https://habr.com/ru/post/534662/- Python
- Игры и игровые приставки
- Логические игры
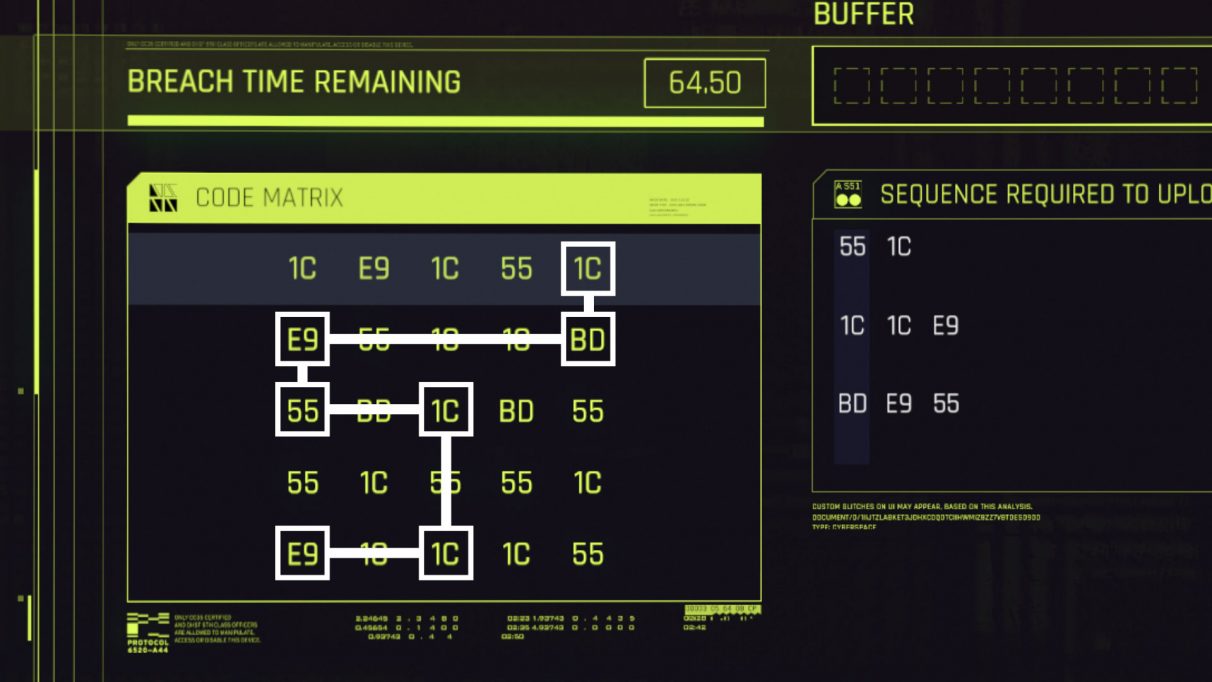
Если вы хотя бы отдалённо интересуетесь играми и не прожили последнюю пару лет в тайге, то, вероятно, слышали что-нибудь о Cyberpunk 2077. После долгого ожидания она наконец вышла! И в ней есть мини-игра про взлом! И чем больше получишь в ней очков, тем ценнее приз! Может ли магия Python дать нам преимущество в этом жестоком Нете? Разумеется.
Краткое описание мини-игры: игроку даётся квадратная матрица и одна или несколько последовательностей шестнадцатеричных чисел, а также буфер определённой длины. Цель игрока — завершить наибольшее количество последовательностей, выбирая столько узлов, сколько позволяет буфер. Каждая последовательность заполняется значением, если выбранный узел является следующим узлом последовательности. В начале игры можно выбрать любое из значений в первой строке матрицы. После этого в каждом ходе можно попеременно выбирать N-ный столбец/строку, где N — индекс последнего выбранного значения. Если это ужасное описание вам не помогло, то более подробное можно прочитать
здесь.
Учитываются все допустимые пути, а окончательное количество очков каждого пути вычисляется в зависимости от того, сколько последовательностей было завершено при его прохождении. Путь с наибольшим количеством очков затем выводится на экран. К сожалению, мой алгоритм не особо интересен и эффективен. Однако он должен быть достаточно быстр, чтобы решить любую из мини-игр Cyberpunk за несколько секунд, и этого вполне хватает! Уверен, что есть какие-то простые способы ускорения выполнения скрипта, но я решил поделиться уже имеющимися результатами, и обновлять пост по мере поступления новых идей и предложений.
Начнём с компонентов игры:
- Матрица кода: многомерный массив, содержащий шестнадцатеричные значения (узлы) — «игровое поле»
code_matrix = [
[0x1c, 0xbd, 0x55, 0xe9, 0x55],
[0x1c, 0xbd, 0x1c, 0x55, 0xe9],
[0x55, 0xe9, 0xe9, 0xbd, 0xbd],
[0x55, 0xff, 0xff, 0x1c, 0x1c],
[0xff, 0xe9, 0x1c, 0xbd, 0xff]
]
- Буфер: число, обозначающее максимальное количество выбираемых координат
buffer_size = 7
- Координата: точка в матрице кода
- Путь: упорядоченный набор уникальных координат, по которым проходил пользователь
# The same coordinate can't be chosen more than once per path
class DuplicatedCoordinateException(Exception):
pass
# All paths match the following pattern:
# [(0, a), (b, a), (b, c), (d, c), ...]
class Path():
def __init__(self, coords=[]):
self.coords = coords
def __add__(self, other):
new_coords = self.coords + other.coords
if any(map(lambda coord: coord in self.coords, other.coords)):
raise DuplicatedCoordinateException()
return Path(new_coords)
def __repr__(self):
return str(self.coords)
- Последовательность: пути, дающие при завершении награды различного качества
sequences = [
[0x1c, 0x1c, 0x55],
[0X55, 0Xff, 0X1c],
[0xbd, 0xe9, 0xbd, 0x55],
[0x55, 0x1c, 0xff, 0xbd]
]
- Очки: вычисления, которые можно настраивать, чтобы отдавать приоритет разным наградам
class SequenceScore():
def __init__(self, sequence, buffer_size, reward_level=0):
self.max_progress = len(sequence)
self.sequence = sequence
self.score = 0
self.reward_level = reward_level
self.buffer_size = buffer_size
def compute(self, compare):
if not self.__completed():
if self.sequence[self.score] == compare:
self.__increase()
else:
self.__decrease()
# When the head of the sequence matches the targeted node, increase the score by 1
# If the sequence has been completed, set the score depending on the reward level
def __increase(self):
self.buffer_size -= 1
self.score += 1
if self.__completed():
# Can be adjusted to maximize either:
# a) highest quality rewards, possibly lesser quantity
self.score = 10 ** (self.reward_level + 1)
# b) highest amount of rewards, possibly lesser quality
# self.score = 100 * (self.reward_level + 1)
# When an incorrect value is matched against the current head of the sequence, the score is decreased by 1 (can't go below 0)
# If it's not possible to complete the sequence, set the score to a negative value depending on the reward
def __decrease(self):
self.buffer_size -= 1
if self.score > 0:
self.score -= 1
if self.__completed():
self.score = -self.reward_level - 1
# A sequence is considered completed if no further progress is possible or necessary
def __completed(self):
return self.score < 0 or self.score >= self.max_progress or self.buffer_size < self.max_progress - self.score
class PathScore():
def __init__(self, path, sequences, buffer_size):
self.score = None
self.path = path
self.sequence_scores = [SequenceScore(sequence, buffer_size, reward_level) for reward_level, sequence in enumerate(sequences)]
def compute(self): # Returns the sum of the individual sequence scores
if self.score != None:
return self.score
for row, column in self.path.coords:
for seq_score in self.sequence_scores:
seq_score.compute(code_matrix[row][column])
self.score = sum(map(lambda seq_score: seq_score.score, self.sequence_scores))
return self.score
Генерация пути очень похожа на обход графа поиска в глубину. Единственное значимое отличие заключается в том, что доступные узлы варьируются в зависимости от текущего хода и координат предыдущего узла.
# Returns all possible paths with size equal to the buffer
def generate_paths(buffer_size):
completed_paths = []
# Return next available row/column for specified turn and coordinate.
# If it's the 1st turn the index is 0 so next_line would return the
# first row. For the second turn, it would return the nth column, with n
# being the coordinate's row
def candidate_coords(turn=0, coordinate=(0,0)):
if turn % 2 == 0:
return [(coordinate[0], column) for column in range(len(code_matrix))]
else:
return [(row, coordinate[1]) for row in range(len(code_matrix))]
# The stack contains all possible paths currently being traversed.
def _walk_paths(buffer_size, completed_paths, partial_paths_stack = [Path()], turn = 0, candidates = candidate_coords()):
path = partial_paths_stack.pop()
for coord in candidates:
try:
new_path = path + Path([coord])
# Skip coordinate if it has already been visited
except DuplicatedCoordinateException:
continue
# Full path is added to the final return list and removed from the partial paths stack
if len(new_path.coords) == buffer_size:
completed_paths.append(new_path)
else: # Add new, lengthier partial path back into the stack
partial_paths_stack.append(new_path)
_walk_paths(buffer_size, completed_paths, partial_paths_stack, turn + 1, candidate_coords(turn + 1, coord))
_walk_paths(buffer_size, completed_paths)
return completed_paths
Давайте запустим код и убедимся, что всё работает правильно. Хотя большинство мини-игр со взломом протокола имеют рандомизированные значения, в квесте «Spellbound» используется фиксированное состояние, и наилучшее решение уже известно. Оно создано GamerJournalist:
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 1), (2, 1), (2, 3), (1, 3), (1, 0), (4, 0), (4, 3)] -> Should traverse 3rd and 4th sequences, finishes in ~3 seconds
print(max_path[0])
Успех! Из любопытства я решил увеличивать размер буфера, пока не смогу найти путь, выполняющий все последовательности. Учтите, что для вычисления результата может понадобиться какое-то время, поскольку алгоритм проходит по всем возможным путям длиной 11.
buffer_size = 11
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 0), (1, 0), (1, 3), (3, 3), (3, 1), (0, 1), (0, 3), (2, 3), (2, 0), (4, 0), (4, 2)] -> Should traverse all sequences, finishes in ~40 seconds
print(max_path[0], max_path[1])
Хорошо, а теперь займёмся оптимизацией! Будем предполагать, что существует хотя бы один путь с неотрицательным количеством очков. Благодаря этому мы можем прерывать обхождение частичного пути, если его текущее количество очков (скорректированное в соответствии с размером буфера и текущим ходом) меньше 0.
def generate_paths(...):
...
def _walk_paths(...):
...
# Full path is added to the final return list and removed from the partial paths stack
if len(new_path.coords) == buffer_size:
completed_paths.append(new_path)
# If the partial path score is already lower than 0 we should be able to safely stop traversing it
elif PathScore(new_path, sequences, buffer_size).compute() < 0:
continue
else: # Add new, lengthier partial path back into the stack
partial_paths_stack.append(new_path)
_walk_paths(buffer_size, completed_paths, partial_paths_stack, turn + 1, candidate_coords(turn + 1, coord))
...
Давайте попробуем получить исходный результат заново с буфером длиной 7:
buffer_size = 7
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 1), (2, 1), (2, 3), (1, 3), (1, 0), (4, 0), (4, 3)] -> Should traverse 3rd and 4th sequences, finishes instantly
print(max_path[0])
Сработало! Новое решение заметно быстрее, но буфер длиной 7 уже и так вычислен довольно быстро, поэтому трудно ощутить ускорение. Посмотрим, как проявляет себя оптимизация при вычислении пути с наибольшей наградой.
buffer_size = 7
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 0), (1, 0), (1, 3), (3, 3), (3, 1), (0, 1), (0, 3), (2, 3), (2, 0), (4, 0), (4, 2)] -> Should traverse all sequences, finishes in ~13 seconds
print(max_path[0])
Ускорение почти в три раза благодаря добавлению двух строк кода. Совсем неплохо. Вероятно, существуют и другие простые возможности оптимизации, поэтому я, может быть, через неделю дополню пост. Ну а на этом всё. Присылайте свои предложения по улучшению качества/производительности кода!