https://habr.com/ru/post/457252/- Python
- Data Mining
- Big Data
- Искусственный интеллект
Семантическая сегментация — это процесс присвоения каждому пикселю изображения своей метки, что в свою очередь, резко отличается от классификации, где одна метка присваивается всему изображению. Семантическая сегментация рассматривает несколько объектов одного класса как один объект. Случайная сегментация, в свою очередь, обрабатывает несколько объектов одного класса как отдельные объекты. Как правило это более сложный процесс.
 Сравнение семантической и случайной сегментации (источник)
Сравнение семантической и случайной сегментации (источник)
В этой статье будут рассмотрены некоторые методы семантической сегментации, с использованием как классического, так и глубокого обучения.
Классические Методы
До наступления эры глубокого обучения, для сегментирования изображений использовалось большое количество методов обработки изображений. Некоторые из популярных методов перечислены ниже.
Сегментация уровня серого
Простейшая форма семантической сегментации включающая в себя жестко закодированные правила или свойства, которым должен соответствовать пиксель, чтобы ему была присвоена конкретная метка. Правило, такое как интенсивность уровня серого, может быть оформлено в свойствах самого пикселя. Одним из таких методов, который использует эту технику, называется
алгоритм разделения и слияния. Этот алгоритм рекурсивно разбивает изображение на подчасти до тех пор, пока метку нельзя уже будет назначить, а затем объединяет смежные части с одной и той же меткой.
Проблема этого метода в том, что правила должны быть жестко закодированы. Кроме того, чрезвычайно сложно работать со сложными классами, к примеру людьми, которые состоят не только из информации об уровне серого. Следовательно, методы извлечения признаков и оптимизации сложных классов необходимы для правильного изучения представлений.
Марковские случайные поля
Попробуйте сегментировать изображение, обучив модель назначать класс на пиксель. В случае, если наша модель не идеальна, мы можем получить размытые результаты сегментации, которые невозможны по своей природе (например, пиксели собаки, смешанные с пикселями кошки, как показано на рисунке).
 Пиксели с меткой «собака», смешанные с пикселями с меткой «кошка» (изображение С). Более реалистичная сегментация показана на рисунке D .
Пиксели с меткой «собака», смешанные с пикселями с меткой «кошка» (изображение С). Более реалистичная сегментация показана на рисунке D .
Этого можно избежать, рассматривая предыдущее соотношение между пикселями, например тот факт, что объекты являются непрерывными и, как следствие имеют одинаковые метки. Чтобы смоделировать эти отношения, мы используем марковские случайные поля (CRF).
CRF представляют собой класс методов статистического моделирования, которые используются для структурного прогнозирования. В отличие от дискретных классификаторов, перед прогнозом CRF могут учитывать «соседний контекст», такой как взаимосвязь между пикселями. Это делает его идеальным кандидатом для выполнения семантической сегментации. В этом разделе мы и будем использовать CRF для семантической сегментации.
Каждый пиксель в изображении связан с конечным набором возможных состояний. В нашем случае метки назначения представляют собой набор возможных состояний. Цена присвоения состояния (или метки u) одному пикселю (x) называется его одинарной стоимостью. Чтобы смоделировать отношения между пикселями, мы также учитываем стоимость присвоения пары меток (u,v) паре пикселей, (x,y) известную как парная стоимость. Мы можем рассмотреть пары пикселей, которые являются его непосредственными соседями (Grid CRF), или мы можем рассмотреть все пары пикселей в изображении (Dense CRF).

Сумма одинарной и попарной стоимости всех пикселей известна как энергия (или стоимость / потеря) CRF. Это значение может быть минимизировано для получения хорошего результата в сегментации.
Методы глубокого обучения
Глубокое обучение значительно упростило процесс выполнения семантической сегментации и даёт результаты впечатляющего качества. В этом разделе мы обсуждаем популярные модели архитектур и функции потерь, используемые для глубокого обучения.
1. Модельные архитектуры
Одной из самых простых и популярных архитектур, используемых для семантической сегментации, является полностью сверточная сеть (FCN). В
статье FCN для семантической сегментации авторы используют FCN, чтобы уменьшить входное изображение до меньшего размера (получая больше каналов) через серию сверток. Этот набор сверток обычно называют
кодером. Затем кодированный выход подвергается дискретизации с помощью билинейной интерполяции или серии транспонированных сверток. Этот набор транспонированных сверток обычно называется
декодером.
 Downsampling и Upsampling в FCN
Downsampling и Upsampling в FCN
Эта базовая архитектура, которая несмотря на свою эффективность, имеет ряд недостатков. Одним из таких недостатков является наличие артефактов шахматной доски из-за неравномерного перекрытия выходных данных операции транспонирования-свертки.
 Формирование шахматных артефактов
Формирование шахматных артефактов
Другим недостатком является плохое разрешение на границах из-за потери информации в процессе кодирования.
В этой связи было предложено несколько решений для улучшения качества работы базовой модели FCN. Ниже приведены некоторые из популярных решений, которые оказались эффективными:
U-Net
U-Net является обновлением до простой архитектуры FCN. Оно имеет пропускаемые соединения с выхода блоков свертки на соответствующий вход блока транспонированной свертки, на том же уровне.
 U-Net. Источник
U-Net. Источник
Этот пропуск соединений позволяет градиентам «протекать» лучше и предоставляет информацию из нескольких масштабов изображения. Информация более крупных масштабов (верхних уровней) может помочь модели лучше проводить классификацию. Информация из более мелких масштабов (более глубоких слоев) может помочь сегменту модели лучше локализоваться.
Модель тирамису
Модель тирамису похожа на сеть U-Net, за исключением того факта, что она использует блоки свертки и транспонированной сверток, как это реализовано в
DenseNet. Блок состоит из нескольких слоев сверток, где карты характеристик всех предыдущих слоев используются в качестве входных данных для всех последующих слоев. Получающаяся сеть чрезвычайно эффективна по параметрам и может получать доступ к функциям из более старых уровней.
 Сеть Тирамису. Источник
Сеть Тирамису. Источник
Недостатком этого метода является то, что из-за характера операций конкатенации в нескольких средах ML, он не очень эффективно использует память графического процессора.
MultiScale методы
Некоторые модели глубокого обучения имеют методы для использования информации разных масштабов. Например,
сеть разбора фона Pyramid (
PSPNet) выполняет операцию объединения с использованием четырех различного размера ядер и переходит к выходной карте возможностей CNN, такой как ResNet. Затем сеть увеличивает размер всех выходных данных пула и карты выходных объектов CNN с помощью билинейной интерполяции и объединяет их все по оси канала. Окончательная свертка выполняется на этом каскадном выходе для генерации прогноза.
 Сеть разбора фона
Сеть разбора фонаPyramid(
PSPNet)
Atrous (Dilated) Convolutions представляют собой эффективный метод объединения функций нескольких масштабов без значительного увеличения количества параметров. Регулируя степень расширения, у того же фильтра значения его веса распределяются дальше в пространстве. Это позволяет ему изучать более глобальную информацию.
 Cascaded Atrous Convolutions
DeepLabv3
Cascaded Atrous Convolutions
DeepLabv3 бумага использует Atrous сверток с различными скоростями растяжений для сбора информации различных масштабов, без потери в размере изображения. Они экспериментируют с использованием свертка Atrous каскадным образом (как показано выше), а также параллельно в форме объединения пространственных пирамид Atrous (как показано ниже).
 Параллельные Ядовитые Свертки
Параллельные Ядовитые Свертки
Гибридные методы CNN-CRF
Некоторые методы используют CNN в качестве экстрактора признаков, а затем используют эти функции в качестве однотипных затрат (потенциальных) входных данных для плотного CRF. Этот гибридный метод CNN-CRF дает хорошие результаты благодаря способности CRF моделировать межпиксельные отношения.
 Методы с использованием комбинаций CNN и CRF
Методы с использованием комбинаций CNN и CRF
Некоторые методы включают CRF в самой нейронной сети, как представлено в
CRF-as-RNN, где плотный CRF моделируется как рекуррентная нейронная сеть. Это обеспечивает сквозное обучение, как показано на рисунке выше.
2. Функции потерь
Для семантической сегментации, в отличие от обычных классификаторов, должна быть выбрана другая функция потерь. Ниже приведены некоторые из популярных функций потерь, используемых для семантической сегментации:
Пиксельный Softmax с перекрестной энтропией
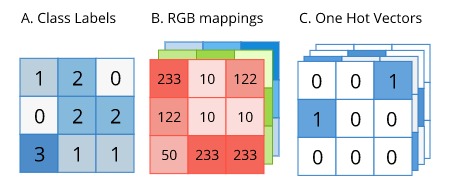
Метки для семантической сегментации имеют тот же размер, что и исходное изображение. Метка может быть представлена в виде кода в горячем виде, как показано ниже:
 One-Hot формат для семантической сегментации
One-Hot формат для семантической сегментации
Поскольку метка находится в удобной «горячей» форме, её можно напрямую использовать как основную истину (или цель) для расчета кросс-энтропии. Однако, softmax необходимо применять по пикселям к прогнозируемому результату перед применением кросс-энтропии, поскольку каждый пиксель может принадлежать к любому из наших целевых классов.
Очаговая потеря
Focal Loss, представленный в статье
RetinaNet, предлагает обновить стандартную кросс-энтропийную потерю для использования в случаях с экстремальным дисбалансом класса.
Рассмотрим график стандартного уравнения кросс-энтропийной потери, как показано ниже (синий цвет). Даже в том случае, когда наша модель довольно уверенно относится к классу пикселя (скажем, 80%), она имеет ощутимое значение потерь (здесь около 0,3). С другой стороны, Focal Loss (Фиолетовый цвет, с gamma=2) не штрафует модель, когда модель уверена в классе (т.е. потеря составляет почти 0 для 80% достоверности).
 Стандартная перекрестная энтропия (синяя) против фокусных потерь с различными значениями гаммы
Стандартная перекрестная энтропия (синяя) против фокусных потерь с различными значениями гаммы
Давайте рассмотрим, почему это важно, на интуитивном примере. Предположим, что у нас есть изображение с 10000 пикселями, только с двумя классами: класс фона (0 в форме с одним всплытием) и класс цели (1 в форме с одним всплытием). Предположим, что 97% изображения — это фон, а 3% — цель. Теперь, скажем, наша модель на 80% уверена в пикселях, которые являются фоновыми, но только на 30% уверена в пикселях, которые являются целевым классом.
При использовании кросс-энтропии потери из-за фоновых пикселей
(97% of 10000) * 0.3 и равны,
2850, а потери из-за целевых пикселей равны
(3% of 10000) * 1.2 и равны
360. Очевидно, что потери из-за более уверенного класса доминируют, и у модели очень низкий стимул изучать целевой класс. Для сравнения, при потере фокуса, потери из-за пикселей фона равны нулю.
(97% of 10000) * 0 Это позволяет модели лучше изучать целевой класс.
Потеря костей
Dice Loss — еще одна популярная функция потерь, используемая для проблем семантической сегментации с экстремальным дисбалансом классов. Представленная в статье V-Net потеря коэффициента Сёренсена используется для расчета перекрытия между прогнозируемым классом и классом истинности основания. Коэффициент Сёренсена (D) представлен следующим образом:
 Коэффициент Сёренсена
Коэффициент Сёренсена
Наша цель — максимизировать совпадение между предсказанным и базовым классом истинности (т.е. максимизировать Коэффициент Сёренсена). Следовательно, мы обычно сводим (1-D) к минимуму, чтобы получить ту же цель, поскольку большинство библиотек ML предоставляют варианты только для минимизации.
 Производный коэффициент Сёренсена
Производный коэффициент Сёренсена
Несмотря на то, что Коэффициент Сёренсена хорошо работает для образцов с дисбалансом классов, формула для вычисления её производной (показанная выше) имеет квадратные члены в знаменателе. Когда эти значения малы, мы можем получить большие градиенты, что приведет к нестабильности обучения.
Использование
Семантическая сегментация используется в различных реальных сферах. Ниже приведены некоторые важные случаи использования семантической сегментации.
Беспилотное вождение
Семантическая сегментация используется для идентификации полос движения, транспортных средств, людей и других объектов, требующих внимания. Полученный результат используется для принятия разумных решений правильного управления транспортным средством.
 Семантическая сегментация для беспилотных транспортных средств
Семантическая сегментация для беспилотных транспортных средств
Одно ограничение для беспилотных транспортных средств состоит в том, что производительность должна проходить в реальном времени. Решением вышеуказанной проблемы является локальная интеграция графического процессора вместе с транспортным средством. Чтобы повысить производительность, можно использовать более легкие (с низкими параметрами) нейронные сети или реализовать методы для подгонки нейронных сетей
на границе.
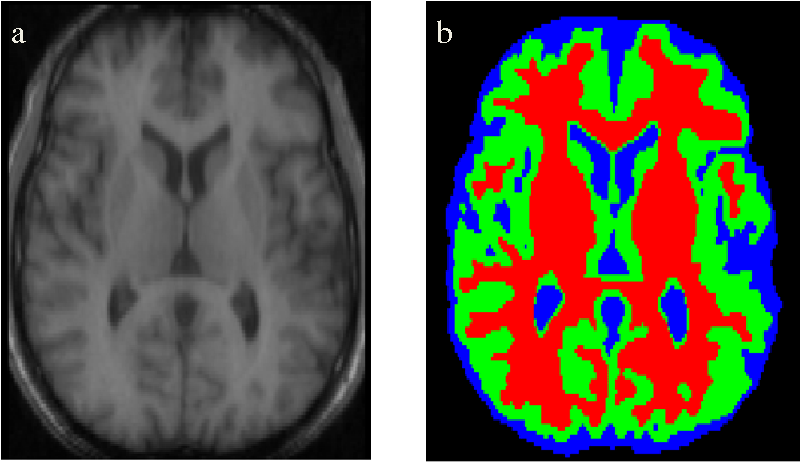
Сегментация медицинских изображений
Семантическая сегментация используется для идентификации элементов при медицинском сканировании. Это особенно полезно для выявления аномалий, таких как опухоли. Точность и низкий уровень возврата алгоритмов имеют большое значение для этих приложений.
 Сегментация медицинских сканов
Сегментация медицинских сканов
Мы также можем автоматизировать менее критичные операции, такие как оценка объема органов с помощью семантически сегментированных сканов 3D изображений.
Понимание фона
Семантическая сегментация обычно формирует основу для более сложных задач, таких как понимание фона и визуальный вопрос и ответ (VQA). Граф фона или заголовок обычно являются результатом алгоритмов понимания
 Понимание фона в действии
Понимание фона в действии
Модная индустрия
Семантическая сегментация используется в индустрии моды для извлечения предметов одежды из образа и предоставления аналогичных предложений от розничных магазинов. Более продвинутые алгоритмы могут «переодевать» отдельные предметы одежды в образе.
 Семантическая сегментация используется в качестве промежуточного шага для исправления образа на основе ввода текста
Семантическая сегментация используется в качестве промежуточного шага для исправления образа на основе ввода текста
Обработка спутникового изображения
Семантическая сегментация используется для определения типов земель по спутниковым снимкам. Типичные случаи использования включают сегментирование водных объектов для предоставления точной картографической информации. Другие передовые варианты использования включают картографирование дорог, определение типов сельскохозяйственных культур, определение свободного места для парковки и так далее.
 Семантическая сегментация спутниковых/аэрофотоснимков
Семантическая сегментация спутниковых/аэрофотоснимков
Заключение
Глубокое обучение значительно улучшило и упростило алгоритмы семантической сегментации и проложило путь для более широкого применения в реальных сферах. Концепции, перечисленные в этой статье, не являются исчерпывающими, поскольку исследовательские сообщества постоянно стремятся повысить точность и производительность этих алгоритмов в режиме реального времени. На ряду с этим, вы познакомились с некоторыми популярными вариантами этих алгоритмов и их реальным применением.
Больше подобных статей можно читать в
телеграм-канале Нейрон (@neurondata)
Всем знаний!
{kind=link}
{kind=link}
{kind=link}
{kind=link}