http://habrahabr.ru/post/243945/
Мы создаем новое поколение веб-приложения Netflix.com, использующего node.js. Вы можете узнать больше о нашем походе из
презентации, которую мы представили на NodeConf.eu несколько месяцев назад. Сегодня я хочу поделиться накопленным опытом в настройке производительности нового стека нашего приложения.
Мы впервые столкнулись с проблемами, когда заметили, что задержка запроса в нашем node.js приложении со временем увеличивается. К тому же оно использовало больше ресурсов процессора, чем мы ожидали, и это коррелировало с временем задержки. Нам приходилось использовать перезагрузку как временное решение, пока мы искали причину с помощью новых инструментов и техник аналитики производительности в нашей Linux EC2 среде.
Огонь разгорается
Мы заметили, что задержка запроса в нашем node.js приложении со временем увеличивается. Так, на некоторых из наших серверах задержка вырастала с 1 миллисекунды до 10 миллисекунд каждый час. Мы также видели зависимость увеличения использования ресурсов процессора.
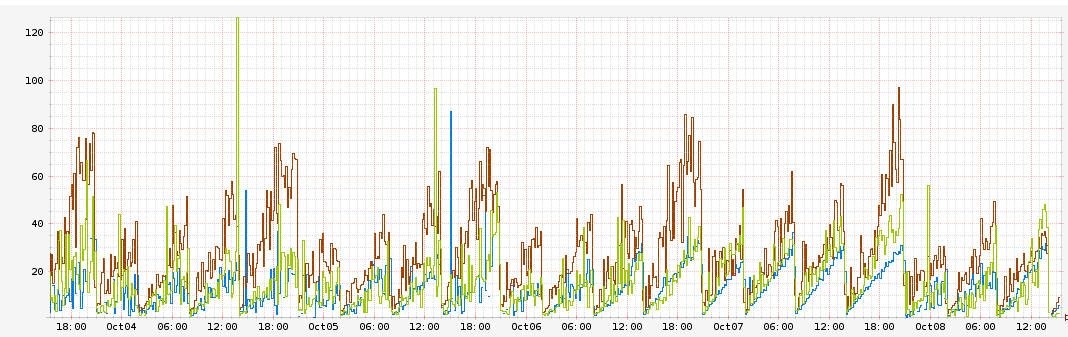
Этот график демонстрирует длительность задержки запроса в миллисекундах относительно времени. Каждый цвет обозначает различный экземпляр AWS AZ. Вы можете увидеть, что задержка постоянно возрастает на 10 миллисекунд в час и достигает 60 миллисекунд перед перезагрузкой.
Тушение огня
Изначально мы предположили, что это могут быть утечки памяти в наших собственных обработчиках запросов, которые, в свою очередь, вызывали задержки. Мы проверили это предположение, с помощью нагрузочного тестирования изолированного приложения добавив метрики для измерения задержек только на наших обработчиках запросов и общей длительности задержки запросов, также увеличив размер используемой памяти в node.js до 32 гигабайт.
Мы выяснили, что задержка в наших обработчиках остается постоянной и равняется 1 миллисекунде. Также мы установили, что размер затрачиваемой памяти процессом тоже остается неизменным, достигая примерно 1.2 гигабайта. Тем не менее общая задержка и использование процессора продолжало расти. Это означало, что наши обработчики тут ни при чем, а проблемы находятся глубже в стеке.
Что-то добавляло дополнительные 60 миллисекунд к обслуживанию запроса. Нам был нужен способ для профилирования использования процессора приложением и визуализация полученных данных. На помощь нам пришли Linux
Perf Events и flame graphs процессора.
Если вы не знакомы с flame graphs, то я советую вам прочитать
отличную статью Брендана Грегга, в которой он все подробно обьясняет. Вот её краткое содержание (прямо из статьи):
- Каждый блок обозначает функцию в стеке (стек фрейм)
- Ось Y обозначает глубину стека (количество фреймов в стеке). Верхний блок обозначает функцию, которая выполнялась процессором, все, что ниже – это стек её вызова.
- Ось X обозначает количество вызовов функции. На ней не показывается количество затраченного функцией времени, как на большинстве графиков. Порядок расположения не имеет значения, блоки просто отсортированы в лексикографическом порядке.
- Ширина блока показывает общее время выполнения функции процессором или часть времени выполнения вызвавшей её функции. Широкие блоки функций могут выполняться медленнее, чем узкие, а могут просто вызываться чаще.
- Количество вызовов может превышать время, если функция выполнялась в несколько потоков.
- Цвета не имеют особого значения и определяются в произвольном порядке из «теплых» тонов. Flame graphs [дословно «графики пламени»; прим. переводчика] называются так потому, что показывают самые «горячие» места в коде приложения.
Ранее node.js flame graphs можно было использовать только в системах с DTrace совместно с
jstack() от Дейва Пачеко. Однако недавно команда Google V8 добавила поддержку perf_events в движок V8, которая позволяет профилировать JavaScript на Linux. В
этой статье Брендан описал использование новой возможности, которая появилась в node.js 0.11.13 для создания flame graphs в Linux.
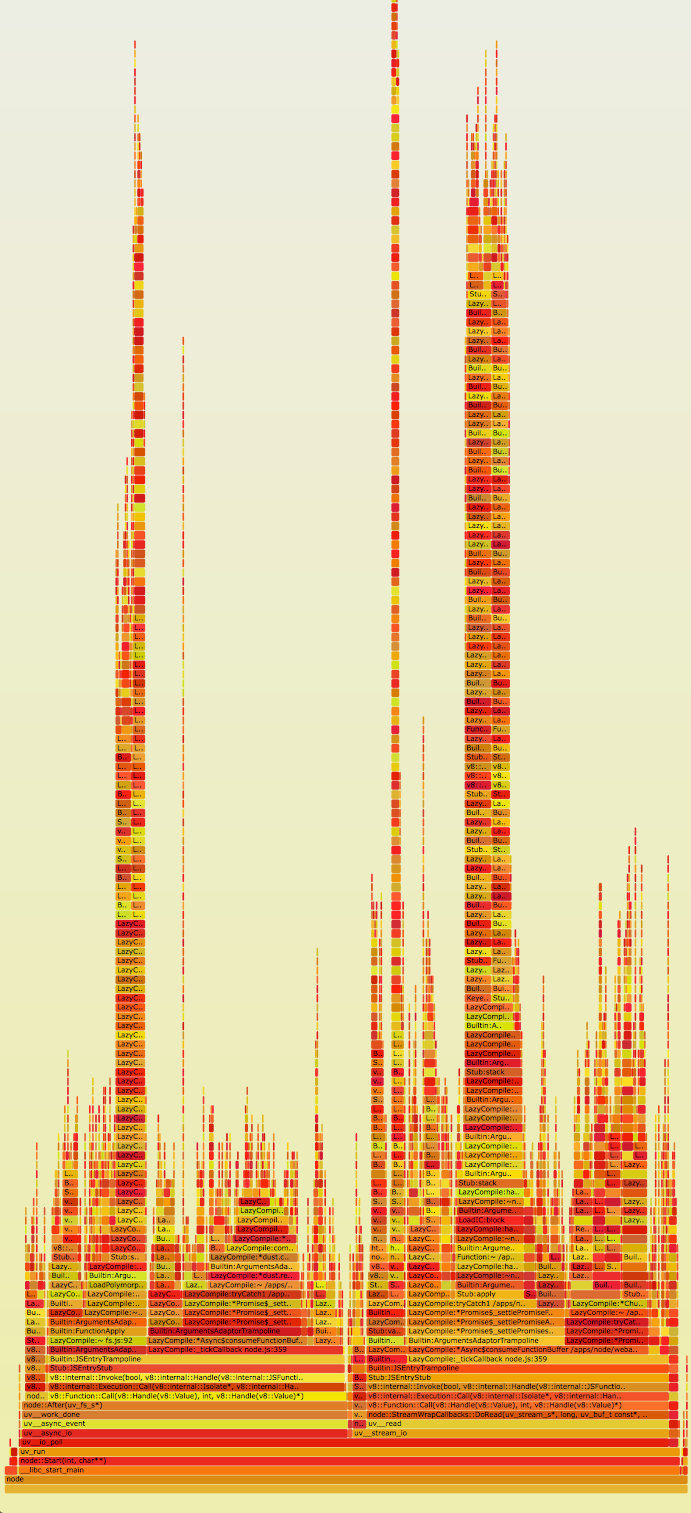
По этой
ссылке вы можете посмотреть оригинальный интерактивный flame graph нашего приложения в SVG.
Сразу же можно отметить невероятно большие стеки в приложении (ось Y). Также очевидно, что на них приходится достаточно много времени (ось X). При ближайшем рассмотрении окажется, что эти стек фреймы полны ссылок на функции
route.handle и
route.handle.next из
Express.
Мы нашли в исходном коде Express два интересных момента
1:
- Обработчики маршрутов для всех путей сохраняются в одном глобальном массиве
- Express рекурсивно перебирает и вызывает все обработчики пока не найдет подходящий маршрут
Глобальный массив это не самая подходящая структура данных в этом случае, так как для того, чтобы найти маршрут, в среднем потребуется
O(n) операций. Непонятно, почему разработчики Express решили не использовать постоянную струкутру данных, например, хэш-таблицу для хранения обработчиков. Усугубляет ситуацию и то, что массив обходится рекурсивно. Это обьясняет, почему мы видели такие высокие стеки в flame graphs. Интересно и то, что Express позволяет установить множество обработчиков для одного маршрута.
[a, b, c, c, c, c, d, e, f, g, h]
В данном случае поиск для маршрута
c был бы прекращен при нахождении первого подходящего обработчика (позиция 2 в массиве). Однако для того, чтобы найти обработчик маршрута
d (позиция 6 в массиве), необходимо было бы потратить лишнее время на вызов нескольких экземпляров
c. Мы проверили это с помощью простого Express приложения:
var express = require('express');
var app = express();
app.get('/foo', function (req, res) {
res.send('hi');
});
// добавляем еще один обработчик на тот же маршрут
app.get('/foo', function (req, res) {
res.send('hi2');
});
console.log('stack', app._router.stack);
app.listen(3000);
После запуска приложение выводит эти обработчики:
stack [ { keys: [], regexp: /^\/?(?=/|$)/i, handle: [Function: query] },
{ keys: [],
regexp: /^\/?(?=/|$)/i,
handle: [Function: expressInit] },
{ keys: [],
regexp: /^\/foo\/?$/i,
handle: [Function],
route: { path: '/foo', stack: [Object], methods: [Object] } },
{ keys: [],
regexp: /^\/foo\/?$/i,
handle: [Function],
route: { path: '/foo', stack: [Object], methods: [Object] } } ]
Обратите внимание, что есть два одинаковых обработчика для маршрута
/foo. Было бы неплохо, если Express выкидывал бы ошибку всякий раз, когда один маршрут имеет несколько обработчиков.
Теперь наше предположение заключалось в том, что задержки возникали из-за постоянного увеличения массива с обработчиками. Скорее всего где-то в нашем коде дублировались обработчики. Мы добавили дополнительное логгирование, которое выводило массив обработчиков запросов, и заметили, что он растет по 10 элементов в час. Эти обработчики были идентичны друг другу, как из примера выше.
Что-то добавляло в приложение по 10 одинаковых обработчиков для статических маршрутов в час. Далее мы выяснили, что при переборе этих обработчиков затраты на вызов каждого из них занимают около 1 миллисекунды. Это коррелирует с тем, что мы видели раньше, когда задержка отклика росла на 10 миллисекунд в час.
Оказалось, это было вызвано периодическим (10 раз в час) обновлением обработчиков в нашем коде из внешнего источника. Мы реализовали это удалением старых обработчиков и добавлением новых к массиву. К сожалению, также при этой операции мы всегда добавляли обработчик для статического маршрута. Так как Express позволяет добавлять несколько обработчиков для одного маршрута, все эти дубликаты добавлялись в массив. Хуже всего то, что все они добавлялись раньше остальных, а это означало, что прежде чем Express найдет обработчик API для нашего сервиса, он несколько раз вызовет обработчик для статического маршрута.
Это в полной мере объясняет, почему задержки запросов росли на 10 миллисекунд в час. В самом деле, после того как мы устранили ошибку в нашем коде, постоянное возрастание времени задержки и увеличение использования процессорного времени прекратилось.
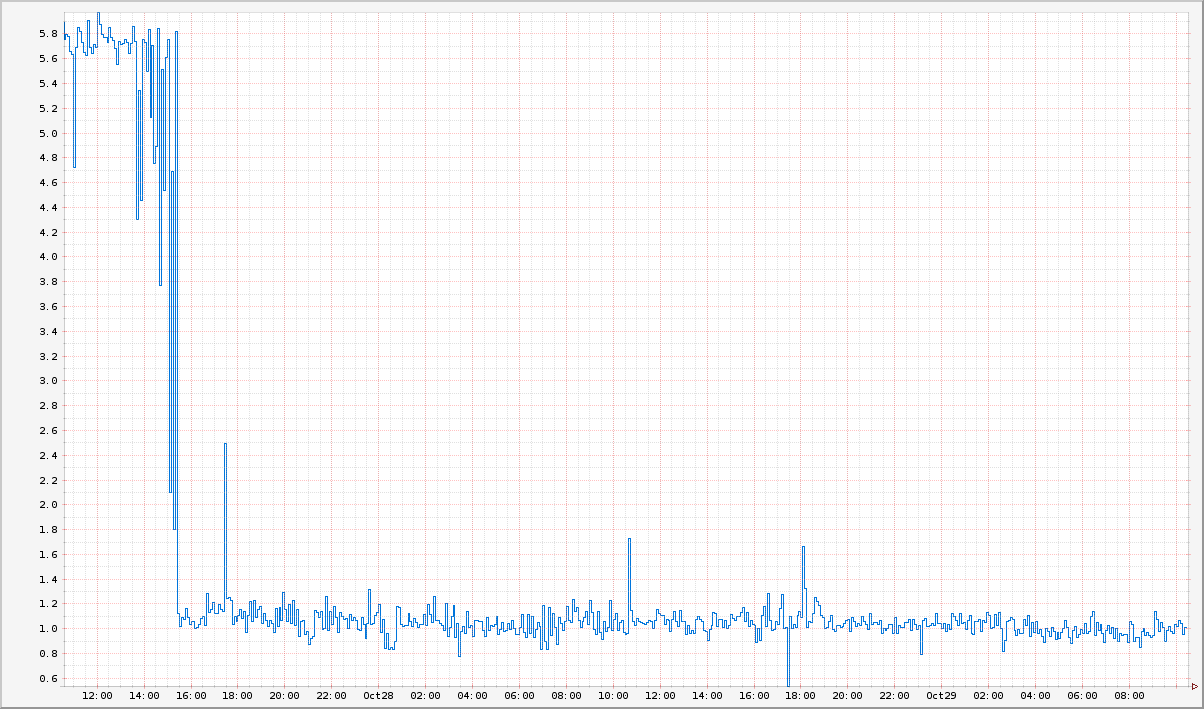
На этом графике видно, что время задержки сократилось до одной миллисекунды после обновления кода.
Когда дым рассеялся
Какой же опыт мы получили? Во-первых, мы должны полностью понимать, как устроены зависимости в нашем коде, прежде чем использовать его в production. Мы сделали неверное предположение о работе Express API без исследования его кода. Неправильное использование Express API является конечной причиной наших проблем с производительностью.
Во-вторых, при решении проблем с производительностью наглядность имеет первостепенное значение. Flame graphs дали нам огромное понимание того, где наше приложение тратит больше всего времени и ресурсов процессора. Я не могу себе представить, как бы мы могли решить эту проблему, будучи не в состоянии получить node.js стеки и визуализировать их с помощью flame graphs.
Желая улучшить наглядность, мы мигрируем на
Restify, который позволит нам улучшить контроль над нашим приложением
2. Это выходит за рамки данной статьи, поэтому читайте в нашем блоге о том, как мы используем node.js в Netflix.
Хотите решать подобные проблемы вместе с нами? Наша команда
ищет инженера для работы с node.js стеком.
Автор: Юнонг Ксиао
@yunongx
Примечания:
- В частности этот фрагмент кода. Обратите внимание, что функция
next() вызывается рекурсивно для перебора массива обработчиков.
- Restify предоставляет множество механизмов для получения лучшей наглядности работы нашего приложения, от поддержки DTrace до интеграции c node-bunyan.
Примечания переводчика:- Я не имею никакого отношения к компании Netflix. Но ссылку на вакансию оставил намеренно, буду искренно рад, если кому-нибудь она пригодится.
- В комментариях к оригинальной статье объясняется, почему Express не использует хэш-таблицы в качестве структуры данных для хранения обработчиков. Причина кроется в том, что регулярное выражение, по которому выбирается необходимый обработчик, не может быть ключом в хэш-таблице. А если хранить его как строку, то сравнивать придется также все ключи из хэш-таблицы (хотя это все и не отменяет того, что при добавлении второго обработчика на маршрут, можно было бы выбрасывать хотя бы предупреждение).
- Также вы можете прочесть развернутый ответ Эрана Хаммера (одного из контрибьюторов hapi) и последовавшую за ним дискуссию.
Комментарии и замечания, касающиеся перевода, приветствуются в личных сообщениях.
{kind=link}