https://habrahabr.ru/company/rambler-co/blog/332202/- Python
- Big Data
- Блог компании Rambler&Co

Всем привет! Я тимлид проекта Рамблер/топ-100. Это лонгрид о том, как мы проектировали архитектуру обновлённого сервиса веб-аналитики, с какими сложностями столкнулись по пути и как с ними боролись. Если вам интересны такие базворды как
Clickhouse,
Aerospike,
Spark, добро пожаловать под кат.
В прошлом году Рамблеру и Топ-100 исполнилось 20 лет – достаточно большой срок, за который на сервисе было несколько крупных обновлений и последнее из них случилось достаточно давно. Предыдущая версия Рамблер/топ-100 морально устарела, с точки зрения интерфейсов, кода и архитектуры. Планируя перезапуск, мы отдавали себе отчёт в том, что косметическим ремонтом не обойтись – нам надо было выстроить новый сервис практически с нуля.
Поиски решения
Вернёмся ненадолго в прошлое, в начало 2016 года, когда были определены состав перезапуска Рамблер/топ-100 и намечена дата релиза. К перезапуску мы должны были повторить функционал предыдущей версии Топ-100, а также дополнить сервис несколькими новыми отчётами о поведении посетителей, нужных для решения аналитических задач сервисов Rambler&Co.
На тот момент у нас было понимание, как выстроить архитектуру с батч-обсчётами раз в сутки. Архитектура была простая как три копейки: ночью запускается набор Hive-скриптов, читает сырые логи, генерирует по ним предопределенный набор агрегатов за предыдущий день и заливает это все в HBase.
Прекрасно понимая, что статистика на утро следующего дня, это буквально вчерашний день, мы искали и исследовали различные варианты систем, которые позволят обеспечить доступность данных для аналитики с небольшим интервалом (5-10 минут и меньше). Чтобы достичь этого, необходимо было решить целый ряд проблем:
- обсчёт постоянно дополняющихся данных в близком к реальному времени;
- склеивание целевых событий с просмотрами страниц и сессиями;
- обработка запросов с произвольной сегментацией данных;
- все вышеперечисленное нужно делать быстро и держать много одновременных запросов.
Давайте подробнее рассмотрим каждую проблему.
Данные от пользователей приходят постоянно, и они должны быть доступны как можно быстрее. Значит, движок базы данных должен быстро вставлять данные, и они должны быть сразу доступны для запросов. Есть необходимость считать сессии пользователей, которые сильно выходят за временные рамки одного
микро-батча. То есть нам нужен механизм хранения сессий, а сами данные должны заливаться в базу не в конце пользовательской сессии, а по мере поступления событий. При этом база должна уметь группировать эти данные по сессиям и просмотрам страниц. Важно также, чтобы движок базы данных обеспечивал возможность склейки и изменения сущностей после записи (например, в рамках сессии произошло целевое событие, пользователь кликнул на какой-то блок).
Бывают ситуации, в которых необходимо быстро делать агрегирующие запросы с заданной пользователем сегментацией. Например, пользователь аналитики хочет узнать, сколько людей заходят с IE6 из Удмуртии, мы должны это посчитать и показать. Это значит, что база должна позволять хранение достаточно слабоагрегированных или вовсе не агрегированных сущностей, а отчёты по ним должны строиться на лету. Учитывая общий объём данных, необходим механизм сэмплирования (построения выборки и обсчёта данных из этой выборки вместо обсчёта по всей совокупности).
При этом нельзя забывать о росте объёма данных в будущем: архитектура должна держать нашу нагрузку на старте и горизонтально масштабироваться. Нагрузка на момент проектирования архитектуры – 1.5-2TB сырых логов и 700 млн — 1 млрд событий в день. Дополнительно очень важно, чтобы база хорошо сжимала данные.
Просмотрев кучу статей, документации, поговорив с ушлыми продажниками и пересмотрев пару десятков докладов с разных BigData конференций, мы пришли к не слишком радостному выводу. На тот момент на рынке были три удовлетворяющие нашим требованиям системы: Druid, HP Vertica и Kudu + Impala.
Druid был opensource’ный и по отзывам достаточно шустрый, но очень сырой. Vertica подходила по всем параметрам и была гораздо круче друида в плане функционала, но стоимость базы на наших объемах данных была неподъемная. Про Kudu + Impala нашли очень мало информации, использовать в продакшене проект с таким кол-вом документации страшновато.
Ещё один ограничивающий фактор – время. Мы не могли позволить себе несколько лет разрабатывать новую систему: нас бы не дождались существующие пользователи Топ-100. Действовать надо было быстро.
Приняв во внимание все вводные, приняли решение делать перезапуск сервиса в два этапа. Сначала реализуем функционал старых отчетов на батч-архитектуре, стараемся по максимуму избежать деградации функционала и добавляем несколько критичных для внутренних заказчиков новых возможностей. Параллельно активно ищем решения, которые позволят обсчитывать данные и показывать их в интерфейсе в близком к реальному времени.
Новая архитектура или «вот это поворот!»
Время шло, дата перезапуска приближалась, Druid и Kudu медленно обзаводились документацией, Vertica не собиралась дешеветь. Мы практически решились делать монстра из комбинации Druid'а и батч-обсчета, когда ВНЕЗАПНО Яндекс выложил в opensource Сlickhouse.
Естественно, мы обратили внимание на новую возможность – на первый взгляд она идеально решала нашу задачу. Внимательно изучив документацию, поговорив со знакомыми из Яндекса и проведя нагрузочные тесты, мы пришли к выводу, что будем рассматривать Clickhouse в качестве основного варианта для второго этапа обновления Топ-100.
В итоге у нас получилась следующая архитектура:
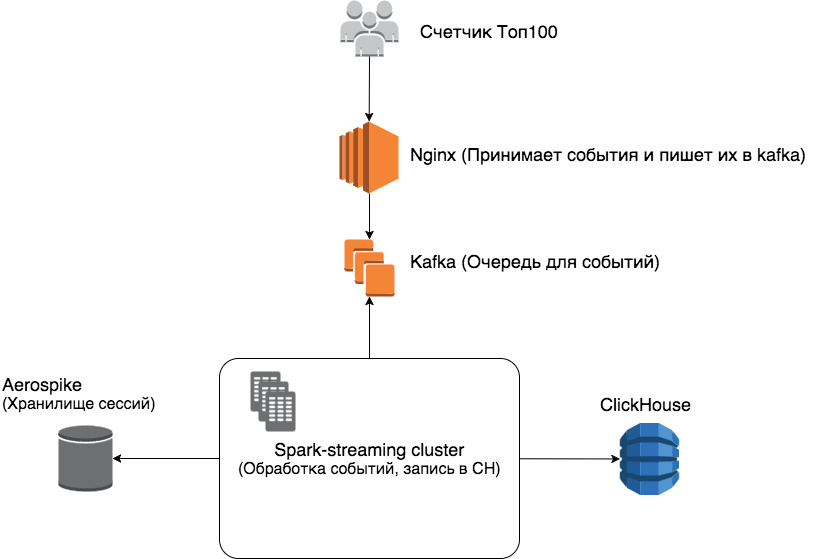
По порядку.
Nginx – принимает события от посетителей веб-страниц, передаваемые счётчиком, записывает их в очередь событий.
Kafka – очень быстрая очередь событий, с репликацией, умеющая работать сразу с несколькими клиентами.
Spark-streaming – выполняет обработку потоковых данных, python-реализация.
Aerospike - выступает качестве хранилища сессий выбрали именно Aerospike потому, что данных достаточно много (в среднем отметка держится на 250-300гб хранимых сессий), а у Aerospike достаточно хорошее соотношение стоимости железа к объему хранимых данных.
Почему именно Aerospike, ведь у Spark есть checkpoint (встроенный вариант хранения состояний объектов)? Дело в том, что документация по checkpoint’ам в Spark достаточно сырая и неинформативная. Например, не до конца понятно, как следить за истечением времени жизни сессий, а также количеством используемой памяти и диска для хранения чекпойнтов. Aerospike же из коробки умеет автоматически удалять истекшие сессии, его относительно легко мониторить и масштабировать.
ClickHouse – колоночная база данных и механизм построения отчетов в одном флаконе.
Немного подробнее о связке Spark + Aerospike + Clickhouse, чтобы не получилось, как на старой картинке.

События от посетителей читаются Spark’ом из Kafka, микро-батч включает 5 минут данных. Данные группируются по проектам и уникальным посетителям (кукам) внутри проектов. Для каждого посетителя проверяется, есть ли активная сессия в рамках данного проекта и, если есть, из этой сессии берутся данные для склейки с новыми данными. Сессии и данные сессий хранятся в Aerospike с некоторым временем жизни. После склейки сессий нам нужно сохранить их в Clickhouse. В этом нам идеально подходит движок
CollapsingMergeTree: когда к нам приходят новые данные, мы делаем в Clickhouse две записи – старую, если она есть, со знаком (-) и новую со знаком (+).
С посетителями разобрались, теперь подробнее про сессии. Для первого встреченного события от посетителя мы генерируем session_id, сохраняем этот id и время последнего события в Aerospike. Всем дальнейшим событиям в рамках этой сессии присваивается этот id. Если промежуток времени между последним событием сессии из Aerospike и новым событием больше 30 минут, считаем это событие началом новой сессии, и всё начинается заново.
Такая архитектура решает все проблемы, описанные в начале статьи, достаточно легко масштабируется и тестируется.
Для проверки, что эта архитектура будет работать в реальности, держать нашу предполагаемую нагрузку и отвечать достаточно быстро, мы провели три теста:
- нагрузочное тестирование Clickhouse с сэмплом данных и предолагаемой схемой таблиц;
- нагрузочное тестирование связки Kafka-Aerospike-ClickHouse;
- проверили работающий прототип связки под продакшн нагрузкой.
Все тесты закончились успешно, мы обрадовались и приступили к реализации.
Преодолевая трудности
В ходе реализации придуманной схемы мы, естественно, встретили некоторое количество граблей.
Spark
Иногда не слишком информативные логи, приходится копаться в исходниках и трейсбэках Spark на Scala. Нет восстановления с offset’ов в Kafka из коробки, пришлось писать свой велосипед. К тому же мы не нашли нормальный механизм graceful shutdown’а реалтайм обсчета, тоже пришлось писать свой велосипед (немного
информации об этой проблеме).
Aerospike
Пока не было проблем, разве что для тестового неймспейса нужен отдельный раздел на жестком диске.
Clickhouse
Почти нет автоматизации DDL для кластера (например, чтобы сделать alter table на distributed таблице нужно зайти на все ноды и сделать на каждой ноде alter table). Много недокументированных функций — нужно лезть в код и разбираться или спрашивать напрямую у разработчиков CH. Слабо автомазизирована работа с репликами и шардами, партиционирование только по месяцам.
It's alive, ALIVE!
Что получилось в результате. Схема базы.
CREATE TABLE IF NOT EXISTS page_views_shard(
project_id Uint32,
page_view_id String,
session_id String,
user_id String,
ts_start Float64,
ts_end Float64,
ua String,
page_url String,
referer String,
first_page_url String,
first_page_referrer String,
referer String,
dt Date,
sign Int8
) ENGINE=CollapsingMergeTree(
dt,
sipHash64(user_id),
(project_id, dt, sipHash64(user_id), sipHash64(session_id), page_view_id),
8192,
sign
);
Строкой в схеме базы данных является просмотр страницы со всеми ассоциированными с ним параметрами. (Схема намеренно упрощена, нет большого количества дополнительных параметров).
Разберем по порядку:
• dt – дата, обязательное требование для MergeTree таблиц;
• sipHash64(user_id) – для поддержки сэмплирования;
• (project_id, dt, sipHash64(user_id), sipHash64(session_id), page_view_id) – первичный ключ, по которому отсортированы данные и по которому производится схлопывание значений с разным sign;
• 8192 – гранулярность индекса;
• sign – описывал выше.
Примеры запросов для одного из проектов:
Количество просмотров страниц и сессий за месяц с группировкой по датам.
SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, dt
FROM page_views
WHERE project_id = 1
GROUP BY dt
ORDER BY dt
WHERE dt >= '2017-02-01' AND dt <= '2017-02-28'
FORMAT JSON;
2-5 секунд на полных данных (127кк строк)
0.5 секунды на сэмпле 0.1
0.1 секунды на сэмпле 0.01

Посчитать все page_views, visits с группировкой по части урл.
SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, URLHierarchy(page)[1]
FROM page_views
GROUP BY URLHierarchy(page)[1]
ORDER BY page_views DESC
WHERE dt >= '2017-02-01' AND dt <= '2017-02-28' and project_id = 1
LIMIT 50
FORMAT JSON;
10 секунд на полных данных
3-5 секунд на сэмпле 0.1
1.5 секунд на сэмпле 0.01
 Kafka
Kafka
Даже не напрягается.
Spark
Работает достаточно быстро, на пиковых нагрузках отстает, потом постепенно догоняет очередь.
ClickHouse, Сжатие данных
1.5-2ТБ данных сжимаются до 110-150 ГБ.
ClickHouse, Нагрузка на запись
1-4 RPS батчами по 10000 записей.
ClickHouse, Нагрузка на чтение
В данный момент сильно зависит от запрашиваемых проектов и типа отчета, от 5 до 30 RPS.
Эту проблему должно решить сэмплирование в зависимости от размера проекта и квоты.
Результаты и впечатления
M-m-m-magic. Мы выкатили в продакшен первый отчет, работающий с ClickHouse –
«Сегодня детально». Пожелания и конструктивная критика приветствуются.
To be continued. Буду рад, если напишете в комментах, о чем было бы интересно почитать в будущем: тонкости эксплуатации, бенчмарки, типовые проблемы и способы их решения, ваш вариант.