https://habrahabr.ru/post/280812/- Программирование
- Алгоритмы
- Python
- Google API

Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый
раз я пробовал найти аномалии на карте цен недвижимости. Просто так. На этот раз идея была построить систему, которая смогла бы сама решать очень популярную ныне Google Recaptcha 2.0, основываясь на некоторых алгоритмах и большой базе обучающих примеров.
Google Recaptcha 2.0 представляет собой набор изображений (9 или 16 квадратных картинок под одной инструкцией), среди которых пользователю, для подтверждения своей разумности, нужно выбрать все изображения одной категории. Речь пойдет
НЕ о построении системы машинного обучения — распознавать мы будем именно капчи!

Если читатель не хочет вдаваться в подробности технического плана и романтику исследований, то вывод всей статьи будет сосредоточен около
БКГ в конце.
Обучающие выборки капч для данного исследования мне любезно предоставил сервис антикапчи
RuCaptcha.com, которые разработали API для доступа к выборкам решенных капч специально для моего исследования.
Стоит заметить, что Google располагает не очень большим набором инструкций для капч (пример: Select all images with recreational vehicle) на всех основных языках мира, а некоторые инструкции встречаются намного чаще других. Далее в статье под типом будут подразумеваться именно инструкции для капчи.
Тысячи изображений
После выгрузки и сортировки пробной партии изображений я стал вручную разбирать разные типы капч. Первым делом я построил md5 суммы от всех капч одного типа в надежде найти совпадения. Самый простой способ не сработал — совпадений попросту не было. А что? — Имею право!
Прогуливаясь глазами по иконкам изображений, нашлось кое-что интересное. Вот, например, 4 одинаковых лимузина:
Одинаковые, да не совсем — это заметно по размерам колеса в нижних левых углах. Почему для сравнения были выбраны именно лимузины? Их легче всего было просматривать глазами — картинки дорожных знаков или наименований улиц сливаются в одну, а искать похожие лимузины или пикапы было проще простого. Оценив глазами изображения разных типов, во многих я увидел повторяющиеся капчи с разными деформациями — растяжениями, сжатиями или смещениями. Найдя подходящую функцию похожести изображений и собрав достаточную базу, можно было надеяться на некоторый успех.
Perceptive hash
Почти все поисковые запросы ведут именно к нему. На хабре можно отыскать достаточно много статей, посвященных перцептивному хэшу (
1,
2,
3,
4). Быстро нашлась и python библиотечка
ImageHash, использующая пакеты NumPy и SciPy.
Как же работает Perceptive Hash? Вкратце:
dct = scipy.fftpack.dct(scipy.fftpack.dct(pixels, axis=0), axis=1)
dctlowfreq = dct[:hash_size, :hash_size]
med = numpy.median(dctlowfreq)
diff = dctlowfreq > med
- Изображение сжимается до размера hash_size.
- От значения получившихся пиксел берется дискретное фурье преобразование.
- От фурье преобразования считается медиана.
- Матрица фурье преобразования сравнивается с медианой и в качестве результата мы получаем матрицу нулей и единиц.
Тем самым от изображения мы можем выделить некоторый инвариант, который не будет меняться при незначительных изменениях исходного изображения. Стандартный hash_size равен 8 и он неплохо себя показал на пробных сравнениях. Одно из замечательных свойств данного хэша — их можно сравнивать и разность их выглядит как натуральное число.
Сейчас поясню. Хэш изображения — это матрица нулей или единиц (ноль — ниже медианы, а единица — выше). Для нахождения разницы, матрицы сравниваются поэлементно и значение разницы равняется количеству отличающихся элементов на одних и тех же позициях. Этакий XOR на матрице.
Десятки тысяч изображений
Перцептивный хэш хорошо определял сходство между одним и тем же лимузином, но с разными деформациями, и различие между совершенно разными изображениями. Однако, хэш подходит скорее для описания форм, изображенных на картинке: при увеличении числа капч неизбежны совпадения по форме объектов, но не по содержанию картинки (с некоторым порогом срабатывания, разумеется).
Так и случилось. С увеличением базы капч, росла необходимость в добавлении ещё одной сравнительной величины для изображений.
Объективную цветовую характеристику изображения можно описать гистограмой интенсивности цветов. Функция расстояния для двух гистограмм (она же функция разности) — сумма среднеквадратичных отклонений элементов гистограммы. Довольно неплохая связка получается.
Абзац о подборе границ срабатывания и механизме поиска похожих изображенийУстановление максимальных допустимых разниц хэшей происходило вручную:
- Имеем пороги срабатывания для разниц перцептивного хэша и гистрограмы: max phash distance и max histogram distance
- Для всех изображений одного типа строим группы похожих, где каждой капче соответствует пара чисел — расстояния до «главы» группы phash distance и histogram distance
- Открываем всю группу изображений и визуально проверяем наличие ошибок
- В случае ложных срабатываний корректируем один из порогов
В пункте 1 я упомянул, что у группы есть «глава»: При поиске похожих изображений, капча сравнивается не со всей базой, а лишь с главами групп похожих изображений. В каждой группе гарантируется, что все изображения являются похожими с главой, но не гарантируется их похожесть друг с другом. Таким образом достигается некоторый выйгрыш в быстродействии.
Чуть позже я узнал об алгоритмах
жадного поиска, но было поздно. В теории такой наколеночный алгоритм ищет первое, а не самое подходящее изображение, как в алгоритме жадного поиска. Однако это мешает только когда поиск ведется по всем типам инструкций сразу.
С одной стороны, учитывая тот факт, что разница
phash у очень близких по форме изображений будет равна нулю, и представив, что процент ложных срабатываний будет достаточно низок — можно подумать, что использование одного лишь перцептивного хэша будет быстрее, чем использование двух хэшей. Но что говорит практика?
Для сравнения я использовал две выборки капч разных типов по 4000 изображений. Один тип обладает хорошей «похожестью», а другой — наоборот. Под похожестью (она же сжимаемость) я имею в виду вероятность того, что 2 случайных изображения одного типа с заданными порогами срабатывания будут одинаковыми с точки зрения хэшей. Результаты оценки следующие:
instructions : phash only : both hashes
дорожные знаки (не названия улиц!) : 0.001% : 0.002%
лимузины : 52.97% : 60.12%
Больше половины изображений лимузинов похожи между собой, вот это да! При использовании обоих хэшей результат все-таки лучше, но как дело обстоит с производительностью?
instructions : phash only : both hashes
дорожные знаки (не названия улиц!) : 31.37s : 31.06s
лимузины : 17.85s : 17.23s
Удивительно, но использование обоих хэшей оказалось быстрее, чем использование только перцептивного хэша с нулевым максимальным отклонением. Разумеется, это вызванно разницей в количестве операция сравнения изображений, и это притом, что сравнение гистограм из 300 значений медленнее сравнения перцептивных хешей размером 8 байт на 28.7%!
Сотни тысяч изображений
Проблемы производительности дали о себе знать на действительно большом объеме выборок. Для самых популярных типов время поиска похожих изображений на моём ноутбуке составляло уже секунды. Требовалась оптимизация поиска с минимальными потерями точности.
Изменение точности phash не казалось мне хорошей идеей. Поэтому посмотрим внимательно на гистограмму интенсивности цветов какой-то капчи:
Если бы меня попросили кратко описать эту гистограмму, то я бы сказал так: «Резкий пик на значении абсциссы 55, затем постепенное снижение графика и два локальных минимума на значениях 170 и 220». Если мы возьмём больше графиков гистограмм от похожих капч, то заметим, что эти графики по форме повторяют друг друга с небольшими погрешностями в положении максимумов и минимумов (экстремумов). Так почему бы не использовать эти значения для того, чтобы заведомо отсекать непохожие?
Окей гугл, как найти экстремумы в графике на питоне?
import numpy as np
from scipy.signal import argrelextrema
mins = argrelextrema(histogram, np.less)[0]
maxs = argrelextrema(histogram, np.greater)[0]
Описание функции
argrelextrema говорит само за себя: Calculate the relative extrema of data.
Однако, наша гистограмма слишком зубчатая и локальных экстремумов намного больше, чем нужно. Необходимо сгладить функцию:
s = numpy.r_[x[window_len-1:0:-1],x,x[-1:-window_len:-1]]
Усредняем график алгоритмом скользящего окна. Размер окна выбирался опытным путем для того, чтобы количество минимумов или максимумов было в среднем 2, и остановился на значении 100 пиксел. Следствием работы такого алгоритма является красивый, гладкий и… удлиненный график. Удлиненный ровно на размер окна.
Соответственно смещаются позиции экстремумов:
mins = array([ 50, 214, 305])
maxs = array([116, 246])
Статистика распределения экстремумовПо всем имеющимся изображениями с двумя локальными минимумами (или максимумами) я подвел статистику их позиций. На графиках встречались огромные пики (до 100х), которые для наглядности пришлось укоротить.



Графики экстремумов зрительно можно разбить на две части на отметке 101. Почему так получается? После фильтрации выяснилось, что это две совершенно разные и почти непересекающиеся группы изображений, причем слева от отметки находится около 200к изображений разных типов. Такое хитрое распределение дают темные капчи вроде тех, что справа. Похожую ситуацию, но с изображениями много светлее, можно наблюдать у минимумов.
Сопоставив многие графики похожих капч я установил, что допустимым отклонением от позиций локальных экстремумов будет 3-4 пиксела. Регулируя эту величину в меньшую сторону можно добиться большей фильтрации и ускорения алгоритма за счет ухудшения сжимаемости.
Разумеется, в капчах от RuCaptcha могут быть и были ошибки распознавания. Для борьбы с ними была введена рейтинговая система капч. Если md5 новой капчи уже содержится в базе, но с другим типом инструкции, то у старой капчи увеличивается счетчик
failure, а если тип старой капчи совпадает с новым, то увеличивается счетчик
popularity. Таким образом вводится естественная регулировка неправильных решений — при поиске похожих учитываются только капчи с
popularity > failure.
Мой первый миллион
За все время исследовательской работы было собрано более миллиона решенных капч. Для хранения данных использовалась база данных PostgreSQL, в которой удобно было хранить хеши и массивы значений гистограмм. К слову о хранении гистограмм — для расчета растояния между двумя гистограммами не обязательно хранить все
255 + window_size значений. При использовании половины или даже трети значений массива точность расстояния падает незначительно, зато экономится дисковое пространство.
По такой выборке капч статистика будет очень точной.
Ниже приведены данные по самым «сжимаемым» и самым популярным капчам (по 3 строчки):
тип инструкций количество капч количество групп сжимаемость (%)
кактус 15274 5508 64
трёхколёсные велосипеды 2453 928 62
байдарки 5261 2067 61
дорожные знаки (не названия улиц!) 201872 189473 6
таблички названий улиц 137893 134695 2
любые уличные знаки 94569 92824 2
Закон Парето в чистом виде: 11% инструкций дают ~80% всех капч (а 20% инструкций дают 91% всех капч). И статистика отнюдь не в пользу самых сжимаемых типов.
Сам же
google говорит так:
reCAPTCHA uses an advanced risk analysis engine and adaptive CAPTCHAs to keep automated software from engaging in abusive activities on your site.
Every time our CAPTCHAs are solved, that human effort helps digitize text, annotate images, and build machine learning datasets. This in turn helps preserve books, improve maps, and solve hard AI problems.
Намекая на то, что, через решение капч людьми он обеспечивает их автоматическую ротацию. Google сделал ставку на небольшой набор инструкций с хорошим уровнем ротации изображений, таких, как дорожные знаки или названия улиц.
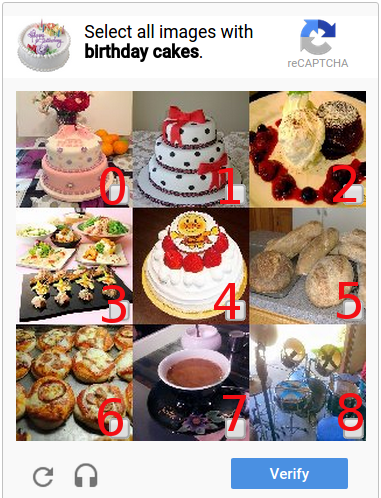
В задачу не входил пункт про проверку на настоящей Google reCaptcha, поэтому в качестве альтернативы я буду использовать следующий алгоритм для всех новых обучающих изображений:
- На вход поступает капча 3x3 или 4x4 и разбивается на 9 или 16 изображений соответственно
- По описанным выше алгоритмам для всех 9 или 16 изображений подбирается похожее по ВСЕМ типам в базе данных
- Индексы изображений найденного решения сравниваются с индексами эталонного решения
- Если разница (количество различающихся индексов) между решениями 50% и больше, то капча считается нерешенной
На примере слева, если данные из базы (автоматическое решение) говорят, что правильные индексы это 0, 1, 3, а эталонное решение это 0, 1, 4, то различающимися индексами будут индексы 3 и 4. В этом примере 2 совпающих и 2 различных индекса, т.е. капча не решена.
Так как в большинстве капч 3x3 правильными являются 3 (+-1) индекса, то такой алгоритм даст схожие результаты, что и на натуральной
reCaptcha.
В пункте 2 решение можно было подбирать по-разному:
- Для каждого изображения делать поиск по ВСЕМ типам изображений в базе и потом отбирать только те, которые соответствуют типу инструкции. Такой подход позволит узнать статистику решений и по нецелевым изображениям тоже, а также проверит влияние ложных срабатываний на верность решений.
- Для каждого изображения производить поиск только по одному типу инструкции. Такой поиск намного быстрее и не дает ложных срабатываний от первого способа впринципе.
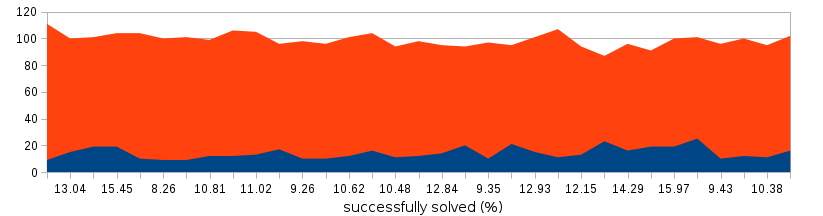
Ниже собрана динамика результатов разгадывания за несколько дней:
В среднем, собранная система разгадывала гугловые капчи с вероятностью 12.5%, тем самым приводя весомый довод в пользу решений компании Google.
К моему удивлению, лидером по количеству решений стала одна из самых плохосжимаемых капч (статистика за несколько выборок):
тип разгадываемость разгадываемость (%) сжимаемость (%)
любые уличные знаки 142 14.03 2
дорожные знаки (не названия улиц!) 80 7.91 6
пальмы 68 6.72 40
пикапы (легковая машина с кузовом) 58 5.73 43
жилой автофургон (дом на колесах) 58 5.73 43
названия улиц 57 5.63 43
А нецелевых капч находилось чуть больше (55%), чем целевых (45%). Целевыми капчами называются те, изображения которых при поиске среди всей БД (а не только по одному типу инструкции) успешно находятся и их тип соответствует типу инструкции капчи. Иными словами — в средней капче 3х3 про лимузины находится 3 изображения с лимузинами и ещё 3.66 изображения с любыми другими типами.
Исследование показало, что на основе перцептивного хеша и гистограмм цветов нельзя построить систему решения капч, даже используя огромные обучающие выборки. Такой результат
reCapthca достигается за счет должной ротации самых популярных типов капч.
Я благодарен RuCaptcha за приятное общение и с их позволения выкладываю обучающую выборку в открытый доступ на yandex диск (спешите скачивать, диск проплачен на месяц):
- yadi.sk/d/CNJQ5uOwqfykL
- yadi.sk/d/gnTU-qwnqfykM
- yadi.sk/d/6vTTjhJaqfykV
Yandex диск не умеет загружать файлы больше 10 гигабайт, поэтому исследователей ждет задача склейки tar архива из 3х частей.
Меня не покидают мысли о машинном обучении на той же самой выборке :) А пока что делюсь
исходным кодом системы на python.