https://habr.com/ru/company/domclick/blog/515560/- Блог компании ДомКлик
- Python
- Программирование
- Java
- ООП
Так уж вышло, что разработчики, особенно молодые, любят паттерны, любят спорить о том, какой паттерн нужно применять здесь или там. Спорить до хрипоты: это фасад или прокси, а может даже синглтон. А если у вас не чистая, гексагональная архитектура, то некоторые разработчики готовы сжечь на костре Святой Инквизиции.
При этом они забывают, что паттерны — это лишь возможные решения. У паттернов, также как и у любых принципов, есть границы применимости, и важно их понимать. Дорога в ад вымощена слепым и религиозным следованием пусть даже и авторитетным словам.
А наличие во фреймворке нужных паттернов никак не гарантирует их правильного и осознанного применения.
Блеск и нищета Active Record
Давайте рассмотрим в качестве антипаттерна паттерн Active Record, которого в некоторых языках программирования и фреймворках стараются избегать всеми возможными путями.
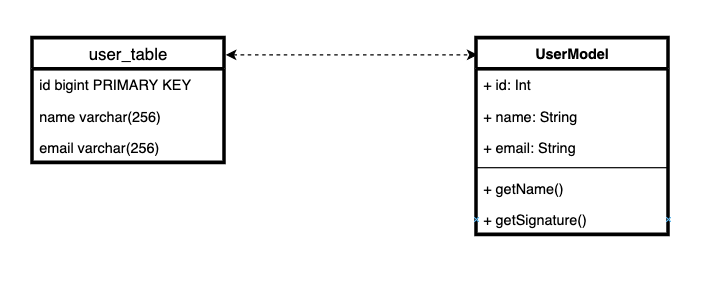
Суть Active Record проста: мы храним бизнес-логику с логикой хранения сущности. Иными словами, если очень упрощенно, каждой табличке в БД соответствует класс сущности вместе с поведением.
Есть достаточно устойчивое мнение, что объединять бизнес логику с логикой хранения в одном классе — это очень плохой, негодный паттерн. Он нарушает принцип единственной ответственности. И по этой причине Django ORM плоха by design.
Действительно, может быть не очень хорошо совмещать в одном классе логику, отвечающую за хранение, и логику предметной области.
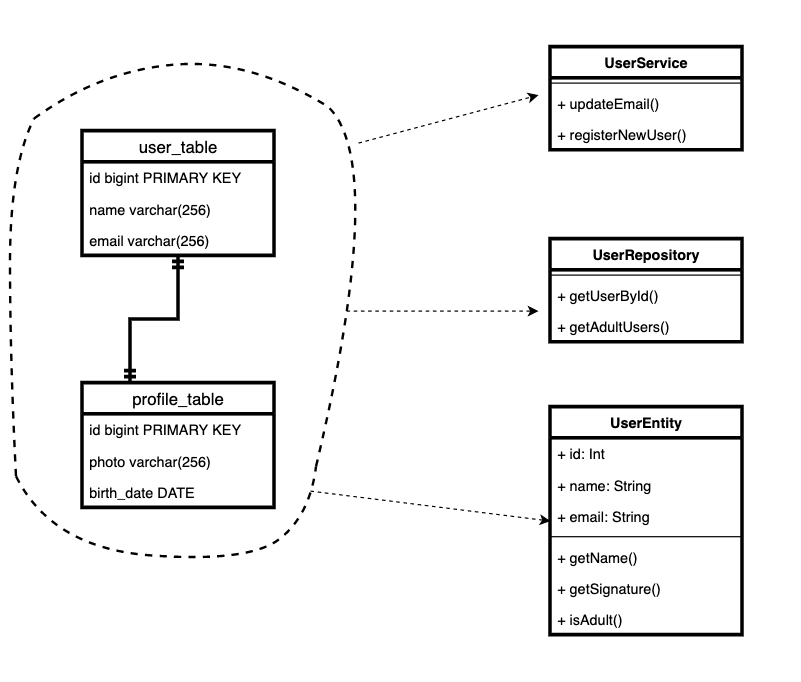
Возьмём для примера модели User и Profile. Это довольно распространенный паттерн. Есть основная табличка, и есть дополнительная, в которой хранятся не всегда обязательные, но иногда нужные данные.
Получается, что сущность предметной области «пользователь» теперь хранится в двух табличках, а в коде у нас два класса. И каждый раз, когда мы напрямую делаем какие-то исправления в
user.profile, нам нужно помнить о том, что это отдельная модель и что мы сделали в ней изменения. И отдельно её сохранять.
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
Чтобы получить список пользователей, нужно обязательно думать, а будет ли у этих пользователей забираться атрибут
profile, чтобы сразу заселектить две таблички с джоином и не получить
SELECT N+1 в цикле.
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
Всё становится еще хуже, если в рамках микросервисной архитектуры часть данных о пользователе хранится в другом сервисе — например, роли и права в LDAP-е.
При этом, конечно же, очень не хочется, чтобы внешних пользователей API это как-то заботило. Есть REST-ресурс
/users/{user_id}, и с ним хотелось бы работать, не думая о том, как внутри устроено хранение данных. Если они хранятся в разных источниках, то изменять пользователя или получать список данных будет сложнее.
Вообще говоря,
модель ОРМ != модель предметной области!
И чем больше отличается реальный мир от предположения «одна табличка в БД — одна сущность предметной области», тем больше проблем с паттерном Active Record.
Получается, что каждый раз, когда пишешь бизнес-логику, надо обязательно помнить, как хранится сущность предметной области.
Методы ORM — самый низкий уровень абстракции. Они не поддерживают никаких ограничений предметной области, а значит, дают возможность ошибиться. А еще скрывают от пользователя, какие запросы на самом деле делаются в БД, что приводит к неэффективным и долгим запросам. Классика, когда запросы делаются в циклах, вместо join-а или фильтра.
А что ещё, кроме querybuilding (возможности выстраивать запросы), нам дает ОRМ? Да ничего. Возможность переехать на новую БД? А кто в здравом уме и твердой памяти переезжал на новую БД и ему в этом помогла ОRМ? Если воспринимать её не как попытку смаппить модель предметной области (!) в БД, а как простую библиотеку, которая позволяет делать запросы к БД в удобном виде, то всё становится на свои места.
И даже несмотря на то, что в названиях классов используется
Model, а в названии файлов —
models, моделями они не становятся. Не надо себя обманывать. Это просто описание табличек. Они не помогут ничего инкапсулировать.
Но если всё так плохо, то что же делать? На помощь приходят паттерны из слоистых архитектур.
Слоистая архитектура наносит ответный удар!
Идея слоистых архитектур проста: мы отделяем бизнес логику, логику хранения и логику использования.
Кажется абсолютно логичным отделить хранение от изменения состояния. Т.е. сделать отдельный слой, который умеет получать и сохранять данные из «абстрактного» хранилища.
Мы всю логику хранения оставляем, например, в классе-хранилище
Repository. А контроллеры (или сервисный слой) используют его только для получения и сохранения сущностей. Тогда мы можем как угодно менять логику хранения и получения, и это будет одно место! А когда пишем клиентский код, можем быть спокойны, что не забыли еще одно место, в котором надо сохранить или из которого надо забрать, и не повторяем один тот же код кучу раз.
Нам не важно, если сущность состоит из записей в разных табличках или микросервисах. Или если в одной табличке хранятся сущности с разным поведением в зависимости от типа.
Но такое разделение ответственностей не дается бесплатно. Надо понимать, что дополнительные слои абстракции созданы для того, чтобы мешать «плохим» изменениям кода. Очевидно, что
Repository скрывает факт хранения объекта в SQL-БД, поэтому надо стараться не давать SQL-изму вылезать за пределы
Repository. И все запросы, даже самые простые и очевидные, придется протаскивать через слой хранения.
Например, если возникнет необходимость получить офис по имени и подразделению, придется написать так:
# пример на котлинообразном языке программирования
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
А в случае с Active Record всё значительно проще:
Office.objects.get(name=’Name’, branch=’Branch’)
Всё не так просто и в том случае, если бизнес-сущность на самом деле хранится нетривиальным образом (в нескольких табличках, в разных сервисах и т.д.). Чтобы реализовать это хорошо (и правильно) — для чего этот паттерн и создавался, — чаще всего приходится использовать такие паттерны, как агрегаты, Unit of work и Data mappers.
Правильно выделить агрегат, правильно соблюсти все накладываемые на него ограничения, правильно сделать data mapping — это сложно. И справится с этой задачей только очень хороший разработчик. Тот самый, который и в случае с Active Record смог бы сделать всё «правильно».
А что происходит с обычными разработчиками? Которые знают все паттерны и свято уверены, что если они используют слоистую архитектуру, то у них автоматически код становится поддерживаемым и хорошим, не чета Active Record. А они создают CRUD-репозитории на каждую табличку. И работают в концепции
одна табличка — один репозиторий — один объект (entity).
А не:
один репозиторий — один объект предметной области.
Они так же слепо уверены, что если в классе используется слово Entity, то оно отражает модель предметной области. Как слово Model в Active Record.
А в результате получается более сложный и менее гибкий слой хранения, который имеет все отрицательные свойства как Active Record, так и Repository/Data mappers.
Но на этом слоистая архитектура не заканчивается. Еще обычно выделяют сервисный слой.
Правильная реализация такого сервисного слоя — это тоже сложная задача. И, например, неопытные разработчики делают сервисный слой, который представляет собой сервисы — прокси к репозиториям или ORM (DAO). Т.е. сервисы написаны так, что на самом деле не инкапсулируют бизнес-логику:
# псевдокод на котлинообразном языке в
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
И возникает сочетание недостатков как Active Record, так и Service layer.
В результате в слоистых Java-фреймворках и коде, которые пишут молодые и неопытные любители паттернов, количество абстракций на единицу бизнес-логики начинает превышать все разумные пределы.
Слои есть, но они все тривиальны и являются лишь прослойками для вызова следующего слоя.
Наличие во фреймворке паттернов ООП не гарантирует их правильного и адекватного применения.
Серебряной пули нет
Совершенно очевидно, что серебряной пули нет. Сложные решения — для сложных проблем, а простые решения — для простых проблем.
Да и не бывает плохих и хороших паттернов. В одной ситуации хорош Active Record, в других — слоистая архитектура. И да, для подавляющего большинства небольших и средних приложений Active Record
достаточно хорошо работает. И для подавляющего большинства небольших и средних приложений слоистая архитектура (а-ля Spring) работает хуже. И ровно наоборот для богатых логикой сложных приложений и веб-сервисов.
Чем проще приложение или сервис, тем меньше слоев абстракций нужно.
В рамках микросервисов, в которых не так уж и много бизнес-логики, зачастую бессмысленно использовать слоистые архитектуры. Обычные transactional script — скрипты в контроллере — могут оказаться совершенно адекватными для решаемой задачи.
Собственно, хороший разработчик и отличается от плохого тем, что он не только знает паттерны, но и понимает, когда их применять.