https://habr.com/ru/post/522942/Задача
Дано: проект на основе OpenWRT (а он — на основе BuildRoot) с одним дополнительным репозиторием, подключенным как feed. Задача: слить дополнительный репозиторий с основным.
Предыстория
Мы делаем маршрутизаторы и, однажды, захотели дать клиентам возможность включать свои приложения в прошивку. Чтобы не мучаться с выделением SDK, toolchain и сопутствующими сложностями, решили выложить весь проект на github в закрытый репозиторий. Структура репозитория:
/target // скрипты для сборки ядер
/toolchain // скрипты для сборки gcc, musl и прочих инструментов сборки
/feeds // дополнительные репозитории с приложениями
/package // скрипты для сборки приложений
...
Было решено часть приложений собственной разработки перенести из основного репозитория в дополнительный, чтоб никто не подсмотрел. Мы всё это сделали, выложили на github и стало хорошо.
Много воды утекло с тех пор…
Клиента того давно уж нет, репозиторий с github убрали, и сама идея открывать клиентам доступ в репозиторий протухла. Однако же, два репозитория в проекте остались. И все скрипты/приложения, так или иначе связанные с git, вынужденно усложняются, чтобы работать с такой структурой. Проще говоря, это технический долг. Например, чтобы обеспечить воспроизводимость релизов, необходимо в основной репозиторий (primary) закоммитить файлик, secondary.version, с хэшем из второго репозитория. Конечно, это делает скрипт, и ему не очень сложно. Но, таких скриптов с десяток, и все они сложнее чем могли бы быть. В общем, я принял волевое решение влить репозиторий secondary обратно в primary. При этом, было поставлено главное условие — сохранить воспроизводимость релизов.
Раз поставлено такое условие, то тривиальные методы слияния, как то, закоммитить всё из secondary отдельно и потом, сверху, сделать merge-коммит двух независимых деревьев, не подойдут. Придётся открыть капот и испачкать руки.
Структура данных git
Для начала, что из себя представляет репозиторий git? Это база объектов. Объекты бывают трёх типов: блобы (blob), деревья (tree) и коммиты (commit). Все объекты адресуются sha1 хэшем своего содержимого. Блоб — это, тупо, данные без каких-либо дополнительных атрибутов. Дерево представляет из себя отсортированный список ссылок на деревья и блобы вида “<права> <тип> <хэш> <имя>” (где <тип> это, либо blob, либо tree). Таким образом дерево, это как бы директория в файловой системе, а блоб — это как бы файл. Коммит содержит имя автора и коммитера, дату создания и добавления, комментарий, хэш дерева и произвольное количество (чаще всего одна или две) ссылок на родительские коммиты. Вот эти ссылки на родительские коммиты, как раз и превращают базу объектов в ациклический орграф (среди иностранцев, известен, как DAG). Подробно читайте
тут:
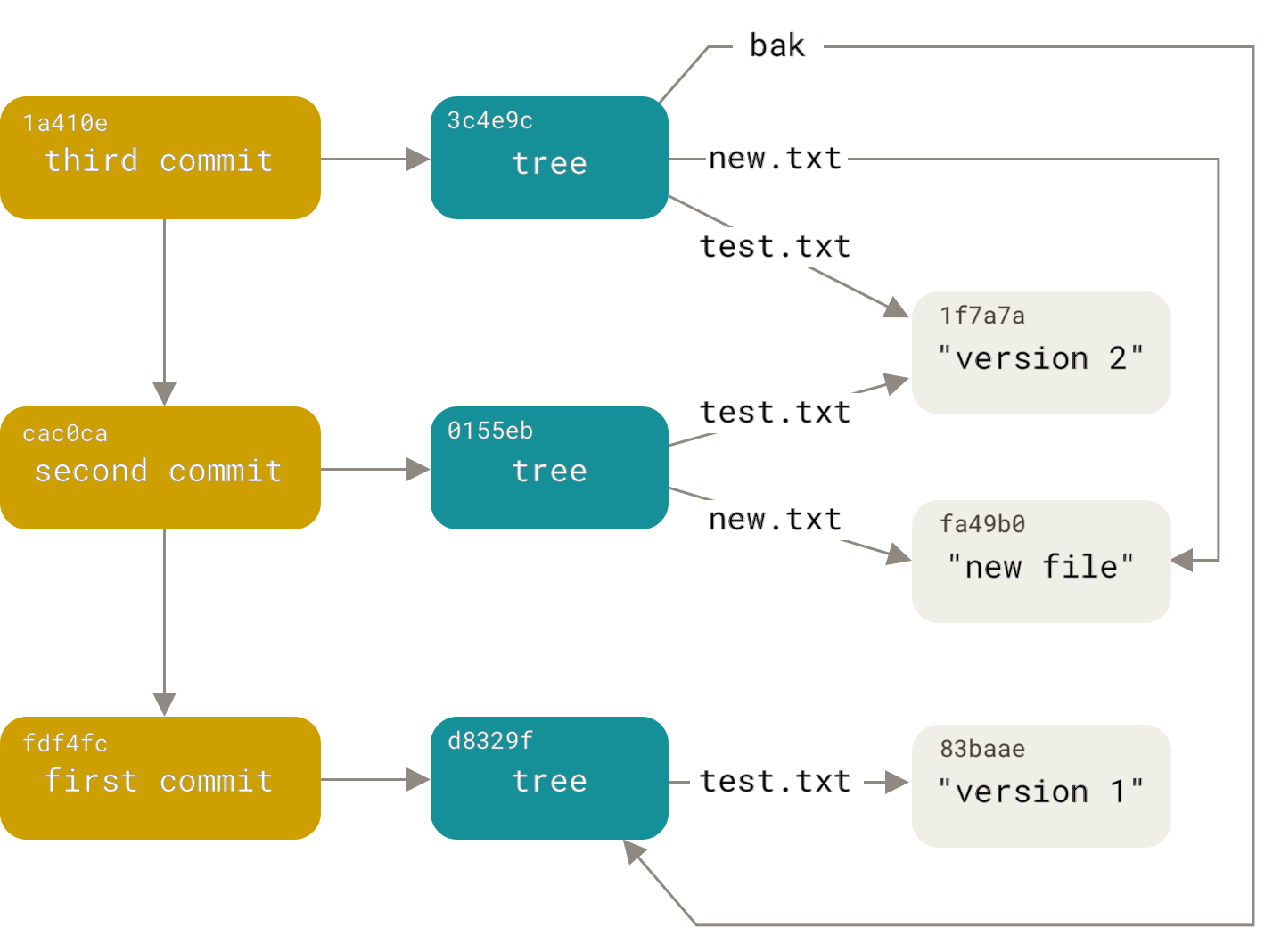
Таким образом, наша задача преобразовалась в задачу построения нового орграфа, повторяющего структуру старого. Но с заменой коммитов файла secondary.version на коммиты из дополнительного репозитория

Процесс разработки у нас далёк от классического gitflow. Мы всё коммитим в мастер, стараясь его, при этом, не сломать. Оттуда же делаем билды. По необходимости делаем стабилизирующие ветки, которые потом обратно сливаем в мастер. Соответственно, граф репозитория выглядит как голый ствол секвойи оплетённый лианами.
Анализ
Задача естественным образом разбивается на два этапа: анализ и синтез. Так как для синтеза надо, очевидно, пробежать от самого момента выделения репозитория secondary до всех тэгов и веток, вставляя коммиты из второго репозитория, то на этапе анализа нужно найти места куда вставлять secondary-коммиты и сами эти коммиты. Значит, надо построить редуцированный граф, где узлами будут коммиты основного графа изменяющие файл secondary.version (ключевые коммиты). Причём, если узлы настоящего гита ссылаются на родителей, то в новом графе нужны ссылки на потомков. Завожу именованный кортеж:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
необходимая оговорка
Весь код в статье, не совсем настоящий. Обработка иключений, мелкие детали и незначительные подробности реализации намеренно опущены.
Кладу его в словарь:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}
Туда же кладу все коммиты изменяющие secondary.version:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])
И строю простенький рекурсивный алгоритм:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)
То есть, как бы протягиваю ключевые узлы в прошлое, и подцепляю к новым родителям.
Запускаю, и… RuntimeError max recursion depth exceeded
Как же так получилось? Неужели, слишком много коммитов?
git log и
wc знают ответ. Всего коммитов с момента разделения около 20000, а затрагивающих secondary.version — почти 700. Рецепт известен, нужна нерекурсивная версия.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)
(А вы говорили, что все эти алгоритмы нужны только чтоб интервью проходить!)
Запускаю, и… оно работает. Минуту, пять, двадцать… Нет, так долго нельзя. Останавливаю. Судя по всему каждый коммит и каждый путь обрабатывается по многу раз. Сколько же в дереве разветвлений? Выяснилось, что в дереве 40 разветвлений и, соответственно,
разных путей только от мастера. И к значительной части ключевых коммитов ведут многие пути. Поскольку тысячи лет у меня в запасе нет, надо поменять алгоритм так, чтобы каждый коммит обрабатывался ровно один раз. Для этого добавляю множество, где отмечаю каждый обработанный коммит. Но тут есть маленькая проблема: при таком подходе часть связей будет утеряна, так как разные пути с разными ключевыми коммитами могут проходить через одни и те же коммиты, и только первый пойдёт дальше. Чтобы обойти эту проблему, множество заменяю на словарь, где ключами будут коммиты, а значениями — списки достижимых ключевых коммитов:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)
В результате этого бесхитростного обмена памяти на время граф строится за 30 сек.
Синтез
Теперь у меня есть commit_map с ключевыми узлами связанными в граф через ссылки на потомков. Для удобства, преобразую его в последовательность пар
(предок, потомок). В последовательности должно быть гарантированно, что все пары, где узел встречается в качестве потомка, расположены раньше чем любая пара, где узел встречается в качестве предка. Дальше надо просто пройти по этому списку и закоммитить сначала коммиты из основного репозитория, а потом из дополнительного. Тут надо помнить, что коммит содержит ссылку на дерево, которое является состоянием файловой системы. Так как, дополнительный репозиторий содержит дополнительные поддиректории в директории
package/, то надо будет для всех коммитов создать новые деревья. В первой версии, я просто писал блобы в файлы и просил гит построить индекс по рабочей директории. Однако, такой метод оказался не очень производительным. Коммитов всё ещё 20000, и каждый нужно закоммитить ещё раз. Так что, тут производительность имеет большое значение. Небольшое исследование внутренностей
GitPython привело меня к классу
gitdb.LooseObjectDB, который открывает прямой доступ к объектам git-репозитория. С ним, блобы и деревья (и любые другие объекты, тоже) из одного репозитория можно писать прямо в другой. Замечательным свойством базы объектов git является то, что адресом любого объекта, является хэш от его данных. По этому, одинаковый блоб будет иметь один и тот же адрес, даже в разных репозиториях.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)
Сами функции коммита:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
Как видите коммиты из secondary репозитория добавляются скопом. Сначала, я сделал чтобы добавлялись индивидуальные коммиты, но (внезапно!) выяснилось, что иногда более новый ключевой коммит содержит предыдущую версию secondary репозитория (проще говоря, версию откатывают). В такой ситуации метод iter_commit пасует и возвращает пустой список. В результате репозиторий получается неправильный. По-этому, пришлось просто коммитить актуальную версию.
Интересна история появления генератора all_but_last. Описание я опустил, но делает он именно то, что вы ожидаете. Сначала там был просто вызов
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)
. Однако, быстро выяснилось, что запись "
x..y^" означает совсем не «все коммиты от
x до
y, исключая сами
x и
y», а «все коммиты от
x до первого родителя
y, включая этого родителя». В большинстве случаев, это одно и то же. Но только не тогда, когда у
y несколько родителей…
В общем, всё закончилось хорошо. Весь скрипт уместился строчек в 300 и отработал примерно за 6 часов. Мораль: GitPython'ом удобно делать всякие крутые штуки с репозиториями, но лучше техдолг лучше лечить своевременно