«Sanitize this!» и «Search that!»
- четверг, 6 ноября 2014 г. в 02:11:36

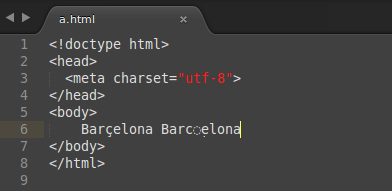

<!doctype html>
<head>
<meta charset="utf-8">
</head>
<body>
Barçelona Barçelona
</body>
</html>


U+00E7, ç). Во втором — цедилла пришпилена из комбинируемой диакритики. Firefox сломал об это зубы, а хром — нет.LIGATURES = {
'ffi' => 'ffi',
'ffl' => 'ffl',
'ff' => 'ff',
'fi' => 'fi',
'fl' => 'fl',
'ft' => 'ſt',
'st' => 'st'
}
Scenario: substitute ascii with wide characters # features/language.feature:25
Given input string is "Efficient Real Estate" # features/step_definitions/language_steps.rb:3
When monkeypatched method wideize is called on string instance # features/step_definitions/language_steps.rb:25
Then output string is printed out # features/step_definitions/language_steps.rb:43
Result: Efficient Real Estate
And output string length is 21 # features/step_definitions/language_steps.rb:51
And output string equals to "Efficient Real Estate" # features/step_definitions/language_steps.rb:47
U+FF00 диапазона.class String
ASCII_SYMBOLS, ASCII_DIGITS, ASCII_LETTERS_SMALL, ASCII_LETTERS_CAP = [
[(0x21..0x2F), (0x3A..0x40), (0x5B..0x60), (0x7B..0x7E)],
[(0x30..0x39)],
[(0x61..0x7A)],
[(0x41..0x5A)]
].map { |current| current.map(&:to_a).flatten.map { |i| [i].pack('U') } }
ASCII_ALL = [ASCII_SYMBOLS, ASCII_DIGITS, ASCII_LETTERS_SMALL, ASCII_LETTERS_CAP]
CODEPOINT_ORIGIN = 0xFF00 - 0x0020 # For FULLWIDTH characters
UTF_SYMBOLS, UTF_DIGITS, UTF_LETTERS_SMALL, UTF_LETTERS_CAP = ASCII_ALL.map { |current|
Hash[* current.join.each_codepoint.map { |char|
[[char].pack("U"), [char + CODEPOINT_ORIGIN].pack("U")]
}.flatten]
}
UTF_ALL = [UTF_SYMBOLS.values, UTF_DIGITS.values, UTF_LETTERS_SMALL.values, UTF_LETTERS_CAP.values]
UTF_ASCII = UTF_SYMBOLS.merge(UTF_DIGITS).merge(UTF_LETTERS_SMALL).merge(UTF_LETTERS_CAP)
ASCII_UTF = UTF_ASCII.invert
def shift_ascii_to_wide
self.gsub /#{ASCII_ALL.flatten.map{ |k| Regexp::quote k }.join('|')}/um, UTF_ASCII
end
DIACRITICS_MAP = {
'À' => [ 'A', "\u{0300}" ],
'Á' => [ 'A', "\u{0301}" ],
'Â' => [ 'A', "\u{0302}" ],
'Ã' => [ 'A', "\u{0303}" ],
'Ä' => [ 'A', "\u{0308}" ],
'Å' => [ 'A', "\u{030A}" ],
'Ç' => [ 'C', "\u{0327}" ],
'È' => [ 'E', "\u{0300}" ],
'É' => [ 'E', "\u{0301}" ],
'Ê' => [ 'E', "\u{0302}" ],
'Ë' => [ 'E', "\u{0308}" ],
'Ì' => [ 'I', "\u{0300}" ],
'Í' => [ 'I', "\u{0301}" ],
'Î' => [ 'I', "\u{0302}" ],
'Ï' => [ 'I', "\u{0308}" ],
'Ð' => [ 'D', "\u{0335}" ],
'Ñ' => [ 'N', "\u{0303}" ],
'Ò' => [ 'O', "\u{0300}" ],
'Ó' => [ 'O', "\u{0301}" ],
'Ô' => [ 'O', "\u{0302}" ],
'Õ' => [ 'O', "\u{0303}" ],
'Ö' => [ 'O', "\u{0308}" ],
'Ø' => [ 'O', "\u{0337}" ],
'Ù' => [ 'U', "\u{0300}" ],
'Ú' => [ 'U', "\u{0301}" ],
'Û' => [ 'U', "\u{0302}" ],
'Ü' => [ 'U', "\u{0308}" ],
'Ý' => [ 'Y', "\u{0301}" ],
'à' => [ 'a', "\u{0300}" ],
'á' => [ 'a', "\u{0301}" ],
'â' => [ 'a', "\u{0302}" ],
'ã' => [ 'a', "\u{0303}" ],
'ä' => [ 'a', "\u{0308}" ],
'å' => [ 'a', "\u{030A}" ],
'ç' => [ 'c', "\u{0327}" ],
'è' => [ 'e', "\u{0300}" ],
'é' => [ 'e', "\u{0301}" ],
'ê' => [ 'e', "\u{0302}" ],
'ë' => [ 'e', "\u{0308}" ],
'ì' => [ 'ı', "\u{0300}" ],
'í' => [ 'ı', "\u{0301}" ],
'î' => [ 'ı', "\u{0302}" ],
'ï' => [ 'ı', "\u{0308}" ],
'ð' => [ 'd', "\u{0335}" ],
'ñ' => [ 'n', "\u{0303}" ],
'ò' => [ 'o', "\u{0300}" ],
'ó' => [ 'o', "\u{0301}" ],
'ô' => [ 'o', "\u{0302}" ],
'õ' => [ 'o', "\u{0303}" ],
'ö' => [ 'o', "\u{0308}" ],
'ø' => [ 'o', "\u{0337}" ],
'ù' => [ 'u', "\u{0300}" ],
'ú' => [ 'u', "\u{0301}" ],
'û' => [ 'u', "\u{0302}" ],
'ü' => [ 'u', "\u{0308}" ],
'ý' => [ 'y', "\u{0301}" ],
'ÿ' => [ 'y', "\u{0308}" ]
}.map { |k,v| [k, v.join('')] }.to_h