https://habrahabr.ru/company/ruvds/blog/334806/- Разработка веб-сайтов
- Node.JS
- JavaScript
- Блог компании RUVDS.com
Node.js, с момента появления, зависит от JS-движка V8, который обеспечивает исполнение команд языка, который мы все знаем и любим. V8 — это виртуальная машина JavaScript, написанная Google для браузера Chrome. С самого начала V8 создавали для того, чтобы сделать JavaScript быстрым, по крайней мере — обеспечить большую скорость, чем конкурирующие движки. Для динамического языка без строгой типизации достижение высокой производительности — задача непростая. V8 и другие движки развиваются, всё лучше решая эту задачу. Однако, новый движок — это не просто «рост скорости исполнения JS». Это — и необходимость в новых подходах к оптимизации кода. Не всё то, что было сегодня самым быстрым, будет радовать нас максимальной производительностью в будущем. Не всё, что считалось медленным, останется таким.
Как характеристики TurboFan V8 повлияют на то, как будут оптимизировать код? Как техники, считающиеся оптимальными сегодня, покажут себя в недалёком будущем? Как ведут себя «убийцы производительности V8» в наши дни, и чего от них можно ожидать? В этом материале мы постарались найти ответы на эти и многие другие вопросы.
Перед вами — плод совместного труда
Дэвида Марка Клементса и
Маттео Коллины. Материал проверили
Франциска Хинкельманн и
Бенедикт Мейрер из команды разработчиков V8.

Центральная часть движка V8, которая позволяет ему исполнять JavaScript на высокой скорости, это компилятор JIT (Just In Time). Это — динамический компилятор, который может оптимизировать код в процессе его выполнения. Когда V8 только был создан, компилятор JIT назвали FullCodeGen, это был (как справедливо отметил
Ян Го) первый оптимизирующий компилятор для данной платформы. Затем команда V8 создала компилятор Crankshaft, включавший в себя множество оптимизаций производительности, которые не были реализованы в FullCodeGen.
Как человек, который наблюдал за JavaScript с 90-х годов и всё это время пользовался им, я заметил, что часто то, какие участки JS-кода будут работать медленно, а какие быстро, оказывается совершенно неочевидным, независимо от того, какой именно движок используется. Причины, по которым программы исполнялись медленнее, чем ожидалось, часто было сложно понять.
В последние годы я и Маттео Коллина сосредоточились на выяснении того, как писать высокопроизводительный код для Node.js. Естественно, это подразумевает знание того, какие подходы являются быстрыми, а какие — медленными, когда наш код исполняется JS-движком V8.
Теперь пришло время пересмотреть все наши предположения о производительности, так как команда V8 написала новый JIT-компилятор: TurboFan.
Мы собираемся рассмотреть широко известные программные конструкции, которые ведут к отказу от оптимизирующей компиляции. Кроме того, здесь мы займёмся и более сложными изысканиями, направленными на исследование производительности разных версий V8. Всё это будет сделано посредством серии микробенчмарков, запускаемых с использованием разных версий Node и V8.
Конечно, прежде чем оптимизировать код с учётом особенностей V8, мы сначала должны сосредоточиться на дизайне API, алгоритмах и структурах данных. Эти микробенчмарки можно рассматривать как индикаторы того, как меняется исполнение JavaScript в Node. Мы можем использовать эти индикаторы для того, чтобы изменить общий стиль нашего кода и способы, которыми мы улучшаем производительность после применения обычных оптимизаций.
Мы рассмотрим производительность микробенчмарков в версиях V8 5.1, 5.8, 5.9, 6.0, и 6.1.
Для того, чтобы было понятно, как версии V8 связаны с версиями Node, отметим следующее: движок V8 5.1 используется в Node 6, здесь применяется компилятор Crankshaft JIT, движок V8 5.8 используется в версиях Node с 8.0 по 8.2, тут применяется и Crankshaft, и TurboFan.
В настоящий момент ожидается, что в Node 8.3, или, возможно, в 8.4, будет движок V8 версии 5.9 или 6.0. Самая свежая на момент написания этого материала версия V8 — 6.1. Она интегрирована в Node в экспериментальном репозитории
node-v8. Другими словами, V8 6.1, в итоге, окажется в какой-то будущей версии Node.
Код тестов и другие материалы, использованные при подготовке этой статьи, можно найти
здесьВот — документ, в котором, кроме прочего, имеются необработанные результаты испытаний.
Большинство микробенчмарков выполнено на Macbook Pro 2016, 3.3 ГГц Intel Core i7, 16 ГБ 2133 МГц LPDDR3-памяти. Некоторые из них (работа с числами, удаление свойств объектов) были выполнены на MacBook Pro 2014, 3 Ггц Intel Core i7, 16 GB 1600 МГц DDR3-памяти. Замеры производительности для разных версий Node.js выполнялись на одном и том же компьютере. Мы внимательно следили за тем, чтобы на результаты испытаний не повлияли другие программы.
Давайте посмотрим на наши тесты и поговорим о том, что полученные результаты означают для будущего Node. Все испытания выполнялись с использованием пакета
benchmark.js, данные на каждой из диаграмм означают число операций в секунду, то есть, чем полученное значение больше — тем лучше.
Проблема try/catch
Один из хорошо известных шаблонов деоптимизации заключается в использовании блоков
try/catch.
Обратите внимание на то, что здесь и далее в списках описаний испытаний, в скобках, будут даны краткие названия испытаний на английском. Эти названия применяются для обозначения результатов на диаграммах. Кроме того, они помогут сориентироваться в коде, который использовался в ходе тестов.
В этом испытании мы сравним четыре тестовых случая:
- Функция, выполняющая вычисления в блоке
try/catch, расположенном в ней (sum with trу catch).
- Функция, выполняющая вычисления без блоков
try/catch (sum without try catch).
- Вызов функции для выполнения вычислений внутри блока
try (sum wrapped).
- Вызов функции для выполнения вычислений без использования
try/catch (sum function).
→
Код тестов на GitHub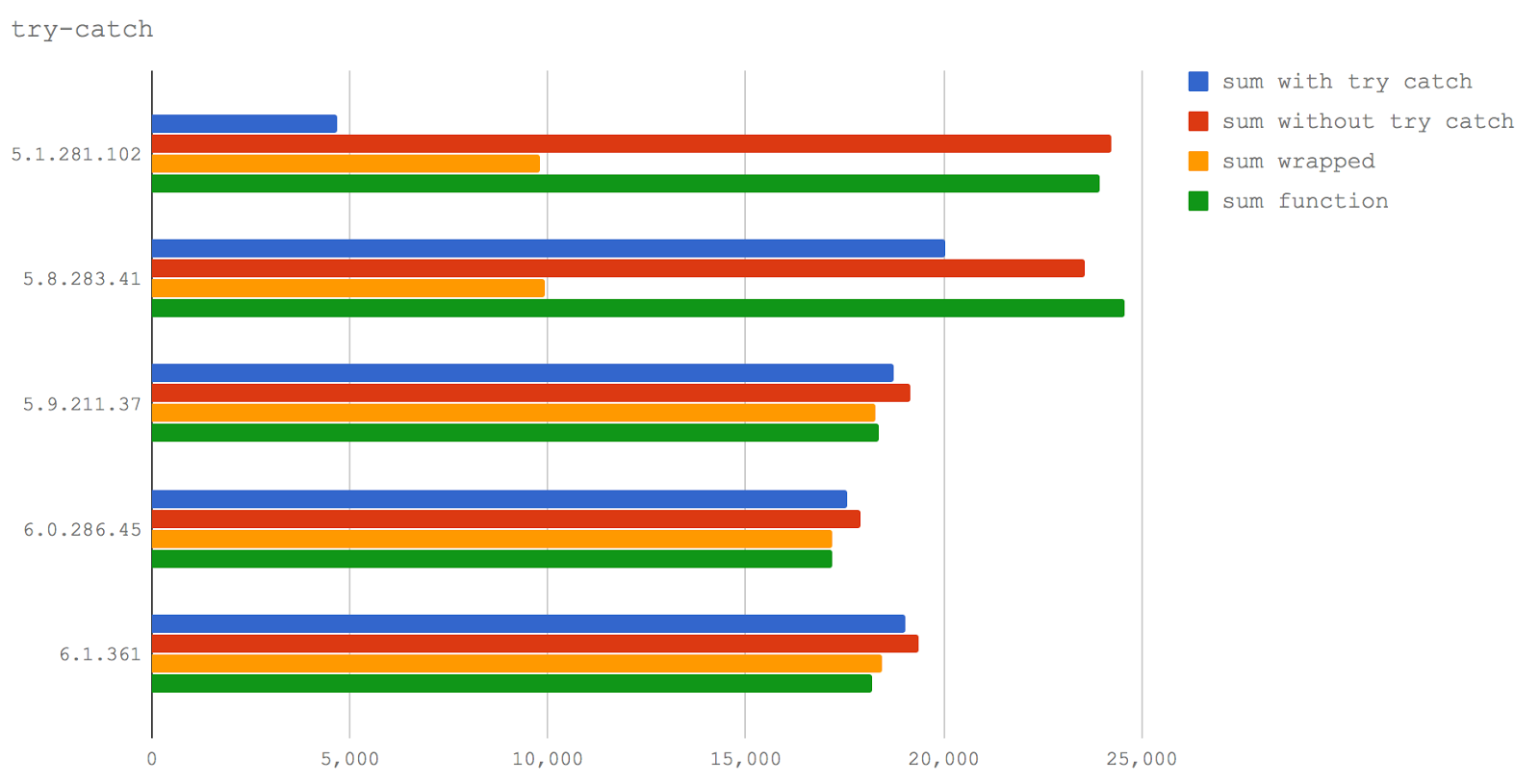
Мы можем видеть, что то, что уже известно о негативном влиянии
try/catch на производительность, подтверждается в Node 6 (V8 5.1), а в Node 8.0-8.2 (V8 5.8)
try/catch оказывает гораздо меньшее влияние на производительность.
Также следует отметить, что вызов функции из блока
try оказывается гораздо более медленным, чем вызов её за пределами
try — это справедливо и для Node 6 (V8 5.1), и для Node 8.0-8.2 (V8 5.8).
Однако, в Node 8.3+ вызов функции из блока
try на производительность практически не влияет.
Тем не менее, не стоит успокаиваться. Работая над некоторыми материалами для семинара по оптимизации, мы обнаружили
ошибку, когда довольно специфическое стечение обстоятельств может привести к бесконечному циклу деоптимизации/реоптимизации в TurboFan. Это вполне можно считать очередным шаблоном-убийцей производительности.
Удаление свойств из объектов
Многие годы команду
delete избегал любой, кто хотел писать высокопроизводительный код на JS (ну, по крайней мере, в случаях, когда надо было написать оптимальный код для самых нагруженных частей программ).
Проблема с
delete сводится к тому, как V8 обходится с динамической природой объектов JavaScript, и с цепочками прототипов (также потенциально динамическими), которые усложняют поиск свойств на низком уровне реализации движка.
Подход движка V8 к созданию высокопроизводительных объектов со свойствами заключается в создании класса на уровне C++, основываясь на «форме» объекта, то есть — на том, какие ключи и значения имеет объект (включая ключи и значения цепочки прототипов). Эти конструкции известны как «скрытые классы». Однако, этот тип оптимизации производится во время выполнения программы. Если же нет уверенности по поводу формы объекта, у V8 имеется ещё один режим поиска свойств: поиск по хэш-таблице. Такой поиск свойств гораздо медленнее.
Исторически сложилось так, что когда мы удаляем командой
delete ключ из объекта, последующие операции доступа к свойствам будут выполняться методом поиска в хэш-таблице. Именно поэтому программисты команду
delete стараются не использовать, вместо этого устанавливая свойства в
undefined, что, в плане уничтожения значения, ведёт к тому же результату, но добавляет сложностей при проверке существования свойства. Однако, обычно такой подход достаточно хорош, например, при подготовке объектов к сериализации, так как
JSON.stringify не включает значения
undefined в свой вывод (
undefined, в соответствии со спецификацией JSON, не относится к допустимым значениям).
Теперь давайте выясним, решает ли новая реализация TurboFan проблему удаления свойств из объектов.
Тут мы сравним три тестовых случая:
- Сериализация объекта после того, как его свойство было установлено в
undefined (setting to undefined).
- Сериализация объекта после того, как для удаления его свойства была использована команда
delete (delete).
- Сериализация объекта после того, как команда
delete была использована для удаления свойства, которое было добавлено позже всего (delete last property).
→
Код тестов на GitHub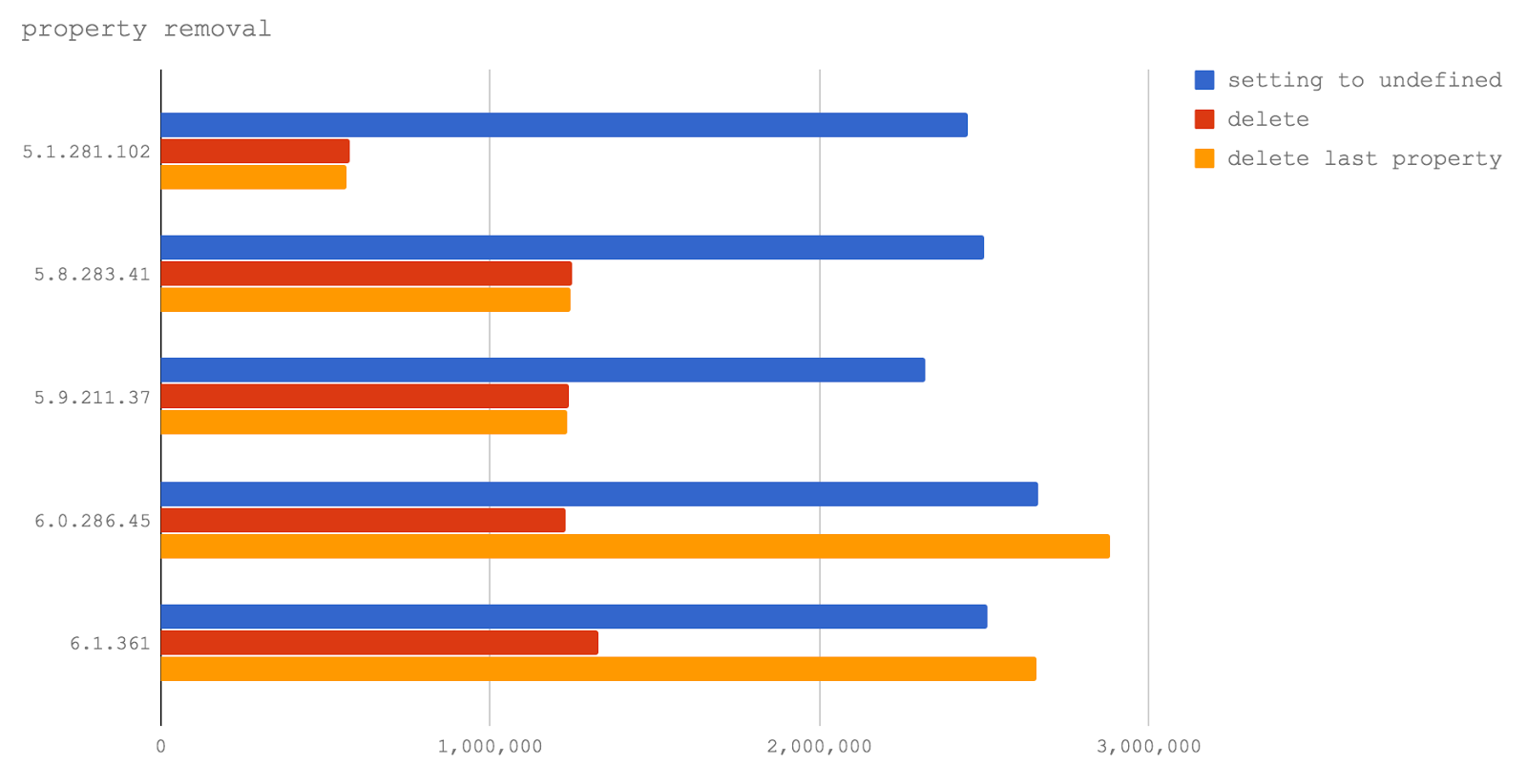
В V8 6.0 и 6.1 (они ещё не используются ни в одном из релизов Node), удаление последнего свойства, добавленного к объекту, соответствует оптимизированному TurboFan пути выполнения программы, и, таким образом, выполняется даже быстрее, чем установка свойства в
undefined. Это очень хорошо, так как говорит о том, что команда разработчиков V8 работает над улучшением производительности команды
delete.
Однако, использование этого оператора всё ещё приводит к серьёзному падению производительности при доступе к свойствам, если из объекта было удалено свойство, которое не является последним из добавленных. Это наблюдение нам помог сделать
Якоб Куммеров, указавший на особенность наших тестов, в которых был исследован лишь вариант с удалением последнего добавленного свойства. Выражаем ему благодарность. В итоге, как ни хотелось бы нам сказать, что команду
delete можно и нужно использовать в коде, написанном для будущих релизов Node, мы вынуждены рекомендовать этого не делать. Команда
delete продолжает негативно влиять на производительность.
Утечка и преобразование в массив объекта arguments
Типичная проблема с неявно создаваемым объектом
arguments, доступным в обычных функциях (в противовес им, стрелочные функции объекта
arguments не имеют), заключается в том, что он похож на массив, но массивом не является.
Для того, чтобы использовать методы массивов или особенности их поведения, индексируемые свойства
arguments необходимо скопировать в массив. В прошлом у JS-разработчиков была склонность ставить знак равенства между более коротким и более быстрым кодом. Хотя такой подход, в случае клиентского кода, позволяет достичь снижения объёма данных, которые должен загрузить браузер, то же самое может повлечь проблемы с серверным кодом, где размер программ гораздо менее важен, нежели скорость их выполнения. В результате, соблазнительно короткий способ преобразовать объект
arguments в массив стал весьма популярным:
Array.prototype.slice.call(arguments). Такая команда вызывает метод
slice объекта
Array, передавая объект
arguments как контекст
this для этого метода. Метод
slice видит объект, который похож на массив, после чего делает своё дело. В результате мы получаем массив, собранный из содержимого объекта
arguments, похожего на массив.
Однако, когда неявно создаваемый объект
arguments передаётся чему-либо, находящемуся вне контекста функции (например, если его возвращают из функции или передают другой функции, как при вызове
Array.prototype.slice.call(arguments)), обычно это вызывает падение производительности. Исследуем это утверждение.
Следующий микробенчмарк нацелен на исследование двух взаимосвязанных ситуаций в четырёх версиях V8. А именно, это цена утечки
arguments и цена копирования
arguments в массив, который потом передаётся за пределы функции вместо объекта
arguments.
Вот наши тестовые случаи:
- Передача объекта
arguments другой функции без преобразования arguments в массив (leaky arguments).
- Создание копии объекта
arguments с использованием конструкции Array.prototype.slice (Array.prototype.slice arguments).
- Использование цикла
for и копирование каждого свойства (for-loop copy arguments)
- Использование оператора расширения из EcmaScript 2015 для того, чтобы назначить массив входных данных функции ссылке (spread operator).
→
Код тестов на GitHub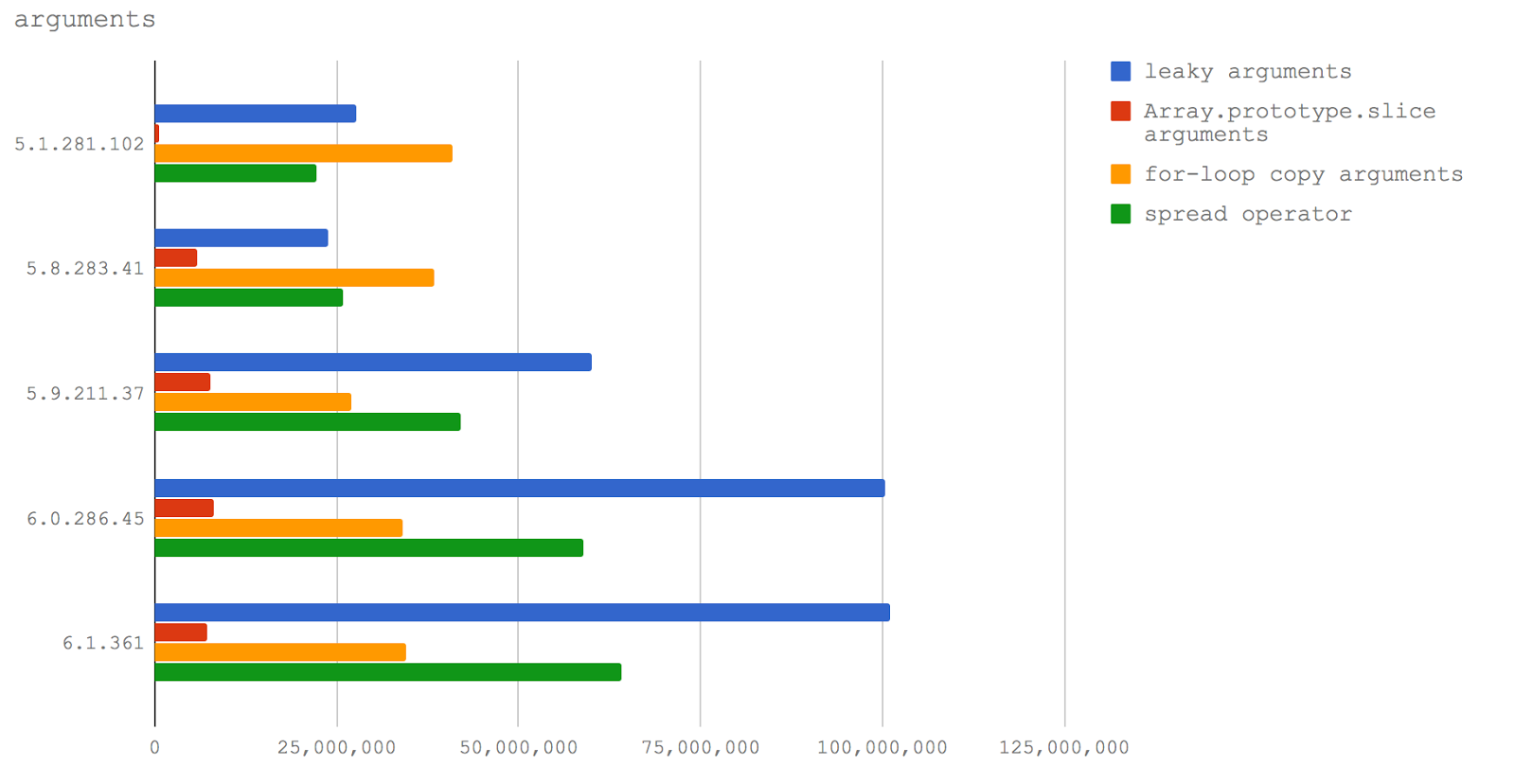
Взглянем теперь на те же самые данные, представленные в форме линейного графика для того, чтобы подчеркнуть изменения в характеристиках производительности.
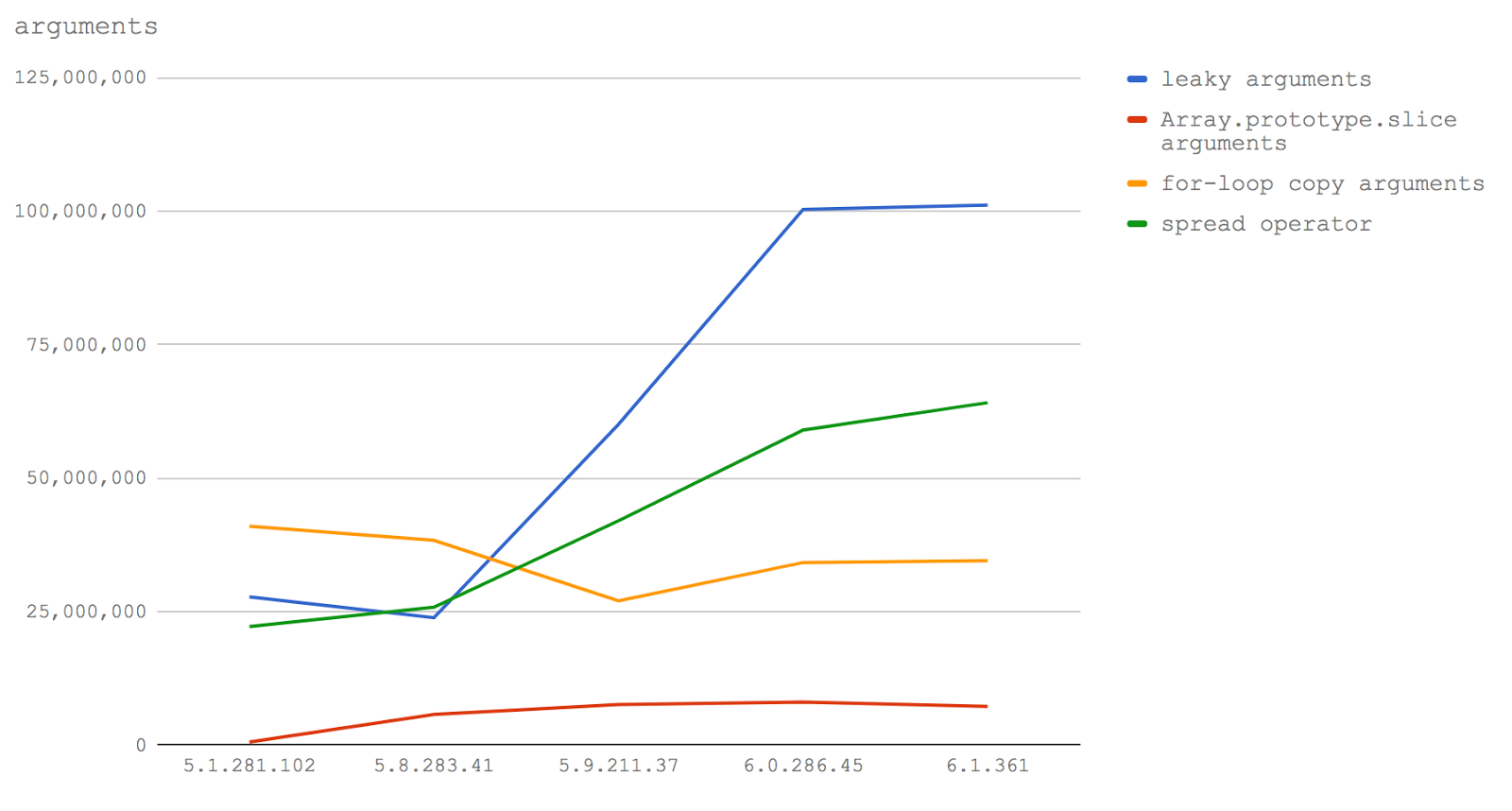
Вот какие выводы можно из всего этого сделать. Если нужно писать производительный код, предусматривающий обработку входных данных функции в виде массива (что, по опыту знаю, нужно довольно часто), то в Node 8.3 и выше нужно использовать оператор расширения. В Node 8.2 и ниже следует использовать цикл
for для копирования ключей из
arguments в новый (заранее созданный) массив (подробности вы можете увидеть в коде тестов).
Далее, в Node 8.3+ падения производительности при передаче объекта
arguments в другие функции не происходит, поэтому тут могут быть другие преимущества в плане производительности, если нам не нужен полный массив и можно работать со структурой, похожей на массив, но массивом не являющейся.
Частичное применение (каррирование) и привязка контекста функций
Частичное применение (или каррирование) функций позволяет сохранить некое состояние в областях видимости вложенного замыкания.
Например:
function add (a, b) {
return a + b
}
const add10 = function (n) {
return add(10, n)
}
console.log(add10(20))
В этом примере параметр
a функции
add частично применён как число 10 в функции
add10.
Более краткая форма частичного применения функции стала доступна начиная с EcmaScript 5 благодаря методу
bind:
function add (a, b) {
return a + b
}
const add10 = add.bind(null, 10)
console.log(add10(20))
Однако, обычно метод
bind не используют, так как он ощутимо медленнее, чем вышеописанный способ с замыканием.
В нашем испытании измеряется разница между использованием
bind и замыкания в различных версиях V8. Для сравнения здесь же используется непосредственный вызов исходной функции.
Вот четыре тестовых случая.
- Функция, которая вызывает другую функцию с предварительным частичным применением первого аргумента (curry).
- Стрелочная функция, которая вызывает другую функцию с частично применённым первым аргументом (fat arrow curry).
- Функция, созданная с помощью метода
bind, который частично применяет первый аргумент другой функции (bind).
- Непосредственный вызов функции без использования частичного применения (direct call).
→
Код тестов на GitHub
Линейная диаграмма результатов испытаний чётко показывает практически полное отсутствие различий между рассмотренными методами работы с функциями в последних версиях V8. Что интересно, частичное применение с использованием стрелочных функций значительно быстрее, чем использование обычных функций (как минимум, в наших тестах). На самом деле, оно практически совпадает с непосредственным вызовом функции. В V8 5.1 (Node 6) и 5.8 (Node 8.0-8.2)
bind очень медленный, и выглядит очевидным, что использование стрелочных функций для этих целей позволяет достичь самой высокой скорости. Однако, производительность при использовании
bind, начиная с V8 версии 5.9 (Node 8.3+) значительно растёт. Такой подход оказывается самым быстрым (хотя, разница в производительности тут практически неразличима) в V8 6.1 (Node будущих версий).
Самым быстрым способом каррирования во всех версиях Node оказывается применение стрелочных функций. В последних версиях разница между этим способом и применением
bind несущественна, в текущих же условиях это быстрее, чем использование обычных функций. Однако, мы не можем говорить о том, что полученные результаты справедливы в любых ситуациях, так как нам, вероятно, надо исследовать больше типов частичного применения функций со структурами данных различных размеров для того, чтобы получить более полную картину.
Размер кода функции
Размер функции, включая её сигнатуру, пробелы и даже комментарии, может повлиять на то, может ли V8 сделать функцию встроенной, или нет. Да, это так: добавление комментариев к функции может примерно на 10% снизить производительность. Изменится ли это в будущем?
В данном испытании мы исследуем три сценария:
- Вызов функции маленького размера (sum small function).
- Работа маленькой функции, дополненной комментариями, выполняемой во встроенном режиме (long all together).
- Вызов большой функции с комментариями (sum long function).
→
Код тестов на GitHub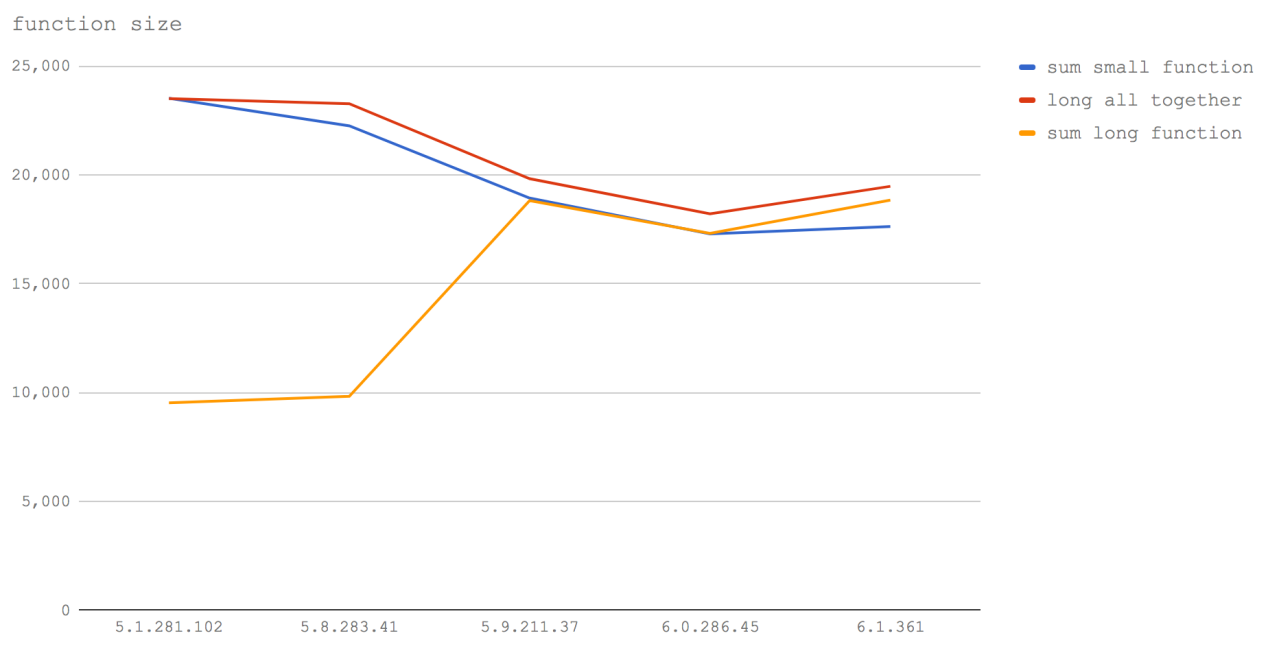
В V8 5.1 (Node 6) тесты sum small function и long all together показывают один и тот же результат. Это отлично иллюстрирует то, как работает встраивание. Когда мы вызываем маленькую функцию, это аналогично тому, что V8 записывает содержимое данной функции в место, откуда её вызывают. Поэтому, когда мы пишем текст функции (даже с добавлением комментариев), мы вручную встраиваем её в место вызова и производительность оказывается одной и той же. Опять же, в V8 5.1 (Node 6) можно видеть, что вызов функции, дополненной комментариями, после достижения функцией определённого размера, ведёт к значительно более медленному выполнению кода.
В Node 8.0-8.2 (V8 5.8) ситуация, в целом, остаётся такой же, за исключением того, что стоимость вызова маленькой функции заметно выросла. Это, вероятно, из-за смешивания элементов Crankshaft и TurboFan, когда одна функция может быть в Crankshaft, а другая — в TurboFan, что приводит к разладу механизмов встраивания (то есть, должен произойти переход между кластерами последовательно встроенных функций).
В V8 5.9 и выше (Node 8.3+) добавление посторонних символов, таких, как пробелы или комментарии, не влияет на производительность функций. Это происходит из-за того, что TurboFan использует для вычисления размера функции абстрактное синтаксическое дерево (AST,
Abstract Syntax Tree), вместо того, чтобы как Crankshaft, считать символы. Вместо того, чтобы принимать во внимание число байтов функции, TurboFan анализирует реальные инструкции функции, поэтому начиная с V8 5.9 (Node 8.3+)
пробелы, символы, из которых составлены имена переменных, сигнатуры функций и комментарии больше не влияют на то, может ли функция быть встроенной. Кроме того, нельзя не заметить то, что общая производительность функций снижается.
Основной вывод тут заключается в том, что функции всё ещё стоит делать как можно меньшего размера. В настоящий момент всё ещё нужно избегать излишних комментариев (и даже пробелов) внутри функций. Кроме того, если вы стремитесь к максимальной производительности, ручное встраивание функций (то есть, перенос кода функций в место вызова, что освобождает от необходимости вызова функций) стабильно остаётся самым быстрым подходом. Конечно, тут надо соблюдать баланс, так как, после достижения реальным исполняемым кодом определённого размера, функция всё равно встроена не будет, поэтому бездумное копирование кода других функций в свою может вызвать проблемы с производительностью. Другими словами, ручное встраивание функций — это потенциальный «выстрел в ногу». В большинстве случаев встраивание функций лучше доверить компилятору.
32-битные и 64-битные целые числа
Хорошо известно, что в JavaScript есть лишь один числовой тип:
Number.
Однако, V8 реализован на C++, поэтому базовый тип числового значения JavaScript — это вопрос выбора.
В случае с целыми числами (то есть, тогда, когда мы задаём числа в JS без десятичной точки), V8 считает все числа 32-х битными — до тех пор, пока они перестанут таковыми являться. Это кажется вполне справедливым выбором, так как во многих случаях числа находятся в диапазоне 2147483648 -2147483647. Если JS-число (целиком) превышает 2147483647, JIT-компилятору приходится динамически менять базовый тип числового значения на тип с двойной точностью (с плавающей запятой) — это может, в потенциале, оказать определённое влияние на другие оптимизации.
В этом испытании мы рассмотрим три сценария:
- Функция, которая работает лишь с числами, укладывающимися в 32-битный диапазон (sum small).
- Функция, которая работает с комбинацией 32-битных чисел и чисел, для представления которых требуется тип данных двойной точности (from small to big).
- Функция, которая оперирует лишь числами с двойной точностью (all big).
→
Код тестов на GitHub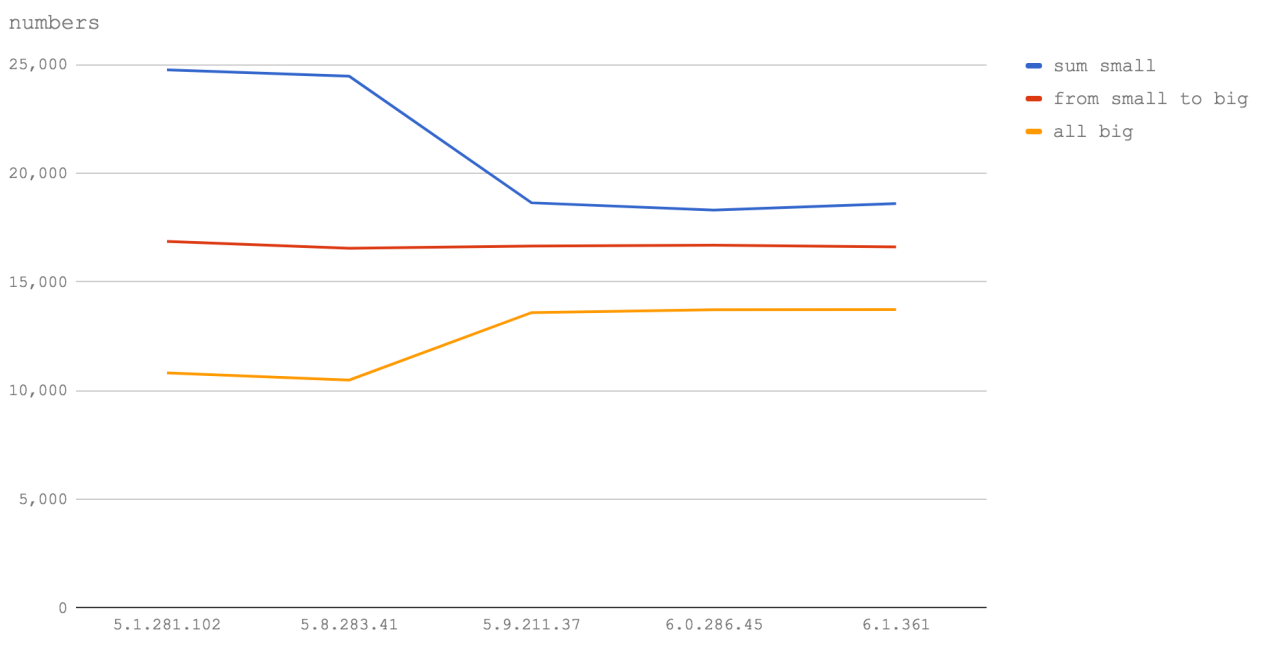
Диаграмма позволяет говорить о том, что, идёт ли речь о Node 6 (V8 5.1), или о Node 8 (V8 5.8), или даже о будущих версиях Node, вышеописанное наблюдение остаётся справедливым. А именно, оказывается, что вычисления с использованием целых чисел, превышающих 2147483647, приводят к тому, что функции исполняются со скоростью, находящейся в районе половины или двух третей от максимальной. Поэтому, если у вас есть длинные цифровые ID — помещайте их в строки.
Кроме того, очень заметно, что операции с числами, укладывающимися в 32-битный диапазон, выполняются гораздо быстрее в Node 6 (V8 5.1), а также в Node 8.1 и 8.2 (V8 5.8), чем в Node 8.3+ (V8 5.9+). Однако, операции над числами двойной точности в Node 8.3+ (V8 5.9+) выполняются быстрее. Вероятно, это так из-за замедления в обработке 32-битных чисел, и не относится к скорости вызова функций или циклов
for, которые используются в коде тестов.
Якоб Куммеров,
Ян Го и команда V8 помогли нам сделать результаты этого испытания правильнее и точнее. Мы благодарны им за это.
Перебор свойств объектов
Взятие значений всех свойств объекта и выполнение с ними каких-то действий — распространённая задача. Существует множество способов её решения. Выясним, какой из способов самый быстрый в исследуемых версиях V8 и Node.
Вот четыре испытания, которым подверглись все исследуемые версии V8:
- Использование цикла
for-in с применением hasOwnProperty для определения того, является ли свойство свойством объекта (for-in).
- Использование
Object.keys и перебор ключей с использованием метода reduce объекта Array. Доступ к значениям свойств осуществляется внутри функции-итератора, переданной reduce (Object.keys functional).
- Использование
Object.keys и перебор ключей с использованием метода reduce объекта Array. Доступ к значениям свойств осуществляется внутри стрелочной функции-итератора, переданной reduce (Object.keys functional with arrow).
- Перебор массива, возвращённого из
Object.keys, в цикле for. Доступ к значениям свойств объекта осуществляется в том же цикле (Object.keys with for loop).
Кроме того, мы провели три дополнительных теста для V8 версий 5.8, 5.9, 6.0 и 6.1:
- Использование
Object.values и перебор значений свойств объекта с использованием метода reduce объекта Array (Object.values functional).
- Использование
Object.values и перебор значений с использованием метода reduce объекта Array, при этом функция-итератор, переданная методу reduce, была стрелочной функцией (Object.values functional with arrow).
- Перебор массива, возвращённого из
Object.values, в цикле for (Object.values with for loop).
Мы не проводили эти тесты в V8 5.1 (Node 6), так как эта версия не поддерживает встроенного метода EcmaScript 2017
Object.values.
→
Код тестов на GitHub
В Node 6 (V8 5.1) и Node 8.0-8.2 (V8 5.8) использование цикла
for-in, без сомнения, является самым быстрым способом перебора ключей объекта, и затем — доступа к значениям его свойств. Этот способ даёт примерно 40 миллионов операций в секунду, что в 5 раз быстрее, чем при использовании ближайшего по производительности подхода, предусматривающего использование
Object.keys, и дающего примерно 8 миллионов операций в секунду.
В V8 6.0 (Node 8.3) с циклом
for-in что-то случилось и производительность упала до всего четвёртой части скорости, достижимой в предыдущих версиях. Однако, это подход остался самым производительным.
В V8 6.1 (то есть, в будущих версиях Node), производительность метода, использующего
Object.keys, растёт, этот метод оказывается быстрее метода с циклом
for-in, однако, скорость пока даже не приближается к тем результатам, которые были характерны для
for-in в V8 5.1 и 5.8 (Node 6, Node 8.0-8.2).
Кажется, что движущая сила TurboFan — это стремление к оптимизации конструкций, характерных для интуитивного подхода к программированию. Таким образом, оптимизация производится для вариантов использования, наиболее удобных для разработчика.
Применение
Object.values для прямого получения значений свойств медленнее, чем использование
Object.keys и доступ к значениям объектов по ключам. Кроме того, процедурные циклы оказываются быстрее, чем функциональный подход. Таким образом, при таком подходе может понадобиться больше работы, когда дело доходит до перебора свойств объектов.
Кроме того, для тех, кто привык пользоваться циклом
for-in из-за его высокой производительности, текущее состояние дел может оказаться весьма неприятным. Значительная часть скорости теряется, а никакой доступной альтернативы нам не предлагают.
Создание объектов
Создание объектов в JS — это то, что происходит постоянно, поэтому данный процесс исследовать будет очень полезно.
Мы собираемся провести три набора тестов:
- Создание объектов с использованием объектного литерала (literal).
- Создание объектов на основе класса EcmaScript 2015 (class).
- Создание объектов с помощью функции-конструктора (constructor).
→
Код тестов на GitHub
В Node 6 (V8 5.1) все подходы показывают примерно одинаковые результаты.
В Node 8.0-8.2 (V8 5.8), при создании объектов из классов EcmaScript 2015, производительность составляет менее половины той, которая достижима с использованием объектных литералов или функций-конструкторов. Как вы понимаете, вполне очевидно, чем стоит пользоваться в этих версиях Node.
В V8 5.9 разные способы создания объектов снова показывают одну и ту же производительность.
Затем, в V8 6.0 (надеемся, это будет Node 8.3 или 8.4) и 6.1 (пока эта версия V8 не ассоциируется ни с одним будущим релизом Node), скорость создания объектов оказывается просто сумасшедшей. Более 500 миллионов операций в секунду! Это просто потрясающе.
Но даже тут можно видеть, что создание объектов с помощью конструктора выполняется немного медленнее. Поэтому мы полагаем, что и в будущем самым производительным кодом окажется тот, где используют литералы объектов. Это нам подходит, так как мы, в качестве общего правила, рекомендуем возвращать из функций литералы объектов (а не использовать классы и конструкторы).
Надо сказать, что Якоб Куммеров отметил
здесь, что TurboFan способен оптимизировать выделение объектов в нашем микробенчмарке. Мы планируем это исследовать и обновить результаты испытаний.
Полиморфные и мономорфные функции
Если мы всегда передаём в функцию аргумент одного и того же типа (скажем, это строка), это значит, что мы используем функцию мономорфно. Но некоторые функции рассчитаны на полиморфизм. Это означает, что один и тот же параметр может быть представлен различными скрытыми классами. Возможно, он может обрабатываться, как строка, или как массив, или как какой-то произвольный объект. Такой подход позволяет, в некоторых ситуациях, создавать приятные программные интерфейсы, но плохо влияет на производительность. Испытаем полиморфное и мономорфное использование функций.
Мы собираемся исследовать пять тестовых случаев:
- Функции передаются и объекты, созданные с использованием литералов, и строки (polymorphic with literal).
- Функции передаются и объекты, созданные с помощью конструктора, и строки (polymorphic with constructor).
- Функции передаются только строки (monomorphic string).
- Функции передаются только объекты, созданные с помощью литералов (monomorphic obj literal).
- Функции передаются только объекты, созданные с помощью конструктора (monomorphic obj with constructor).
→
Код тестов на GitHub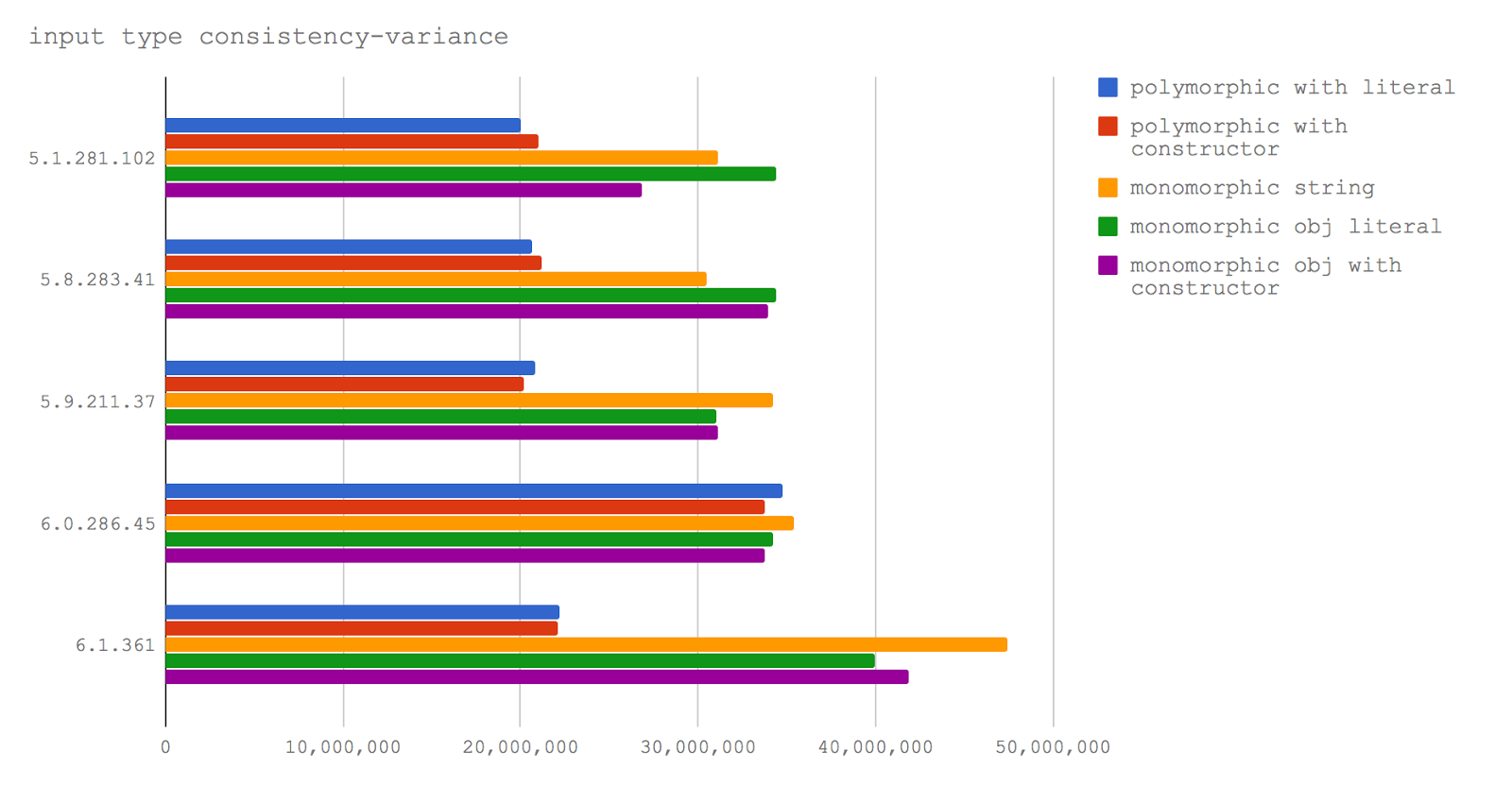
Данные на диаграмме убедительно показывают то, что мономорфные функции работают быстрее полиморфных во всех исследованных версиях V8.
Разрыв в производительности между мономорфными и полиморфными функциями в V8 6.1 (в движке, который получит одна из будущих версий Node) особенно велик, что усугубляет ситуацию. Однако, стоит отметить, что этот тест использует экспериментальную ветку node-v8, в которой применяется нечто вроде «ночной сборки» V8, поэтому данный результат вполне может не соответствовать реальным характеристикам V8 6.1.
При написании кода, который должен быть оптимальным, то есть, речь идёт о функции, которая будет постоянно вызываться, полиморфизма следует избегать. С другой стороны, если функцию вызывают раз или два, скажем, эта функция используется для подготовки программы к работе, полиморфные API вполне приемлемы.
По поводу этого испытания хотим отметить, что команда V8 сообщила нам о том, что им не удалось надёжно воспроизвести результаты этого теста, используя их внутреннюю систему исполнения,
d8. Однако, эти тесты удаётся воспроизвести на Node. Результаты теста следует рассматривать, исходя из предположения, что ситуация может измениться в обновлениях Node (основываясь на том, как Node интегрируется с V8). Этот вопрос требует дополнительного анализа. Благодарим Якоба Куммерова за то, что обратил на это наше внимание.
Ключевое слово debugger
И, наконец, поговорим о ключевом слове
debugger.
Не забудьте убрать это ключевое слово из продакшн-кода. Иначе ни о какой производительности и речи быть не может.
Тут мы исследовали два тестовых случая:
- Функция, которая содержит ключевое слово
debugger (with debugger).
- Функция, которая не содержит ключевое слово
debugger (without debugger).
→
Код тестов на GitHub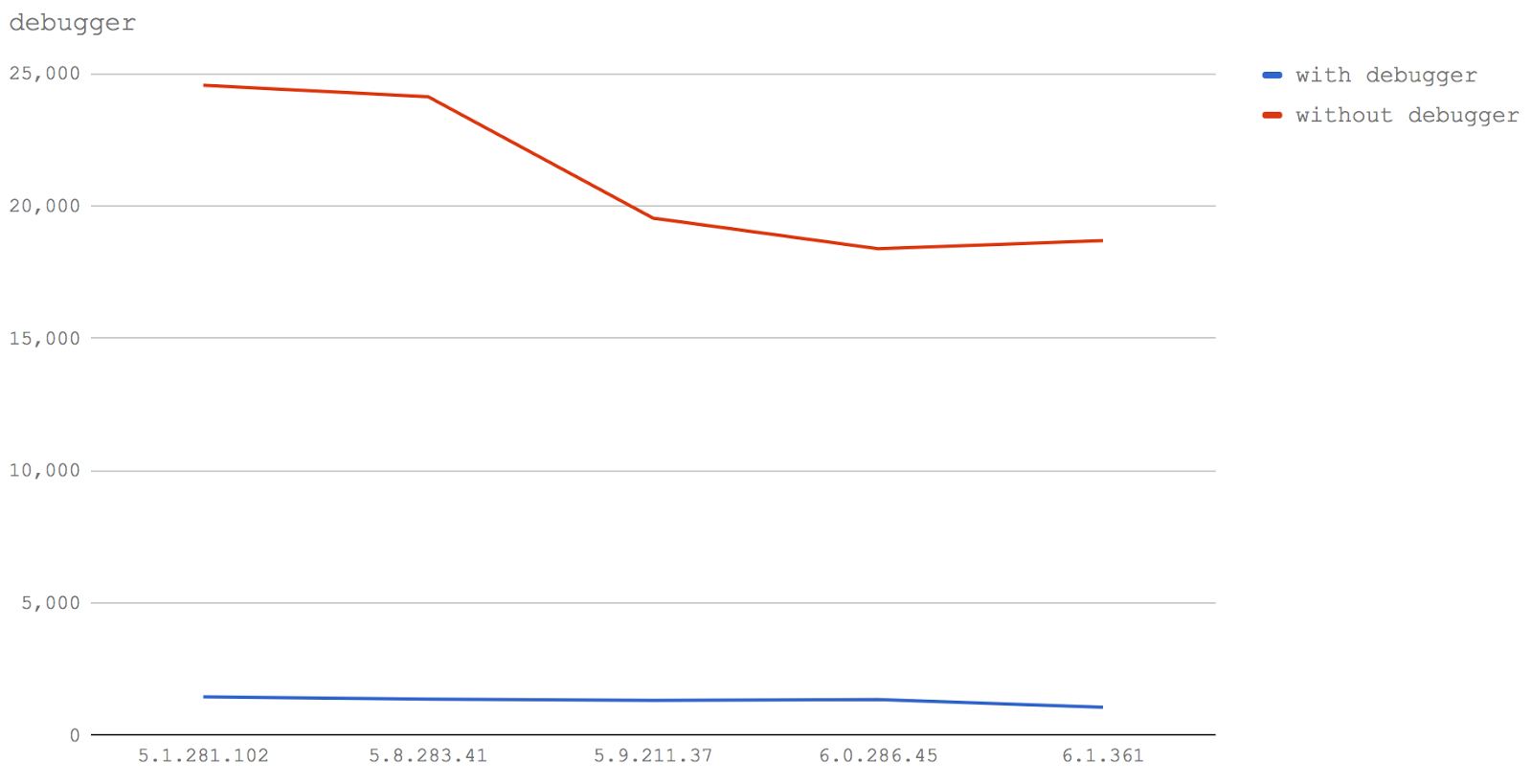
Говорить тут особо нечего. Все версии V8 показывают сильнейшее падение производительности при использовании ключевого слова
debugger.
Тут можно обратить внимание на то, что линия графика для теста without debugger заметно идёт вниз в более свежих версиях V8.
Испытание на реальной задаче: сравнение логгеров
В дополнение к микробенчмаркам, мы можем взглянуть на то, как разные версии V8 решают практические задачи. Для этого используем несколько популярных логгеров для Node.js, которые мы с Маттео исследовали, создавая логгер
Pino.
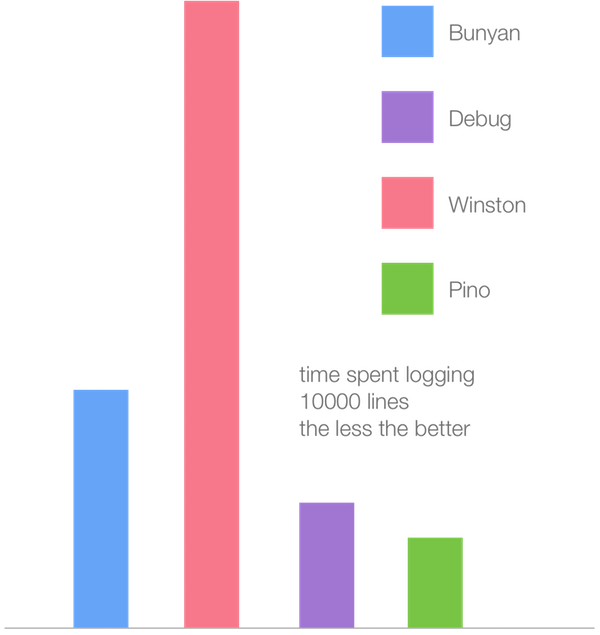
На нижеприведённой гистограмме показано время, необходимое наиболее популярным логгерам для вывода 10 тысяч строк (чем столбик ниже — тем лучше) в Node.js 6.11 (Crankshaft).
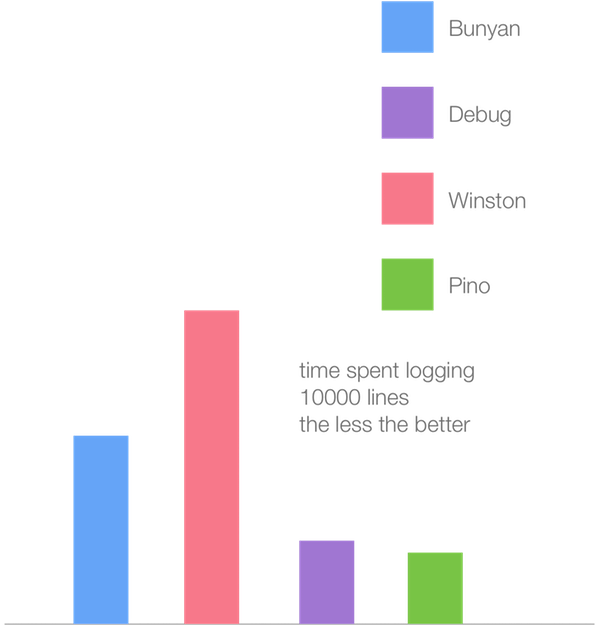
Вот — то же самое, но уже с использованием V8 6.1 (TurboFan).
В то время, как все логгеры показали примерно двукратный рост производительности, Winston извлёк максимум пользы из нового JIT-компилятора TurboFan. Похоже, в данном случае на производительность повлияли сразу несколько факторов, которые, по отдельности, проявлялись в наших микробенчмарках. Самые медленные способы работы в Crankshaft оказываются значительно быстрее в TurboFan, в то время как то, что быстрее всего работает при использовании Crankshaft, оказывается в TurboFan немного медленнее. Логгер Winston, который был самым неторопливым, вероятно, использует техники, которые являются самыми медленными в Crankshaft, но оказываются гораздо быстрее в TurboFan. В то же время, Pino оптимизирован в расчёте на максимальную производительность в Crankshaft. Он показывает сравнительно небольшой прирост производительности.
Итоги
Некоторые из тестов показывают, что то, что было медленным в V8 5.1, 5.8 и 5.9, оказывается быстрее благодаря полноценному использованию TurboFan в V8 6.0 и 6.1. В то же время, то, что было самым быстрым, теряет в производительности, нередко показывая те же результаты, что и более медленные варианты после роста их скорости.
В основном это связано со стоимостью выполнения вызовов функций в TurboFan (V8 6.0 и выше). Основная идея при работе над TurboFan заключалась в оптимизации того, что используется наиболее часто, а так же в том, чтобы существующие «убийцы производительности V8» не влияли бы слишком сильно на скорость выполнения программ. Это привело к общему росту производительности браузерного (Chrome) и серверного (Node) кода. Компромисс, похоже, заключается в падении производительности тех подходов, которые ранее были самыми быстрыми. Надеемся, это временное явление. При сравнении производительности логгеров было выяснено, что общий эффект от использования TurboFan заключается в значительном росте производительности приложений с очень разной кодовой базой (например, это касается Winston и Pino).
Если вы какое-то время наблюдаете за ситуацией вокруг производительности JavaScript, приспособились к странностям движков, сейчас уже почти пришло то время, когда вам стоит обновить свои знания в этой области, взять на вооружение кое-что новое, и кое-что забыть. Если вы стремитесь к написанию качественного JS-кода, значит, благодаря трудам команды V8, ожидайте роста производительности ваших приложений.
Уважаемые читатели! Какие подходы к оптимизации JavaScript используете вы?