Общий обзор архитектуры сервиса для оценки внешности на основе нейронных сетей
- пятница, 17 июля 2020 г. в 00:28:30

Привет!
В данной статье я поделюсь опытом построения микросервисной архитектуры для проекта, использующего нейронные сети.
Поговорим о требованиях к архитектуре, посмотрим на различные структурные диаграммы, разберем каждый из компонентов готовой архитектуры, а также оценим технические метрики решения.
Приятного чтения!
Основная идея – на основе фото дать оценку привлекательности человека по десятибалльной шкале.
В данной статье мы отойдем от описания как используемых нейронных сетей, так и процесса подготовки данных, обучения. Однако, в одной из следующих публикаций, мы обязательно вернемся к разбору пайплайна оценки на углубленном уровне.
Сейчас же мы верхнеуровнево пройдемся по пайплайну оценки, а упор сделаем на взаимодействие микросервисов в контексте общей архитектуры проекта.
При работе над пайплайном оценки привлекательности, задача была декомпозирована на следующие составляющие:
Первое решается силами предобученной MTCNN. Для второго была обучена сверточная нейросеть на PyTorch, в качестве backbone был использован ResNet34 – из баланса «качество / скорость инференса на CPU»

Функциональная диаграмма пайплайна оценки
В жизненном цикле ML проекта этапы работы над архитектурой и автоматизацией развертывания модели, зачастую, одни из самых затратных по времени и ресурсам.

Жизненный цикл ML проекта
Данный проект не исключение – было принято решение обернуть пайплайн оценки в онлайн-сервис, для этого требовалось погрузиться в архитектуру. Были обозначены следующие базовые требования:
После анализа требований стало очевидно, что микросервисная архитектура вписывается практически идеально.
Для того, чтобы избавиться от лишней головной боли, в качестве фронтенда был выбран Telegram API.
Для начала рассмотрим структурную диаграмму готовой архитектуры, далее перейдем к описанию каждого из компонентов, а также формализуем процесс успешной обработки изображения.
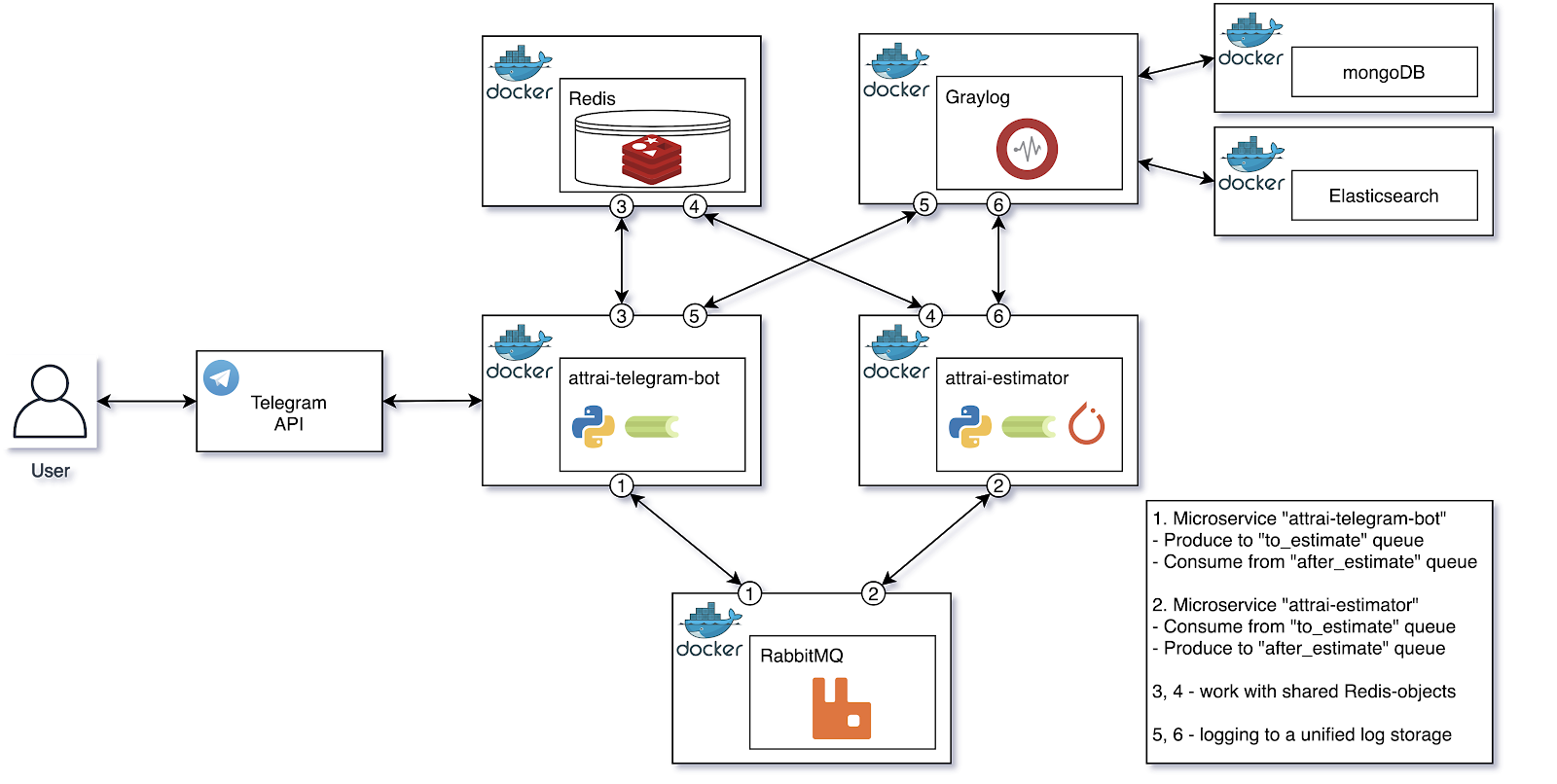
Структурная диаграмма готовой архитектуры
Поговорим подробнее о каждом из компонентов диаграммы, обозначим их Single Responsibility в процессе оценки изображения.
Данный микросервис инкапсулирует все взаимодействия с Telegram API. Можно выделить 2 основных сценария – работа с пользовательским изображением и работа с результатом пайплайна оценки. Разберем оба сценария в общем виде.
При получении пользовательского сообщения с изображением:
Также, данный микросервис, как celery worker, слушает очередь «after_estimate», которая предназначается для тасков, прошедших через пайплайн оценки.
При получении новой таски из “after_estimate”:
Данный микросервис является celery worker и инкапсулирует в себе всё, что связано с пайплайном оценки изображения. Алгоритм работы тут один – разберем его.
При получении новой таски из “to_estimate”:
Graylog — это решение для централизованного управления логами. В данном проекте, он использовался по своему прямому назначению.
Выбор пал именно на него, а не на привычный всем ELK стэк, по причине удобства работы с ним из под Python. Все, что необходимо сделать для логирования в Graylog, это добавить GELFTCPHandler из пакета graypy к остальным root logger handlers нашего python-микросервиса.
Я, как человек, который до этого работал только с ELK стэком, в целом, получил позитивный опыт во время работы с Graylog. Единственное, что удручает – превосходство по фичам Kibana над веб-интерфейсом Graylog.
RabbitMQ — это брокер сообщений на основе протокола AMQP.
В данном проекте он использовался как наиболее стабильный и проверенный временем брокер для Celery и работал в durable режиме.
Redis — это NoSQL СУБД, работающая со структурами данных типа «ключ — значение»
Иногда возникает необходимость использовать в разных python-микросервисах общие объекты, реализующие какие-либо структуры данных.
Например, в Redis хранится hashmap вида «telegram_user_id => количество активных тасок в очереди», что позволяет ограничить количество запросов от одного пользователя определенным значением и, тем самым, предотвратить DoS-атаки.
Наконец, после обзора архитектуры, можно перейти к не менее интересной части — DevOps

Docker Swarm - система кластеризации, функционал которой реализован внутри Docker Engine и доступен из коробки.
При помощи «роя», все ноды нашего кластера можно разделить на 2 типа – worker и manager. На машинах первого типа разворачиваются группы контейнеров (стэки), машины второго типа отвечают за скалирование, балансировку и другие классные фичи. Менеджеры по умолчанию являются и воркерами.
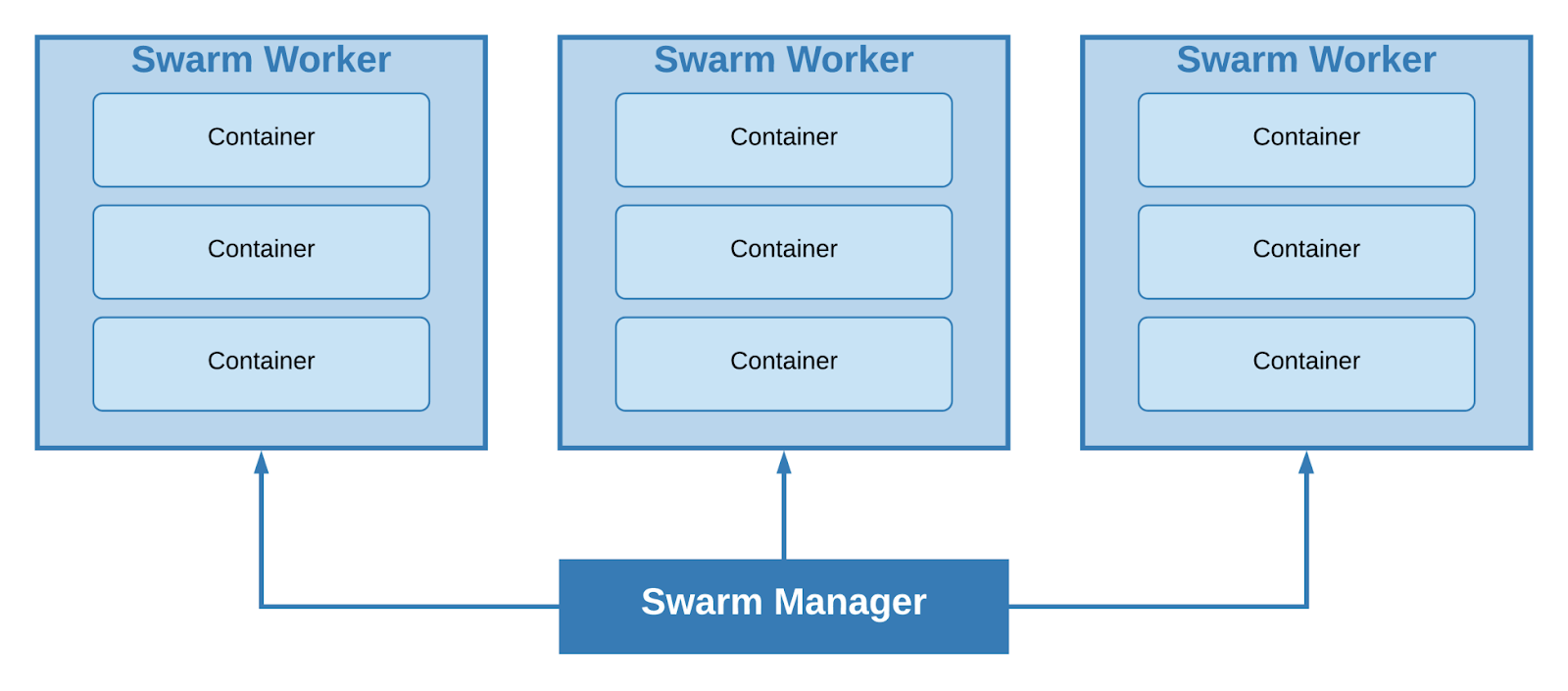
Кластер с одним leader manager и тремя worker
Минимально возможный размер кластера – 1 нода, единственная машина будет одновременно выступать как leader manager и worker. Исходя из размера проекта и минимальных требований к отказоустойчивости, было принято решение использовать именно этот подход.
Забегая вперед, скажу, что с момента первой production-поставки, которая была в середине июня, проблем, связанных с данной организацией кластера, не было (но это не значит, что подобная организация хоть сколько-нибудь допустима в любых средне-крупных проектах, на которые накладываются требования по отказоустойчивости).
В режиме «роя» за развертывание стэков (наборов docker services) отвечает docker stack
Он поддерживает docker-compose конфиги, позволяя дополнительно использовать deploy параметры.
Например, при помощи данных параметров были ограничены ресурсы на каждый из инстансов микросервиса оценки (выделяем на N инстансов N ядер, в самом микросервисе ограничиваем кол-во ядер, используемое PyTorch`ем, одним)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…Важно отметить, что Redis, RabbitMQ и Graylog — stateful сервисы и масштабировать их так же просто, как «attrai-estimator», не получится
Кажется, что использование Kubernetes в проектах маленького и среднего размера – оверхед, весь необходимый функционал можно получить от Docker Swarm, который довольно user friendly для оркестратора контейнеров, а также имеет низкий порог вхождения.
Развертывалось это все на VDS со следующими характеристиками:
После локального нагрузочного тестирования, казалось, что при серьезном наплыве пользователей, данной машинки будет хватать впритык.
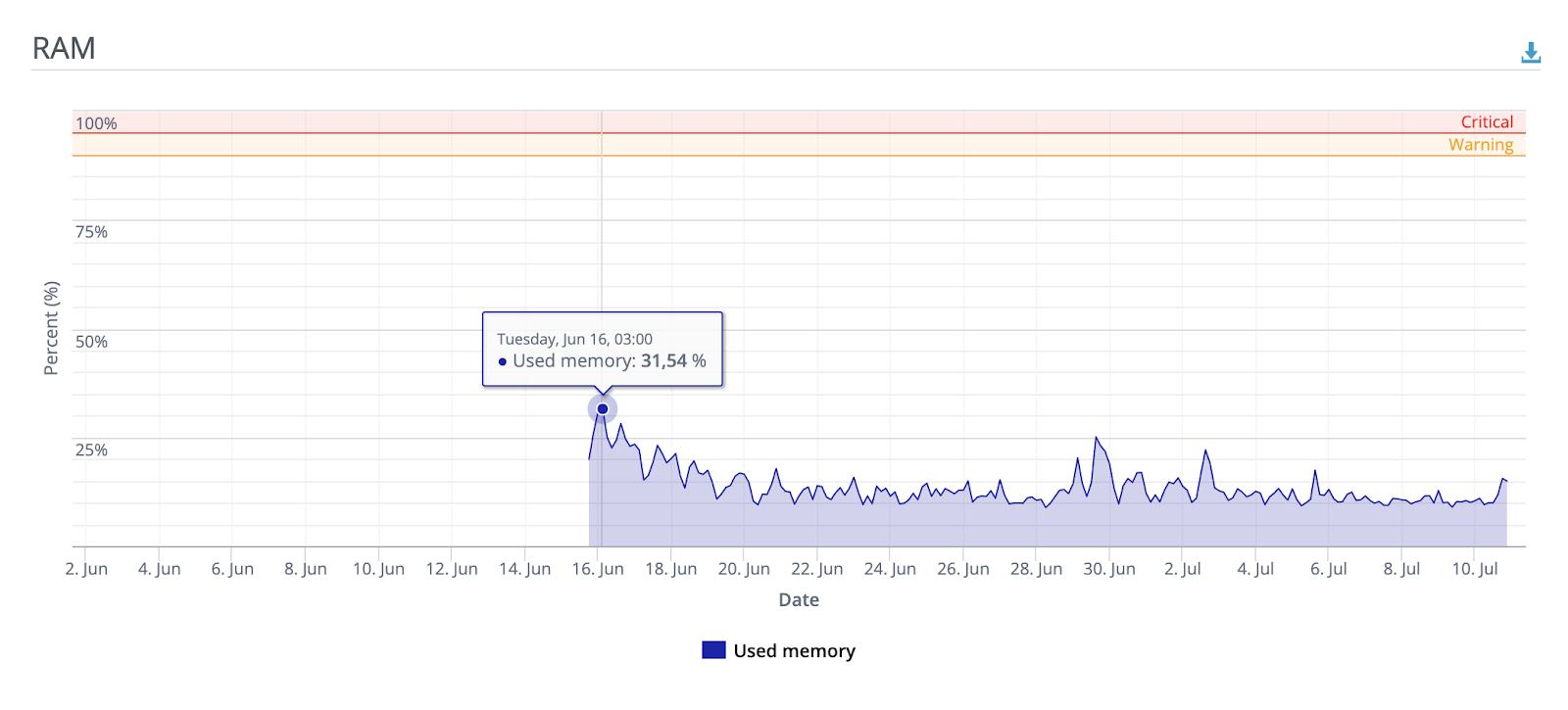
Но, сразу после деплоя, я запостил ссылку на одну из самых популярных в СНГ имиджборд (ага, ту самую), после чего люди заинтересовались и за несколько часов сервис успешно обработал десятки тысяч изображений. При этом в пиковые моменты ресурсы CPU и RAM не были использованы даже наполовину.

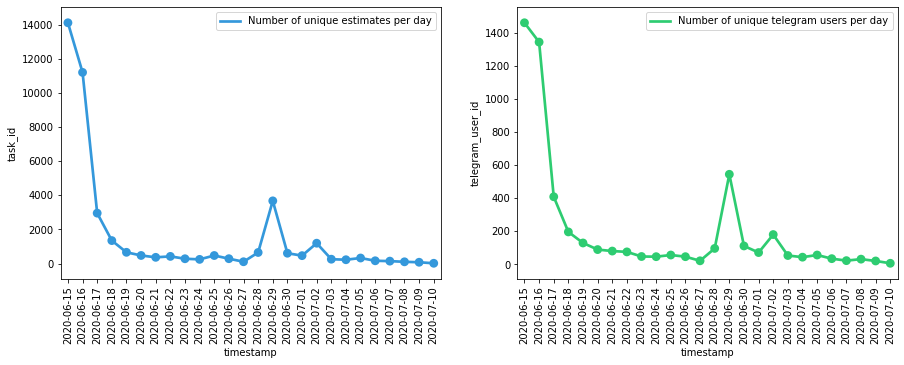
Количество уникальных пользователей и запросов на оценку, с момента деплоя, в зависимости от дня
Распределение времени инференса пайплайна оценки

Резюмируя, могу сказать, что архитектура и подход к оркестрации контейнеров полностью себя оправдали — даже в пиковые моменты не было падений и проседаний по времени обработки.
Думаю, проекты маленького и среднего размеров, использующие в своем процессе реалтайм инференс нейронных сетей на CPU, успешно могут перенять практики, описанные в данной статье.
Добавлю, что изначально статья была больше, но, дабы не постить лонгрид, решил некоторые моменты в данной статье опустить — вернемся к ним в следующих публикациях.
Потыкать бота можно в Telegram — @AttraiBot, работать будет, как минимум, до конца осени 2020 года. Напомню — никакие пользовательские данные не хранятся — ни исходные изображения, ни результаты пайплайна оценки — все сносится после обработки.