Мы опубликовали современный Voice Activity Detector и не только
- суббота, 16 января 2021 г. в 00:35:14
Всегда при работе с речью встает несколько очень "простых" вопросов, для решения которых нет большого количества удобных, открытых и простых инструментов: детекция наличия голоса (или музыки), детекция наличия цифр и классификация языков.
Для решения задачи детекции голоса (Voice Activity Detector, VAD) существует довольно популярный инструмент от Google — webRTC VAD. Он нетребовательный по ресурсам и компактный, но его основной минус состоит в неустойчивости к шуму, большом числе ложноположительных срабатываний и невозможности тонкой настройки. Понятно, что если переформулировать задачу не в детекцию голоса, а в детекцию тишины (тишина — это отсутствие и голоса и шума), то она решается весьма тривиальными способами (порогом по энергии, например), но с теми же минусами и ограничениями. Что самое неприятное — зачастую такие решения являются хрупкими и какие-то хардкодные пороги не переносятся на другие домены.
Изначально мы хотели сделать простой и быстрый внутренний инструмент для себя и наших партнеров для детекции произнесенных чисел без привлечения полноценного STT (фишка изначально была именно в портативности засчет использования современных фреймворков типа PyTorch и ONNX), но в итоге оказалось, что можно сделать не только детектор чисел, но и качественный, быстрый и портативный VAD и классификатор языков, который и опубликовали бесплатно для всех желающих тут под лицензией MIT. За подробностями прошу под кат.
Что же умеет делать наш "VAD"?
Основные "фишки" на данный момент:
Вообще мы постарались привести основные примеры использования в интерактивном ноутбучке в colab и в самом репозитории. Все их выписывать в статью смысла нет, давайте просто перечислим самые важные и приведем самый простой пример:
Самый просто пример, где мы натравливаем VAD на файл:
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
print(speech_timestamps)Тут кратко опишем, как данные кормятся в VAD. Для остальных алгоритмов заинтересовавшиеся просто найдут информацию в коде.
Все замеры скорости мы делали на 1 потоке процессора AMD Ryzen Threadripper 3960X. Для этого мы использовали такие настройки:
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnxПодробнее вы можете просто посмотреть в коде, но задежка зависит от следующих параметров:
Получаются такие задержки:
| Batch size | Pytorch latency, ms | Onnx latency, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
Попробуем теперь измерить пропускную способность в секундах аудио, обрабатываемых за одну секунду на 1 потоке процессора:
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
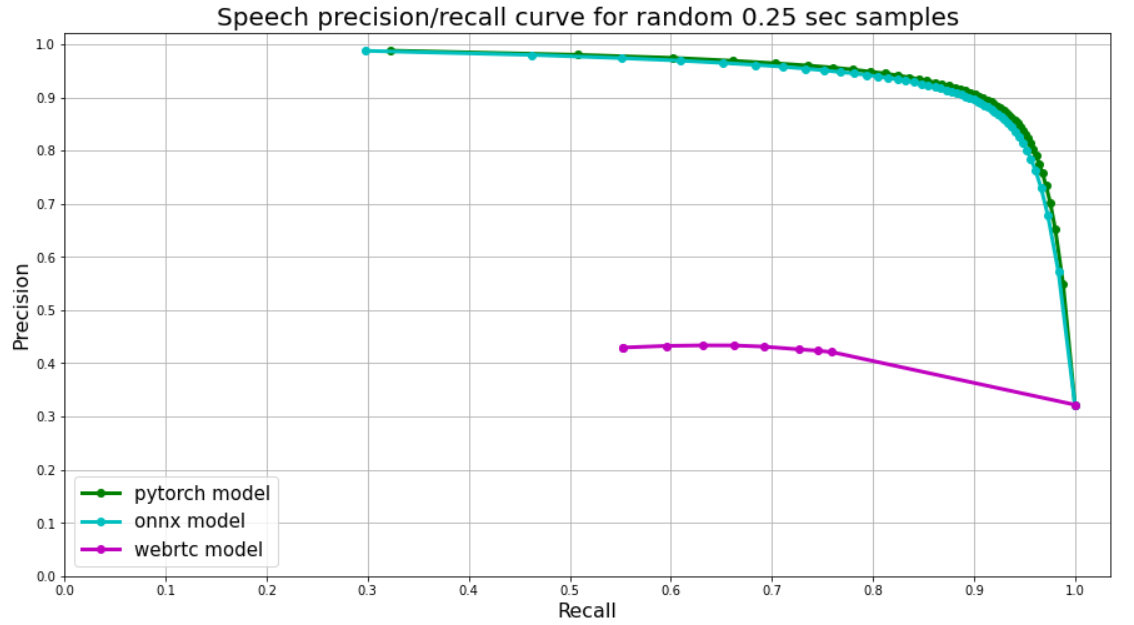
По логике процесса, описанного выше, мы измеряли качество нашего VAD по сути просто присваивая некую усредненную вероятность каждому кусочку аудио и сравнивая ее с истинными метками. Но как добавить к сравнению WebRTС, он же выдает просто 0 или 1?
WebRTC принимает на вход фреймы аудио и отдает 0 или 1. По-умолчанию используется длина фрейма в 30 мс, то есть каждый кусочек аудио в 250 мс мы делится примерно на 8 таких фреймов. Это неидеально, но мы просто интерпретируем среднее из таких 0 и 1 как вероятность.
В итоге получается вот такой результат:
Как упоминалось выше, наш VAD также обладает тем преимуществом, что его можно более тонко настраивать используя более очевидные параметры. Инструкцию по такой настройке, примеры и описания работы остальных алгоритмов вы можете найти в репозитории нашего проекта. Пропускная способность и задержка других алгоритмов примерно сравнима с VAD.