Оптимизация ES2015 Прокси в V8
- среда, 11 октября 2017 г. в 03:13:44

Прокси появились в JavaScript с принятием стандарта ES2015. Они позволяют перехватывать фундаментальные операции объектов и переопределять их поведение. Прокси являются основой таких библиотек, как jsdom или Complink RPC library. В последнее время мы приложили много усилий, чтобы улучшить производительность прокси в V8. Эта статья проливает немного света на общие подходы к улучшению производительности в V8 и для прокси в частности.
Прокси — это "объекты, используемые для переопределения фундаментальных операций (например доступ к свойствам, присваивание, перечисление, вызов функции)" (из MDN). Больше информации может быть найдено в полной спецификации. Например, следующий пример кода добавляет логирование обращения к любому свойству объекта:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get was called for: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get was called for: property
// valueПервое, на что мы обратим внимание — это создание прокси. Первоначальная реализация на С++ повторяла шаги из спецификации EcmaScript, что приводило к минимум 4-ём прыжкам между C++ и JS средами выполнения, это видно на нижележащей схеме. Мы хотели перевести эту реализацию на платформонезависимый CodeStubAssembler (CSA), запускаемый в JS-среде исполнения. Это портирование минимизировало бы число прыжков между языковыми средами исполнения. CEntryStub и JSEntryStub на схеме — это и есть среды исполнения. Точечная линия показывает границы между средами исполнения. На наше счастье, большинство вспомогательных объявлений-заглушек (helper predicates) уже были в CSA, благодаря чему начальная версия получилась лаконичной и читабельной.
Схема ниже показывает поток управления при работе прокси с любым перехватчиком (в этом примере перехват apply, который вызывается в момент использования прокси как функции), нарисована она по следующему коду:
function foo(...) {...}
g = new Proxy({...}, {
apply: foo
});
g(1, 2);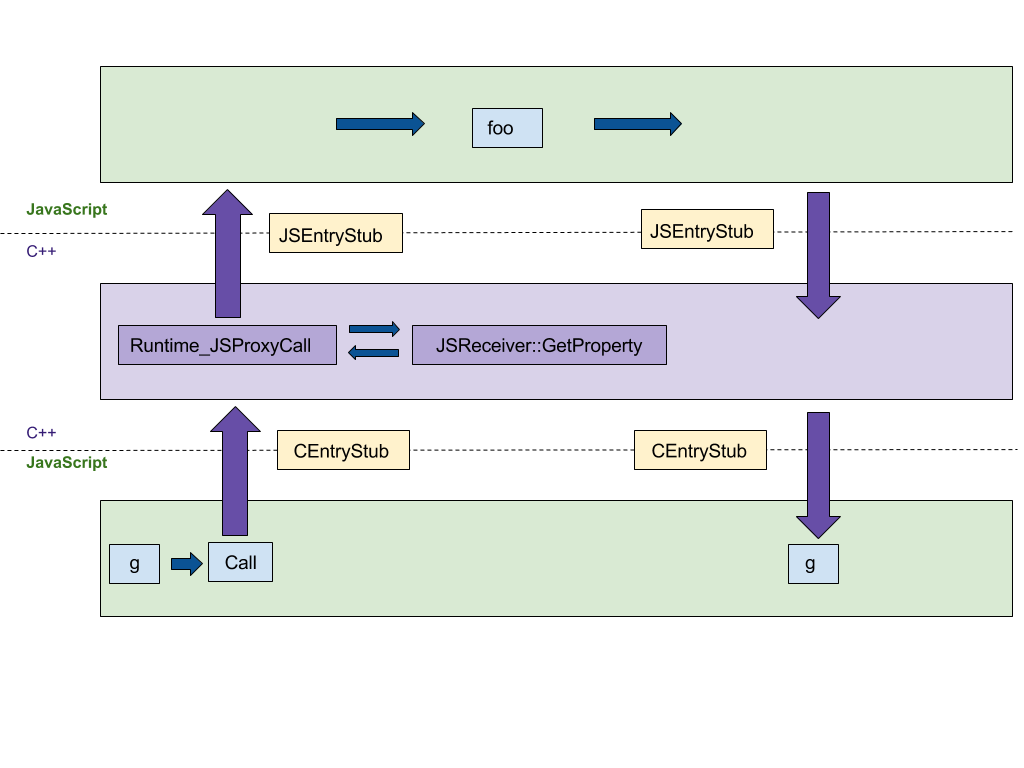
После портирования вызова перехватчика на CSA все вызовы происходят в JS-среде, уменьшая количество "прыжков" между языками с 4-х до нуля.
Это изменения привело к следующему улучшению производительности:
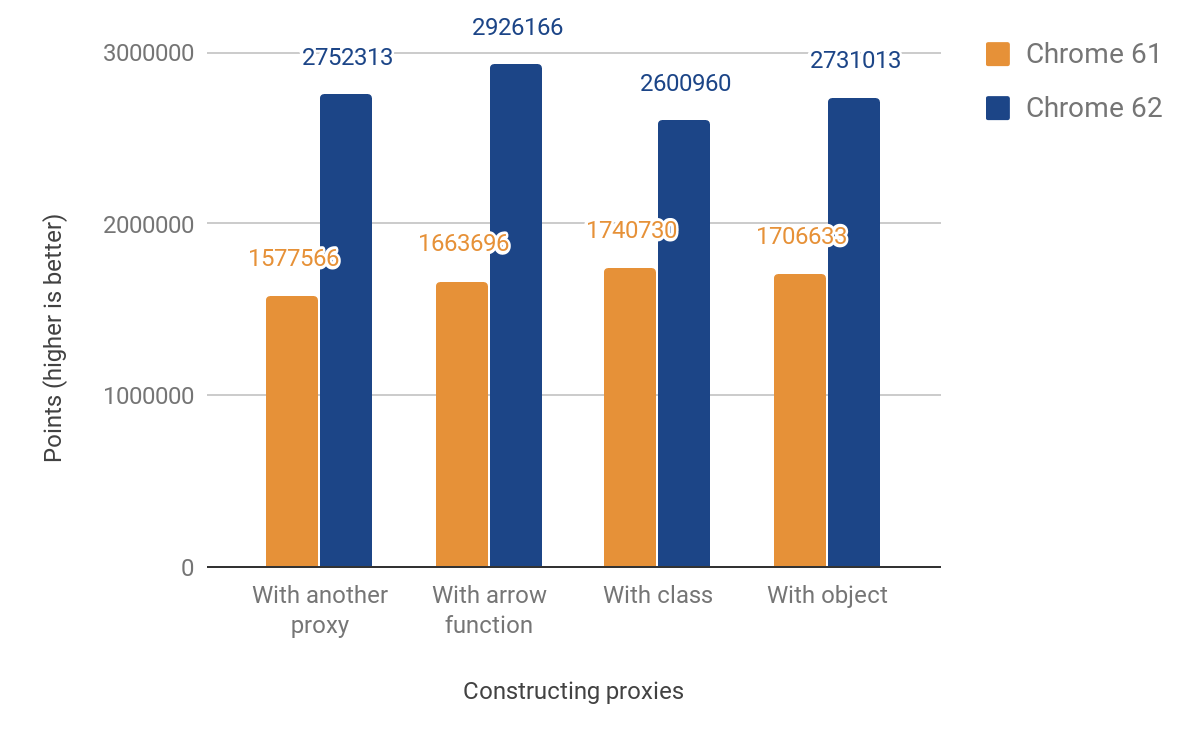
Наши измерения производительности JS показывают ускорение от 49% до 74%. Грубо говоря мы измеряли, сколько раз конкретный микробенчмарк может быть запущен за 1000 мс. Для некоторых тестов код запускается несколько раз, чтобы уточнить результат (из-за ограниченной точности таймера). Код всех бенчмарков ниже может быть найден в нашей js-perf-test директории.
Call и construct перехватчикиСледующая часть показывает результаты оптимизации перехватчиков вызова и создания (они же apply и construct).
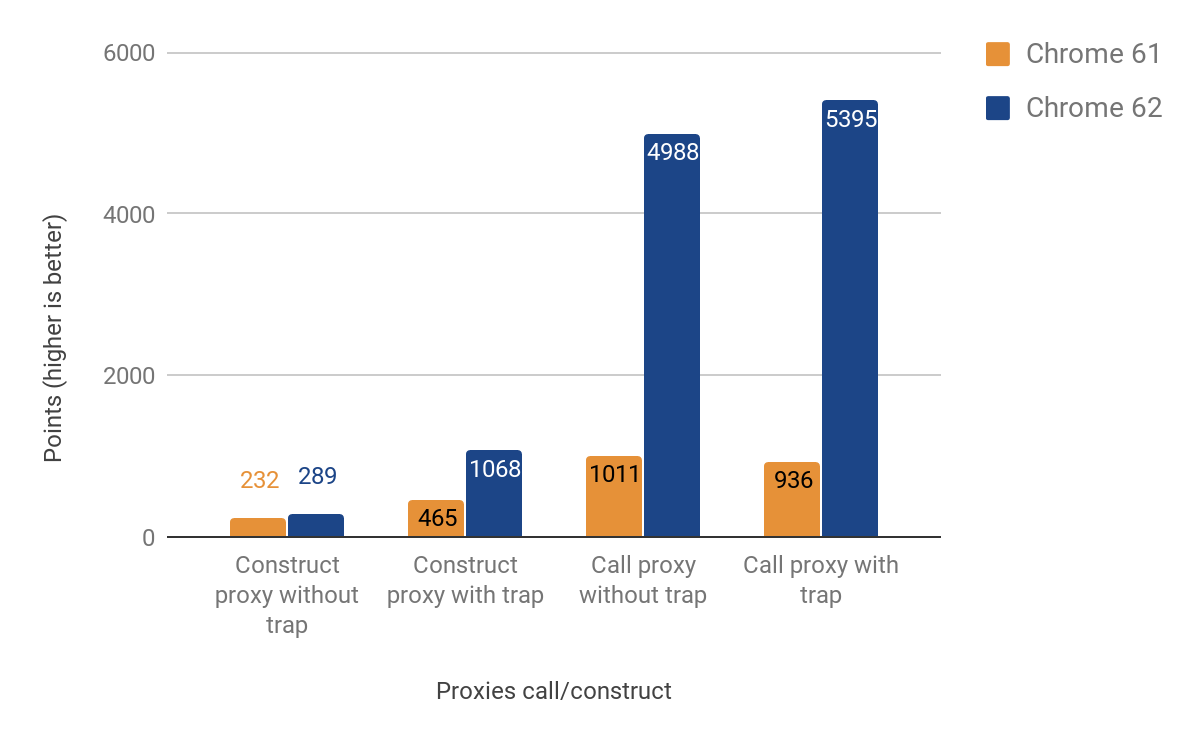
Значительное увеличение производительности при вызове прокси — до 500% быстрее! А ускорение создания прокси не так примечательно, особенно если не определены никакие перехватчики — в этом случае ускорение только 25%. Получили мы эти результаты с помощью запуска следующей команды в d8 shell:
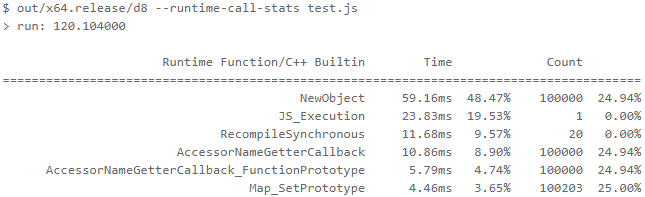
Где test.js — это файл со следующим содержимым:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');Выяснилось, что большая часть времени тратится в функции NewObject и в функциях, ею вызываемой, так что теперь мы думаем, как ускорить это в следующих релизах.
Следующая секция о том, насколько мы оптимизировали наиболее используемые операции — чтение и запись свойств через прокси. Оказалось что get-перехватчик более запутан, чем предыдущие примеры, из-за особенностей поведения инлайн-кеша. Подробнее про инлайн-кеши вы можете посмотреть в этом видео.
В конечном счёте мы получили рабочий порт на CSA со следующими результатами:
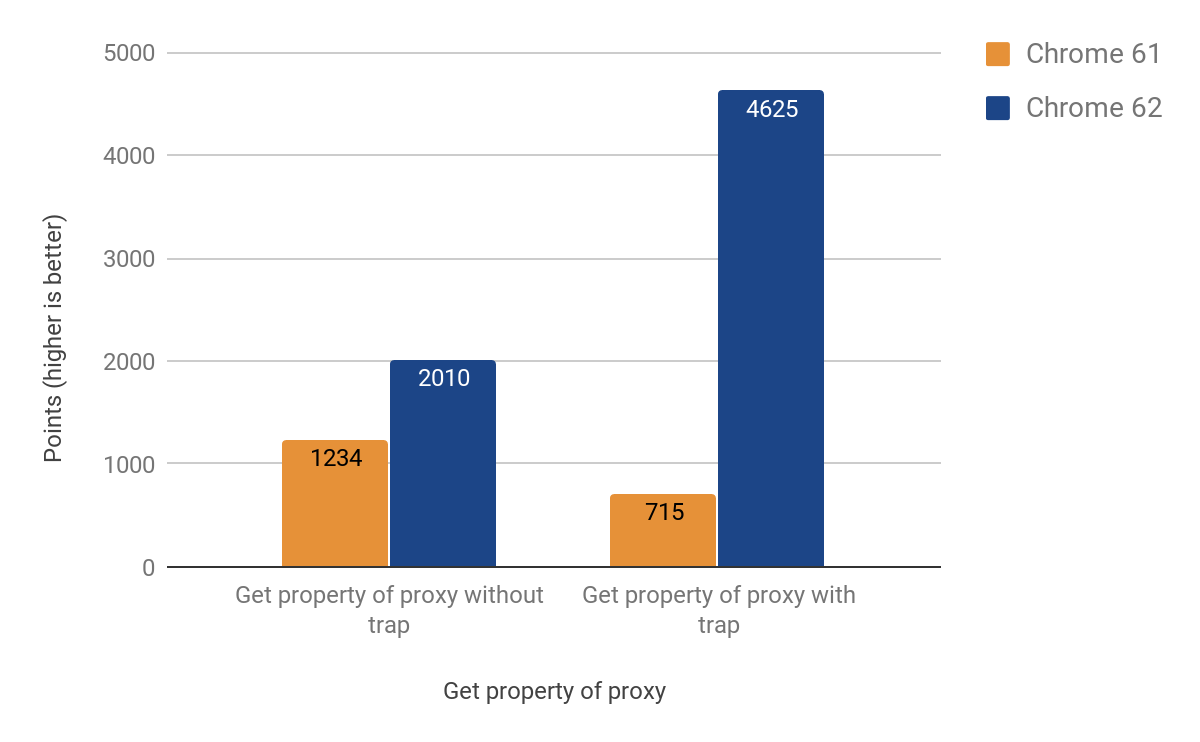
После применения изменений мы заметили, что размер apk-файла Chrome для Android вырос на ~160Kb, что больше ожидаемого для маленькой функции в 20 строчек, но, к счастью, мы храним подобную статистику. Оказалось, что функция вызывается дважды из другой функции, которая вызывается 3 раза из третьей, которая вызывается 4 раза. Причиной проблемы был агрессивный инлайн функций. В конце концов мы решили проблему вынесением функции в отдельную заглушку (здесь, видимо, имеются ввиду те же заглушки, что выше были названы "предикатами"), что сохранило драгоценные килобайты — окончательная версия увеличивала объём apk-файла всего лишь на ~19Kb.
Следующая часть показывает результаты оптимизации has-перехватчика. Мы думали это будет легко (ожидали переиспользования большей части кода из get-перехватчика), но у has своя атмосфера. Отчасти из-за трудно отлаживаемой проблемы обхода цепочки прототипов при вызове in оператором. Результаты улучшения варьируются от 71% от 428%. И опять выигрыш более заметен, если перехватчики определены при создании.
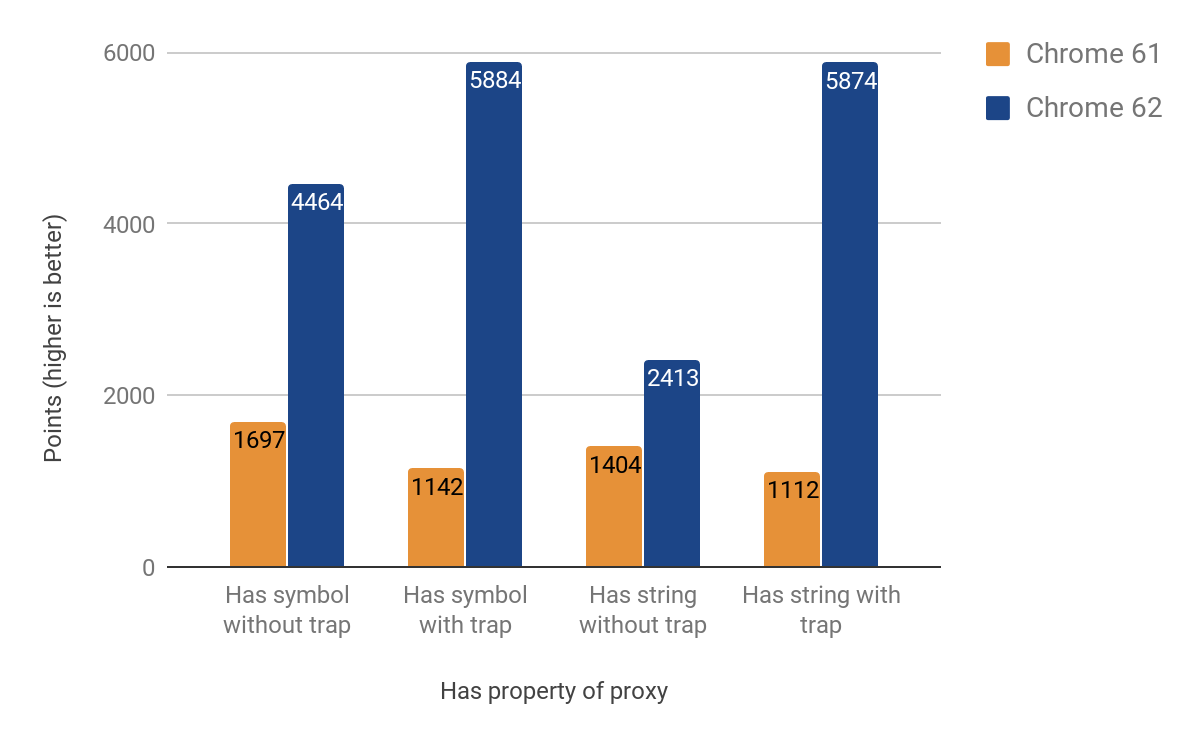
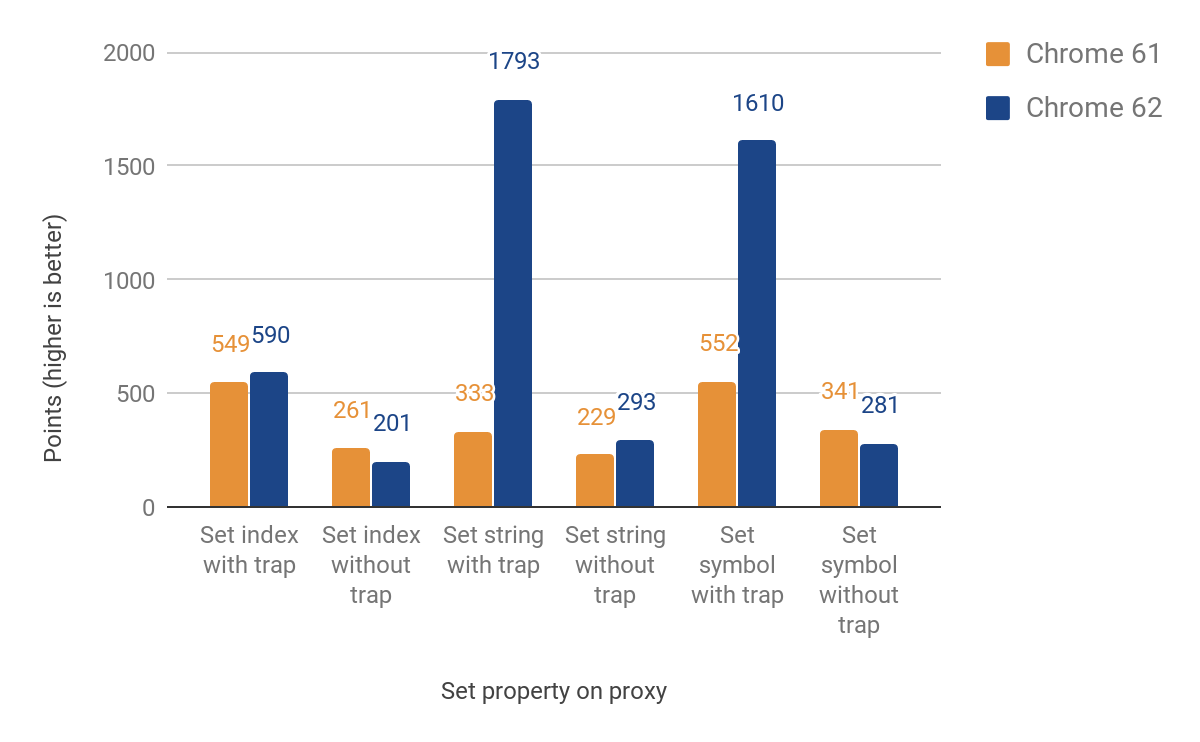
Теперь мы переходим к set-перехватчику. И в этот раз нам надо по-разному работать с именованными и индексированными свойствами (элементами). Эти два типа не часть языка JS, а результат внутренних оптимизаций обработки свойств объектов. Изначальная реализация прокси по-прежнему выходит из среды исполнения (для элементов), что опять приводит к пересечению сред исполнения. Тем не менее мы достигли улучшения от 27% до 438% для случаев, когда перехватчик определён, но ценой замедления на 23%, если не определён. Падение производительности здесь обусловлено дополнительными проверками, чтобы различать индексированные и именованные свойства объекта. Для индексированных свойств пока нет никаких улучшений. Вот график с полными результатами:
Полученные в jsdom-proxy-benchmark:
Проект jsdom-proxy-benchmark составляет (в прямом смысле слова составляет: собирает в один html-файл) ECMAScript specification с помощью инструмента Ecmarkup. В версии jsdom@11.2.0 (который лежит в основе Ecmarkup) использует прокси для реализации таких структур как NodeList и HTMLCollection. Мы использовали это как бенчмарк, чтобы измерить прозводительность в более приближенном к реальному миру сценарии, чем наши синтетические микро-бенчмарки. За 100 проходов средние результаты такие:
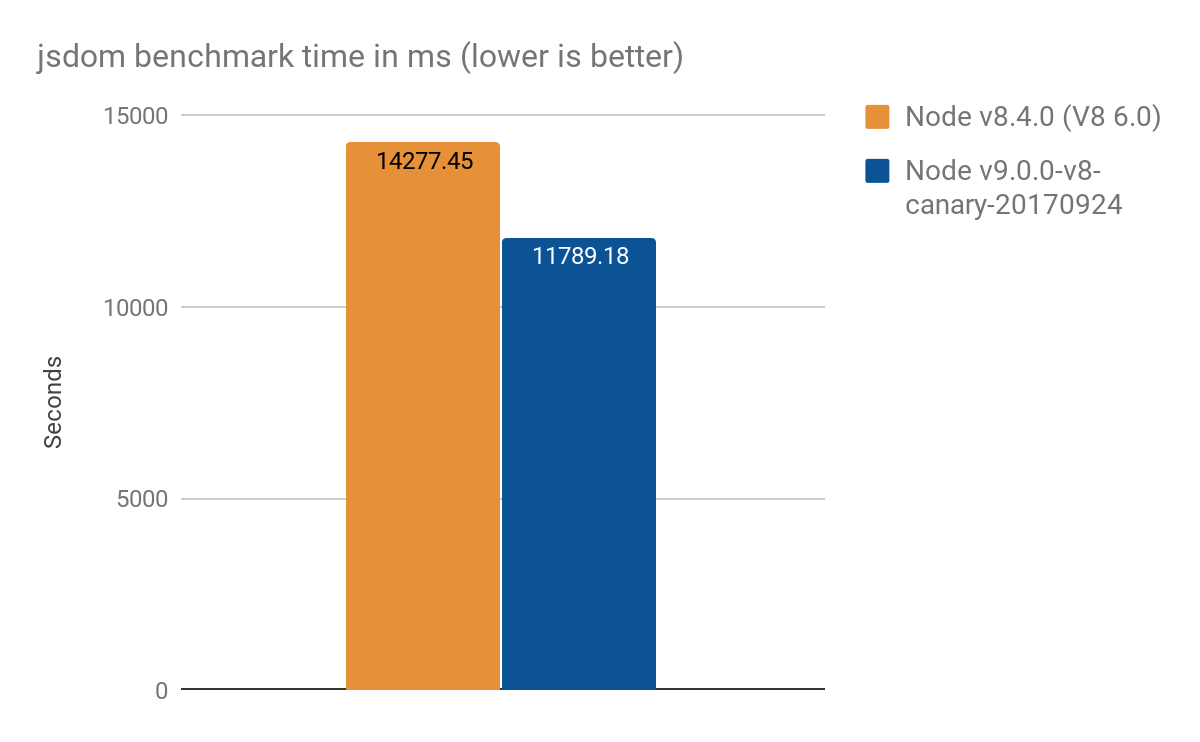
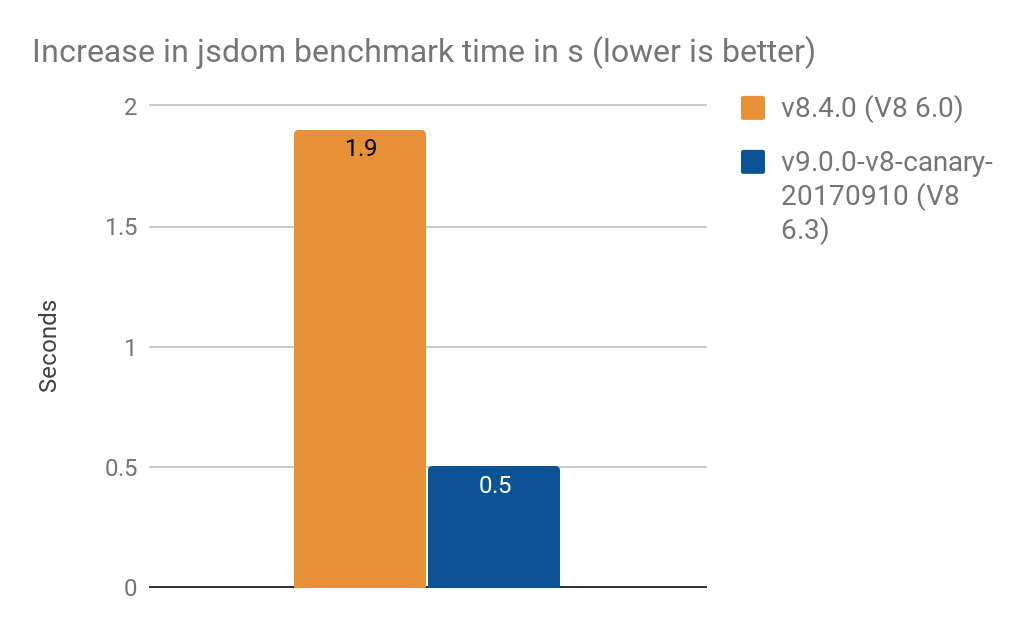
Спасибо за результаты, предоставленные TimothyGu.
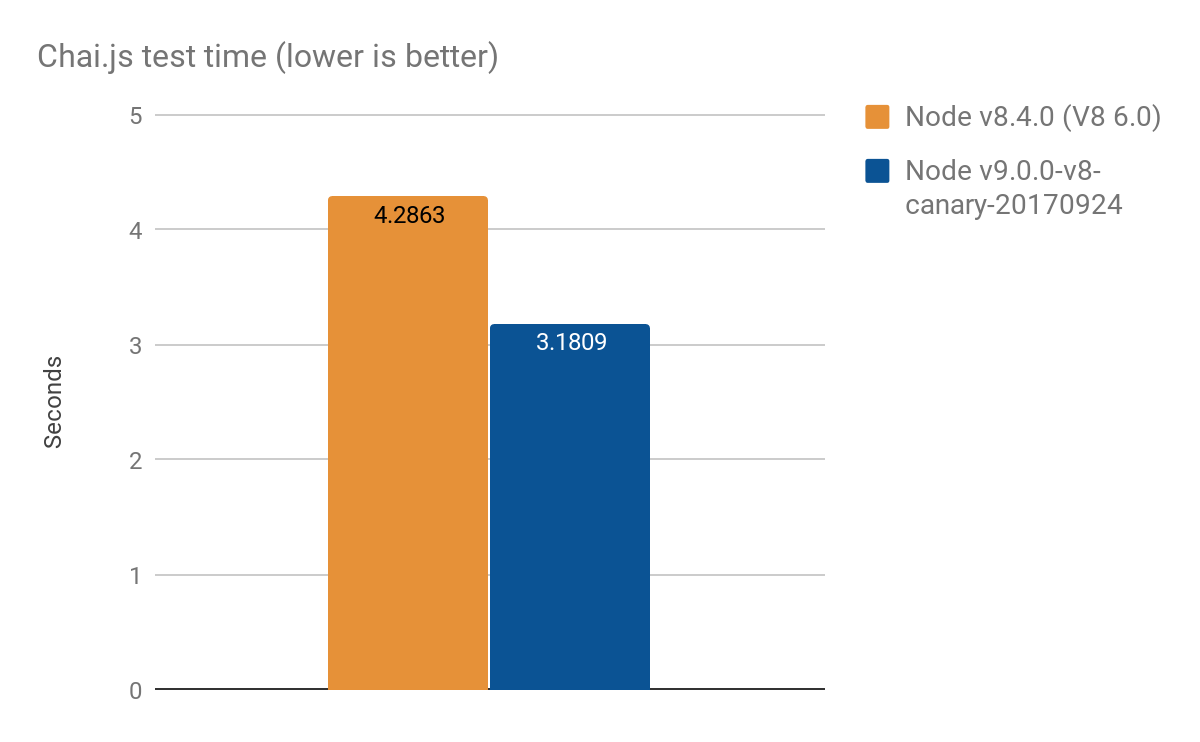
Полученные в Chai.js:
Chai.js — это популярная библиотека ассертов, довольно плотно использующая прокси. Мы сделали что-то типа бенчмарка, использующего реальные сценарии; и запуская тесты под разные версии V8 выявили выигрыш более чем одной секунды из четырёх. В среднем за 100 запусков:
У нас есть прижившийся стандартный подход, как побеждать узкие места производительности, и краеугольный камень — это следующие несколько шагов (которыми мы и следовали в раскрытой в этой статье работе):
Эти шаги подходят для любой оптимизации, которую вам может потребоваться сделать.