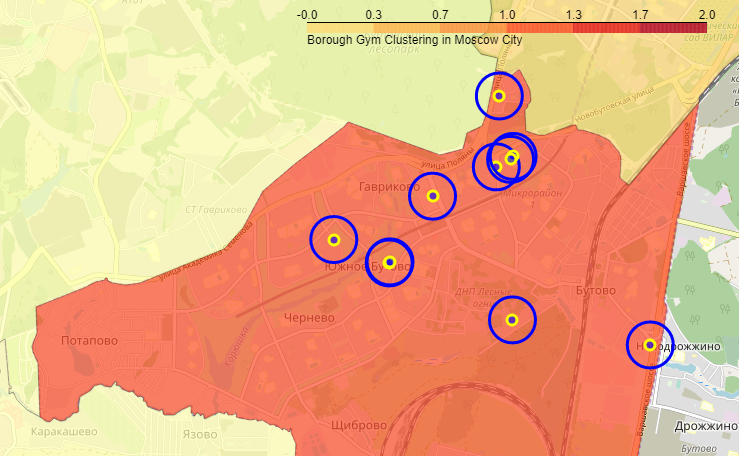
В ходе исследования мной была собрана следующая информация:
список районов Москвы, содержащий:
Собранная информация была выверена, очищена и опубликована на GitHub в виде набора .csv файлов.
Для сегментации районов по плотности населения и цене на недвижимость был использована K-Means кластеризация с применением Elbow метода. При исследовании графиков зависимости Distortion и Inertia от количества центроидов, я принял решение остановиться на одном варианте кластеризации с 3-мя центроидами. При необходимости может быть проведена альтернативная сегментация с 5 кластерами, которая может сформировать несколько отличный набор оптимальных районов для расположения фитнес центров.
Поэтому рекомендованный список районов следует рассматривать как отправную точку для более детального анализа.
Для определения близости конкурирующих фитнес объектов был использован подход, состоящий в отображении фитнес центров на интерактивной тепловой географической карте. Этот подход позволил визуально проанализировать близость существующих фитнес-центров в каждом районе и выделить области с низкой плотностью.
На основании полученных данных может быть проведен дополнительный анализ с использованием категориальной сегментации фитнес-объектов и автоматического расчета рекомендуемых мест расположения новых фитнес центров с учетом плотности конкурирующих фитнес объектов.