http://habrahabr.ru/post/219139/
В процессе работы над хеш-таблицей возник обычный вопрос: какую из известных хеш-функций использовать. Образцов таких функций в сети множество, есть и «любимчики», использовавшиеся ранее и показавшие неплохой результат, в основном оценивавшийся «на глаз» — длины цепочек в хеш-таблице на боевых данных «примерно равны», значит, все работает так, как нужно; отдельные выбросы… ну что ж, ну выбросы, бывает.
В этот раз, наткнувшись на
статью и воодушевившись ею, решил получить более или менее объективную сравнительную оценку хеш-функций. Для этого были сформулированы требования к ним, в число которых вошли следующие:
- функция должна возвращать 32-битное целое значение;
- функция должна получать на входе zero-terminated string (без явно заданной длины);
- функция должна быть достаточно быстрой (по сравнению с конкурентами);
- функция должна давать как можно более равномерное распределение хэш-значения;
- (несколько необычное требование, вытекающее из особенностей конкретного применения) функция должна давать как можно более равномерное распределение хэш-значения, если в качестве этого значения использовать любой байт возвращенного ею числа.
В качестве тестовых данных я воспользовался тремя словарями из вышеупомянутой статьи, автору которой весьма признателен за сэкономленное время. Словари были преобразованы в windows-1251 и слиты в один файл. Всего получилось 327049 различных слов.
Приступим
Первой жертвой экспериментов пала любимица с магической цифрой 37, ранее бездумно применявшаяся для хеширования всего и вся:
unsigned int HashH37(const char * str)
{
unsigned int hash = 2139062143;
for(; *str; str++)
hash = 37 * hash + *str;
return hash;
}
Одного взгляда на гистограмму было достаточно, чтобы понять, что выбросы, конечно, бывают, да, бывают… но не такие же

Впрочем, младшие два байта результата вполне юзабельны
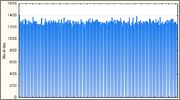
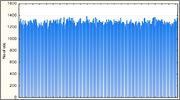
а вот старшие как раз и дают то, что доводит общую картину до категории «печальная»

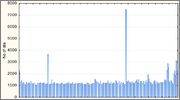
Итак, по «любимице» вывод: там, где достаточно 16 бит результата, функция вполне пригодна, в качестве же полного 32-битного хеша не годится абсолютно.
Другие кандидаты
Естественно, после увиденного привычной хеш-функции пришлось подыскивать замену. Не мудрствуя лукаво, просмотрел все функции, подходящие по первому пункту (т.е. не требующие знания длины строки перед вычислением хеша), в
статье, хеш-функциям и посвященной.
В число кандидатов попали (названия сохраняю оригинальные)
- Js
- PJW
- ELF
- BKDR
- SDBM
- DJB
- AP
- FAQ6
- Rot13
- Ly
- Rs
Из перечисленных только функции FAQ6, Rot13, Ly и Rs показали удовлетворительные результаты. Для остальных без лишних слов приведу распределения полного 32-битного значения:
Функция Js
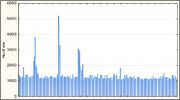
Функция PJW
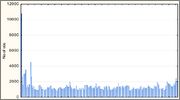
Функция ELF
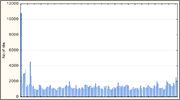
Функция BKDR
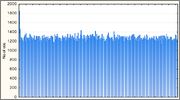
Функция SDBM
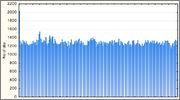
Функция DJB
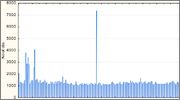
Функция AP
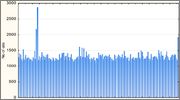
Победители
Для признанных «подходящими» функций приведу полный код (немного измененный по сравнению с данным в статье-источнике, изменения в основном связаны с требованием отстутствия явно заданной длины хешируемой строки) и распределения как полного 32-битного значения, так и каждого байта.
Функция FAQ6
unsigned int HashFAQ6(const char * str)
{
unsigned int hash = 0;
for (; *str; str++)
{
hash += (unsigned char)(*str);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return hash;
}
32-битное значение

первый байт

второй байт

третий байт

четвертый байт

Функция Rot13
unsigned int HashRot13(const char * str)
{
unsigned int hash = 0;
for(; *str; str++)
{
hash += (unsigned char)(*str);
hash -= (hash << 13) | (hash >> 19);
}
return hash;
}
32-битное значение

первый байт

второй байт

третий байт

четвертый байт

Функция Ly
unsigned int HashLy(const char * str)
{
unsigned int hash = 0;
for(; *str; str++)
hash = (hash * 1664525) + (unsigned char)(*str) + 1013904223;
return hash;
}
32-битное значение

первый байт

второй байт

третий байт

четвертый байт

Функция Rs
unsigned int HashRs(const char * str)
{
static const unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
for(; *str; str++)
{
hash = hash * a + (unsigned char)(*str);
a *= b;
}
return hash;
}
32-битное значение

первый байт

второй байт

третий байт

четвертый байт

Производительность
Из всех протестированных функций наибольшую скорость работы продемонстрировала DJB. Несмотря на то, что в число «годных» функций она не попала, затраченное ею время на обработку всех тестовых слов я принял за 100% и соотнес с ним время работы остальных функций. Получилось следующее:
| DJB |
100 |
| SDBM |
111 |
| BKDR |
113 |
| H37 |
113 |
| Ly |
122 |
| Js |
125 |
| Rs |
125 |
| Rot13 |
145 |
| AP |
159 |
| ELF |
184 |
| PJW |
191 |
| FAQ6 |
205 |
Если оставить в таблице только выбранные для использования функции, получим
| Ly |
122 |
| Rs |
125 |
| Rot13 |
145 |
| FAQ6 |
205 |
Выводы
Рассмотрев статистические характеристики некоторых известных хеш-функций, мы выбрали из них те, что показали наиболее равномерное распределение как по полному 32-битному значению, так и по отдельным байтам и захабрили (для истории?) их исходный код. Следует отметить, что не вошедшие в четверку «лидеров» функции могут оказаться предпочтительными при других условиях, например, если полученное значение берется по какому-либо модулю. Мы такие случаи не рассматривали.
Благодарю за внимание.