Мультифункциональный фиттинг экспериментальных данных
- воскресенье, 1 декабря 2019 г. в 00:30:57
Очень часто, как и в точных науках (физика, химия), так и в прочих областях (экономика, социология, маркетинг и пр.) при работе с разного рода экспериментально полученными зависимостями одной величины (Y) от другой (X) возникает потребность описать полученные данные какой-нибудь математической функцией. Этот процесс часто называют экспрессией, аппроксимацией, приближением или фиттингом.
Наиболее часто для фиттинга данных используется линейная функция:
Лирическое отступление
Немаловажным будет так уже упомянуть ситуацию, когда одни и те же экспериментальные данные можно достаточно хорошо (в рамках заранее определенных метрик) описывать очень разными математическими функциями, как показано на Рис. 1.
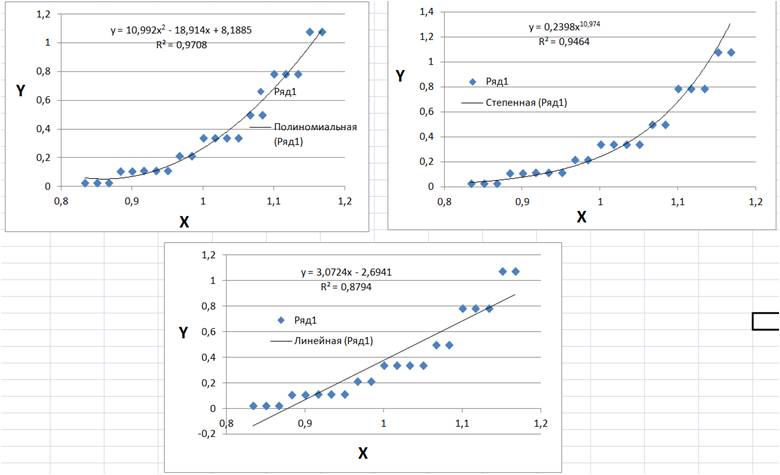
Рис. 1. Попытка описания одного и того же набора экспериментальных данных квадратичной, степенной и линейной функциями.
Однозначного отчета, а что лучше — не существует. Все определяется теми задачами (получить площадь под кривой, узнать значение производной, узнать новое значения Y для иного X и т.д.), для решения которых предлагается использовать то или иное математическое приближение. Конечно, больше всего полезной информации можно получить из того математического приближения, которое не просто прекрасно описывает экспериментальные данные, а за которым стоит физическая/химическая/экономическая и пр. модель наблюдаемой в эксперименте зависимости. Тогда, из полученных оптимизированных параметров извлекается полезная информация.
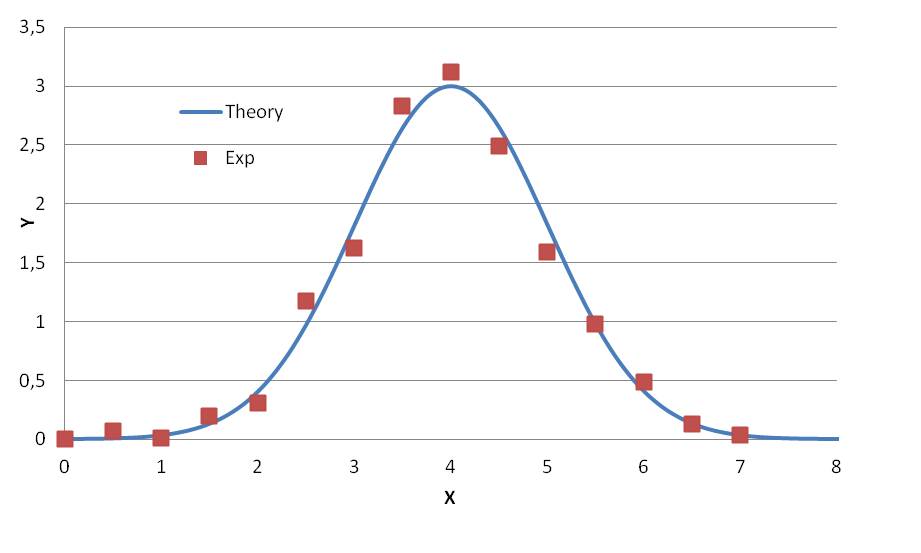
Рис. 2-А. Абстрактный пример нелинейной экспериментальной зависимости Y от X (красные точки) и ее теоретической аппроксимации (синяя кривая) функцией Гаусса.
Для проведения фиттинга нелинейных экспериментальных зависимостей существует ряд программных решений (Matlab, Origin, Datafit и пр.). Не вызывает больших сложностей осуществить подобный фиттинг в MS Excel (помним про solver).
Однако, бывают ситуации, когда экспериментальная кривая состоит из нескольких полностью или частично накладывающихся друг на друга индивидуальных, независимых в силу своей природы, кривых. Особенно часто это проявляется при физических и химических измерениях: инфракрасная спектроскопия (Рис. 2-Б), ядерный магнитный резонанс (Рис. 2-В), рентгеновская фотоэлектронная спектроскопия (Рис. 2-Г), хроматографии (Рис. 2-Д) и пр. В некоторых случаях маленький, но очень гордый важный пик бывает полностью или почти полностью скрыт большим пиком, так что его почти не видно невооруженным взглядом. А о его существовании приходиться догадываться по косвенным соображениям.
| Примеры |
|---|
 Рис. 2-Б. Пример перекрытие пиков в FTIR спектре. По оси Y (не показана) -безразмерная величина, характеризующая поглощение ИК излучения веществом, по оси X — волновое число в см-1. Источник: Canadian Journal of Microbiology 63(12), October 2017. |
 Рис. 2-В. Пример перекрытия H1-NMR пиков. Источник. |
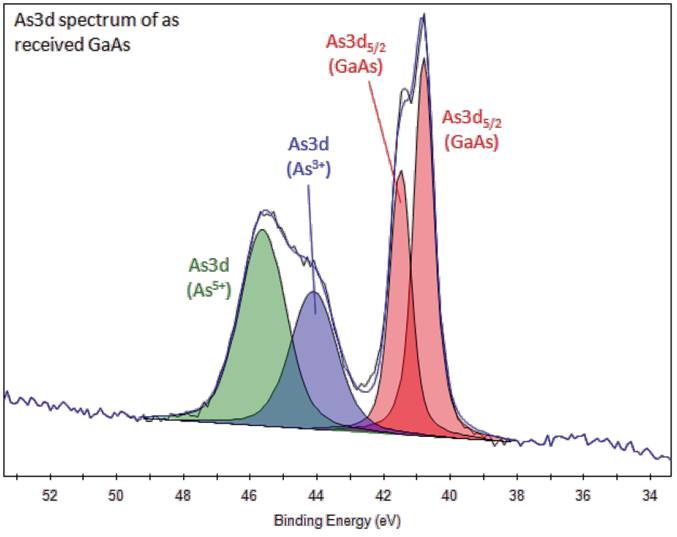 Рис. 2-Г. Перекрытие пиков в As3d -XPS спектре образца арсенида галлия (GaAs). Четко видны различные электронные состояния As в образце. Количественный анализ, выполняемый при помощи фиттинга, позволяет исследователям проанализировать структуру образца. Источник. |
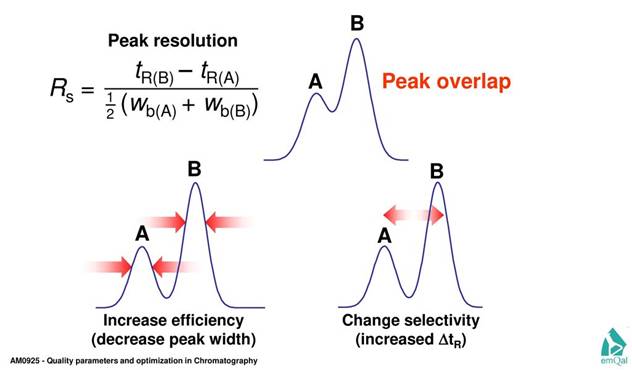 Рис. 2-Д. Примеры перекрытия хроматографических пиков. Концентрация анализируемого вещества прямо пропорциональна площади под кривой пика, по этому необходимо уметь эту площадь точно определять. Источник. |
В зависимости от области науки, где встречаются подобные ситуации с перекрытием пиков, исследователи научились их по разному решать. В ЯМРе повышают напряженность магнитного поля, понижают температуру по время измерения, что приводит к разделению (разрешению) пиков. Другими словами, используют аппаратное и методологическое решение проблемы, что вне сомнений хорошо в контексте усовершенствования приборов и методик, но нередко стоит больших денег и не всегда доступно.
В инфракрасной спектроскопии особо ничего не делают с плохо разделенными пиками, аппаратно разделить их не получается, а исторически все привыкли, что тот или иной пик представлен на спектре, к примеру, как плечо на фоне другого пика и довольно редко, кто-то пытается извлечь более полную информацию из такого спектра, осуществляя его фиттинг (J. Braz. Chem. Soc., Vol. 19, No. 8, 1582-1594, 2008).
В тоже время в рентгеновской фотоэлектронной спектроскопии практически всегда приходиться проводить фиттинг экспериментальных данных как суперпозицию нескольких индивидуальных пиков (имеющих форму кривой Гаусса), что реализуется посредством специального ПО,
поставляемого с прибором.
Для разделения пиков в жидкостной и газовой хроматографии уменьшают концентрации веществ, устанавливают дополнительные разделительные колонки, увеличивают их длину, используют методы химической модификации веществ, изменяют условия проведения хроматографического разделения и пр. Но, как ни странно, несмотря на актуальность проблемы, в этой области не используют математические возможности разделения пиков. Хотя и существуют соответствующие методы и модели, но своего применения в коммерческих хроматографических решениях они пока не нашли…
Несмотря на возникающую необходимость проводить многокомпонентный (мульти функциональный) фиттинг автор этих срок не знаком с ПО, позволяющим использовать для фиттинга одновременно несколько одинаковых или разных математических функций. В замечательной программе OriginPro 8 мультифиттинг ограничен функциями Лоренца и Гаусса, что уже не плохо, но не достаточно. При этом качество фиттинга не всегда удовлетворительное и нет возможности контролировать сам процесс фиттинга. Если не понравились его результаты, то процесс приходиться начинать с самого начала и так много раз....
Еще не маловажным моментом является, тот факт что практически все программы при осуществлении фиттинга работают лишь с данным сигналом Y и автоматически не осуществляют фиттинг производной этого сигнала, что может привести к малозначимым результатам.
По этому, когда возникла реальная задача описать экспериментальные кривые, из формы которых было видно, что без мультифункционального фиттинга не обойтись, то подходящего инструмента под рукой не оказалось. А еще захотелось наглядности и контролируемости процесса фиттинга и, чтобы экспериментальная и расчетная производные совпадали. Конечно, проблему можно было бы решить в ручную в МS Excel, но данных было много и хотелось попрактиковаться в Питоне, который несколькими месяцами ранее стал изучать, как свой первый язык программирования.
В этом контексте была поставлена следующая цель.
Написать программу для удобного, наглядного, быстрого и качественного мультифиттинга загружаемых экспериментальных данных, учитывая фиттинг самого сигнала и его производной.
При этом пользователь должен руками задать количество используемых в фиттинге различных математических функций и иметь возможность выбрать ту или иную математическую функцию из списка.
В процессе самого фиттинга хотелось иметь возможность самому контролировать процесс подбора параметров, а не доверять в слепую алгоритмам оптимизации, в первую очередь из-за того, что они не учитывают совпадение производных экспериментального и расчетного сигналов.
Плюс прочие мелочи, такие как сглаживание шумов и удаление "артефактов" из исходных данных, мешающих вычислению производной.
С учетом отсутствия опыта в программировании, задача казалась не простой, но очень интересной, решать которую пришлось, разбивая ее на подзадачи:
Наверное нет особого смысла описывать детали, вопросы и проблемы, которые возникали по ходу написания программы. Детали доступны самом коде, код доступен тут. Большинство вопросов и проблем оказались стандартными, полное или частичное решение которых находилось на различных сайтах и в книгах, посвященных Питону, а так же на stackoverflow. Решения и примеры тупо копировались разбирались и адаптировались под свои нужды. Ниже кратко описана работа программы, ее возможности и ограничения на данный момент. Программа состоит из трех рабочих файлов и краткой инструкции:
Fitting_tool.py -Интерфейс, проверка корректности ввода параметров, вызов различных функций.
NumPy1.py — Класс методов для чтения, записи, обработки данных и отображения их в графическом виде
ThFunction.py — Класс из нескольких математических функций, их параметров с начальными значениями и границами интервалов изменений этих параметров.
Fitting Tool v.1.0 Help.pdf — Небольшой мануал с картинками, который решил сделать сразу на английском.
При запуске программы предлагается открыть файл со своими данными или воспользоваться уже имеющимися примерами, которые необходимо импортировать.
Затем можно просмотреть оригинальный график и его производную, посчитанную, как есть или после математического сглаживания. При этом заранее непросто сказать, какой метод сглаживания будет лучше работать и имеет смысл попробовать их все или выбрать опцию без сглаживания. В результате появиться стандартное окно с графиком экспериментального сигнала и его производной, Рис. 3-А.
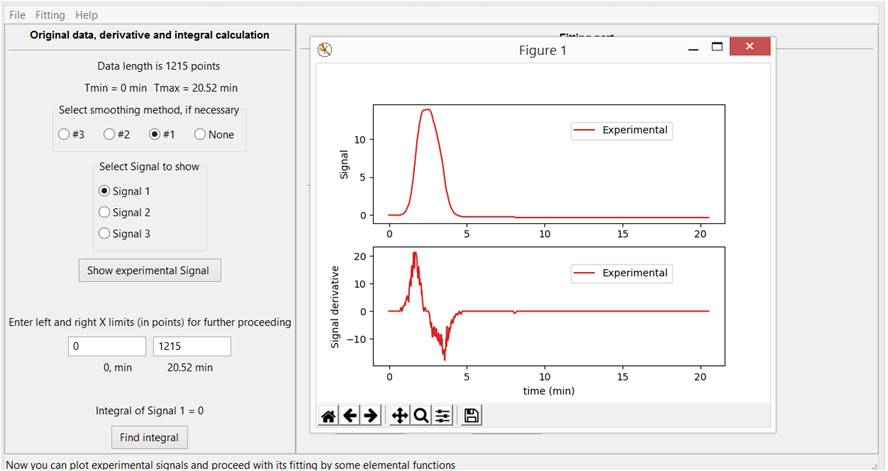
Рис. 3-А. Графическое представление оригинального экспериментального сигнала и его производной с использование одного из трех методов математического сглаживания.
Задав левую и правую границы рассматриваемого интервала, можно сфокусировать график и последующие расчеты на интересующей области, Рис. 3-Б.
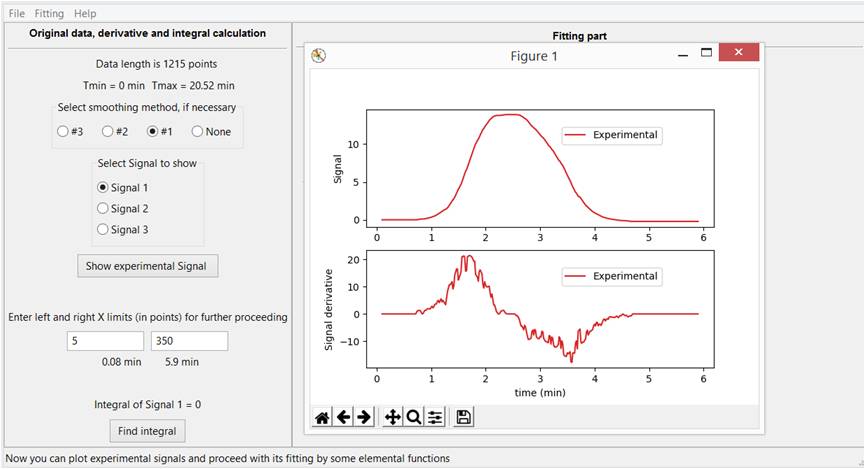
Рис. 3-Б. Задание левой и правой границы интервала наиболее интересной части экспериментальной кривой для дальнейшего фиттинга.
В правой части программы можно задать количество математических функций, используемых для фиттинга и выбрать тип каждой используемой функции. После чего появится возможность задать три значения для каждого параметра выбранной функции. Значения Min, Max соответствуют левой (Min) и правой (Max) границе числового интервала, в котором пользователь будет производить поиск оптимального значения параметра. Величина Def (Min< Def < Max) показывает начальное, оно же текущее значение данного параметра, Рис. 4.
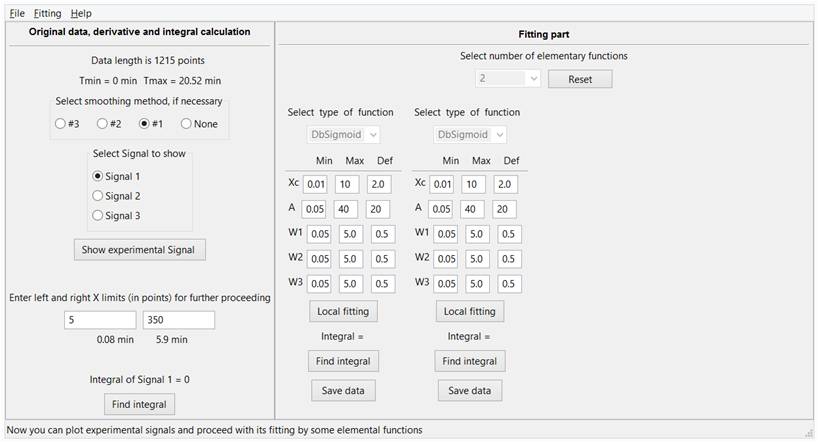
Рис. 4. Выбор числа и типа математических функций, которые будут использованы при фиттинге. При необходимости пользователь может изменить значения Min, Max и Def для каждого из параметров каждой функции.
Далее, либо, оставаясь в рамках одной выбранной функции, пользователь может проводить фиттинг (Local fitting) ее параметров, либо через меню Fitting\Global fitting производить оптимизацию параметров глобальной функции, являющейся суперпозицией двух (и более) локальных функций.
Для начала, удобно "занулить" амплитуду второй функции и добиться некоторого (не обязательно идеального) совпадения профилей левой (или правой) части экспериментального сигнала и его производной с соответствующей частью первой функции и ее производной, Рис. 5-А.
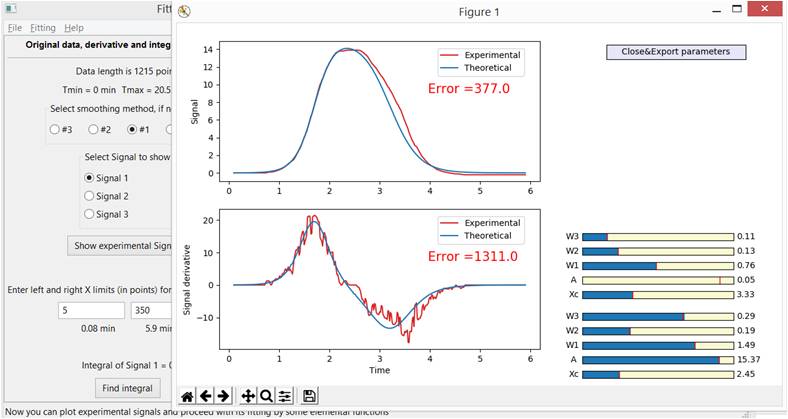
Рис. 5-А. Фиттинг с одной функцией. Попытка получить наилучшее совпадение для левой части экспериментальной кривой. Амплитуда второй функции специально уменьшена практически до нуля.
После получения удовлетворительного результата, "включаем в игру" вторую функцию (Рис. 5-Б) и находим для нее оптимальные параметры. В процессе ее фиттинга, можно вернуться к параметрам 1й функции и убедиться, что ошибка находится в глобальном минимуме по всем ее параметрам.
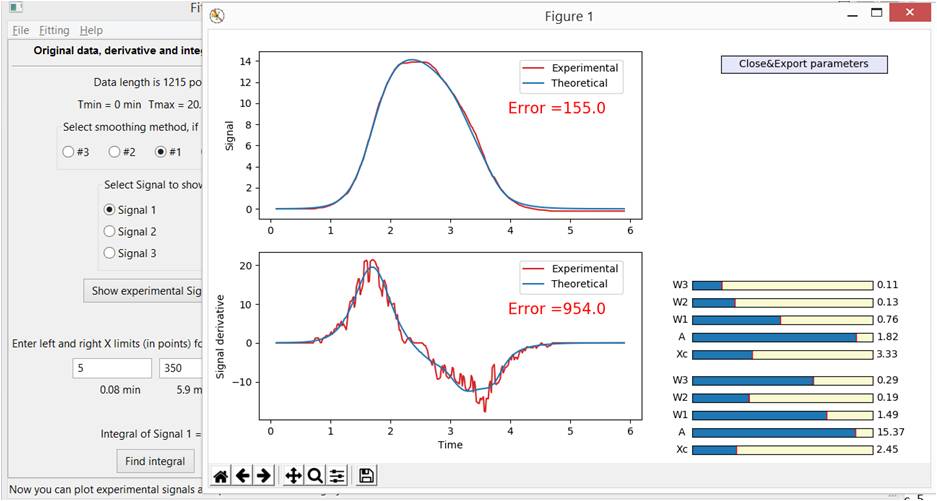
Рис. 5-Б. Фиттинг с двумя функциями дает более лучшее описание оригинального сигнала и его производной (игнорируя оставшиеся шумы в графике производной).
Кнопка "Close&Export parameters" позволяет закрыть окно с графиком и экспортировать текущие параметры в главное окно программы, где можно задать более удобные значения Min и Max для выбранных параметров и еще раз через Fitting\Global fitting продолжить уменьшать ошибку.
Ошибка — она же метрика качества аппроксимации исходного сигнала и его производной определяется по стандартной формуле: