https://habr.com/ru/post/466565/- Python
- Программирование
- Обработка изображений
- Машинное обучение
- Искусственный интеллект
Привет Хабр.
После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.
 Примечание
Примечание: данный пример экспериментальный и учебный, мне было просто интересно посмотреть, что из этого получится. Делать второй FineReader я не планировал и не планирую, так что многие вещи тут, разумеется, не реализованы. Поэтому претензии в стиле «зачем», «уже есть лучше» и пр, не принимаются. Наверно готовые OCR-библиотеки для Python уже есть, но было интересно сделать самому. Кстати, для тех кто хочет посмотреть, как делался настоящий FineReader, есть две статьи в их блоге на Хабре за 2014 год:
1 и
2. Ну а мы приступим.
Для примера мы возьмем простой текст. Вот такой:
HELLO WORLD
И посмотрим что с ним можно сделать.
Разбиение текста на буквы
Первым шагом разобьем текст на отдельные буквы. Для этого пригодится OpenCV, точнее его функция findContours.
Откроем изображение (cv2.imread), переведем его в ч/б (cv2.cvtColor + cv2.threshold), слегка увеличим (cv2.erode) и найдем контуры.
image_file = "text.png"
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
cv2.imshow("Input", img)
cv2.imshow("Enlarged", img_erode)
cv2.imshow("Output", output)
cv2.waitKey(0)
Мы получаем иерархическое дерево контуров (параметр cv2.RETR_TREE). Первым идет общий контур картинки, затем контуры букв, затем внутренние контуры. Нам нужны только контуры букв, поэтому я проверяю что «родительским» является общий контур. Это упрощенный подход, и для реальных сканов это может не сработать, хотя для распознавания скриншотов это некритично.
Результат:
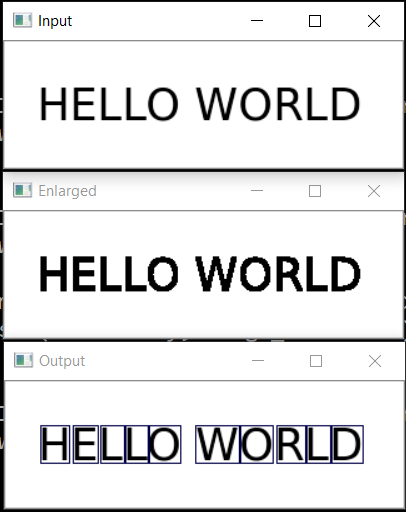
Следующим шагом сохраним каждую букву, предварительно отмасштабировав её до квадрата 28х28 (именно в таком формате хранится база MNIST). OpenCV построен на базе numpy, так что мы можем использовать функции работы с массивами для кропа и масштабирования.
def letters_extract(image_file: str, out_size=28) -> List[Any]:
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
return letters
В конце мы сортируем буквы по Х-координате, также как можно видеть, мы сохраняем результаты в виде tuple (x, w, letter), чтобы из промежутков между буквами потом выделить пробелы.
Убеждаемся что все работает:
cv2.imshow("0", letters[0][2])
cv2.imshow("1", letters[1][2])
cv2.imshow("2", letters[2][2])
cv2.imshow("3", letters[3][2])
cv2.imshow("4", letters[4][2])
cv2.waitKey(0)

Буквы готовы для распознавания, распознавать их мы будем с помощью сверточной сети — этот тип сетей неплохо подходит для таких задач.
Нейронная сеть (CNN) для распознавания
Исходный датасет EMNIST имеет 62 разных символа (A..Z, 0..9 и пр):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
Нейронная сеть соответственно, имеет 62 выхода, на входе она будет получать изображения 28х28, после распознавания «1» будет на соответствующем выходе сети.
Создаем модель сети.
from tensorflow import keras
from keras.models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
def emnist_model():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
Как можно видеть, это классическая сверточная сеть, выделяющая определенные признаки изображения (количество фильтров 32 и 64), к «выходу» которой подсоединена «линейная» сеть MLP, формирующая окончательный результат.
Обучение нейронной сети
Переходим к самому продолжительному этапу — обучению сети. Для этого мы возьмем базу EMNIST, скачать которую можно
по ссылке (размер архива 536Мб).
Для чтения базы воспользуемся библиотекой idx2numpy. Подготовим данные для обучения и валидации.
import idx2numpy
emnist_path = '/home/Documents/TestApps/keras/emnist/'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
Мы подготовили два набора, для обучения и валидации. Сами символы представляют собой обычные массивы, которые несложно вывести на экран:

Также мы используем лишь 1/10 датасета для обучения (параметр k), в противном случае процесс займет не менее 10 часов.
Запускаем обучение сети, в конце процесса сохраняем обученную модель на диск.
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
model.save('emnist_letters.h5')
Сам процесс обучения занимает около получаса:
Это нужно сделать только один раз, дальше мы будем пользоваться уже сохраненным файлом модели. Когда обучение закончено, все готово, можно распознавать текст.
Распознавание
Для распознавания мы загружаем модель и вызываем функцию predict_classes.
model = keras.models.load_model('emnist_letters.h5')
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return chr(emnist_labels[result[0]])
Как оказалось, изображения в датасете изначально были повернуты, так что нам приходится повернуть картинку перед распознаванием.
Окончательная функция, которая на входе получает файл с изображением, а на выходе дает строку, занимает всего 10 строк кода:
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
Здесь мы используем сохраненную ранее ширину символа, чтобы добавлять пробелы, если промежуток между буквами более 1/4 символа.
Пример использования:
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
Результат:

Забавная особенность — нейронная сеть «перепутала» букву «О» и цифру «0», что впрочем, неудивительно т.к. исходный набор EMNIST содержит
рукописные буквы и цифры, которые не совсем похожи на печатные. В идеале, для распознавания экранных текстов нужно подготовить отдельный набор на базе экранных шрифтов, и уже на нем обучать нейросеть.
Заключение
Как можно видеть, не боги горшки обжигают, и то что казалось когда-то «магией», с помощью современных библиотек делается вполне несложно.
Поскольку Python является кроссплатформенным, работать код будет везде, на Windows, Linux и OSX. Вроде Keras портирован и на iOS/Android, так что теоретически, обученную модель можно использовать и на
мобильных устройствах.
Для желающих поэкспериментировать самостоятельно, исходный код под спойлером.
keras_emnist.py# Code source: dmitryelj@gmail.com
import os
# Force CPU
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# Debug messages
# 0 = all messages are logged (default behavior)
# 1 = INFO messages are not printed
# 2 = INFO and WARNING messages are not printed
# 3 = INFO, WARNING, and ERROR messages are not printed
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import cv2
import imghdr
import numpy as np
import pathlib
from tensorflow import keras
from keras.models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
from scipy import io as spio
import idx2numpy # sudo pip3 install idx2numpy
from matplotlib import pyplot as plt
from typing import *
import time
# Dataset:
# https://www.nist.gov/node/1298471/emnist-dataset
# https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
def cnn_print_digit(d):
print(d.shape)
for x in range(28):
s = ""
for y in range(28):
s += "{0:.1f} ".format(d[28*y + x])
print(s)
def cnn_print_digit_2d(d):
print(d.shape)
for y in range(d.shape[0]):
s = ""
for x in range(d.shape[1]):
s += "{0:.1f} ".format(d[x][y])
print(s)
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
def emnist_model():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model2():
model = Sequential()
# In Keras there are two options for padding: same or valid. Same means we pad with the number on the edge and valid means no padding.
model.add(Convolution2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
# model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# model.add(MaxPooling2D((2, 2)))
## model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model3():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0), metrics=['accuracy'])
return model
def emnist_train(model):
t_start = time.time()
emnist_path = 'D:\\Temp\\1\\'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
# Test:
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
# Required for learning_rate_reduction:
keras.backend.get_session().run(tf.global_variables_initializer())
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
print("Training done, dT:", time.time() - t_start)
def emnist_predict(model, image_file):
img = keras.preprocessing.image.load_img(image_file, target_size=(28, 28), color_mode='grayscale')
emnist_predict_img(model, img)
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return chr(emnist_labels[result[0]])
def letters_extract(image_file: str, out_size=28):
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
# cv2.imshow("Input", img)
# # cv2.imshow("Gray", thresh)
# cv2.imshow("Enlarged", img_erode)
# cv2.imshow("Output", output)
# cv2.imshow("0", letters[0][2])
# cv2.imshow("1", letters[1][2])
# cv2.imshow("2", letters[2][2])
# cv2.imshow("3", letters[3][2])
# cv2.imshow("4", letters[4][2])
# cv2.waitKey(0)
return letters
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
if __name__ == "__main__":
# model = emnist_model()
# emnist_train(model)
# model.save('emnist_letters.h5')
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
Как обычно, всем удачных экспериментов.