В этой статье (оригинал представляет собой интерактивное приложение на JavaScript) подробно описывается, как текстовая строка кодируется в символ QR-кода. Она, по сути, объясняет, как устроена внутри моя
библиотека генератора QR-кодов.
Пользовательский ввод
Результат генерации QR-кода
Пошаговый процесс
0. Анализируем символы Unicode
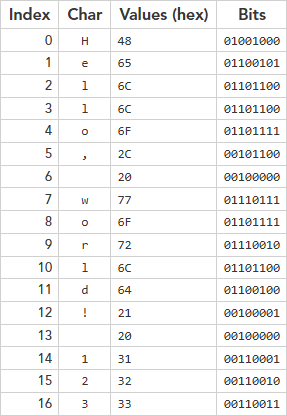
Количество кодовых точек во входной текстовой строке: 17.
Подробности о каждом из символов:
Index: индекс во входной строке
Char: сам символ
CP hex: значение кодовой точки Unicode в шестнадцатеричном виде
NM: можно ли закодировать в цифровом режиме
AM: можно ли закодировать в алфавитно-цифровом режиме
BM: можно ли закодировать в байтовом режиме
KM: можно ли закодировать в режиме кандзи
Можно ли закодировать каждый символ в соответствующем режиме:
Для кодирования всех символов выбран сегментный режим Byte
1. Создаём сегмент данных
Преобразуем каждый символ в биты. В цифровом и алфавитно-цифровом режиме идущие по порядку символы группируются, а затем кодируются в биты. В байтовом режиме символ преобразуется в 8, 16, 24 или 32 бита.
Созданный единый сегмент:
- Режим: Byte
- Количество: 17 байтов
- Данные: длина 136 байтов
(Для упрощения моё демо всегда создаёт единый сегмент. Но можно
сегментировать текст оптимально, чтобы минимизировать общую длину в битах.)
2. Подстраиваемся под номер версии
Общая длина в битах должна представлять список сегментов в зависимости от версии:
(Примечание: кодовое слово определяется как 8 битов, также известные как байт.)
Ёмкость кодовых слов данных QR-кода для каждой версии, уровень коррекции ошибок и помещаются ли данные (зелёный/красный фон):
ECC L: low
ECC M: medium
ECC Q: quartile
ECC H: high
Выбранный номер версии: 1
3. Выполняем конкатенацию сегментов, добавляем заполнители, создаём кодовые слова
Объединяем различные битовые строки:
Примечание:
- Описание режима сегмента — это всегда 4-битное поле.
- Ширина поля количества символов в сегменте зависит от режима и версии.
- Разграничителем обычно являются четыре бита «0», но их бывает и меньше, если мы достигли предела ёмкости кодового слова данных.
- Битовый заполнитель имеет ширину от нуля до семи битов «0», чтобы заполнить все неиспользованные биты в последнем байте.
- Байтовый заполнитель состоит из перемежающихся (шестнадцатеричных) EC и 11, пока не будет заполнена вся ёмкость.
Полная последовательность битов данных:
01000001000101001000011001010110110001101100011011110010110000100000011101110110111101110010011011000110010000100001001000000011000100110010001100110000
Вся последовательность байтов кодовых слов данных (полученная разбиением битовой строки на группы по 8 бит) в шестнадцатеричном виде:
41 14 86 56 C6 C6 F2 C2 07 76 F7 26 C6 42 12 03 13 23 30
4. Разбиваем блоки, добавляем ECC, реализуем чередование
Статистика обо всех блоках:
Разделяем последовательность кодовых слов данных (зелёный фон) на короткие и длинные блоки; затем для каждого блока вычисляем кодовые слова ECC (синий) и добавляем их в конец блока:
(Примечание: математические расчёты вычислений кодов коррекции ошибок Рида-Соломона пропущены, потому что это долго и скучно.)
Окончательная последовательность кодовых слов, образованная чередованием кодовых слов данных/ECC из разных блоков:
Окончательная последовательность битов для отрисовки сканирования зигзагом:
0100000100010100100001100101011011000110110001101111001011000010000001110111011011110111001001101100011001000010000100100000001100010011001000110011000010000101101010010101111000000111000010100011011011001001
5. Рисуем фиксированные паттерны
Рисуем горизонтальные и вертикальные
паттерны таймингов (в строке 6 и столбце 6, считая с 0 начиная с левого верхнего угла):
Рисуем
опорные паттерны (finder pattern) в трёх углах, каждый из которых имеет размер 8×8, включая разделитель, перерисовывая некоторые модули таймингов:
Рисуем временные макетные
биты формата (format bit) (рядом с finder pattern):
6. Отрисовываем кодовые слова и остаток
Вычисляем сканирование зигзагом (которое начинается с правого нижнего угла) так, чтобы посетить все незаполненные модули (то есть пропуская функциональные модули):
Рисуем модули данных/ECC согласно порядку сканирования зигзагом и битовые значения из окончательной последовательности кодовых слов:
(Например, байт годового слова C5 (шестнадцатеричный) — это двоичные 11000101, создающие последовательность модулей [тёмный, тёмный, светлый, светлый, светлый, тёмный, светлый, тёмный].)
7. Пробуем применять каждую из масок
Паттерн маски (влияющий только на нефункциональные модули):
Ниже показаны примеры для паттерна маски 3.
Выполняем XOR маски с модулями данных, ECC и остатком:
Отрисовываем сами
биты формат (рядом с finder pattern):
8. Находим штрафные паттерны
Горизонтальные последовательности модулей одного цвета (каждый длиной не более 5 битов):
Вертикальные последовательности модулей одного цвета (каждый длиной не более 5 битов):
Прямоугольники 2×2 модулей одного цвета:
Горизонтальные паттерны, похожие на finder pattern:
Вертикальные паттерны, похожие на finder pattern:
Баланс тёмных/светлых модулей:
9. Вычисляем штрафные очки, выбираем наилучшую маску
Mask: номер паттерна маски
RunP: штрафные очки линейной последовательности одного цвета
BoxP: штрафные очки прямоугольника 2×2 одного цвета
FindP: штрафные очки паттернов, похожих на finder pattern
BalP: штрафные очки за баланс тёмного/светлого
TotalP: сумма штрафных очков
Наименьшая сумма штрафных очков: паттерн маски 3
Как вычисляются штрафы:
- RunP: 3 очка за каждую линейную последовательность из 5 модулей одного цвета, 4 очка за каждую последовательность из 6 модулей, 5 очков за каждые 7 модулей, 6 очков за каждые 8 модулей и так далее. Последовательности не могут пересекаться.
- BoxP: 3 очка за каждый прямоугольник 2×2 одного цвета. Прямоугольники могут пересекаться.
- FindP: 40 очков за каждый паттерн, похожий на finder pattern. Finder pattern могут пересекаться.
- BalP: 0 очков, если соотношение тёмных модулей находится в интервале [45%, 55%]; 10 очков, если в интервале [40%, 60%]; 20 очков, если в интервале [35%, 65%]; 30 очков, если в интервале [30%, 70%] и так далее.
Вы можете изучить исходный код этого веб-приложения на TypeScript (
файл 0,
файл 1) и
скомпилированный код на JavaScript.
Дополнительная информация