https://habr.com/ru/post/526170/- Python
- Машинное обучение
- Искусственный интеллект
- TensorFlow

В октябре традиционно в центре внимания вновь GPT-3. С моделью от OpenAI связано сразу несколько новостей — хорошая и не очень.
Сделка OpenAI и Microsoft
Начать придется с менее приятной — компания Майкрософт
завладела эксклюзивными правами на GPT-3. Сделка предсказуемо
вызвала негодование — Элон Маск, основатель OpenAI, а ныне бывший член совета директоров компании, заявил, что Майкрософт по сути захватили OpenAI.
Дело в том, что OpenAI изначально создавалась как некоммерческая организация с высокой миссией — не позволить искусственному интеллекту оказаться в руках отдельного государства или корпорации. Основатели организации призывали к открытости исследований в этой области, чтобы технологии работали на благо всего человечества.
Майкрософт в свое оправдание утверждают, что не собираются ограничивать доступ к API модели. Таким образом, по факту ничего не изменилось — до этого OpenAI тоже не публиковала код, но если раньше даже компаниям-партнерам позволяли работать с GPT-3 только через API, то сейчас эксклюзивные права на использование появились у Microsoft.
ruGPT3 от Сбера
Теперь к более приятной новости — исследователи из Сбера
выложили в открытый доступ модель, которая повторяет архитектуру GPT-3 и основана на коде GPT-2 и, самое главное, обучена на русскоязычном корпусе.
В качестве датасета для обучения использовалась коллекция русской литературы, данные Википедии, снапшоты новостных и вопросно-ответных сайтов, материалы порталов Pikabu, 22century.ru banki.ru, Omnia Russica. Разработчики также включили данные с GitHub и StackOverflow, чтобы научить генерировать и программный код. Общий объем очищенных данных — более 600 Гб.
Новость однозначно хорошая, но есть пара оговорок. Эта модель похожа на GPT-3, но не является ей. Сами
авторы признают, что она в 230 раз меньше самой большой версии GPT-3, у которой 175 млрд весов, а значит, результаты бенчмарков повторить точно не сможет. То есть, не рассчитывайте, что эта модель будет писать неотличимые от журналистских тексты.
Также стоит учитывать, что описанная архитектура GPT-3 может отличаться от реальной реализации. Сказать точно можно только ознакомившись с тренировочными параметрами, и если раньше веса публиковали с задержкой, то в свете последних событий их можно не ждать.
Дело в том, что от количества тренировочных параметров зависит бюджет проекта, и по оценкам экспертов, обучение GPT-3 обошлось не менее 10 млн. долларов. Таким образом, воспроизвести работу OpenAI могут только крупные компании c сильными ML-специалистами и мощными вычислительными ресурсами.
Отчет State of AI 2020
Все вышесказанное подтверждает выводы
третьего ежегодного отчета о текущем состоянии дел в области машинного обучения. Натан Бенайх и Ян Хогарт, инвесторы которые специализируются на ИИ-стартапах, опубликовали подробную презентацию, которая охватывает вопросы технологий, кадров, применения в промышленности и тонкости правового поля.
Из любопытного — целых 85% исследований публикуются без исходного кода. Если коммерческие организации можно оправдать тем, что код часто вплетен в инфраструктуру проектов, то что говорить про исследовательские институты и некоммерческие компании вроде DeepMind и OpenAI?
Также сказано, что увеличение датасетов и моделей приводит к увеличению бюджетов, и с учетом того, что область машинного обучения стагнирует, каждый новый прорыв требует несоразмерно больших бюджетов (сравните размер GPT-2 и GPT-3), а значит, позволить это себе смогут только крупные корпорации.
Советуем ознакомиться с этим документом, так как он написан кратко и понятно, хорошо проиллюстрирован. Также четыре прогноза на 2020 год из прошлого отчета уже сбылись.
Не станем и дальше сгущать краски, все-таки встречаются и хорошие истории, иначе бы этой подборки не было.
Открытые мультиязычные модели от Google и Facebook
mT5
Google опубликовали
исходный код и
датасет семейства мультиязычных моделей T5. Из-за шумихи, связанной с OpenAI, эта новость прошла практически незамеченной, несмотря на внушительных масштаб — самая крупная модель насчитывает 13 млрд параметров.
Для обучения использовали датасет из 101 языка, среди которых на втором месте русский. Объяснить это можно тем, что наш великий и могучий занимает второе по популярности место в вебе.
M2M-100
Facebook тоже не отстают и
выложили мультиязычную модель, которая по их заявлениям позволяет напрямую, без промежуточного языка, переводить 100x100 языковых пар.
В области машинного перевода принято создавать и обучать модели под каждый отдельный язык и задачу. Но в случае с Facebook такой подход не способен эффективно масштабироваться, так как пользователи соцсети публикуют контент на более чем 160 языках.
Как правило многоязычные системы, которые сразу обрабатывают несколько языков, опираются на английский. Перевод получается опосредованным и неточным. Преодолеть разрыв между исходным и целевым языком сложно из-за недостатка данных, так как найти перевод с китайского на французский и наоборот бывает очень сложно. Для этого создателям пришлось генерировать синтетические данные путем обратного перевода.
В статье приводятся бенчмарки, модель справляется с переводом лучше аналогов, которые опираются на английский, а также
ссылка на датасет.

Достижения в области видеоконференций
В октябре появилось сразу несколько интересных новостей от Nvidia.
StyleGAN2
Во-первых, опубликовали
обновления для StyleGAN2. Низкоресурсная архитектура модели теперь дает улучшенные показатели на датасетах с менее чем 30 тысячами изображений. В новой версии появилась поддержка смешанной точности: обучение ускорилось в ~1.6x раз, инференс в ~1.3x раз, потребление GPU снизилось в ~1.5x раза. Также добавили автоматический выбор гиперпараметров модели: готовые решения для датасетов разного разрешения и разного количества доступных графических процессоров.
NeMo
Neural Modules —
открытый набор инструментов, который помогает быстро создавать, обучать, и файнтюнить разговорные модели. NeMo состоит из ядра, которое обеспечивает единый “look and feel” для всех моделей и коллекций, состоящих из сгруппированных по области применения модулей.
Maxine
Другой
анонсированный продукт, скорее всего внутри использует обе вышеназванные технологии. Платформа для видеозвонков Maxine объединяет в себе целый зоопарк ML-алгоритмов. Сюда входит уже привычные улучшение разрешения, устранение шумов, удаление фона, но также коррекция взгляда и теней, восстановление картинки по ключевым чертам лица (то есть дипфейки), генерация субтитров и перевод речи на другие языки в режиме реального времени. То есть почти все, что ранее встречалось по отдельности, Nvidia объединила в один цифровой продукт. Сейчас можно подать заявку на ранний доступ.
Новые разработки Google
Из-за карантина в этому году идет настоящая гонка за лидерство в области видеоконференций. Google Meet
поделились кейсом создания своего алгоритма для качественного удаления фона на основе фреймворка от Mediapipe (который умеет отслеживание движение глаз, головы и рук).
Google также запустил новую функцию для сервиса YouTube Stories на iOS, который позволяет улучшать качество речи. Это
интересный кейс, потому что для видео доступно в разы больше энхесеров, чем для аудио. Данный алгоритм отслеживает и фиксирует корреляции между речью и визуальными маркерами, вроде мимики лица, движения губ, которые затем использует, чтобы отделить речь от фоновых звуков, в том числе голосов от остальных говорящих.
Еще компания
представила новую попытку в сфере распознования языка жестов.
Говоря о ПО для видеоконференций, стоит также упомянуть о новых дипфейк-алгоритмах.
MakeItTalk
Недавно в открытый доступ выложили
код алгоритма, который анимирует фото, опираясь исключительно на аудиопоток. Это примечательно, так как обычно дипфейки алгоритмы принимают на вход видео.

BeyondBelief
Новое поколение дипфейк-алгоритмов ставит перед собой задачу делать подмену не только лица, но и всего тела, включая цвет волосы, тон кожи и фигуру.
Данную технологию в первую очередь собираются применять в сфере онлайн-шопинга, чтобы можно было использовать фотографии товаров, представленные самим брендом, без необходимости нанимать отдельных моделей. Больше сфер применения можно посмотреть в
видеодемонстрации. Пока что выглядит неубедительно, но в скором времени все может измениться.
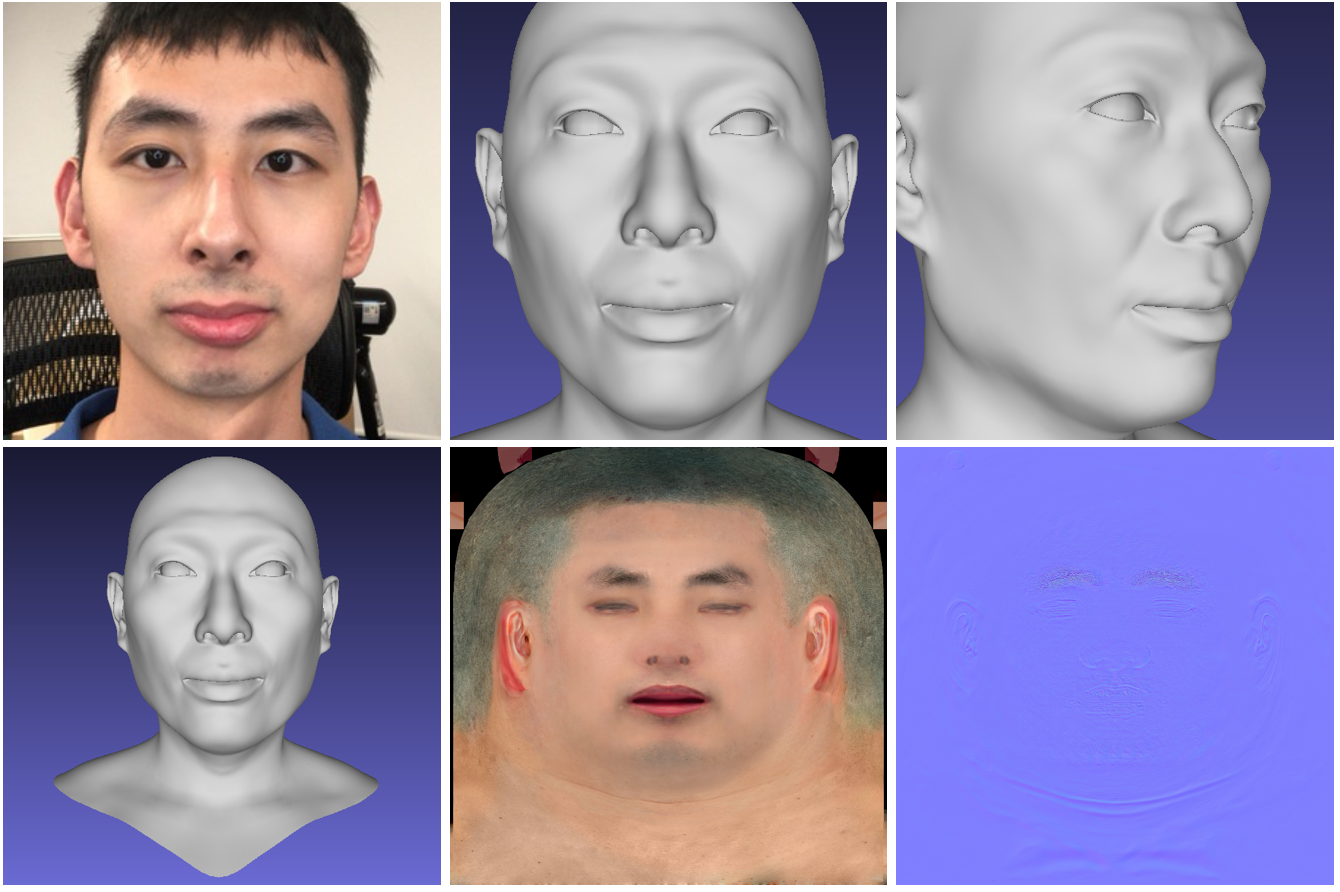
Hi-Fi 3D Face
Нейросеть генерирует высококачественную 3D-модель лица человека по фотографиям. На вход модель принимает короткое видео с обычной RGB-D камеры, а на выходе отдает сгенерированную 3D-модель лица. Код проекта и 3DMM-модель находятся в
открытом доступе.

SkyAR
Авторы представили
открытую технологию для замены неба на видео в режиме реального времени, который также позволяет управлять стилями. На целевом видео можно сгенерировать погодные эффекты вроде молний.
Пайплайн модели поэтапно решает ряд задач: сетка матирует небо, отслеживает движущиеся объекты, оборачивает и перекрашивает изображение под цветовую гамму скайбокса.

Sea-thru
Инструмент решает необычную задачу по восстановлению настоящих цветов на сделанных под водой снимках. То есть, алгоритм учитывает глубину и расстояние до объектов, чтобы восстановить освещение и убрать воду с изображений. Пока доступны только датасеты.
Модель от MIT для диагностики Covid-19
В завершение поделимся любопытным кейсом на актуальную тему — исследователи MIT разработали модель, которая отличает бессимптомных больных коронавирусной инфекцией от здоровых людей с помощью записей принудительного кашля.
Модель обучена на десятках тысяч аудиозаписей образцов кашля. Как
заявляют в MIT, алгоритм идентифицирует людей, у которых было подтверждено наличие Covid-19 с точностью 98,5%.
Государственные органы уже одобрили создание приложения. Пользователь сможет загрузить аудиозапись своего кашля и на основе результата определить, нужно ли сдавать полноценный анализ в лаборатории.
На этом все, спасибо за внимание!