Предсказываем будущее с помощью библиотеки Facebook Prophet
- суббота, 25 марта 2017 г. в 03:13:32
 Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Существует большое количество различных подходов для прогнозирования временных рядов, такие как ARIMA, ARCH, регрессионные модели, нейронные сети и т.д.
Сегодня же мы познакомимся с библиотекой для прогнозирования временных рядов Facebook Prophet (в переводе с английского, "пророк", выпущена в open-source 23-го февраля 2017 года), а также попробуем в жизненной задаче – прогнозировании числа постов на Хабрехабре.
Согласно статье Facebook Prophet, был разработан для прогнозирования большого числа различных бизнес-показателей и строит достаточно хорошие default'ные прогнозы. Кроме того, библиотека дает возможность, изменяя человеко-понятные параметры, улучшать прогноз и не требует от аналитиков глубоких знаний устройства предсказательных моделей.
Давайте немного обсудим, как же работает библиотека Prophet. По сути, это additive regression model, состоящая из следующих компонент:
dummy variables. Добавляются 6 дополнительных признаков, например, [monday, tuesday, wednesday, thursday, friday, saturday], которые принимают значения 0 и 1 в зависимости от даты. Признак sunday, соответствующий седьмому дню недели, не добавляют, потому что он будут линейно зависеть от других дней недели и это будет влиять на модель.Подробнее про алгоритмы можно прочитать в публикации Sean J. Taylor, Benjamin Letham "Forecasting at scale".
В этой же публикации представлено и сравнение mean absolute percentage error для различных методов автоматического прогнозирования временных рядов, согласно которому Prophet имеет существенно более низкую ошибку.

Давайте сначала разберемся, как оценивается качество моделей в статье, а затем перейдем к алгоритмам, с которыми сравнивали Prophet.
MAPE (mean absolute percentage error) — это средняя абсолютная ошибка нашего прогноза. Пусть — это показатель, а — это соответствущий этой величине прогноз нашей модели. Тогда — это ошибка прогноза, a — это относительная ошибка прогноза.
MAPE часто используется для оценки качества, поскольку эта величина относительная и по ней можно сравнивать качество даже на различных наборах данных.
Кроме того, бывает полезно смотреть и на абсолютную ошибку MAE - mean absolute error, чтобы понимать, на сколько ошибается модель в абсолютных величинах.
Cтоит сказать пару слов о тех алгоритмах, с которыми сравнивали Prophet в публикации, тем более, большинство из них очень простые и их часто используют как baseline:
naive — наивный прогноз, когда мы прогнозируем все последующие значения последней точкой;snaive - seasonal naive — такой прогноз подходит для данных с явно выраженной сезонностью. Например, если мы говорим о показатели с недельной сезонностью, то для каждого последующего понедельника мы будем брать значение за последний понедельник, для вторника — за последний вторник и так далее;mean — в качестве прогноза берется среднее значение показателя;arima - autoregressive integrated moving average — подробности на wiki;ets - exponential smoothing — подробности на wiki.Для начала необходимо установить библиотеку. Библиотека Prophet доступна для python и R. Я предпочитаю python, поэтому использовала именно его. Для python библиотека ставится с помощью PyPi следующим образом:
pip install fbprophetПод R у библиотеки есть CRAN package. Подробные инструкции по установке можно найти в документации.
В качестве показателя для предсказания я выбрала количество постов, опубликованных на Хабрахабре. Данные я взяла из учебного конкурса на Kaggle "Прогноз популярности статьи на Хабре". Тут рассказано подробнее о соревновании и курсе машинного обучения, в рамках которого оно проводится.
import pandas as pd
habr_df = pd.read_csv('howpop_train.csv')
habr_df['published'] = pd.to_datetime(habr_df.published)
habr_df = habr_df[['published', 'url']]
aggr_habr_df = habr_df.groupby('published')[['url']].count()
aggr_habr_df.columns = ['posts']
aggr_habr_df = aggr_habr_df.resample('D').apply(sum)Для начала посмотрим на данные и построим time series plot за весь период. На таком длинном периоде удобнее смотреть на недельные точки.
Для визуализации я как обычно буду использовать библиотеку plot.ly, которая позволяет строить в python интерактивные графики. Подробнее про нее и визуализацию в целом можно почитать в статье Открытый курс машинного обучения. Тема 2: Визуализация данных c Python.
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
from plotly import graph_objs as go
# инициализируем plotly
init_notebook_mode(connected = True)
# опишем функцию, которая будет визуализировать все колонки dataframe в виде line plot
def plotly_df(df, title = ''):
data = []
for column in df.columns:
trace = go.Scatter(
x = df.index,
y = df[column],
mode = 'lines',
name = column
)
data.append(trace)
layout = dict(title = title)
fig = dict(data = data, layout = layout)
iplot(fig, show_link=False)
plotly_df(aggr_habr_df.resample('W').apply(sum), title = 'Опубликованные посты на Хабрахабре')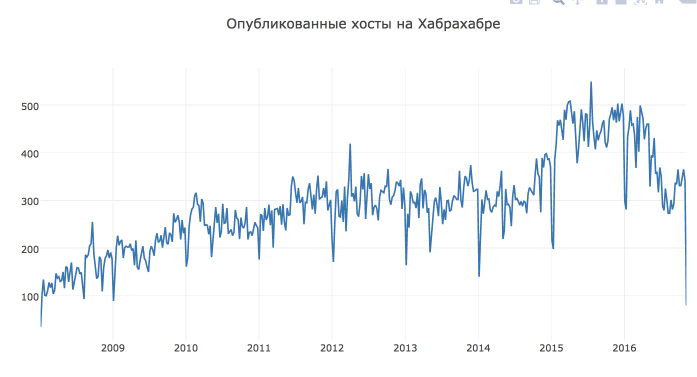
Библиотека Prophet имеет интерфейс похожий на sklearn, сначала мы создаем модель, затем вызываем у нее метод fit и затем получаем прогноз. На вход методу fit библиотека принимает dataframe с двумя колонками:
ds — время, поле должно быть типа date или datetime,y — числовой показатель, который мы хотим предсказывать.Для того чтобы измерить качество полученного прогноза, уберем из обучения последний месяц данных и будем предсказывать его. Создатели советуют делать предсказания по нескольким месяцам данных, в идеале – год и более (в нашем случае есть несколько лет истории для обучения).
#импортируем библиотеку
from fbprophet import Prophet
predictions = 30
# приводим dataframe к нужному формату
df = aggr_habr_df.reset_index()
df.columns = ['ds', 'y']
# отрезаем из обучающей выборки последние 30 точек, чтобы измерить на них качество
train_df = df[:-predictions] Далее создаем объект класса Prophet (все параметры модели задаются в конструкторе класса, для начала возьмем default'ные параметры) и обучаем его.
m = Prophet()
m.fit(train_df)С помощью вспомогательной функции Prophet.make_future_dataframe создаем dataframe, который содержит все исторические временные точки и еще 30 дней, для которых мы хотели построить прогноз.
Для того, чтобы построить прогноз вызываем у модели функцию predict и передаем в нее полученный на предыдущем шаге dataframe future.
future = m.make_future_dataframe(periods=predictions)
forecast = m.predict(future)В библиотеке Prophet есть встроенные средства визуализации, которые позволяют оценить результат построенной модели.
Во-первых, метод Prophet.plot отображает прогноз. Честно говоря, в данном случае такая визуализация не очень показательна. Основной вывод из этого графика, который я сделала — в данных много outlier'ов. Однако если при прогнозировании будет меньше исторических точек, то по ней можно будет что-нибудь понять.
m.plot(forecast)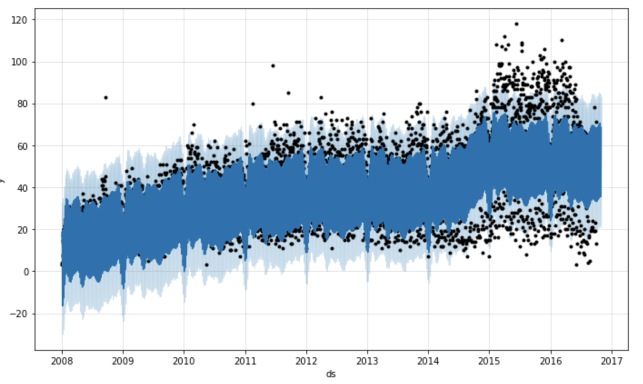
Вторая функция Prophet.plot_components, на мой взгляд, гораздо более полезная. Она позволяет посмотреть отдельно на компоненты: тренд, годовую и недельную сезонность. Если при построении модели были заданы аномальные дни/праздники, то они также будут отображаться на этом графике.
m.plot_components(forecast)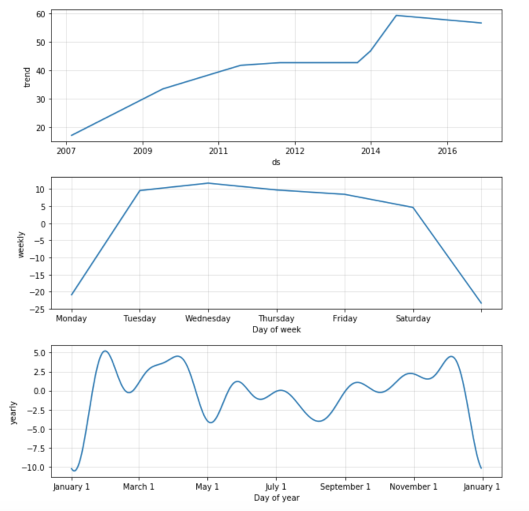
На графике видно, что Prophet хорошо хорошо подстроился под рост числа постов "ступенькой" в начале 2015-го. По недельной сезонности можно сделать вывод, что меньше постов приходится на воскресенье и понедельник. На графике годовой сезонности ярче всего выделяется провал активности в Новогодние каникулы, также виден спад и на майских праздниках.
Давайте оценим качество алгоритма и посчитаем MAPE для последних 30 дней, которые мы предсказывали. Для расчета нам нужны наблюдения и прогнозы для них .
Для начала посмотрим на объект forecast, который генерирует библиотека. На самом деле это dataframe, в котором есть вся необходимая нам информация для прогноза.
print(', '.join(forecast.columns))ds, t, trend, seasonal_lower, seasonal_upper, trend_lower, trend_upper, yhat_lower, yhat_upper, weekly, weekly_lower, weekly_upper, yearly, yearly_lower, yearly_upper, seasonal, yhatПрежде чем продолжить, нам нужно объединить forecast с нашими исходными наблюдениями.
cmp_df = forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(df.set_index('ds'))Напомню, что мы изначально отложили данные за последний месяц, чтобы построить прогноз на 30 дней и измерить качество получившейся модели.
import numpy as np
cmp_df['e'] = cmp_df['y'] - cmp_df['yhat']
cmp_df['p'] = 100*cmp_df['e']/cmp_df['y']
print 'MAPE', np.mean(abs(cmp_df[-predictions:]['p']))
print 'MAE', np.mean(abs(cmp_df[-predictions:]['e']))В результате мы получили качество около 37.35%, а в среднем в прогнозе модель ошибается на 10.62 поста.
Давайте сделаем свою визуализацию построенной Prophet модели: с фактическими значениями, прогнозом и доверительными интервалами.
Во-первых, я хочу оставить данные за меньший период, чтобы они не превращались в месиво точек. Во-вторых, хочется показывать результаты модели только за тот период, на котором мы делали предсказание — мне кажется, так график будет более читаемым. В-третьих, сделаем график интерактивным с помощью plot.ly.
# функция для визуализации построенного прогноза
def show_forecast(cmp_df, num_predictions, num_values):
# верхняя граница доверительного интервала прогноза
upper_bound = go.Scatter(
name='Upper Bound',
x=cmp_df.tail(num_predictions).index,
y=cmp_df.tail(num_predictions).yhat_upper,
mode='lines',
marker=dict(color="444"),
line=dict(width=0),
fillcolor='rgba(68, 68, 68, 0.3)',
fill='tonexty')
# прогноз
forecast = go.Scatter(
name='Prediction',
x=cmp_df.tail(predictions).index,
y=cmp_df.tail(predictions).yhat,
mode='lines',
line=dict(color='rgb(31, 119, 180)'),
)
# нижняя граница доверительного интервала
lower_bound = go.Scatter(
name='Lower Bound',
x=cmp_df.tail(num_predictions).index,
y=cmp_df.tail(num_predictions).yhat_lower,
marker=dict(color="444"),
line=dict(width=0),
mode='lines')
# фактические значения
fact = go.Scatter(
name='Fact',
x=cmp_df.tail(num_values).index,
y=cmp_df.tail(num_values).y,
marker=dict(color="red"),
mode='lines',
)
# последовательность рядов в данном случае важна из-за применения заливки
data = [lower_bound, upper_bound, forecast, fact]
layout = go.Layout(
yaxis=dict(title='Посты'),
title='Опубликованные посты на Хабрахабре',
showlegend = False)
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
show_forecast(cmp_df, predictions, 200)Как видно, описанная выше функция позволяет гибко настраивать визуализацию и отобразить произвольное число наблюдений и прогнозов модели.
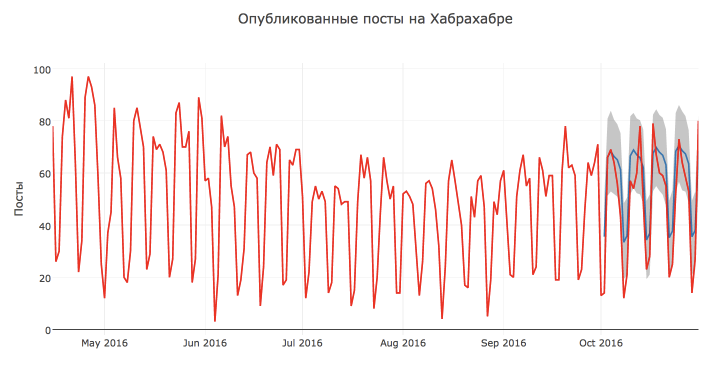
Визуально прогноз модели, кажется достаточно хорошим и разумным. Скорее всего такая низкая оценка качества объясняется аномальным высоким количеством постов 13 и 17 октября и снижением активности с 7 октября.
Также по графику можно сделать вывод, что большинство точек лежат внутри доверительного интервала.
На глаз прогноз получился вполне разумным, но давайте сравним его с классической моделью SARIMA - Seasonal autoregressive integrated moving average с недельным периодом.
На Хабрахабре уже есть несколько статей про ARIMA-модели, всем интересующимся советую почитать их: Построение модели SARIMA с помощью Python+R и Анализ временных рядов с помощью python.
Для построения прогноза я также вдохновлялась учебными материалами курса Прикладные задачи анализа данных на Сoursera, в котором подробно описаны ARIMA-модели и как их строить на python.
Стоит отметить, что построение ARIMA модели требует гораздо больших затрат по сравнению с Prophet: нужно исследовать исходный ряд, привести его к стационарному, подобрать начальные приближения и потратить немало времени на подбор гипер-параметров алгоритма (на моем компьютере модель подбиралась почти 2 часа).
Но в данном случае усилия были не напрасны и предсказание SARIMA получилось более точным: MAPE=16.54%, MAE=7.28 поста. Лучшая модель с параметрами: D=1, d=1, Q=1, q=4, P=1, p=3.
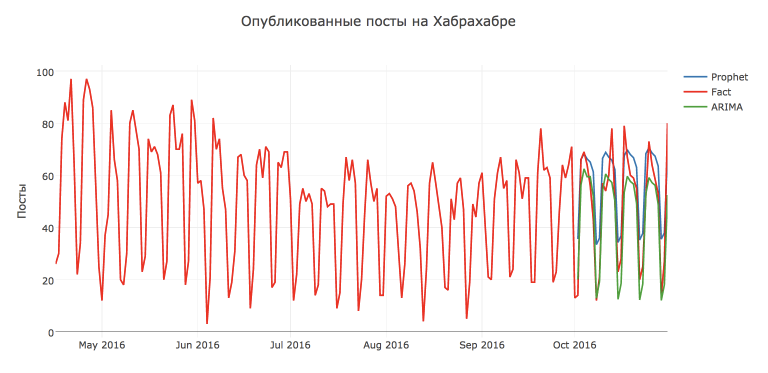
Но и Prophet, конечно же, можно еще потюнить. Например, если предсказывать в этой библиотеке не исходный ряд, а после преобразования Бокса-Кокса, нормализующего дисперсию ряда, то мы получим прирост качества: MAPE=26.79%, MAE=8.49 поста.
from scipy import stats
import statsmodels.api as sm
def invboxcox(y,lmbda):
if lmbda == 0:
return(np.exp(y))
else:
return(np.exp(np.log(lmbda*y+1)/lmbda))
train_df2 = train_df.copy().fillna(14)
train_df2 = train_df2.set_index('ds')
train_df2['y'], lmbda_prophet = stats.boxcox(train_df2['y'])
train_df2.reset_index(inplace=True)
m2 = Prophet()
m2.fit(train_df2)
future2 = m2.make_future_dataframe(periods=30)
forecast2 = m2.predict(future2)
forecast2['yhat'] = invboxcox(forecast2.yhat, lmbda_prophet)
forecast2['yhat_lower'] = invboxcox(forecast2.yhat_lower, lmbda_prophet)
forecast2['yhat_upper'] = invboxcox(forecast2.yhat_upper, lmbda_prophet)
cmp_df2 = forecast2.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(df.set_index('ds'))
cmp_df2['e'] = cmp_df2['y'] - cmp_df2['yhat']
cmp_df2['p'] = 100*cmp_df2['e']/cmp_df2['y']
np.mean(abs(cmp_df2[-predictions:]['p'])), np.mean(abs(cmp_df2[-predictions:]['e']))Мы познакомились с open-source библиотекой Prophet и ее использованием для предсказания временных рядов на практике.
Я бы не стала говорить, что эта библиотека творит чудеса и идеально предсказывает будущее. В нашем случае прогноз получился хуже стандартной SARIMA. Однако, библиотека Prophet достаточно удобная, легко кастомизируется (чего только стоит возможность добавления заранее известных аномальных дней), поэтому ее полезно иметь в своем аналитическом toolbox'e.
Немного материалов для более глубокого изучения библиотеки Prophet и предсказаний временных рядов, в общем:
Prophet GitHub репозиторийProphet документацияProphet