Рост. Вес. Три соседа
- воскресенье, 8 сентября 2019 г. в 00:44:01
В поиске интересного и простого ДатаСета я набрёл этого красавца.
В нём есть данные о росте и весе 10 000 мужчин и женщин. Никакого описания. Ничего «лишнего». Только рост, вес и метка пола. Эта таинственная простота мне понравилась.
Что ж, начнём!
Погнали!

Для начала подгрузим нужные модули
# Для работы с табличными данными
import pandas as pd
# Для моих любимых графиков
import matplotlib.pyplot as plt
%matplotlib inline
# Модель машшиного обучения «К ближайших соседей»
from sklearn.neighbors import KNeighborsRegressor
# Для разбивки данных на тренировочный и тестовый наборы
from sklearn.model_selection import train_test_splitКогда библиотеки встали ровно — пришло время загрузить сам ДатаСет и посмотреть на первые 10 элементов. Это нужно, чтобы наше нутро было спокойно, что мы всё загрузили правильно.
Кстати, не пугайтесь, что рост и вес отличаются от привычных нам. Это из-за другой системы измерений: дюймы и фунты, вместо сантиметров и килограмм.
data = pd.read_csv('weight-height.csv')
data.head(10)| Gender | Height | Weight | |
|---|---|---|---|
| 0 | Male | 73.847017 | 241.893563 |
| 1 | Male | 68.781904 | 162.310473 |
| 2 | Male | 74.110105 | 212.740856 |
| 3 | Male | 71.730978 | 220.042470 |
| 4 | Male | 69.881796 | 206.349801 |
| 5 | Male | 67.253016 | 152.212156 |
| 6 | Male | 68.785081 | 183.927889 |
| 7 | Male | 68.348516 | 167.971110 |
| 8 | Male | 67.018950 | 175.929440 |
| 9 | Male | 63.456494 | 156.399676 |
Хорошо! Мы видим, что первые десять записей — «мужчины». Мы видим их рост (height) и вес (weight). Данные подгрузились хорошо.
Теперь можно посмотреть на количество строк в наборе.
data.shape
>> (10000, 3)Десять тысяч строк / записей. И у каждой по три параметра. То, что нужно!
Пришло время исправить систему измерений. Теперь тут сантиметры и килограммы.
data['Height'] *= 2.54
data['Weight'] /= 2.205
# И проверим результат
data.head(10)| Gender | Height | Weight | |
|---|---|---|---|
| 0 | Male | 187.571423 | 109.702296 |
| 1 | Male | 174.706036 | 73.610192 |
| 2 | Male | 188.239668 | 96.481114 |
| 3 | Male | 182.196685 | 99.792504 |
| 4 | Male | 177.499761 | 93.582676 |
| 5 | Male | 170.822660 | 69.030456 |
| 6 | Male | 174.714106 | 83.414008 |
| 7 | Male | 173.605229 | 76.177374 |
| 8 | Male | 170.228132 | 79.786594 |
| 9 | Male | 161.179495 | 70.929558 |
Вот теперь стало привычнее. И первая же запись нам говори о мужчине с ростом ~190см и весом ~110кг. Большой человек. Назовём его Боб.
Но как понять: это много или мало по сравнению с остальными? Возможно ли, что мы все плюс-минус Бобы? Это немного позже.
А сейчас узнаем, насколько симметрично в этом наборе данных сочетаются два гендера?
data['Gender'].value_counts()
>> Male 5000
Female 5000
Name: Gender, dtype: int64Идеально поровну. И это хорошо, ведь если бы было: 9999 мужчин и 1 женщина, то не осталось бы смысла делать вид, что этот ДатаСет одинакого хорошо раскрывает оба пола. В нашем случае — всё ок!
Сейчас интуиция подсказывает, что будет правильно разделить два пола и исследовать отдельно. Ведь в жизни мы часто видим, что мужчины и женщины имеют плюс-минус разные рост и вес
# Мужчины
data_male = data[data['Gender'] == 'Male'].copy()
# Женщины
data_female = data[data['Gender'] == 'Female'].copy()Давайте взглянем на небольшую описательную статистику, которую нам предлагает модуль pandas.
Мужчины:
data_male.describe()| Height | Weight | |
|---|---|---|
| count | 5000.000000 | 5000.000000 |
| mean | 175.326919 | 84.816608 |
| std | 7.272940 | 8.971045 |
| min | 148.353539 | 51.203147 |
| 25% | 170.623685 | 78.860665 |
| 50% | 175.330380 | 84.822470 |
| 75% | 180.311409 | 90.865216 |
| max | 200.656806 | 122.444308 |
Женщины:
data_female.describe()| Height | Weight | |
|---|---|---|
| count | 5000.000000 | 5000.000000 |
| mean | 161.820285 | 61.614555 |
| std | 6.848561 | 8.626970 |
| min | 137.828359 | 29.342461 |
| 25% | 157.211881 | 55.752425 |
| 50% | 161.876547 | 61.731330 |
| 75% | 166.531456 | 67.487948 |
| max | 186.409548 | 91.717557 |
Простым языком:
Описательная статистика — это набор чисел / характеристик для описания. Пожалуй, это самый простой для понимания вид статистики.
Представьте, что вы описываете параметры мяча. Он может быть:
С сильным упрощением можно сказать, что этим и занимается описательная статистика. Но делает это не с мячиками, а с данными.
А вот параметры из таблицы выше:
Среднее значение очень чувствительно к выбросам! Если четыре человека получают зарплату 10 000 ₽, а пятый — 460 000 ₽. То среднее будет — 100 000 ₽. А медиана останется прежней — 10 000 ₽.
Это не значит, что среднее — это плохой показатель. К нему нужно относиться внимательнее.
Кстати, с медианой тоже есть загвоздка.
Если количество измерений нечётное. То медиана — это значение посередине, если поставить данные «по росту».
А если чётное, то медиана — это среднее между двумя «самыми центральными».
Если в наборе данных только целые числа, а медиана получилась дробной — не удивляйтесь. Скорее всего количество измерений чётно.
Пример:
Сын принёс отметки со школы. Было пять уроков, он получил: 1, 5, 3, 2, 4
Пять оценок → нечётное количество
Сроим по росту: 1, 2, 3, 4, 5
Берём центральное — 3
Медианная оценка — 3
На следующий день сын принёс со школы новые оценки: 4, 2, 3, 5
Четыре оценки → нечётное количество
Строим по росту: 2, 3, 4, 5
Берём центральные: 3, 4
Находим их среднее: 3.5
Медиана — 3.5
Вывод: Молодец сына :)
Видим, что у мужчин среднее и медиана: 175см и 85кг. А у женщин: 162см и 62кг. Это говорит нам, что сильных выбросов нет. Либо они симметричны в обе стороны от медианы. Что бывает очень редко.
Но у обоих полов есть небольшие отклонения среднего от медианы. Но они несущественны и их видно только на сотых долях. Идём дальше!
Это график, который строит значения от минимума до максимума в порядке роста, и показывает количество отдельных экземпляров.
fig, axes = plt.subplots(2,2, figsize=(20,10))
plt.subplots_adjust(wspace=0, hspace=0)
axes[0,0].hist(data_male['Height'],
label='Male Height',
bins=100,
color='red')
axes[0,1].hist(data_male['Weight'],
label='Male Weight',
bins=100,
color='red',
alpha=0.4)
axes[1,0].hist(data_female['Height'],
label='Female Height',
bins=100,
color='blue')
axes[1,1].hist(data_female['Weight'],
label='Female Weight',
bins=100,
color='blue',
alpha=0.4)
axes[0,0].legend(loc=2,
fontsize=20)
axes[0,1].legend(loc=2,
fontsize=20)
axes[1,0].legend(loc=2,
fontsize=20)
axes[1,1].legend(loc=2,
fontsize=20)
plt.savefig('plt_histogram.png')
plt.show()
Данные распределяются колоколообразно. Очень похоже на нормальное распределение.
Помимо статистических тестов на нормальность распределения есть визуальный тест. Если распределение по виду и логике похоже на нормальное — можно считать с долей допущений, что мы имеем дело именно с ним.
Можно было бы сделать статистический тест на нормальность и определить p-value, но не умею это выходит за рамки статьи.
Pandas за нас может посчитать многое. Но нужно хотя бы раз посчитать некоторые статистики самому. Сейчас покажу, как скалькулировать стандартное отклонение.
Сделаем это на примере мужчин и характеристике — рост.
Формула:
, где
Код:
mean = data_male['Height'].mean()
print('mean:\t{:.2f}'.format(mean))
>> mean: 175.33Средний рост — 175см
, где
Код:
data_male['Height_d'] = (data_male['Height'] - mean) ** 2
data_male['Height_d'].head(10)
>> 0 149.927893
1 0.385495
2 166.739089
3 47.193692
4 4.721246
5 20.288347
6 0.375539
7 2.964214
8 25.997623
9 200.149603
Name: Height_d, dtype: float64Формула:
, где
Код:
disp = data_male['Height_d'].mean()
print('disp:\t{:.2f}'.format(disp))
>> disp: 52.89Дисперсия — 53
Формула:
, где
Код:
std = disp ** 0.5
print('std:\t{:.2f}'.format(std))
>> std: 7.27Стандартное отклонение — 7
Сейчас мы узнаем, в каких диапазонах роста и веса находятся 68%, 95% и 99.7% мужчин и женщин.
Это не так сложно — нужно прибавлять и отнимать стандартное отклонение от среднего. Выглядит это так:
Напишем вспомогательную функцию, которая будет считать это:
def get_stats(series, title='noname'):
# выводим название характеристики
print('= {} =\n'.format(title.upper()))
# получаем описательную статистику от pandas
descr = series.describe()
# выводим среднее
mean = descr['mean']
print('= Mean:\t{:.0f}'.format(mean))
# выводим стандартное отклонение
std = descr['std']
print('= Std:\t{:.0f}'.format(std))
# разделитель для красоты
print('\n= = = =\n')
# считаем интвервалы
## 68%
devi_1 = [mean - std, mean + std]
## 95%
devi_2 = [mean - 2 * std, mean + 2 * std]
## 99.7%
devi_3 = [mean - 3 * std, mean + 3 * std]
# выводим результат
print('= 68% is from\t\t{:.0f} to {:.0f}'.format(devi_1[0], devi_1[1]))
print('= 95% is from\t\t{:.0f} to {:.0f}'.format(devi_2[0], devi_2[1]))
print('= 99.7% is from\t\t{:.0f} to {:.0f}'.format(devi_3[0], devi_3[1]))Ну и применяем её к данным:
Мужчины | Рост
get_stats(data_male['Height'], title='Male Height')
>>
= MALE HEIGHT =
= Mean: 175
= Std: 7
= = = =
= 68% is from 168 to 183
= 95% is from 161 to 190
= 99.7% is from 154 to 197Мужчины | Вес
get_stats(data_male['Height'], title='Male Height')
>>
= MALE WEIGHT =
= Mean: 85
= Std: 9
= = = =
= 68% is from 76 to 94
= 95% is from 67 to 103
= 99.7% is from 58 to 112Женщины | Рост
get_stats(data_male['Height'], title='Male Height')
>>
= FEMALE HEIGHT =
= Mean: 162
= Std: 7
= = = =
= 68% is from 155 to 169
= 95% is from 148 to 176
= 99.7% is from 141 to 182Женщины | Вес
get_stats(data_male['Height'], title='Male Height')
>>
= FEMALE WEIGHT =
= Mean: 62
= Std: 9
= = = =
= 68% is from 53 to 70
= 95% is from 44 to 79
= 99.7% is from 36 to 87Отсюда выводы:
Теперь осталось только применить машинное обучение к этому набору и попробовать предстазать вес по росту.
Алгоритм «К ближайших соседей» прост. Он существует для задач классификаций — отличить котика от собачки — и для задач регрессии — угадать вес по росту. Это то, что нам нужно!
Для регрессии он использует такой алгоритм:
Для начала нужно разделить набор данных на обучающую и тестовую части и опробовать алгоритм
X_train, X_test, y_train, y_test = train_test_split(data_male['Height'], data_male['Weight'])Разделили, настало время пробовать.
# Три соседа
knr3 = KNeighborsRegressor(n_neighbors=3)
knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.8298400793623182
# Пять соседей
knr5 = KNeighborsRegressor(n_neighbors=5)
knr5.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr5.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.7958051642678619
# Семь соседей
knr7 = KNeighborsRegressor(n_neighbors=7)
knr7.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr7.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.7769249318420969Не будем далеко ходить и остановимся на трёх соседях. Но вопрос: сможет ли такая модель угадать мой вес?
knr3.predict([[180]])[0, 0]
>> 88.6759623626588188кг — это очень близко. В эту секунду мой вес — 89.8кг
Время построить мою любимую часть науки — графики.
array_male = []
# доверительный интервал 99.7%
xaxis = range(154, 198)
for h in xaxis:
ans = knr3.predict([[h]])
array_male.append(ans[0, 0])
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_male, 'r-', linewidth=4)
plt.title('Male heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_male.png')
plt.show()
X_train, X_test, y_train, y_test = train_test_split(data_female['Height'], data_female['Weight'])
knr3 = KNeighborsRegressor(n_neighbors=3)
knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.8135681584074799array_female = []
# доверительный интервал 99.7%
xaxis = range(141, 183)
for h in xaxis:
ans = knr3.predict([[h]])
array_female.append(ans[0, 0])
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_female, 'b-', linewidth=4)
plt.title('Female heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_female.png')
plt.show()
Ну и конечно интересно, как выглядят эти графики вместе:
# объединение интервалов мужчин и женщин
xaxis = range(154, 183)
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_male[:-15], 'r-', linewidth=4)
plt.plot(xaxis, array_female[13:], 'b-', linewidth=4)
plt.title('Together heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_together.png')
plt.show()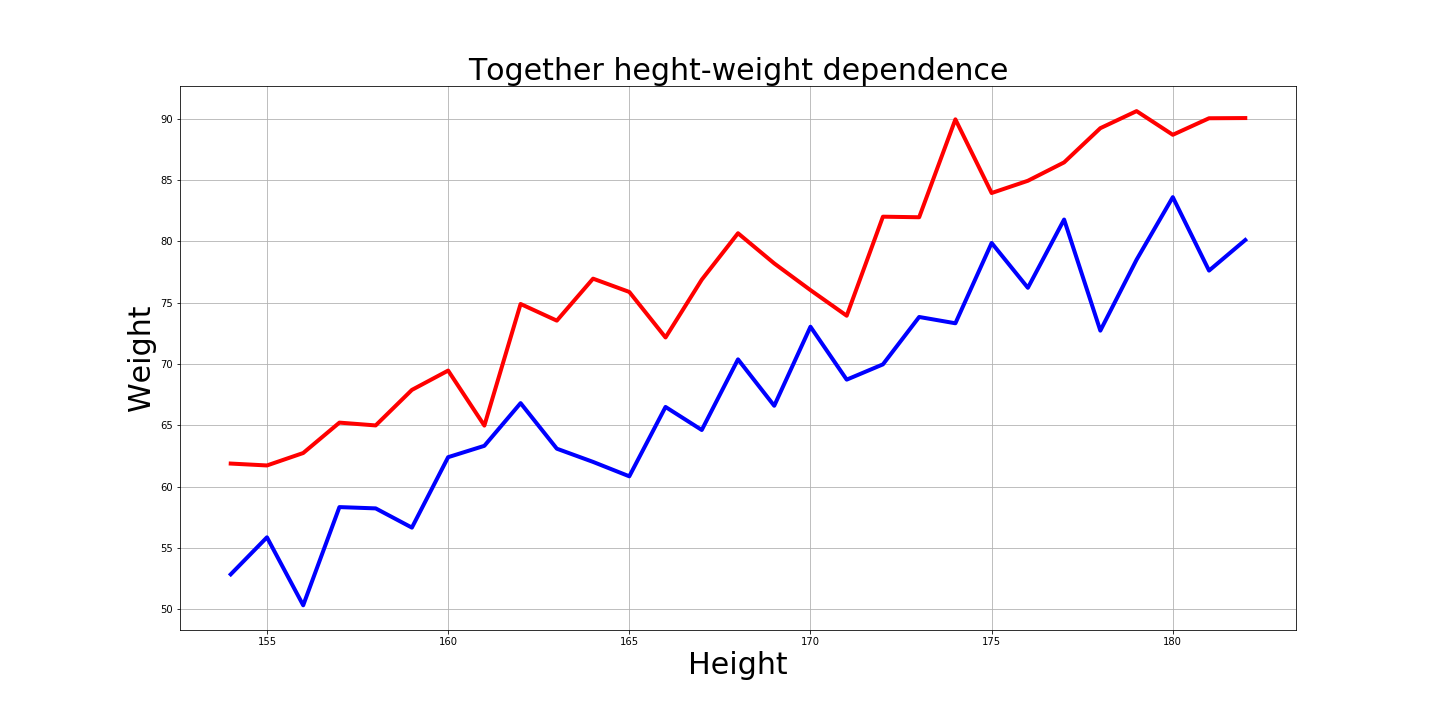
— В каком диапазоне вес и рост у большинства мужчин и женщин?
99.7% мужчин: от 154см до 197см и от 58кг до 112кг.
А 99.7% женщин: от 141см до 182см и от 36кг до 87кг.
— Какие они — «средний» мужчина и «средняя» женщина?
Средний мужчина — 175см и 85кг.
А средняя женщина — 162см и 62кг.
— Сможет ли простенькая модель машинного обучения «KNN» по этим данным угадать вес по росту?
Да, модель предсказала 88кг, а у меня 89.8кг.
Все, что сделал, собрал тут
Ставь лайк, если попал в 99.7% интервал