http://habrahabr.ru/company/nutanix/blog/240859/
Возможно, вы уже слышали достаточно новый для рынка не_онлайн проектов термин —
Web-Scale IT, который по мнению Gartner в 2017 году займет не менее 50% рынка корпоративного IT.
В этом году — это один из основных модных терминов.
Ситуация на корпоративных рынках сейчас активно напоминает фразу про
подростковый секс — все говорят что имели (= умеют), но реально — дела обстоят невесело.
Буквально каждый вендор рассказывает про BigData, конвергентные решения, перспективы и прочее.
Мы в свою очередь смеем надеяться, что у нас с этим
реально все весьма неплохо, но тут всегда виднее со стороны и ваше мнение может не совпадать с нашим.
Все же попробуем рассказать о том, как мы пытаемся изменить рынок, который в ближайшее время будет составлять десятки миллиардов долларов ежегодно и почему мы считаем что время традиционных решений для хранения и обработки данных подходит к своему закату.

Предпосылки оной надежде —
наша история, про которую мы больше в блоге вспоминать не будем, но позволит избежать ненужных дискуссий про «очередных пионеров велосипедо-строителей».
Компания основана в Кремниевой долине в 2009 году ключевыми инженерами Google (разработчиками Google Filesystem), Facebook, Amazon и других глобальных проектов, а с 2012 года расширяется в Европу и подключает инженеров из ключевых Европейских команд (например, Badoo).
Названы самым быстрорастущим технологическим стартапом последних 10 лет, уже вошли в
рейтинг Gartner как визионеры (технологические лидеры) индустрии конвергентных решений.
По мнению Forbes, являемся
лучшим в мире «облачным» стартапом для работы
Да, у нас есть инженеры в России, и будет значительно больше. Растем.
Собственно, в нашем ДНК — крупнейшие в мире интернет проекты, с основной идеей — работать всегда и для любого масштаба / объема данных.
Базируемся на open-source компонентах, доведенных до ума с помощью большого напильника —
Cassandra для хранения метаданных файловой системы (с маневром обхода
CAP теоремы по принципу «умный в гору не пойдет» и доработкой в строну CA),
Apache Zookeper для хранения конфигурации кластера, Centos Linux и файловая система EXT4.
Активное
использование BigData технологий внутри (по настоящему, а не маркетинг).
В общем,
умеем.
Ремарка — просьба понять и не сильно шуметь, если термины покажутся неудачно переведенными — на эту тематику словарей еще не издавалось, многие понятия уже устоялись (хотя и являются однозначными англицизмами). Всегда рады, если подскажете более адекватную терминологию — в конце концов, мы планируем писать много интересных статей.
К статье приложены иллюстрации (того как работает Nutanix), и детальное техническое описание будет в последующих статьях (вы же не хотите читать статью всю ночь?)
Итак, поехали!
(с) Гагарин.
….
Web-Scale
Для начала, стоит попробовать вообще определиться, что подразумевается под сим столь одиозным термином, причем желательно без маркетингового пустословия.
Базовые принципы:
Гипер-конвергентность
Чисто программная реализация (Software Defined)
Распределенные и полностью самодостаточные системы
Линейное расширение с очень точной гранулярностью
Дополнительно:
Мощная автоматизация и аналитика с помощью API
Самоизлечение после отказов оборудования и датацентров (катастрофоустойчивость).
Раскроем смысл?
Гипер-конвергентность

В упрощенном смысле — нативное объединение двух или более различных компонент (сеть, виртуализация и т.д.) в один юнит.
Нативность — ключевое слово в данном случае, ибо мы не говорим просто об упаковке различных компонент в едином пакете, но имеем ввиду полную и изначальную интеграцию.
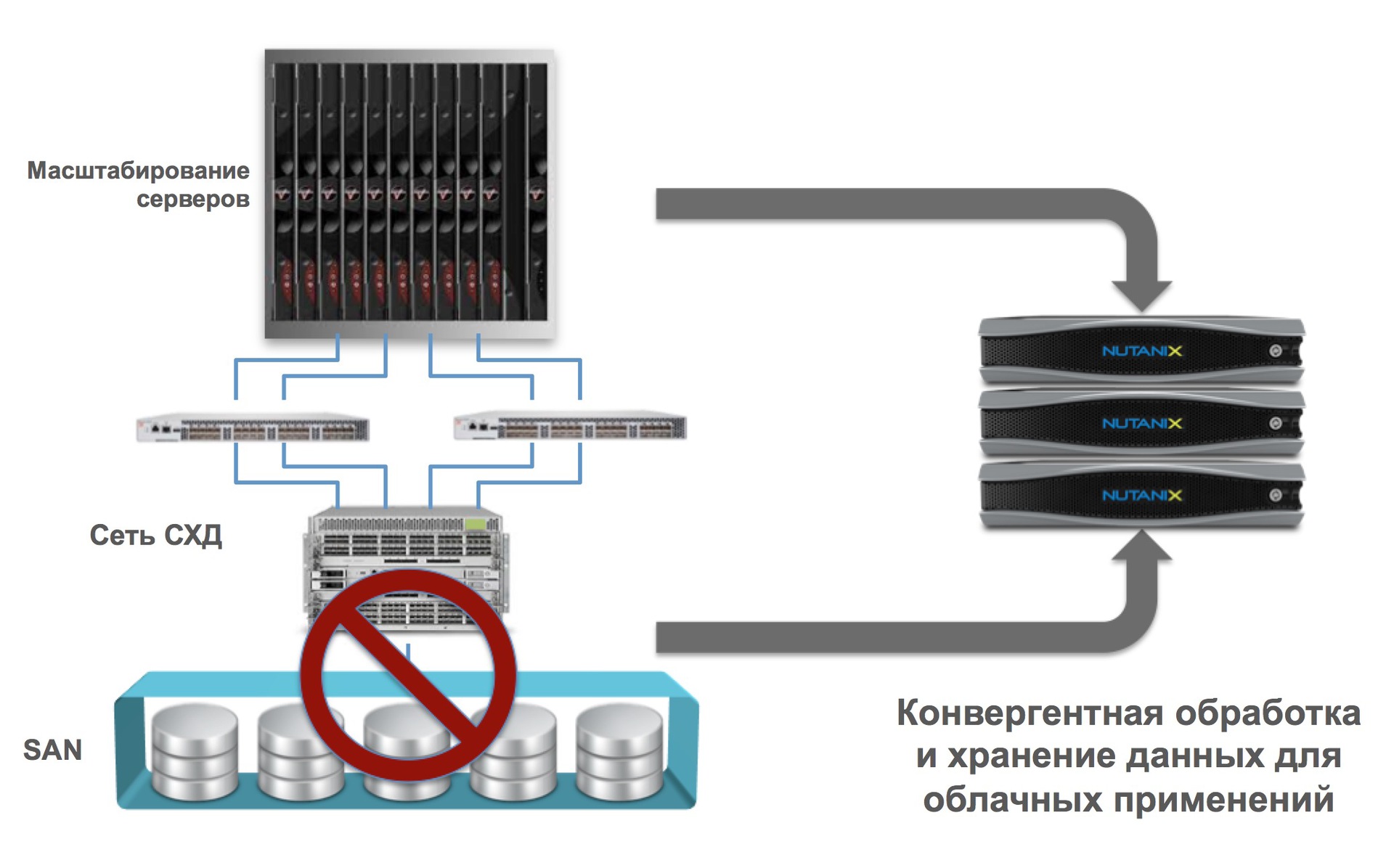
В случае с Nutanix, мы говорим о том, что наша платформа объединяет в себе компьютинг и хранение данных. Другие компании могут например говорить (и это тоже будет гипер-конвергентным) о том, что объединяют CХД (систему хранения данных) с сетью, или множество других вариантов.
Нативная интеграция двух или более компонент в случае Web-scale дает линейное (горизонтальное) масштабирование без каких-либо лимитов.
Как следствие, мы получаем существенные преимущества:
- Масштабирование по одной единице решения (как кубики Лего)
- Локализация ввода-вывода (крайне важно для массивного ускорения операций I/O)
- Устранение традиционных СХД как рудиментарных, с интеграцией в единое решение (нет СХД — нет проблем с ней связанных)
- Поддержка всех основных технологий виртуализации на рынке, включая open-source (ESXi, HyperV, KVM).
Чисто программная реализация
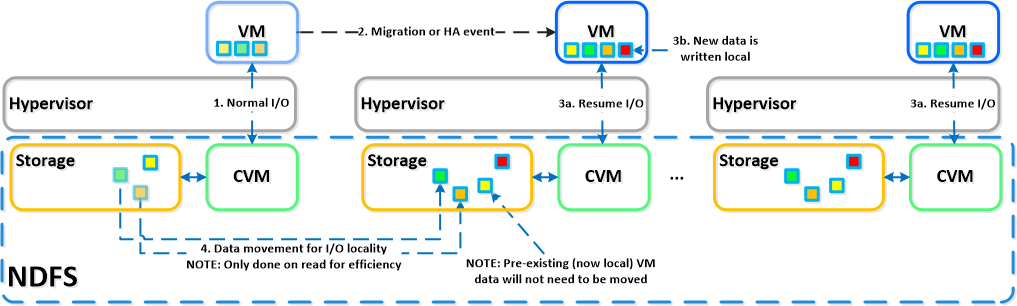
Перенос всей логики из (крайне сложного) пропиетарного оборудования (спец-процессоры, ASIC / FPGA) в 100% программную реализацию.
Как пример, в Nutanix мы выполняем любые (и зачастую уникальные — такие как дедупликация RAM кэша, распределенная map/reduce отложенная дедупликация данных на кластере и т.д.) операции программно.
Многие спросят — это же должно дико “тормозить”? Никоим образом.
Современные процессоры Intel умеют очень многое, причем очень быстро.
Как пример — вместо применения аппаратных спец. адаптеров для компрессии и дедупликации (как делают некоторые архаичные вендоры) — мы просто используем аппаратные
инструкции процессора Intel для подсчета sha1 контрольных сумм.
Компрессия данных (отложенная и “на лету”)?
Легко, свободный алгоритм
snappy, используемый Google.
Резервирование данных?
RAID устаревшая и мертвая технология (которой многие вендоры пытаются сделать мощный фейслифтинг, с лошадиными дозами ботокса), давно не используется крупными онлайн проектами. Почитайте например вот это —
почему RAID мертв для больших данных.
Если очень коротко, то проблема RAID даже не только скорость его работы, но время восстановления после отказов аппаратных узлов (дисков, полок, контроллеров). Например, в cлучае с Nutanix, после отказа жесткого диска на 4TB, восстановление целостности системы (количества реплик данных) для
32 узлов в кластере под тяжелой нагрузкой, занимает всего 28 минут.
Сколько времени будет перестраиваться большой массив (скажем на сотни терабайт) и RAID 6 — думаем, вы сами в курсе (многие часы, иногда сутки).
Учитывая, что уже сейчас готовы
гелиевые диски на 10TB, для традиционных СХД наступают совсем тяжелые времена.

На самом же деле, «все гениальное — просто». Вместо использования сложных и медленных RAID систем, данные должны разбиваться на блоки (так называемые extent groups в нашем случае) и просто “размазываться” по кластеру с нужным количеством копий, причем в peer to peer режиме (в русскоговорящем пространстве пример торрентов сразу всем понятен).
Кстати, отсюда вытекает новый для многих (но не для рынка) термин —
RAIN (
Redundant/Reliable
Array of Inexpensive/
Independent
Nodes) — резервируемый / надежный массив из недорогих / независимых нодов.
Ярким представителем данной архитектуры как раз и является Nutanix.
Звучит сложно? Сокращаем: выносим всю логику работы из железа в чисто программную реализацию на стандартном X86-64 оборудовании.
Ровно так-же как делает Google / Facebook / Amazon и прочие.
Какие преимущества?
- Быстрый (очень быстрый) цикл разработки и апдейтов
- Отвязка от зависимостей к пропиетарному оборудованию
- Использование стандартного (“ширпотреб”) оборудования для решения задач любых масштабов.
Распределенные и полностью самодостаточные системы
Идея проста и лежит на поверхности — уходим от концепции выделенных управляющих систем (контроллеры, центральные узлы метаданных, мозг человека, и т.д.) к концепции равномерного распределения одинаковых ролей между множеством элементов (каждый узел — сам себе контроллер, нет выделенных элементов, пчелиный рой).
Перефразируя — чисто распределенная система.
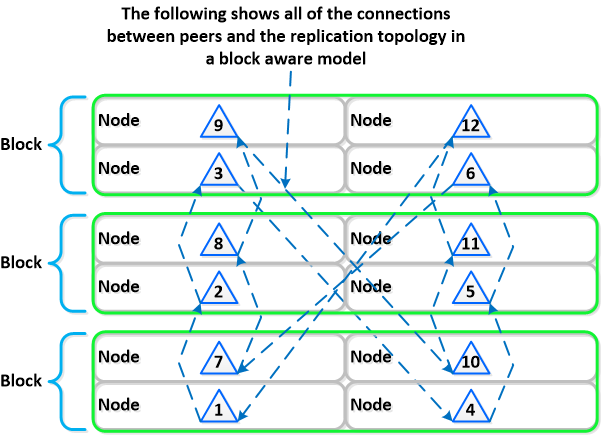
Традиционные производители всегда исходят из того, что оборудование должно быть надежным, что в общем-то в целом возможно (но какой ценой?).
Между тем как для распределенных систем подход принципиально отличается — всегда исходят из того что любое оборудование в итоге откажет и обработка этой ситуации должна быть полностью автоматической, без влияния на жизнеспособность системы.
Мы говорим о «самоизлечивающихся» системах, причем излечение должно происходить максимально быстро.

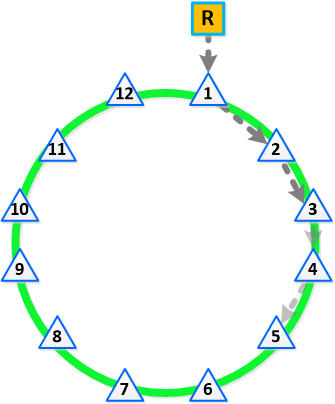
Если логика управления требует координации (так называемые «master» узлы), то выбор оных должен быть полностью автоматическим и любой участник кластера может стать таким мастером.
Что это все означает в реалиях?
- Распределение ролей и ответственностей внутри системы (кластера)
- Использование BigData принципов (такие как MapReduce) для распределения задач
- Процесс «публичных выборов» для обозначения текущего мастера
Линейное расширение с очень точной гранулярностью
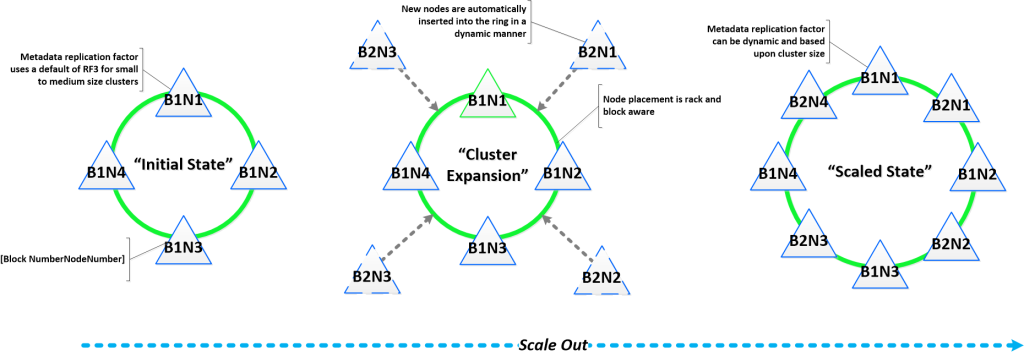
Последовательное и линейное (горизонтальное) расширение обозначает возможность стартовать с определенного количества ресурсов (в нашем случае — 3 узла / нода / сервера) и масштабироваться линейно для получения линейного-же прироста производительности. Все пункты, которые мы обсуждали выше, являются критичными для получения такой возможности.
Как пример, обычно вы имеете трех-уровневую архитектуру (сервера, система хранения данных, сеть), каждый элемент которой масштабируется независимо. Если увеличили число серверов — то СХД и сеть при этом остались старые.
C гипер-конвергентной платформой типа Nutanix, при добавлении каждого нода, вы получите увеличение:
- Количества гипервизоров / компьютинговых нодов
- Количества контроллеров СХД (3 нода = 3 контроллера, 300 нодов = 300 контроллеров, и т.д.)
- Процессорные мощности и емкость СХД
- Количество нод участвующих в решении задач кластера
Сложно? Упрощяем:
- Возможность масштабировать сервера и СХД по одному микро-узлу с соответствующим линейным увеличением производительности, начиная с 3-х и до бесконечности.
Преимущества:
- Возможность стартовать с минимального размера
- Устранение любых «бутылочных горлышек» и точек отказа (да, SLA 100% реален)
- Постоянная и гарантированная производительность при расширении.
…

В следующих статьях мы дадим больше технических подробностей и расскажем, для начала, как работает наша NDFS — распределенная файловая система нового поколения, построенная на ext4 + NoSQL.
Из дополнительных анонсов — наша система управления
KVM, которая работает по тем-же принципам, безлимитно масштабируема и не имеет точек отказа.
Мы будем выступать на
Highload 2014, показывать наши решения «вживую». Приходите.
Хорошего дня!
p.s. да-да, мы обязательно расскажем что мы выбрали из CAP и как решали вопрос Сходимости-Доступности-Партиционирования
p.p.s. (если кто-то дочитал до этого места) для внимательных — конкурс, угадайте как называется наше решение для управления KVM и получите приз (в Москве).