https://habrahabr.ru/company/plarium/blog/345310/- Машинное обучение
- Python
- Data Mining
- Big Data
- Блог компании Plarium

Проблема предсказания оттока клиентов — одна из самых распространенных в практике Data Science (так теперь называется применение статистики и машинного обучения к бизнес-задачам, уже все знают?). Проблема достаточно универсальна: она актуальна для многих отраслей — телеком, банки, игры, стриминг-сервисы, ритейл и пр. Необходимость ее решения довольно легко обосновать с экономической точки зрения: есть куча статей в бизнес-журналах о том, что привлечь нового клиента в N раз дороже, чем удержать старого. И ее базовая постановка проста для понимания так, что на ее примере часто объясняют основы машинного обучения.
Для нас в Plarium-South, как и для любой игровой компании, эта проблема также актуальна. Мы прошли длинный путь через разные постановки и модели и пришли к достаточно оригинальному, на наш взгляд, решению. Все ли так просто, как кажется, как правильно определить отток и зачем тут нейросеть, расскажем под катом.
Отток? Не, не слышал...
Начнем, как полагается, с определений. Есть база клиентов, которые пользуются какими-то услугами, покупают какие-то товары, в нашем случае — играют в игры. В какой-то момент отдельные клиенты перестают пользоваться сервисом, уходят. Это и есть отток. Предполагается, что в тот момент, когда клиент подает первые признаки ухода, его еще можно переубедить: обнять, рассказать, как он важен, предложить скидку, сделать подарок. Таким образом, первоочередная задача состоит в том, чтобы правильно и своевременно предсказать, что клиент собирается уйти.
Может показаться, что возможных значений целевой переменной тут два: пациент либо жив, либо мертв. И действительно, ищем соревнования по предсказанию оттока (
крэкс,
пэкс,
фэкс) и везде видим задачу бинарной классификации: объекты — пользователи, целевая переменная — бинарная. Здесь ярко видно отличие спортивного анализа данных от практического. В практическом анализе перед тем как решать задачу, приходится ее еще и ставить, да так, чтобы из ее решения можно было извлечь прибыль. Чем и займемся.
Отток оттоку рознь
При более близком рассмотрении мы узнаем, что можно выделить два типа оттока — договорный (contractual) и недоговорный (non-contractual). В первом случае клиент явным образом говорит, что он устал и он уходит. Зачастую это сопровождается формальными действиями по прекращению контракта и т. п. В этом случае, действительно, можно четко определить, когда человек является твоим клиентом, когда нет. В недоговорном случае клиент ничего не говорит, никак не уведомляет и просто перестает пользоваться вашим сервисом, услугой, играть в вашу игру и покупать ваши товары. И, как вы уже догадались, второй случай гораздо более распространен.
То есть вы имеете в CRM / базе данных некую активность пользователей (покупки, заходы на сайт, звонки в сотовой сети), которая в какой-то момент уменьшается. Заметьте, не обязательно прекращается, но существенно изменяет интенсивность.
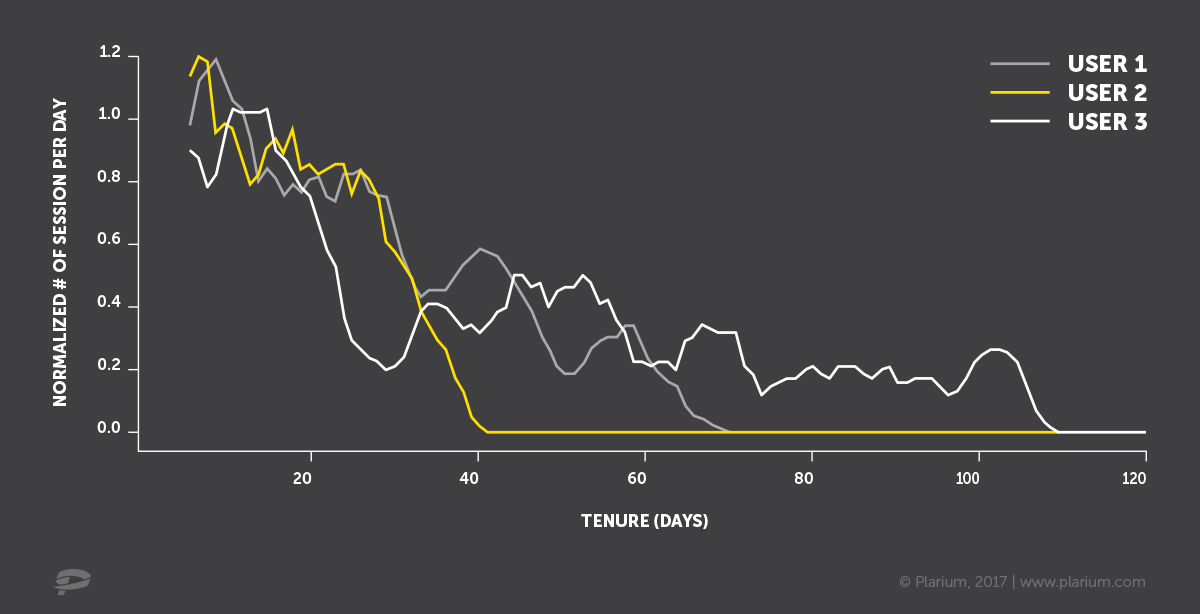
Всех под одну гребенку
Изобразим дни визитов трех гипотетических клиентов синими крестиками на оси времени. Первая мысль — зафиксировать некий период (тут он называется Target definition). Определенную активность в течение этого периода будем считать проявлением жизни, а отсутствие таковой — уходом. Тогда в качестве входных данных для модели предсказания оттока можно взять данные за период до рассматриваемого (Input data).

Можно также предусмотрительно оставить между двумя этими периодами некий буфер, например 1–2 недели, с целью научиться предсказывать отток заранее, чтобы успеть совершить некие действия по
вразумлению удержанию клиента.
Что плохого в таком подходе? Непонятно, как правильно задать параметры. Какой период взять для определения целевой переменной. Для одного клиента трехдневное отсутствие — это безусловный уход, для другого — стандартное поведение. Вы скажете: “Давайте возьмем большой промежуток — месяц, год, два, тогда точно все попадут”. Тут может возникнуть проблема с историческими данными, т. к. не у всех они хранятся так долго. Кроме того, если мы будем строить модель на данных годичной давности, она может не подходить для текущей ситуации. И, к тому же, чтобы проверить результат работы нашей модели на актуальных данных, придется ждать год. Можно ли не уходить глубоко в историю, а еще лучше вообще обойтись без уравниловки?
Вероятность 50/50 — либо ушел, либо нет
Если мы знаем историю заходов пользователя: как он в среднем себя вел до этого и как давно отсутствует сейчас, — нельзя ли подобрать правильные статистические распределения и посчитать вероятность того, что пользователь жив в данный момент? Можно, и уже было сделано в модели
Pareto/NBD еще в 1987 году, где время до ухода описывалось распределением Парето (смесь экспонент с гамма-весами), а распределение визитов/покупок — отрицательным биномиальным. В 2003 возникла идея вместо распределения Парето использовать бета-геометрическое и появилась модель
BG/NBD, которая работает быстрее и зачастую без потери качества. Обе модели достойны внимания, и есть хорошие реализации обеих на
Python и
R. На вход эти модели принимают только три значения по каждому пользователю: количество визитов/покупок, возраст клиента (время, прошедшее с первой покупки до текущего момента) и время, прошедшее с последней покупки. При таком бедном наборе входных данных модели работают очень достойно, что говорит о том, что рановато пока забывать теорвер, его вполне еще можно применять — в промежутках между тем, как "
стакать xgboost-ы".
При этом потенциал для улучшений еще есть. Например, есть сезонность, промоакции, влияющие на статистику заходов, — их эти модели не учитывают. Есть другие данные об активности пользователя, которые могут говорить о близости ухода. Так, в конец разочаровавшийся в игре пользователь может попусту растратить ресурсы (не пропадать же добру), распустить войско. Данные о таком поведении могут помочь отличить реальный уход от временного отсутствия (отпуск в джунглях без интернета). Все эти данные нельзя “скормить” вероятностным моделям, описанным выше (хотя есть уважаемые люди, которые
пытаются это сделать).
Вызываю нейросеть
А что если взять и построить нейросеть, на выходе которой будут параметры распределений? Про это есть
магистерская диссертация выпускника Гетеборгского университета и написанный в рамках нее и прекрасно проиллюстрированный пакет на Python —
WTTE-RNN.
Автор решил предсказывать время до следующего захода (time to event) с помощью распределения Вейбулла и всей мощи рекуррентных нейросетей. Кроме теоретической красоты подхода здесь есть еще и важный практический момент: при использовании рекуррентных нейросетей не нужно городить огород с построением признаков из временных рядов (агрегировать набор рядов набором функций по набору периодов и набору лагов), чтобы представить данные в виде плоской таблицы (объекты — признаки). Можно подать временные ряды на вход сети как есть. Подробнее об этом мы недавно рассказывали в ходе
доклада на PiterPy. Это серьезно экономит вычислительные и временные ресурсы. Кроме рядов одного типа (например, по дням), можно также подать на вход и ряды другого типа или длины (например, почасовые за последний день), и статические характеристики пользователей (пол, страна), хоть картинку с его портретом (вдруг лысые уходят чаще?), нейросети и
такое умеют.
Однако оказалось, что построенная по Вейбуллу функция потерь при обучении часто уходит в NaN. Кроме того, временем до следующего захода не так просто оперировать. Знание его не избавляет от необходимости отвечать на вопросы, какое время до захода считать слишком большим, как рассчитать пороги для каждого пользователя в отдельности и учитывая всяческую сезонность, как отсеять временные перерывы в активности и т. д.
Что же делать?
Не претендуя на однозначную правильность принятого решения, расскажем, какой путь в итоге выбрали мы в Plarium-South. Мы вернулись к бинарному таргету, рассчитали его хитрым образом, а в качестве модели взяли RNN.
Почему к бинарному?- Потому что в конечном итоге бизнесу нужен именно он: нужно знать, когда предпринимать активность по удержанию, а когда нет.
- Потому что метрики бинарной классификации (precision, recall, accuracy) проще использовать для объяснения результатов.
- Зная стоимость удержания и потенциальную прибыль с возвращенного клиента, можно выбрать порог отсечки с точки зрения максимизации суммарной прибыли от кампании по удержанию.
Как рассчитываем таргет?- Строим нормализованный показатель активности пользователя с учетом его средней активности, вырезаем специфические для игровой индустрии начальные периоды неактивности (когда зашел по рекламе, потыкал немного, а начал активно играть спустя несколько недель) и т. д.
- Выбираем порог бинаризации и параметры нормализации, максимизируя совпадение с долгосрочным оттоком, — то есть чтобы результат бинаризации в наибольшей степени соответствовал отсутствию активности, например в следующий год.
- Разносим по времени периоды для тренировки и для расчета таргета, чтобы заглядывать немного в будущее.
- Так мы получаем бинарный таргет, но избавленный от озвученных ранее недостатков (нет фиксированного и единого для всех периода, учитываются разные типы игры и другие специфические особенности).
 Почему RNN?
Почему RNN? - Потому что проще работать с признаками на основе временных рядов.
- Потому что точность получается очень хорошая (ROC-AUC около 0.97).
Если пост вызовет интерес, в следующей серии расскажем подробнее о модели, об ее архитектуре, о подготовке данных и о технологиях, которые используем.
One more thing
И кстати, кому интересно делать подобные вещи, мы ищем специалистов на позиции
Data Scientist и
Data Engineer в краснодарский офис. У нас, помимо оттока, есть и другие интересные задачи (антифрод, рекомендалки, социальный граф), много данных, ресурсов на все хватает. И жить в Краснодаре тепло и приятно. :) Резюме присылайте на
hr.team@plarium.com.