Моя большая практическая шпаргалка SQL (SQLite) с готовыми запросами
- воскресенье, 11 февраля 2024 г. в 00:00:16
Привет, Хабр)
Публикую шпаргалку по SQL, которая долгое время помогала мне, да и сейчас я периодически в неё заглядываю.
Все примеры изначально писались для СУБД SQLite, но почти всё из этого применимо также и к другим СУБД.
Вначале идут очень простые запросы, с них можно начать новичкам. Если хочется чего-то более интересного — листайте вниз. Здесь есть и примеры довольно сложных запросов с агрегирующими функциями, триггерами, длинными подзапросами, с оконными функциями. Помимо этого, часть примеров посвящена работе с SQL в Python при помощи библиотечек sqlite3, pandas, polars. Этот список запросов с комментариями можно использовать как наглядное пособие для изучения SQL.
Большинство советов я публиковал в своем канале по анализу данных, где вы найдете большое количество советов, инструментов и примеров с кодом. А здесь большая полезная папка, которую я собрал в которой куча полезного для работы с данными.

Кстати, все эти примеры SQL заботливо собраны в одной папке, можете скачать её и экспериментировать локально. После скачивания и разархивирования, у вас будет 3 группы файлов:
./db/*.db — базы данных SQLite, которые используются в примерах ниже
./src/*.* — SQL-запросы, сценарии Python
./out/*.* — ожидаемый результат для примеров

Поехали!
Выбираем все значения из таблички
Дополнительные команды SQL
Выбираем нужные столбцы
Сортировка
Ограничение выводимых записей
Ещё некоторые параметры вывода
Удаляем дубликаты
Фильтруем результаты
Более сложные условия фильтрации
Некоторые математические действия
Переименовываем столбцы
Подсчёт с пропущенными значениями
Вывод с условием при помощи WHERE
Условие с отрицанием
Выбираем NULL значения
Агрегирование в SQL
Распространённые агрегирующие функции в SQL
Подсчёт значений при помощи COUNT
Группировка
Как себя ведут неагрегированные столбцы
Выбор нужных столбцов для агрегирования
Фильтрация агрегированных значений
Читабельный вывод
Фильтрация входных данных
Создание табличек
Вставляем данные
Обновляем строки
Удаляем строки
Резервное копирование
Объединение табличек при помощи JOIN
INNER JOIN
Агрегирование объединённых через JOIN записей
LEFT JOIN
Агрегирование данных, собранных через LEFT JOIN
Объединение значений
SELECT DISTINCT и условие WHERE
Использование набора в условии WHERE при помощи IN
Подзапросы
Автоикремент и PRIMARY KEY
Изменение таблички при помощи ALTER
Создание новой таблички на базе старой
Удаление таблички
Сравнение отдельных значений с агрегированными
Сравнение отдельных значений с агрегированными внутри групп
CTE — табличные выражения
Смотрим план запроса с помощью EXPLAIN
Нумеруем строки
Условия if-else
Выбираем с помощью SELECT и CASE
Работаем с диапазоном значений
Ищем по фрагменту с помощью LIKE
Выбираем первую и последнюю строки
Пересечение отдельных табличек
Исключение
Случайные значения в SQL
Создание индексов
Генерация последовательности значений
Генерируем последовательность на основе данных
Генерация последовательностей дат
Подсчитываем количество значений за день, без пропусков
JOIN таблички с собой же
Генерируем уникальные пары значений
Фильтрация пар
EXISTS
NOT EXISTS в SQL
Опережение и отставание
Оконные функции
Используем PARTITION BY в SQL
Данные типа blob
Сохранение JSON
Выбираем отдельные поля в JSON
Доступ к JSON-объекту
Распаковка JSON
Последний элемент в массиве
Модифицируем JSON
Immediate If в SQL
Представление VIEW в SQL
Добавляем проверку CHECK
TRANSACTION в SQL
ROLLBACK в SQL
Откат с помощью ROLLBACK
Вставка значений
Создание триггера
Рекурсивный запрос
Продолжаем работать с bi_contact
Обновляем идентификаторы групп
Рекурсивно устанавливаем метки
Работа с SQL в Python при помощи sqlite3
Инкрементная выборка
Простые операции CREATE, INSERT, DELETE и другие с помощью sqlite3
Интерполируем значения
Выполнение полноценных SQL-запросов в Python
Исключения SQLite в Python
Python и SQLite, ещё некоторые возможности
Работа с датой и временем
SQL в Jupyter Notebooks
Pandas и SQL
Polars и SQL
ORM
Продолжаем работать с ORM
The end

SELECT *
FROM little_penguins;
Adelie|Dream|37.2|18.1|178|3900|MALE
Adelie|Dream|37.6|19.3|181|3300|FEMALE
Gentoo|Biscoe|50|15.3|220|5550|MALE
Adelie|Torgersen|37.3|20.5|199|3775|MALE
Adelie|Biscoe|39.6|17.7|186|3500|FEMALE
Gentoo|Biscoe|47.7|15|216|4750|FEMALE
Adelie|Dream|36.5|18|182|3150|FEMALE
Gentoo|Biscoe|42|13.5|210|4150|FEMALE
Adelie|Torgersen|42.1|19.1|195|4000|MALE
Gentoo|Biscoe|54.3|15.7|231|5650|MALE
ничего особенного, выбираем все записи из таблички little_penguins

.headers on
.mode markdown
SELECT *
FROM little_penguins;
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex |
|---------|-----------|----------------|---------------|-------------------|-------------|--------|
| Adelie | Dream | 37.2 | 18.1 | 178 | 3900 | MALE |
| Adelie | Dream | 37.6 | 19.3 | 181 | 3300 | FEMALE |
| Gentoo | Biscoe | 50 | 15.3 | 220 | 5550 | MALE |
| Adelie | Torgersen | 37.3 | 20.5 | 199 | 3775 | MALE |
| Adelie | Biscoe | 39.6 | 17.7 | 186 | 3500 | FEMALE |
| Gentoo | Biscoe | 47.7 | 15 | 216 | 4750 | FEMALE |
| Adelie | Dream | 36.5 | 18 | 182 | 3150 | FEMALE |
| Gentoo | Biscoe | 42 | 13.5 | 210 | 4150 | FEMALE |
| Adelie | Torgersen | 42.1 | 19.1 | 195 | 4000 | MALE |
| Gentoo | Biscoe | 54.3 | 15.7 | 231 | 5650 | MALE |
включаем заголовки и режим markdown; в SQLite подобные команды начинаются с ., а в PostgreSQL с \
кстати, для просмотра дополнительной инфы или чтобы узнать, какие команды есть, используйте .help

SELECT species,
island,
sex
FROM little_penguins;
| species | island | sex |
|---------|-----------|--------|
| Adelie | Dream | MALE |
| Adelie | Dream | FEMALE |
| Gentoo | Biscoe | MALE |
| Adelie | Torgersen | MALE |
| Adelie | Biscoe | FEMALE |
| Gentoo | Biscoe | FEMALE |
| Adelie | Dream | FEMALE |
| Gentoo | Biscoe | FEMALE |
| Adelie | Torgersen | MALE |
| Gentoo | Biscoe | MALE |
выбираем колонки species, island, sex из таблички little_penguins

SELECT species,
sex,
island
FROM little_penguins
ORDER BY island ASC,
sex DESC;
| species | sex | island |
|---------|--------|-----------|
| Gentoo | MALE | Biscoe |
| Gentoo | MALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
| Adelie | MALE | Dream |
| Adelie | FEMALE | Dream |
| Adelie | FEMALE | Dream |
| Adelie | MALE | Torgersen |
| Adelie | MALE | Torgersen |
выбираем столбцы species, island, sex из таблички little_penguins
сортируем все значения из island в возрастающем порядке (от A к Z)
строки с одинаковыми значениями island дополнительно сортируем по их значениям sex в обратном порядке, от большего к меньшему (от Z к A)

SELECT species,
sex,
island
FROM penguins
ORDER BY species,
sex,
island
LIMIT 10;
| species | sex | island |
|---------|--------|-----------|
| Adelie | | Dream |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
выбираем столбцы species, sex, island из таблички penguins
сортируем по species в порядке возрастания, строки с одинаковым значением species сортируются по sex, с одинаковым sex дополнительно сортируются по island
ну и выводим только первые 10 строк

SELECT species,
sex,
island
FROM penguins
ORDER BY species,
sex,
island
LIMIT 10
OFFSET 3;
| species | sex | island |
|---------|--------|-----------|
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
| Adelie | FEMALE | Biscoe |
OFFSET указывается после LIMIT и позволяет пропустить сколько-то первых строк, в данном случае пропущены 3 первых строки

SELECT DISTINCT species,
sex,
island
FROM penguins;
| species | sex | island |
|-----------|--------|-----------|
| Adelie | MALE | Torgersen |
| Adelie | FEMALE | Torgersen |
| Adelie | | Torgersen |
| Adelie | FEMALE | Biscoe |
| Adelie | MALE | Biscoe |
| Adelie | FEMALE | Dream |
| Adelie | MALE | Dream |
| Adelie | | Dream |
| Chinstrap | FEMALE | Dream |
| Chinstrap | MALE | Dream |
| Gentoo | FEMALE | Biscoe |
| Gentoo | MALE | Biscoe |
| Gentoo | | Biscoe |
SELECT DISTINCT — выбираем уникальные комбинации из столбцов species, sex, island

SELECT DISTINCT species,
sex,
island
FROM penguins
WHERE island = 'Biscoe';
| species | sex | island |
|---------|--------|--------|
| Adelie | FEMALE | Biscoe |
| Adelie | MALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
| Gentoo | MALE | Biscoe |
| Gentoo | | Biscoe |
выбираем уникальные комбинации значений species, sex, island из penguins, где значения поля island равно Biscoe

SELECT DISTINCT species,
sex,
island
FROM penguins
WHERE island = 'Biscoe'
AND sex != 'MALE';
| species | sex | island |
|---------|--------|--------|
| Adelie | FEMALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
выбираем уникальные комбинации значений species, sex, island из penguins, где значения поля island равно Biscoe, а значения поля sex не равно MALE

SELECT flipper_length_mm / 10.0,
body_mass_g / 1000.0
FROM penguins
LIMIT 3;
| flipper_length_mm / 10.0 | body_mass_g / 1000.0 |
|--------------------------|----------------------|
| 18.1 | 3.75 |
| 18.6 | 3.8 |
| 19.5 | 3.25 |
выводим 3 первых строки значений flipper_length_mm, делённых на 10.0, и значений body_mass_g, делённых на 1000.0

SELECT flipper_length_mm / 10.0 AS flipper_cm,
body_mass_g / 1000.0 AS weight_kg,
island AS where_found
FROM penguins
LIMIT 3;
| flipper_cm | weight_kg | where_found |
|------------|-----------|-------------|
| 18.1 | 3.75 | Torgersen |
| 18.6 | 3.8 | Torgersen |
| 19.5 | 3.25 | Torgersen |
делим значения flipper_length_mm на 10.0, делим значения body_mass_g на 1000.0
переименовываем столбцы flipper_length_mm — в flipper_cm, body_mass_g — в weight_kg, island — в where_found
выводим первые 3 строки
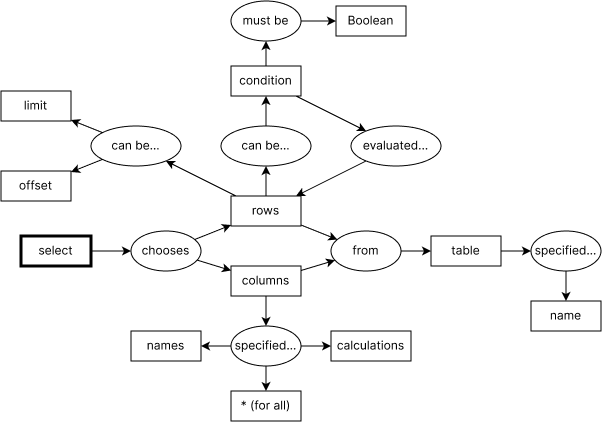
Взаимосвязь рассмотренных понятий SQL можно показать так:

SELECT flipper_length_mm / 10.0 AS flipper_cm,
body_mass_g / 1000.0 AS weight_kg,
island AS where_found
FROM penguins
LIMIT 5;
| flipper_cm | weight_kg | where_found |
|------------|-----------|-------------|
| 18.1 | 3.75 | Torgersen |
| 18.6 | 3.8 | Torgersen |
| 19.5 | 3.25 | Torgersen |
| | | Torgersen |
| 19.3 | 3.45 | Torgersen |
делим значения из flipper_length_mm на 10, затем присваиваем результаты новому столбцу flipper_cm
делим значения из столбца body_mass_g на 1000 и затем присваивание результатов новому столбцу weight_kg
переименовываем island в where_found

SELECT DISTINCT species,
sex,
island
FROM penguins
WHERE island = 'Biscoe';
| species | sex | island |
|---------|--------|--------|
| Adelie | FEMALE | Biscoe |
| Adelie | MALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
| Gentoo | MALE | Biscoe |
| Gentoo | | Biscoe |
выбираем столбцы species, sex, island
выводим все записи из penguins, где значение island равно 'Biscoe'
SELECT DISTINCT species,
sex,
island
FROM penguins
WHERE island = 'Biscoe'
AND sex = 'FEMALE';
| species | sex | island |
|---------|--------|--------|
| Adelie | FEMALE | Biscoe |
| Gentoo | FEMALE | Biscoe |
выводим все записи из penguins, где значение island равно 'Biscoe' и значение sex равно 'FEMALE'

условие с оператором отрицания != тоже без проблем работает
SELECT DISTINCT species,
sex,
island
FROM penguins
WHERE island = 'Biscoe'
AND sex != 'FEMALE';
| species | sex | island |
|---------|------|--------|
| Adelie | MALE | Biscoe |
| Gentoo | MALE | Biscoe |

SELECT species,
sex,
island
FROM penguins
WHERE sex IS NULL;
| species | sex | island |
|---------|-----|-----------|
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Torgersen |
| Adelie | | Dream |
| Gentoo | | Biscoe |
| Gentoo | | Biscoe |
| Gentoo | | Biscoe |
| Gentoo | | Biscoe |
| Gentoo | | Biscoe |
выбираем строки со значениями species, sex, island из таблички penguins, где значения sex нет (NULL)
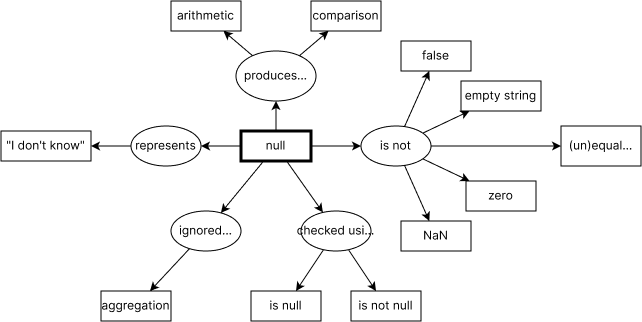
Вот так можно показать связь понятий SQL, которые мы рассмотрели выше:

SELECT sum(body_mass_g) AS total_mass
FROM penguins;
| total_mass |
|------------|
| 1437000 |
суммируем все значения колонки body_mass_g, сохраняем в новый столбец total_mass

SELECT MAX(bill_length_mm) AS longest_bill,
MIN(flipper_length_mm) AS shortest_flipper,
AVG(bill_length_mm) / AVG(bill_depth_mm) AS weird_ratio
FROM penguins;
| longest_bill | shortest_flipper | weird_ratio |
|--------------|------------------|------------------|
| 59.6 | 172 | 2.56087082530644 |
находим максимальное значение из столбца bill_length_mm, записываем это значение как longest_bill
аналогично находим минимальное из flipper_length_mm, находим среднее из bill_length_mm, среднее из bill_depth_mm

SELECT COUNT(*) AS count_star,
COUNT(sex) AS count_specific,
COUNT(DISTINCT sex) AS count_distinct
FROM penguins;
| count_star | count_specific | count_distinct |
|------------|----------------|----------------|
| 344 | 333 | 2 |
COUNT(*) — считаем все значения из count_star
COUNT(sex) — считаем все значения из столбца sex
COUNT(DISTINCT sex) — считаем уникальные значения из sex (очевидно их 2: MALE, FEMALE)
записываем эти 3 числа как count_star, count_specific, count_distinct соответственно

SELECT AVG(body_mass_g) AS average_mass_g
FROM penguins
GROUP BY sex;
| average_mass_g |
|------------------|
| 4005.55555555556 |
| 3862.27272727273 |
| 4545.68452380952 |
из таблички penguins находим среднее всех значений body_mass_g, сохраняем как average_mass_g
группируем по значениям sex (группы FEMALE, MALE, NULL)

SELECT sex,
AVG(body_mass_g) AS average_mass_g
FROM penguins
GROUP BY sex;
| sex | average_mass_g |
|--------|------------------|
| | 4005.55555555556 |
| FEMALE | 3862.27272727273 |
| MALE | 4545.68452380952 |
для того, чтобы было видно названия отдельных групп, выбираем не только среднее AVG(body_mass_g), но и sex
видим 3 группы: NULL, FEMALE, MALE

src/arbitrary_in_aggregation.sql
SELECT sex,
body_mass_g
FROM penguins
GROUP BY sex;
out/arbitrary_in_aggregation.out
| sex | body_mass_g |
|--------|-------------|
| | |
| FEMALE | 3800 |
| MALE | 3750 |
здесь у нас популярная ошибка, мы просто выбираем body_mass_g, а не находим среднее, поэтому SQL выбирает любые значения из body_mass_g. Аккуратнее)

SELECT sex,
AVG(body_mass_g) AS average_mass_g
FROM penguins
GROUP BY sex
HAVING average_mass_g > 4000.0;
| sex | average_mass_g |
|------|------------------|
| | 4005.55555555556 |
| MALE | 4545.68452380952 |
здесь мы используем HAVING вместо WHERE (эффект тот же самый), оставляем только те значения из average_mass_g, которые больше 4000

SELECT sex,
ROUND(AVG(body_mass_g), 1) AS average_mass_g
FROM penguins
GROUP BY sex
HAVING average_mass_g > 4000.0;
| sex | average_mass_g |
|------|----------------|
| | 4005.6 |
| MALE | 4545.7 |
округляем среднее AVG(body_mass_g до 1 знака после запятой, используя ROUND

src/filter_aggregate_inputs.sql
SELECT sex,
ROUND(
AVG(body_mass_g) FILTER (WHERE body_mass_g < 4000.0),
1)
AS average_mass_g
FROM penguins
GROUP BY sex;
out/filter_aggregate_inputs.out
| sex | average_mass_g |
|--------|----------------|
| | 3362.5 |
| FEMALE | 3417.3 |
| MALE | 3752.5 |
при помощи FILTER мы находим среднее только тех значений body_mass_g, которые меньше 4000
округляем до 1 знака после запятой, сохраняем в столбец average_mass_g
группируем по sex
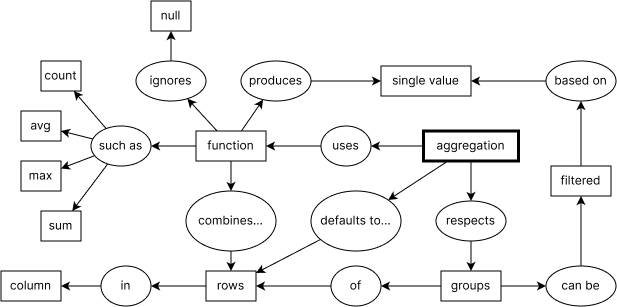
Вот так выглядит связь основных понятий, которые мы только что обсуждали:
Кстати, вот так выглядит создание БД в оперативной памяти:
sqlite3 :memory:
запускаем интерактивную оболочку SQLite, создаём новую базу данных в оперативной памяти для более быстрой работы

CREATE TABLE job (name text NOT NULL,
billable real NOT NULL);
CREATE TABLE work (person text NOT NULL,
job text NOT NULL);
создаём таблицу job со столбцами: name — столбец текстовых значений, не может быть пустым (NOT NULL), billable — содержит вещественные числа, не может быть пустым
создаём табличку work со столбцами: person — текстовый, не может быть пустым, job — текстовый, не может быть пустым

INSERT INTO job
VALUES ('calibrate', 1.5),
('clean', 0.5);
INSERT INTO work
VALUES ('mik', 'calibrate'),
('mik', 'clean'),
('mik', 'complain'),
('po', 'clean'),
('po', 'complain'),
('tay', 'complain');
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
| clean | 0.5 |
| person | job |
|--------|-----------|
| mik | calibrate |
| mik | clean |
| mik | complain |
| po | clean |
| po | complain |
| tay | complain |
ничего особенного, заполняем табличку job парами name-billable, и так же заполняем табличку work парами person-job

UPDATE work
SET person = "tae"
WHERE person = "tay";
| person | job |
|--------|-----------|
| mik | calibrate |
| mik | clean |
| mik | complain |
| po | clean |
| po | complain |
| tae | complain |
меняем все записи "tay" на "tae"

DELETE FROM work
WHERE person = "tae";
SELECT *
FROM work;
| person | job |
|--------|-----------|
| mik | calibrate |
| mik | clean |
| mik | complain |
| po | clean |
| po | complain |
удаляем все строки, где значение person равно "tae"

CREATE TABLE backup (person text NOT NULL,
job text NOT NULL);
INSERT INTO backup
SELECT person,
job
FROM work
WHERE person = 'tae';
DELETE FROM work
WHERE person = 'tae';
SELECT *
FROM backup;
| person | job |
|--------|----------|
| tae | complain |
создаём табличку backup c текстовыми столбцами person и job
помещаем внутрь backup значения столбцов person и job из таблицы work, где значения столбца person равно 'tae'
удаляем из work все записи со значением person равным 'tae'
отображаем записи таблички backup
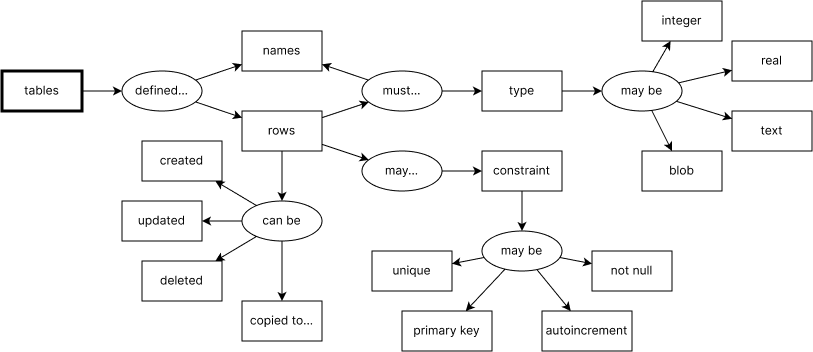
Вот так выглядит связь основных понятий, которые мы только что обсуждали:

SELECT *
FROM work
CROSS JOIN job;
| person | job | name | billable |
|--------|-----------|-----------|----------|
| mik | calibrate | calibrate | 1.5 |
| mik | calibrate | clean | 0.5 |
| mik | clean | calibrate | 1.5 |
| mik | clean | clean | 0.5 |
| mik | complain | calibrate | 1.5 |
| mik | complain | clean | 0.5 |
| po | clean | calibrate | 1.5 |
| po | clean | clean | 0.5 |
| po | complain | calibrate | 1.5 |
| po | complain | clean | 0.5 |
| tay | complain | calibrate | 1.5 |
| tay | complain | clean | 0.5 |
делаем CROSS JOIN для 2 таблиц work и job — все возможные комбинации строк из этих таблиц (если в work 3 строки, а в job 4 строки, то результат будет иметь 4 ⋅ 3 = 12 строк)

SELECT *
FROM work
INNER JOIN job ON work.job = job.name;
| person | job | name | billable |
|--------|-----------|-----------|----------|
| mik | calibrate | calibrate | 1.5 |
| mik | clean | clean | 0.5 |
| po | clean | clean | 0.5 |
объединяем 2 таблицы work и job — берём те записи, где значение job из work совпадает со значением name из job

SELECT work.person,
SUM(job.billable) AS pay
FROM work
INNER JOIN job ON work.job = job.name
GROUP BY work.person;
| person | pay |
|--------|-----|
| mik | 2.0 |
| po | 0.5 |
объединяем те строки таблиц work и job, где значение job в таблице work соответствует значению name в job
суммируем значения billable из таблицы job для каждого значения person из таблицы work
группируем результаты по значениям person из work

SELECT *
FROM work
LEFT JOIN job ON work.job = job.name;
| person | job | name | billable |
|--------|-----------|-----------|----------|
| mik | calibrate | calibrate | 1.5 |
| mik | clean | clean | 0.5 |
| mik | complain | | |
| po | clean | clean | 0.5 |
| po | complain | | |
| tay | complain | | |
склеиваем таблицы work и job по соответствующим значениям столбца job
если в таблице work есть строки, для которых нет совпадений в таблице job, то они все равно будут включены в результат с пустыми (NULL) значениями
использование LEFT JOIN гарантирует, что все строки из левой таблицы work будут включены в результат, независимо от наличия совпадающих строк в правой таблице job

SELECT work.person,
sum(job.billable) AS pay
FROM work
LEFT JOIN job ON work.job = job.name
GROUP BY work.person;
| person | pay |
|--------|-----|
| mik | 2.0 |
| po | 0.5 |
| tay | |
вычисляем сумму значений столбца billable из job, сохраняем как pay
используем LEFT JOIN, чтобы гарантированно включить все строки из work в job
группируем по столбцу person из work
Вот так выглядит связь основных понятий, которые мы только что обсуждали:


SELECT work.person,
COALESCE(SUM(job.billable), 0.0) AS pay
FROM work
LEFT JOIN job ON work.job = job.name
GROUP BY work.person;
| person | pay |
|--------|-----|
| mik | 2.0 |
| po | 0.5 |
| tay | 0.0 |
COALESCE используется для замены NULL на 0.0, если сумма billable для данного person равна NULL
LEFT JOIN включает все записи из work и только соответствующие записи из job
группируем по значениям столбца person из work

SELECT DISTINCT person
FROM work
WHERE job != 'calibrate';
| person |
|--------|
| mik |
| po |
| tay |
выбираем уникальные значения из столбца person, где поле job не равно calibrate

SELECT *
FROM work
WHERE person NOT IN ('mik',
'tay');
| person | job |
|--------|----------|
| po | clean |
| po | complain |
выбираем все строки из work, где person не равно 'mik' и не равно 'tay'

SELECT DISTINCT person
FROM work
WHERE person not in
(SELECT DISTINCT person
FROM work
WHERE job = 'calibrate');
| person |
|--------|
| po |
| tay |
внутренний подзапрос выбирает уникальные значения столбца person из work, где в поле job стоит 'calibrate'
внешний, главный запрос выбирает те уникальные значения person, где person не равно значениям из внутренного подзапроса

CREATE TABLE person (ident integer PRIMARY KEY autoincrement,
name text NOT NULL);
INSERT INTO person
VALUES (NULL, 'mik'),
(NULL, 'po'),
(NULL, 'tay');
SELECT *
FROM person;
INSERT INTO person
VALUES (1, "prevented");
| ident | name |
|-------|------|
| 1 | mik |
| 2 | po |
| 3 | tay |
Runtime error near line 12: UNIQUE constraint failed: person.ident (19)
создаём табличку person с 2 столбцами: ident с целочисленными значениями, name с текстовыми значениями; столбец ident устанавливаем как PRIMARY KEY, включаем автоматическое инкрементирование значений
помещаем в таблицу person 3 пары ident-name
при попытке добавить ещё одну пару (1, "prevented") возникает ошибка, поскольку уже существует строка с indent равным 1
Внутренняя табличка:
SELECT *
FROM sqlite_sequence;
| name | seq |
|--------|-----|
| person | 3 |
выводим все текущие значения автоинкрементных счетчиков для таблиц в БД SQLite

ALTER TABLE job ADD ident integer NOT NULL DEFAULT -1;
UPDATE job
SET ident = 1
WHERE name = 'calibrate';
UPDATE job
SET ident = 2
WHERE name = 'clean';
SELECT *
FROM job;
| name | billable | ident |
|-----------|----------|-------|
| calibrate | 1.5 | 1 |
| clean | 0.5 | 2 |
добавляем новый столбец ident в табличку job; столбец заполняется целыми числами, не может быть пустым; ставим значение по умолчанию -1 для этого столбца
делаем значение столбца ident равным 1 там, где name равен 'calibrate'
устанавливаем значение ident равным 2 для строки, где name равен clean

CREATE TABLE new_work (person_id integer NOT NULL,
job_id integer NOT NULL,
FOREIGN key(person_id) REFERENCES person(ident),
FOREIGN key(job_id) REFERENCES job(ident));
INSERT INTO new_work
SELECT person.ident AS person_id,
job.ident AS job_id
FROM (person
JOIN work
ON person.name = work.person)
JOIN job ON job.name = work.job;
SELECT *
FROM new_work;
| person_id | job_id |
|-----------|--------|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
создаём таблицу new_work с 2 целочисленными столбцами: person_id и job_id; оба столбца не могут быть пустыми
2 FOREIGN KEY ограничения добавляются, чтобы связать столбцы person_id и job_id новой таблицы new_work с соответствующими столбцами ident в таблицах person и job
добавляем данные в таблицу new_work, используя результат запроса SELECT
FROM (person JOIN work ON person.name = work.person) — данные будут выбраны из результатов соединения таблиц person и work по условию равенства значений столбца name в таблице person и столбца person в таблице work
JOIN job ON job.name = work.job — результаты предыдущего соединения будут дополнительно соединены с таблицей job по условию равенства значений столбца name в таблице job и столбца job в work

DROP TABLE work;
ALTER TABLE new_work RENAME TO work;
удаляем work из БД
изменяем имя таблички new_work на work
CREATE TABLE job (ident integer PRIMARY KEY autoincrement,
name text NOT NULL,
billable real NOT NULL);
CREATE TABLE sqlite_sequence(name,
seq);
CREATE TABLE person (ident integer PRIMARY KEY autoincrement,
name text NOT NULL);
CREATE TABLE IF NOT EXISTS "work" (person_id integer NOT NULL,
job_id integer NOT NULL,
FOREIGN key(person_id) REFERENCES person(ident),
FOREIGN key(job_id) REFERENCES job(ident));
создаём таблицу job с 3 колонками: ident хранит целые числа, используется в качестве первичного ключа (PRIMARY KEY) и автоматически увеличивается (autoincrement);
name текстовый столбец, не может быть пустым (NOT NULL);
billable — столбец вещественных чисел, не может быть пустым
создаём sqlite_sequence с 2 колонками: name и seq
создаём таблицу person с 2 колонками: ident — хранит целые числа, используется в качестве первичного ключа и автоматически увеличивается (autoincrement), name — хранит текст, не может быть пустым
создаём work с 4 колонками: person_id - хранит целые числа, не может быть пустым; аналогичный столбец job_id
устанавливаем внешние ключи, связывающие person_id с ident в таблице person и job_id с ident в таблице job

src/compare_individual_aggregate.sql
SELECT body_mass_g
FROM penguins
WHERE body_mass_g > (SELECT AVG(body_mass_g)
FROM penguins)
LIMIT 5;
out/compare_individual_aggregate.out
| body_mass_g |
|-------------|
| 4675 |
| 4250 |
| 4400 |
| 4500 |
| 4650 |
выбираем только те строки, где значение в столбце body_mass_g больше, чем среднее значение body_mass_g по всем строкам в таблице penguins
ну и выводим только первые 5 строк

SELECT penguins.species,
penguins.body_mass_g,
Round(averaged.avg_mass_g, 1) AS avg_mass_g
FROM penguins
JOIN (SELECT species,
Avg(body_mass_g) AS avg_mass_g
FROM penguins
GROUP BY species) AS averaged
ON penguins.species = averaged.species
WHERE penguins.body_mass_g > averaged.avg_mass_g
LIMIT 5;
| species | body_mass_g | avg_mass_g |
|---------|-------------|------------|
| Adelie | 3750 | 3700.7 |
| Adelie | 3800 | 3700.7 |
| Adelie | 4675 | 3700.7 |
| Adelie | 4250 | 3700.7 |
| Adelie | 3800 | 3700.7 |
выбираем столбцы species и body_mass_g из таблицы penguins
вычисляем среднюю массу для каждого вида пингвина, округляем до 1 знака после запятой, используя подзапрос, который связывается с исходной таблицей penguins по полю species
используя результаты подзапроса, фильтруем только те записи, где масса пингвина больше средней массы для его вида
выводим только первые 5 записей

src/common_table_expressions.sql
WITH grouped AS
(SELECT species,
avg(body_mass_g) AS avg_mass_g
FROM penguins
GROUP BY species)
SELECT penguins.species,
penguins.body_mass_g,
round(grouped.avg_mass_g, 1) AS avg_mass_g
FROM penguins
JOIN grouped
WHERE penguins.body_mass_g > grouped.avg_mass_g
LIMIT 5;
out/common_table_expressions.out
| species | body_mass_g | avg_mass_g |
|---------|-------------|------------|
| Adelie | 3750 | 3700.7 |
| Adelie | 3800 | 3700.7 |
| Adelie | 4675 | 3700.7 |
| Adelie | 4250 | 3700.7 |
| Adelie | 3800 | 3700.7 |
создаём табличку grouped (с помощью WITH), которая содержит среднюю массу тела пингвинов (AVG(body_mass_g)) для каждого вида из penguins (GROUP BY species)
из penguins выбираем такие столбцы: species, body_mass_g; и из из общей таблицы grouped выбираем avg_mass_g, округлённое до 1 знака
объединяем penguins с общей таблицей grouped (через JOIN); для каждого пингвина будет найдена соответствующая средняя масса тела для его вида
WHERE — фильтруем; оставляем только тех, у которых масса тела больше средней массы их вида
выводим только первые 5 строк

EXPLAIN query PLAN
SELECT species,
AVG(body_mass_g)
FROM penguins
GROUP BY species;
QUERY PLAN
|--SCAN penguins
`--USE TEMP B-TREE FOR GROUP BY
EXPLAIN query PLAN — получаем план выполнения запроса, как будет выполнен запрос в базе данных
выбираем столбец species, вычисляем среднее значение столбца body_mass_g для каждого вида из penguins
GROUP BY species — группируем результаты по столбцу species

каждая таблица имеет специальный столбец rowid с уникальными числовыми идентификаторами
SELECT rowid, species, island
FROM penguins
LIMIT 5;
| rowid | species | island |
|-------|---------|-----------|
| 1 | Adelie | Torgersen |
| 2 | Adelie | Torgersen |
| 3 | Adelie | Torgersen |
| 4 | Adelie | Torgersen |
| 5 | Adelie | Torgersen |

WITH sized_penguins AS
(SELECT species,
IIF(body_mass_g < 3500, 'small', 'large') AS size
FROM penguins)
SELECT species,
size,
count(*) AS num
FROM sized_penguins
GROUP BY species,
size
ORDER BY species,
num;
| species | size | num |
|-----------|-------|-----|
| Adelie | small | 54 |
| Adelie | large | 98 |
| Chinstrap | small | 17 |
| Chinstrap | large | 51 |
| Gentoo | large | 124 |
создаём временную таблицу sized_penguins, которая содержит два столбца: species и size
size определяется на основе условия: если body_mass_g меньше 3500, то он считается 'small', в противном случае - 'large'
выбираем столбцы species и size из временной таблицы sized_penguins, а подсчитываем количество записей для каждой комбинации species и size, используя функцию count(*)
группируем данные (GROUP BY) по species и size

WITH sized_penguins AS
(SELECT species,
CASE
WHEN body_mass_g < 3500 THEN 'small'
WHEN body_mass_g < 5000 THEN 'medium'
ELSE 'large'
END AS SIZE
FROM penguins)
SELECT species,
SIZE,
count(*) AS num
FROM sized_penguins
GROUP BY species,
SIZE
ORDER BY species,
num;
| species | size | num |
|-----------|--------|-----|
| Adelie | large | 1 |
| Adelie | small | 54 |
| Adelie | medium | 97 |
| Chinstrap | small | 17 |
| Chinstrap | medium | 51 |
| Gentoo | medium | 56 |
| Gentoo | large | 68 |
в блоке WITH создаём набор данных с именем sized_penguins, где находится species и size, определенные на body_mass_g
CASE разделяет пингвинов на 3 категории: 'small', 'medium' и 'large' в зависимости от их массы
в основном блоке SELECT выбираются вид пингвина, его размер и количество пингвинов каждого размера (num) из набора sized_penguins
результаты группируются по виду пингвина и их размеру с помощью GROUP BY
в конце запроса результаты сортируются сначала по species в алфавитном порядке, а затем по num

WITH sized_penguins AS
(SELECT species,
CASE
WHEN body_mass_g BETWEEN 3500 AND 5000 THEN 'normal'
ELSE 'abnormal'
END AS SIZE
FROM penguins)
SELECT species,
SIZE,
count(*) AS num
FROM sized_penguins
GROUP BY species,
SIZE
ORDER BY species,
num;
| species | size | num |
|-----------|----------|-----|
| Adelie | abnormal | 55 |
| Adelie | normal | 97 |
| Chinstrap | abnormal | 17 |
| Chinstrap | normal | 51 |
| Gentoo | abnormal | 62 |
| Gentoo | normal | 62 |
создаём общую таблицу выражений (CTE) sized_penguins, она выбирает вид пингвина и определяет его размер в зависимости от массы тела; если масса в диапазоне от 3500 до 5000 г, это размер normal, в противном случае - abnormal
затем из этой CTE извлекаем данные с указанием видов пингвинов, их размеров и количества пингвинов каждого вида и размера, используя SELECT с агрегирующей функцией COUNT(*)
группируем по виду и размеру пингвина с помощью GROUP BY
сортируем результат по виду и количеству пингвинов в порядке возрастания с помощью ORDER BY
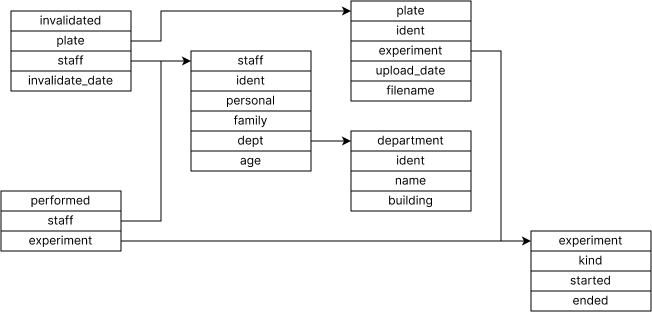
Ещё одна БД:
ER-диаграмма показывает отношения между отдельными табличками и выглядит так:

SELECT *
FROM staff;
| ident | personal | family | dept | age |
|-------|----------|-----------|------|-----|
| 1 | Kartik | Gupta | | 46 |
| 2 | Divit | Dhaliwal | hist | 34 |
| 3 | Indrans | Sridhar | mb | 47 |
| 4 | Pranay | Khanna | mb | 51 |
| 5 | Riaan | Dua | | 23 |
| 6 | Vedika | Rout | hist | 45 |
| 7 | Abram | Chokshi | gen | 23 |
| 8 | Romil | Kapoor | hist | 38 |
| 9 | Ishaan | Ramaswamy | mb | 35 |
| 10 | Nitya | Lal | gen | 52 |

SELECT personal,
family
FROM staff
WHERE personal LIKE '%ya%'
OR family GLOB '*De*';
| personal | family |
|----------|--------|
| Nitya | Lal |
SELECT personal, family — хотим выбрать столбцы personal и family из таблицы staff
FROM staff — ну понятно, запрос будет выполнен в таблице staff
'%ya%' — хотим выбрать строки, в которых значение столбца personal содержит подстроку ya (с помощью LIKE) или значение столбца family содержит De (с помощью GLOB)

SELECT *
FROM
(SELECT *
FROM
(SELECT *
FROM experiment
ORDER BY started ASC
LIMIT 5)
UNION ALL SELECT *
FROM
(SELECT *
FROM experiment
ORDER BY started DESC
LIMIT 5))
ORDER BY started ASC ;
| ident | kind | started | ended |
|-------|-------------|------------|------------|
| 17 | trial | 2023-01-29 | 2023-01-30 |
| 35 | calibration | 2023-01-30 | 2023-01-30 |
| 36 | trial | 2023-02-02 | 2023-02-03 |
| 25 | trial | 2023-02-12 | 2023-02-14 |
| 2 | calibration | 2023-02-14 | 2023-02-14 |
| 40 | calibration | 2024-01-21 | 2024-01-21 |
| 12 | trial | 2024-01-26 | 2024-01-28 |
| 44 | trial | 2024-01-27 | 2024-01-29 |
| 34 | trial | 2024-02-01 | 2024-02-02 |
| 14 | calibration | 2024-02-03 | 2024-02-03 |
выбираем 5 самых старых записей из таблицы experiment, отсортированных по возрастанию даты начала (started ASC) с помощью подзапроса (внутренний SELECT)
выбираем 5 самых новых записей из experiment, отсортированных по убыванию даты начала (started DESC) с помощью другого подзапроса
объединяем эти 2 подзапроса с помощью UNION ALL, так мы получаем временную таблицу, содержащую 10 записей (5 самых старых и 5 самых новых)
из временной таблицы выбираем все столбцы для каждой записи (SELECT *) и окончательно сортируем записи по возрастанию даты начала (started ASC) с помощью внешнего ORDER BY

SELECT personal,
family,
dept,
age
FROM staff
WHERE dept = 'mb' INTERSECT
SELECT personal,
family,
dept,
age
FROM staff WHERE age < 50 ;
| personal | family | dept | age |
|----------|-----------|------|-----|
| Indrans | Sridhar | mb | 47 |
| Ishaan | Ramaswamy | mb | 35 |
здесь мы используем INTERSECT для объединения результатов двух отдельных запросов
вначале выбираем данные из таблицы staff, в которых значение поля dept равно 'mb'
потом выбираем данные из таблицы staff, в которых значение поля age меньше 50
с помощью INTERSECT мы находим пересечение, то есть строки, которые являются общими для результатов обоих запросов
в результате будут выбраны строки, которые присутствуют в обоих результатах, то есть записи из staff, где значение dept равно 'mb' и значение age меньше 50

SELECT personal,
family,
dept,
age
FROM staff
WHERE dept = 'mb'
EXCEPT
SELECT personal,
family,
dept,
age
FROM staff
WHERE age < 50 ;
| personal | family | dept | age |
|----------|--------|------|-----|
| Pranay | Khanna | mb | 51 |
при помощи SELECT извлекаем 4 поля из staff: personal, family, dept и age
затем используем WHERE, чтобы отфильтровать только те строки, в которых значение dept равно 'mb'
после этого при помощи EXCEPT удаляем из исходного результата любые строки, которые также присутствуют в результате второго запроса
второй запрос SELECT также извлекает четыре поля из staff: personal, family, dept и age
используем WHERE, чтобы отфильтровать только те строки, где значение age меньше 50

WITH decorated AS
(SELECT random() AS rand,
personal || ' ' || family AS name
FROM staff)
SELECT rand,
abs(rand) % 10 AS selector,
name
FROM decorated
WHERE selector < 5;
| rand | selector | name |
|----------------------|----------|-----------------|
| 7176652035743196310 | 0 | Divit Dhaliwal |
| -2243654635505630380 | 2 | Indrans Sridhar |
| -6940074802089166303 | 5 | Pranay Khanna |
| 8882650891091088193 | 9 | Riaan Dua |
| -45079732302991538 | 5 | Vedika Rout |
| -8973877087806386134 | 2 | Abram Chokshi |
| 3360598450426870356 | 9 | Romil Kapoor |
создаём временную таблицу decorated
в этой таблице извлекается случайное число с помощью random()
конкатенируем значения personal и family под именем name с помощью ' ' для разделения
таким образом создаём временную таблицу, содержащую столбцы rand с случайными числами и name со значениями из столбцов personal и family таблицы staff
делаем выборку из временной таблицы decorated; в выборку включаем столбцы rand, name
abs(rand) % 10 — это мы вычисляем остаток от деления абсолютного значения rand на 10
ну и в конце оставляем только строки, где selector меньше 5

EXPLAIN query PLAN
SELECT filename
FROM plate
WHERE filename like '%07%';
CREATE INDEX plate_file ON plate(filename);
EXPLAIN query PLAN
SELECT filename
FROM plate
WHERE filename like '%07%';
QUERY PLAN
`--SCAN plate USING COVERING INDEX sqlite_autoindex_plate_1
QUERY PLAN
`--SCAN plate USING COVERING INDEX plate_file
выбираем все значения столбца filename из таблицы plate, где значение столбца filename содержит подстроку 07
создаём индекс с именем plate_file для столбца filename в таблице plate
запрашиваем план выполнения запроса (EXPLAIN query PLAN)

SELECT value
FROM generate_series(1, 5);
| value |
|-------|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
generate_series(1, 5) — генерируем ряд чисел от 1 до 5
SELECT value — выбираем этот столбец value со сгенерированными числами от 1 до 5

CREATE TABLE temp (num integer NOT NULL);
INSERT INTO temp
VALUES (1),
(5);
SELECT value
FROM generate_series ((SELECT min(num)
FROM TEMP),
(SELECT max(num)
FROM TEMP));
| value |
|-------|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
создаём временную таблицу temp, которая содержит 1 столбец с именем num типа integer; этот столбец не может быть пустым
помещаем в temp значения 1 и 5 в столбец num
используем generate_series для создания последовательности чисел между минимальным и максимальным значениями из столбца num в таблице temp

SELECT date(
(SELECT julianday(min(started))
FROM experiment) + value) AS some_day
FROM
(SELECT value
FROM generate_series(
(SELECT 0),
(SELECT count(*) - 1
FROM experiment)))
LIMIT 5;
| some_day |
|------------|
| 2023-01-29 |
| 2023-01-30 |
| 2023-01-31 |
| 2023-02-01 |
| 2023-02-02 |
SELECT julianday(min(started)) FROM experiment — находим минимальную дату в столбце started из experiment, преобразуем её в Julian день (числовое представление даты) и возвращаем этот Julian день
внешним подзапросом вычисляем разницу между этим минимальным Julian днем и каждым value из generate_series
затем складываем эти разницы с минимальным Julian днем, и конвертируем обратно в дату с помощью date()
ну и выбираем только первые 5 результатов этого вычисления с помощью LIMIT 5

WITH -- complete sequence of days with 0 as placeholder for number of experiments
all_days AS (
SELECT DATE (
(
SELECT julianday (MIN(started))
FROM experiment
) + VALUE
) AS some_day,
0 AS zeroes
FROM (
SELECT VALUE
FROM generate_series (
(
SELECT 0
),
(
SELECT COUNT(*) - 1
FROM experiment
)
)
)
), -- sequence of actual days with actual number of experiments started
actual_days AS (
SELECT started,
COUNT(started) AS num_exp
FROM experiment
GROUP BY started
) -- combined by joining on day and taking actual number (if available) or zero
SELECT all_days.some_day AS DAY,
COALESCE(actual_days.num_exp, all_days.zeroes) AS num_exp
FROM all_days
LEFT JOIN actual_days ON all_days.some_day = actual_days.started
LIMIT 5;
| day | num_exp |
|------------|---------|
| 2023-01-29 | 1 |
| 2023-01-30 | 1 |
| 2023-01-31 | 0 |
| 2023-02-01 | 0 |
| 2023-02-02 | 1 |
создаём последовательность всех дней с нулевым значением в качестве заполнителя для количества экспериментов
создаём последовательность фактических дней с реальным числом экспериментов
объединяем эти последовательности, соединяя их по дням и беря реальное количество (если доступно) или ноль
выводит результат, показывая дни (all_days.some_day) и соответствующее количество экспериментов (COALESCE(actual_days.num_exp, all_days.zeroes) AS num_exp), при этом используется функция COALESCE, чтобы использовать фактическое количество экспериментов, если оно доступно, или ноль, если нет

WITH person AS (
SELECT ident,
personal || ' ' || family AS name
FROM staff
)
SELECT LEFT.name,
RIGHT.name
FROM person AS
LEFT JOIN person AS RIGHT
LIMIT 10;
| name | name |
|--------------|------------------|
| Kartik Gupta | Kartik Gupta |
| Kartik Gupta | Divit Dhaliwal |
| Kartik Gupta | Indrans Sridhar |
| Kartik Gupta | Pranay Khanna |
| Kartik Gupta | Riaan Dua |
| Kartik Gupta | Vedika Rout |
| Kartik Gupta | Abram Chokshi |
| Kartik Gupta | Romil Kapoor |
| Kartik Gupta | Ishaan Ramaswamy |
| Kartik Gupta | Nitya Lal |
создаём временную общую таблицу person с помощью WITH
объединяем столбцы personal и family в один столбец name
при помощи SELECT выбираем из person значения столбца name через алиасы left и right
после этого происходит объединение person с собой с помощью оператора LEFT JOIN, при этом таблица алиасируется как RIGHT
Этот SQL-код, однако, содержит ошибку, правильный синтаксис должен быть следующим:
WITH person AS (
SELECT ident,
personal || ' ' || family AS name
FROM staff
)
SELECT LEFT.name,
RIGHT.name
FROM person AS LEFT
LEFT JOIN person AS RIGHT ON < условие соединения >
LIMIT 10;
В исходном примере условие соединения (ON) не было указано

WITH person AS (
SELECT ident,
personal || ' ' || family AS name
FROM staff
)
SELECT LEFT.name,
RIGHT.name
FROM person AS
LEFT JOIN person AS RIGHT ON LEFT.ident < RIGHT.ident
WHERE LEFT.ident <= 4
AND RIGHT.ident <= 4;
| name | name |
|-----------------|-----------------|
| Kartik Gupta | Divit Dhaliwal |
| Kartik Gupta | Indrans Sridhar |
| Kartik Gupta | Pranay Khanna |
| Divit Dhaliwal | Indrans Sridhar |
| Divit Dhaliwal | Pranay Khanna |
| Indrans Sridhar | Pranay Khanna |
создаём временную таблицу person, которая содержит результат выбора из таблицы staff
из person выбираем значения left.name и right.name с использованием операции слияния (JOIN). В этом случае происходит слияние person с собой, причем каждая копия person используется в качестве левой и правой таблиц соответственно. Слияние выполняется по условию, что идентификатор слева меньше идентификатора справа.
затем применяем дополнительное условие с помощью WHERE, которое фильтрует результаты JOIN-операции. Это условие проверяет, что идентификаторы слева и справа меньше или равны 4

WITH person AS (
SELECT ident,
personal || ' ' || family AS name
FROM staff
),
together AS (
SELECT LEFT.staff AS left_staff,
RIGHT.staff AS right_staff
FROM performed AS
LEFT JOIN performed AS RIGHT ON LEFT.experiment = RIGHT.experiment
WHERE left_staff < right_staff
)
SELECT LEFT.name AS person_1,
RIGHT.name AS person_2
FROM person AS
LEFT JOIN person AS
RIGHT JOIN together ON LEFT.ident = left_staff
AND RIGHT.ident = right_staff;
| person_1 | person_2 |
|-----------------|------------------|
| Kartik Gupta | Vedika Rout |
| Pranay Khanna | Vedika Rout |
| Indrans Sridhar | Romil Kapoor |
| Abram Chokshi | Ishaan Ramaswamy |
| Pranay Khanna | Vedika Rout |
| Kartik Gupta | Abram Chokshi |
| Abram Chokshi | Romil Kapoor |
| Kartik Gupta | Divit Dhaliwal |
| Divit Dhaliwal | Abram Chokshi |
| Pranay Khanna | Ishaan Ramaswamy |
| Indrans Sridhar | Romil Kapoor |
| Kartik Gupta | Ishaan Ramaswamy |
| Kartik Gupta | Nitya Lal |
| Kartik Gupta | Abram Chokshi |
| Pranay Khanna | Romil Kapoor |
во временной табличке person выбираем имена сотрудников из таблицы staff; используем personal ' ' family AS name, чтобы объединить значения из столбцов personal и family
временная табличка together использует оператор LEFT JOIN для объединения таблицы performed с собой на основе столбца experiment. Затем выбираются пары сотрудников, участвовавших в одном и том же эксперименте, исключая случаи, когда идентификатор левого сотрудника (left_staff) больше идентификатора правого сотрудника (right_staff)
затем выполняется основной SELECT, который использует person и together для объединения имен сотрудников на основе их идентификаторов. Он выполняет два LEFT JOIN, чтобы объединить person с самим собой и затем объединить результат с together на основе идентификаторов сотрудников.
затем выбираются имена сотрудников для отображения в итоговом результате.

SELECT name,
building
FROM department
WHERE EXISTS
(SELECT 1
FROM staff
WHERE dept = department.ident )
ORDER BY name;
| name | building |
|-------------------|------------------|
| Genetics | Chesson |
| Histology | Fashet Extension |
| Molecular Biology | Chesson |
выбираем столбцы name и building из таблицы department
WHERE EXISTS (SELECT 1 FROM staff WHERE dept = department.ident ) — используем подзапрос, который проверяет существование хотя бы одной записи в таблице staff, для которой значение столбца dept совпадает с значением столбца ident из таблицы department
ORDER BY name — устанавливаем порядок сортировки результатов по столбцу name в алфавитном порядке

SELECT name,
building
FROM department
WHERE NOT EXISTS
(SELECT 1
FROM staff
WHERE dept = department.ident )
ORDER BY name;
| name | building |
|---------------|----------|
| Endocrinology | TGVH |
выбираем столбцы name и building из таблицы department
WHERE NOT EXISTS — выбираем только те записи из department, для которых не существует записей в таблице staff
SELECT 1 FROM staff WHERE dept = department.ident — проверяем, существуют ли записи в таблице staff, связанные с отделом из таблицы department
ORDER BY name — сортируем результат по столбцу name
Избегание коррелированных подзапросов
src/avoid_correlated_subqueries.sql
SELECT DISTINCT department.name AS name,
department.building AS building
FROM department
JOIN staff ON department.ident = staff.dept
ORDER BY name;
out/avoid_correlated_subqueries.out
| name | building |
|-------------------|------------------|
| Genetics | Chesson |
| Histology | Fashet Extension |
| Molecular Biology | Chesson |
SELECT DISTINCT — выбираем уникальные значения name и building из таблицы department
JOIN staff ON department.ident = staff.dept — объединяем таблицы department и staff на основе условия, что значение столбца ident из department равно значению dept из staff
ORDER BY name — результаты выборки сортируем в алфавитном порядке по столбцу name

WITH ym_num AS (
SELECT strftime ('%Y-%m', started) AS ym,
COUNT(*) AS num
FROM experiment
GROUP BY ym
)
SELECT ym,
lag (num) OVER (
ORDER BY ym
) AS prev_num,
num,
lead (num) OVER (
ORDER BY ym
) AS next_num
FROM ym_num
ORDER BY ym;
| ym | prev_num | num | next_num |
|---------|----------|-----|----------|
| 2023-01 | | 2 | 5 |
| 2023-02 | 2 | 5 | 5 |
| 2023-03 | 5 | 5 | 1 |
| 2023-04 | 5 | 1 | 6 |
| 2023-05 | 1 | 6 | 5 |
| 2023-06 | 6 | 5 | 3 |
| 2023-07 | 5 | 3 | 2 |
| 2023-08 | 3 | 2 | 4 |
| 2023-09 | 2 | 4 | 6 |
| 2023-10 | 4 | 6 | 4 |
| 2023-12 | 6 | 4 | 5 |
| 2024-01 | 4 | 5 | 2 |
| 2024-02 | 5 | 2 | |
создаём временную таблицу ym_num из 2 столбцов: ym (год-месяц 'YYYY-MM') и num (количество записей в каждом месяце)
используем SQLite strftime для извлечения года и месяца из started, агрегируем результаты с помощью GROUP BY
в основном запросе выбираем данные из ym_num, выполняем следующие операции и получаем год-месяц ym, количество записей в предыдущем месяце (lag)num, текущее количество записей num и количество записей в следующем месяце (lead)num
результаты упорядочиваем по столбцу ym (год-месяц)

WITH ym_num AS (
SELECT strftime ('%Y-%m', started) AS ym,
COUNT(*) AS num
FROM experiment
GROUP BY ym
)
SELECT ym,
num,
SUM(num) OVER (
ORDER BY ym
) AS num_done,
CUME_DIST() OVER (
ORDER BY ym
) AS progress
FROM ym_num
ORDER BY ym;
| ym | num | num_done | progress |
|---------|-----|----------|--------------------|
| 2023-01 | 2 | 2 | 0.0769230769230769 |
| 2023-02 | 5 | 7 | 0.153846153846154 |
| 2023-03 | 5 | 12 | 0.230769230769231 |
| 2023-04 | 1 | 13 | 0.307692307692308 |
| 2023-05 | 6 | 19 | 0.384615384615385 |
| 2023-06 | 5 | 24 | 0.461538461538462 |
| 2023-07 | 3 | 27 | 0.538461538461538 |
| 2023-08 | 2 | 29 | 0.615384615384615 |
| 2023-09 | 4 | 33 | 0.692307692307692 |
| 2023-10 | 6 | 39 | 0.769230769230769 |
| 2023-12 | 4 | 43 | 0.846153846153846 |
| 2024-01 | 5 | 48 | 0.923076923076923 |
| 2024-02 | 2 | 50 | 1.0 |
создаём временную таблицу ym_num, которая содержит: ym — год и месяц, извлеченные из started в experiment с помощью strftime('%Y-%m'); num — количество записей в experiment для каждого сочетания года и месяца
выбираем ym и num из таблицы ym_num, добавляем 2 дополнительных столбца: num_done — сумма количества экспериментов по всем предыдущим годам и месяцам (sum(num) OVER (ORDER BY ym)); progress — кумулятивное распределение количества экспериментов по всем предыдущим годам и месяцам (cume_dist() OVER (ORDER BY ym))
упорядочиваем результаты по столбцу ym (год и месяц)
Внезапно небольшое задание: объясните, что делает запрос ниже
src/explain_window_function.sql
EXPLAIN query PLAN
WITH ym_num AS (
SELECT strftime ('%Y-%m', started) AS ym,
COUNT(*) AS num
FROM experiment
GROUP BY ym
)
SELECT ym,
num,
SUM(num) OVER (
ORDER BY ym
) AS num_done,
CUME_DIST() OVER (
ORDER BY ym
) AS progress
FROM ym_num
ORDER BY ym;
out/explain_window_function.out
QUERY PLAN
|--CO-ROUTINE (subquery-3)
| |--CO-ROUTINE (subquery-4)
| | |--CO-ROUTINE ym_num
| | | |--SCAN experiment
| | | `--USE TEMP B-TREE FOR GROUP BY
| | |--SCAN ym_num
| | `--USE TEMP B-TREE FOR ORDER BY
| `--SCAN (subquery-4)
`--SCAN (subquery-3)
создаём временную табличку ym_num с результатами агрегирования по месяцам, где данные из started преобразуются в формат год-месяц (strftime('%Y-%m', started) AS ym) и подсчитываем количество событий (count(*) AS num)
группируем результаты по полю ym
выбираем поля ym и num из ym_num и добавляем 2 дополнительных поля: num_done и progress; num_done — общее количество событий/мес, сгруппированных в порядке увеличения месяца; поле progress — прогресс в процентном соотношении относительно общего числа записей (cume_dist())
в итоге выводим данные в порядке увеличения значения ym (год-месяц)

WITH y_m_num AS
(SELECT strftime('%Y', started) AS YEAR,
strftime('%m', started) AS MONTH,
count(*) AS num
FROM experiment
GROUP BY YEAR,
MONTH)
SELECT YEAR,
MONTH,
num,
sum(num) OVER (PARTITION BY YEAR
ORDER BY MONTH) AS num_done
FROM y_m_num
ORDER BY YEAR,
MONTH;
| year | month | num | num_done |
|------|-------|-----|----------|
| 2023 | 01 | 2 | 2 |
| 2023 | 02 | 5 | 7 |
| 2023 | 03 | 5 | 12 |
| 2023 | 04 | 1 | 13 |
| 2023 | 05 | 6 | 19 |
| 2023 | 06 | 5 | 24 |
| 2023 | 07 | 3 | 27 |
| 2023 | 08 | 2 | 29 |
| 2023 | 09 | 4 | 33 |
| 2023 | 10 | 6 | 39 |
| 2023 | 12 | 4 | 43 |
| 2024 | 01 | 5 | 5 |
| 2024 | 02 | 2 | 7 |
создаём временную таблицу y_m_num с тремя столбцами: YEAR, MONTH и num.
временную табличку заполняем записями из experiment. Для каждой записи определяем год и месяц даты в столбце started (через strftime), считаем количество записей (count(*)) для каждого года и месяца, группируем результаты по году и месяцу
выбираем данные из y_m_num, добавляем столбец num_done — накопительное значение для num в пределах каждого года sum(num) OVER (PARTITION BY YEAR ORDER BY MONTH) — суммируем значение num для каждого месяца при сортировке по месяцам внутри каждого года
в итоге сортируем результаты по году и месяцу с помощью ORDER BY YEAR, MONTH

CREATE TABLE images (name text NOT NULL,
content blob);
INSERT INTO images(name, content)
VALUES ("biohazard", readfile("img/biohazard.png")),
("crush", readfile("img/crush.png")),
("fire", readfile("img/fire.png")),
("radioactive", readfile("img/radioactive.png")),
("tripping", readfile("img/tripping.png"));
SELECT name,
length(content)
FROM images;
| name | length(content) |
|-------------|-----------------|
| biohazard | 19629 |
| crush | 15967 |
| fire | 18699 |
| radioactive | 16661 |
| tripping | 17208 |
создаём таблицу images со столбцами: name — текстовый столбец, не может быть пустым; content — столбец двоичных данных (blob)
вставляем 5 пар name-blob в images с помощью INSERT INTO
readfile читает содержимое файла name и возвращает его как двоичные данные blob
выполняем выборку данных из images с помощью SELECT, получая значения name и вычисляя количество байт двоичных данных в content
Ещё одна БД
sqlite3 data/lab_log.db
.schema
CREATE TABLE sqlite_sequence(name,
seq);
CREATE TABLE person(ident integer PRIMARY KEY autoincrement,
details text NOT NULL);
CREATE TABLE machine(ident integer PRIMARY KEY autoincrement,
name text NOT NULL,
details text NOT NULL);
CREATE TABLE usage(ident integer PRIMARY KEY autoincrement,
log text NOT NULL);
создаём sqlite_sequence со столбцами name и seq (для значения счетчика, он используется в качестве AUTOINCREMENT)
создаём person со столбцами ident (целочисленный, является первичным ключом (PRIMARY KEY), автоматически инкрементируется) и details (текстовый столбец, не может иметь значение NULL)
создаём machine со столбцами ident (целочисленный, является первичным ключом (PRIMARY KEY), автоматически инкрементируется), name (текстовый, не может иметь значение NULL), details (текстовый, не может иметь значение NULL)
создаём usage со столбцами ident (целочисленный, является первичным ключом (PRIMARY KEY), автоматически инкрементируется) и log (текстовый столбец, не может иметь значение NULL)

SELECT *
FROM machine;
| ident | name | details |
|-------|----------------|---------------------------------------------------------|
| 1 | WY401 | {"acquired": "2023-05-01"} |
| 2 | Inphormex | {"acquired": "2021-07-15", "refurbished": "2023-10-22"} |
| 3 | AutoPlate 9000 | {"note": "needs software update"} |

SELECT details->'$.acquired' AS single_arrow,
details->>'$.acquired' AS double_arrow
FROM machine;
| single_arrow | double_arrow |
|--------------|--------------|
| "2023-05-01" | 2023-05-01 |
| "2021-07-15" | 2021-07-15 |
| | |
details->'$.acquired' AS single_arrow — с помощью -> извлекаем значение JSON поля acquired из столбца details для каждой строки из machine, обозначаем его как single_arrow
details->>'$.acquired' AS double_arrow — оператор ->> также используется для извлечения JSON по указанному пути, но возвращает текст, в отличие от ->, который возвращает JSON значение; здесь мы извлекаем значение JSON поля acquired из столбца details для каждой строки из machine, обозначаем его как double_arrow

SELECT ident,
json_array_length(log->'$') AS LENGTH,
log->'$[0]' AS FIRST
FROM USAGE;
| ident | length | first |
|-------|--------|--------------------------------------------------------------|
| 1 | 4 | {"machine":"Inphormex","person":["Gabrielle","Dub\u00e9"]} |
| 2 | 5 | {"machine":"Inphormex","person":["Marianne","Richer"]} |
| 3 | 2 | {"machine":"sterilizer","person":["Josette","Villeneuve"]} |
| 4 | 1 | {"machine":"sterilizer","person":["Maude","Goulet"]} |
| 5 | 2 | {"machine":"AutoPlate 9000","person":["Brigitte","Michaud"]} |
| 6 | 1 | {"machine":"sterilizer","person":["Marianne","Richer"]} |
| 7 | 3 | {"machine":"WY401","person":["Maude","Goulet"]} |
| 8 | 1 | {"machine":"AutoPlate 9000"} |
json_array_length(log->'$') AS LENGTH — вычисляем длину массива, находящегося внутри JSON-объекта в столбце log; используем оператор ->, чтобы получить массив из корневого уровня JSON-объекта, и json_array_length для подсчета количества элементов в этом массиве; результат помещаем в столбец с именем LENGTH
log->'$[0]' AS FIRST — извлекаем первый элемент из массива, указанного в корневом уровне JSON-объекта в столбце log; используем оператор ->, чтобы получить доступ к массиву, и указываем индекс элемента в квадратных скобках; результат сохраняем в столбец FIRST

SELECT ident,
json_each.key AS KEY,
json_each.value AS value
FROM USAGE,
json_each(usage.log)
LIMIT 10;
| ident | key | value |
|-------|-----|--------------------------------------------------------------|
| 1 | 0 | {"machine":"Inphormex","person":["Gabrielle","Dub\u00e9"]} |
| 1 | 1 | {"machine":"Inphormex","person":["Gabrielle","Dub\u00e9"]} |
| 1 | 2 | {"machine":"WY401","person":["Gabrielle","Dub\u00e9"]} |
| 1 | 3 | {"machine":"Inphormex","person":["Gabrielle","Dub\u00e9"]} |
| 2 | 0 | {"machine":"Inphormex","person":["Marianne","Richer"]} |
| 2 | 1 | {"machine":"AutoPlate 9000","person":["Marianne","Richer"]} |
| 2 | 2 | {"machine":"sterilizer","person":["Marianne","Richer"]} |
| 2 | 3 | {"machine":"AutoPlate 9000","person":["Monique","Marcotte"]} |
| 2 | 4 | {"machine":"sterilizer","person":["Marianne","Richer"]} |
| 3 | 0 | {"machine":"sterilizer","person":["Josette","Villeneuve"]} |
SELECT ident, json_each.key AS KEY, json_each.value AS value — определяем, что нужно выбрать из таблицы usage и JSON-объектов, распарсенных с помощью функции json_each; из каждой строки выбираем идентификатор, а также ключ и его значение из каждого JSON-объекта в столбце log
FROM usage, json_each(usage.log) — указываем источник данных для выборки; usage указывается после ключевого слова FROM, а json_each вызывается перед log, чтобы разобрать JSON-объекты из этого столбца
LIMIT 10 — выбираем только первые 10 строк

SELECT ident,
log->'$[#-1].machine' AS FINAL
FROM USAGE
LIMIT 5;
| ident | final |
|-------|--------------|
| 1 | "Inphormex" |
| 2 | "sterilizer" |
| 3 | "Inphormex" |
| 4 | "sterilizer" |
| 5 | "sterilizer" |
SELECT ident, log->'$[#-1].machine' AS FINAL — выбираем 2 столбца из machine; ident возвращается как есть, а столбец log обрабатывается так:
log->'$[#-1].machine — извлекаем данные из столбца log (-> используется для доступа к JSON-полю в столбце log)
$[#-1] — обращаемся к последнему элементу массива, который хранится в log
.machine — хотим извлечь значение поля machine из объекта, находящегося в последнем элементе массива

SELECT ident,
name,
json_set(details, '$.sold', json_quote('2024-01-25')) AS updated
FROM machine;
| ident | name | updated |
|-------|----------------|--------------------------------------------------------------|
| 1 | WY401 | {"acquired":"2023-05-01","sold":"2024-01-25"} |
| 2 | Inphormex | {"acquired":"2021-07-15","refurbished":"2023-10-22","sold":" |
| | | 2024-01-25"} |
| 3 | AutoPlate 9000 | {"note":"needs software update","sold":"2024-01-25"} |
SELECT ident, name, ... FROM machine; — выбираем значения столбцов ident и name из таблицы machine
json_set(details, '$.sold', json_quote('2024-01-25')) AS updated — при помощи json_set обновляем JSON-объект в столбце details; функция добавляет/изменяет свойство sold в JSON-объекте в столбце details, присваивая ему новое значение, полученное с помощью функции json_quote; результат сохраняем как updated
Обновляем табличку penguins:
SELECT species,
count(*) AS num
FROM penguins
GROUP BY species;
| species | num |
|-----------|-----|
| Adelie | 152 |
| Chinstrap | 68 |
| Gentoo | 124 |

ALTER TABLE penguins ADD active integer NOT NULL DEFAULT 1;
UPDATE penguins
SET active = IIF(species = 'Adelie', 0, 1);
изменяем таблицу penguins, добавляя новый столбец active типа integer, который не может содержать значение NULL, и устанавливаем значение по умолчанию 1 для всех строк
обновляем значения в столбце active в penguins; значение столбца active устанавливается на 0, если значение в species равно 'Adelie', иначе устанавливается на 1
функция IIF (Immediate If) используется здесь для реализации условного выражения (1 аргумент - условие, 2 - результат, если условие истинно, и 3 - результат, если условие ложно)
SELECT species,
count(*) AS num
FROM penguins
WHERE active
GROUP BY species;
| species | num |
|-----------|-----|
| Chinstrap | 68 |
| Gentoo | 124 |

CREATE VIEW IF NOT EXISTS active_penguins (species, island, bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g, sex) AS
SELECT species,
island,
bill_length_mm,
bill_depth_mm,
flipper_length_mm,
body_mass_g,
sex
FROM penguins
WHERE active;
SELECT species,
count(*) AS num
FROM active_penguins
GROUP BY species;
| species | num |
|-----------|-----|
| Chinstrap | 68 |
| Gentoo | 124 |
создаём представление (VIEW) с именем active_penguins, если его еще не существует
представление содержит столбцы species, island, bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g, и sex; данные для представления берутся из penguins, при условии, что пингвины являются активными (WHERE active)
выполняем выборку из представления active_penguins: выбираем вид пингвина (species) и количество таких пингвинов (num), удовлетворяющих условиям, заданным в представлении active_penguins
Напоминание о часах работы:
CREATE TABLE job (name text NOT NULL,
billable real NOT NULL);
INSERT INTO job
VALUES ('calibrate', 1.5),
('clean', 0.5);
SELECT *
FROM job;
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
| clean | 0.5 |

CREATE TABLE job (name text NOT NULL,
billable real NOT NULL, CHECK (billable > 0.0));
INSERT INTO job
VALUES ('calibrate', 1.5);
INSERT INTO job
VALUES ('reset', -0.5);
SELECT *
FROM job;
Runtime error near line 9: CHECK constraint failed: billable > 0.0 (19)
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
создаём таблицу job с 2 столбцами, которые не могут быть пустыми: name (текстовый тип данных) и billable (вещественные тип данных)
ограничение (CHECK) гарантирует, что значение столбца billable должно быть больше чем 0.0
добавляем новую запись в job с указанными значениями 'calibrate' для столбца name и 1.5 для столбца billable — сейчас под условие CHECK это попадает
пытаемся добавить еще одну запись в таблицу job с указанными значениями 'reset' для столбца name и -0.5 для столбца billable. Однако, так как -0.5 меньше либо равно 0.0, то это нарушает условие CHECK
ACID
ACID — это акроним, который описывает набор свойств транзакций баз данных, предназначенных для обеспечения целостности данных в случае ошибок, сбоев питания и других непредвиденных ситуаций:
Атомарность (Atomicity): Транзакция должна быть атомарной, что означает, что она должна быть выполнена целиком или не выполнена вообще. Если одна часть транзакции не может быть выполнена, то все изменения, сделанные в рамках этой транзакции, должны быть отменены.
Согласованность (Consistency): Транзакция должна приводить базу данных из одного согласованного состояния в другое согласованное состояние. Это означает, что все правила и ограничения, установленные на данные, должны быть соблюдены во время выполнения транзакции.
Изолированность (Isolation): Транзакции должны быть изолированы друг от друга, чтобы предотвратить взаимное влияние. Каждая транзакция должна быть выполнена так, как если бы она была единственной выполняемой транзакцией в базе данных. Это гарантирует, что результаты одной транзакции не будут видны другим транзакциям до их завершения.
Долговечность (Durability): Результаты выполненной транзакции должны быть постоянными и доступными даже в случае сбоя системы или перезагрузки. Это достигается путем записи изменений в постоянное хранилище, например SSD.

CREATE TABLE job (name text NOT NULL,
billable real NOT NULL, CHECK (billable > 0.0));
INSERT INTO job
VALUES ('calibrate', 1.5);
BEGIN TRANSACTION;
INSERT INTO job
VALUES ('clean', 0.5);
ROLLBACK;
SELECT *
FROM job;
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
создаём таблицу job с 2 колонками, которые не могут быть пустыми:
name текстового типа
billable с типом данных real (вещественное число) и условием CHECK (billable > 0.0), что гарантирует, что значение billable больше 0.0
добавляем в job запись: ('calibrate', 1.5)
начинаем новую транзакцию.
добавляем другую запись в таблицу job: ('clean', 0.5)
откатываем последнюю транзакцию, добавляя 'clean', 0.5, поэтому данная строка не сохраняется

CREATE TABLE job (
name text NOT NULL,
billable real NOT NULL,
CHECK (billable > 0.0) ON CONFLICT ROLLBACK
);
INSERT INTO job
VALUES ('calibrate', 1.5);
INSERT INTO job
VALUES ('clean', 0.5),
('reset', -0.5);
SELECT *
FROM job;
Runtime error near line 11: CHECK constraint failed: billable > 0.0 (19)
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
создаём новую таблицу с именем job и 2 непустыми столбцами: текстовым name и вещественным billable
значение в billable должно быть больше 0 (CHECK (billable > 0.0))
добавляем в job запись с именем calibrate со значением billable 1.5
вторая запись с именем clean имеет значение billable равное 0.5
третья запись с именем reset имеет значение billable равное -0.5 — тут возникает проблема с записью третьей строки, так как это нарушает ограничение CHECK (billable > 0.0)

CREATE TABLE job (name text NOT NULL,
billable real NOT NULL,
CHECK (billable > 0.0));
INSERT OR ROLLBACK INTO job
VALUES ('calibrate', 1.5);
INSERT OR ROLLBACK INTO job
VALUES ('clean', 0.5),
('reset', -0.5);
SELECT *
FROM job;
Runtime error near line 11: CHECK constraint failed: billable > 0.0 (19)
| name | billable |
|-----------|----------|
| calibrate | 1.5 |
создаём таблицу job с 2 непустыми столбцами:
текстовым столбцом name
вещественнозначным billable с ограничением CHECK (billable > 0.0) — значение в этом столбце всегда будет больше нуля
вставляем данные в job с помощью оператора INSERT OR ROLLBACK, а именно одну запись с названием calibrate и значением billable равным 1.5
вставляем ещё 2 записи в таблицу job с помощью оператора INSERT OR ROLLBACK: clean со значением 0.5 для billable, reset со значением -0.5 billable (что не подходит по условию CHECK)

CREATE TABLE jobs_done (person text UNIQUE,
num integer DEFAULT 0);
INSERT INTO jobs_done
VALUES("zia", 1);
.print "after first"
SELECT *
FROM jobs_done;
.print
INSERT INTO jobs_done
VALUES("zia", 1);
.print "after failed"
SELECT *
FROM jobs_done;
INSERT INTO jobs_done
VALUES("zia", 1) ON conflict(person) DO
UPDATE
SET num = num + 1;
.print "\nafter upsert"
SELECT *
FROM jobs_done;
after first
| person | num |
|--------|-----|
| zia | 1 |
Runtime error near line 14: UNIQUE constraint failed: jobs_done.person (19)
after failed
| person | num |
|--------|-----|
| zia | 1 |
after upsert
| person | num |
|--------|-----|
| zia | 2 |
создаём jobs_done со столбцами person (текстовый тип данных с уникальными значениями) и num (целочисленный тип, по умолчанию равен 0)
вставляем в jobs_done запись с именем "zia" и числом 1
пытаемся снова вставить строку с тем же именем "zia" и числом 1 и снова выводим результаты запроса SELECT
вставляем строку с тем же именем "zia" и числом 1 но уже указываем, чтобы в случае конфликта по столбцу person, обновить значение столбца num, увеличив его на 1

-- Track hours of lab work.
CREATE TABLE job (person text NOT NULL,
reported real NOT NULL CHECK (reported >= 0.0));
-- Explicitly store per-person total rather than using sum().
CREATE TABLE total (person text UNIQUE NOT NULL,
hours real);
-- Initialize totals.
INSERT INTO total
VALUES ("gene", 0.0),
("august", 0.0);
-- Define a trigger.
CREATE TRIGGER total_trigger
BEFORE
INSERT ON job BEGIN -- Check that the person exists.
SELECT CASE
WHEN NOT EXISTS
(SELECT 1
FROM total
WHERE person = new.person) THEN raise
(ROLLBACK, 'Unknown person ')
END; -- Update their total hours (or fail if non-negative constraint violated).
UPDATE total
SET hours = hours + new.reported
WHERE total.person = new.person; END;
создаём таблицу job со столбцами person и reported
создаём total со столбцами person и hours
устанавливаем значения gene и august в 0.0
создаём триггер total_trigger, который срабатывает перед вставкой новых записей в таблицу job. Этот триггер:
проверяет, существует ли человек в таблице total, прежде чем разрешить вставку новых записей в таблицу job
обновляет общее количество отработанных часов для соответствующего человека в таблице total путем добавления нового количества отработанных часов из таблицы job
INSERT INTO job
VALUES ('gene', 1.5),
('august', 0.5),
('gene', 1.0);
| person | reported |
|--------|----------|
| gene | 1.5 |
| august | 0.5 |
| gene | 1.0 |
| person | hours |
|--------|-------|
| gene | 2.5 |
| august | 0.5 |
Срабатывание триггера
INSERT INTO job
VALUES ('gene', 1.0),
('august', -1.0) ;
Runtime error near line 6: CHECK constraint failed: reported >= 0.0 (19)
| person | hours |
|--------|-------|
| gene | 0.0 |
| august | 0.0 |
Графическое представление
CREATE TABLE lineage (parent text NOT NULL,
child text NOT NULL);
INSERT INTO lineage
VALUES ('Arturo', 'Clemente'),
('Darío', 'Clemente'),
('Clemente', 'Homero'),
('Clemente', 'Ivonne'),
('Ivonne', 'Lourdes'),
('Soledad', 'Lourdes'),
('Lourdes', 'Santiago');
SELECT *
FROM lineage;
| parent | child |
|----------|----------|
| Arturo | Clemente |
| Darío | Clemente |
| Clemente | Homero |
| Clemente | Ivonne |
| Ivonne | Lourdes |
| Soledad | Lourdes |
| Lourdes | Santiago |
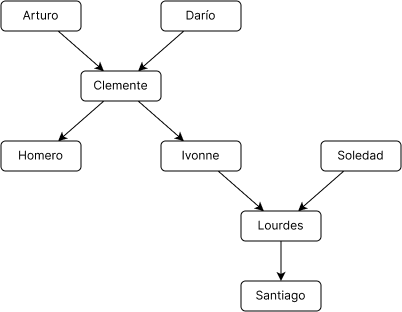

WITH RECURSIVE descendent AS (
SELECT 'Clemente' AS person,
0 AS generations
UNION ALL
SELECT lineage.child AS person,
descendent.generations + 1 AS generations
FROM descendent
JOIN lineage ON descendent.person = lineage.parent
)
SELECT person,
generations
FROM descendent;
| person | generations |
|----------|-------------|
| Clemente | 0 |
| Homero | 1 |
| Ivonne | 1 |
| Lourdes | 2 |
| Santiago | 3 |
определяем общий термин descendent (потомок) как рекурсивное общее выражение. Начинаем с одной записи, где 'Clemente' - это начальное имя, а 0 - это количество поколений.
далее мы выполняем рекурсивное объединение с самим собой (с descendent) и таблицей lineage, чтобы найти всех потомков для каждого найденного человека. Выбираем потомка из таблицы lineage, увеличиваем количество поколений на 1 и продолжаем делать это для всех найденных потомков, пока они находятся
если новых потомков больше не найдено, используем SELECT для выбора столбцов person и generations из descendent
База данных отслеживания контактов
SELECT *
FROM person;
| ident | name |
|-------|-----------------------|
| 1 | Juana Baeza |
| 2 | Agustín Rodríquez |
| 3 | Ariadna Caraballo |
| 4 | Micaela Laboy |
| 5 | Verónica Altamirano |
| 6 | Reina Rivero |
| 7 | Elias Merino |
| 8 | Minerva Guerrero |
| 9 | Mauro Balderas |
| 10 | Pilar Alarcón |
| 11 | Daniela Menéndez |
| 12 | Marco Antonio Barrera |
| 13 | Cristal Soliz |
| 14 | Bernardo Narváez |
| 15 | Óscar Barrios |
SELECT *
FROM contact;
| left | right |
|-------------------|-----------------------|
| Agustín Rodríquez | Ariadna Caraballo |
| Agustín Rodríquez | Verónica Altamirano |
| Juana Baeza | Verónica Altamirano |
| Juana Baeza | Micaela Laboy |
| Pilar Alarcón | Reina Rivero |
| Cristal Soliz | Marco Antonio Barrera |
| Cristal Soliz | Daniela Menéndez |
| Daniela Menéndez | Marco Antonio Barrera |


CREATE TEMPORARY TABLE bi_contact (LEFT text, RIGHT text);
INSERT INTO bi_contact
SELECT LEFT,
RIGHT
FROM contact
UNION ALL
SELECT RIGHT,
LEFT
FROM contact;
| original_count |
|----------------|
| 8 |
| num_contact |
|-------------|
| 16 |
создаём временную табличку bi_contact с 2 столбцами: LEFT и RIGHT, оба текстовые
вставляем в bi_contact данные из другой таблицы при помощи SELECT
используем UNION ALL для объединения результатов 2 операций SELECT в один набор данных; данные из столбца LEFT и RIGHT таблицы contact вставляем в таблицу bi_contact. Первый набор данных берёт значения из столбцов LEFT и RIGHT таблицы contact, а второй набор данных берёт значения из столбцов RIGHT и LEFT таблицы contact
в общем, вставляем в bi_contact комбинацию значений из столбцов LEFT и RIGHT таблицы contact и их перевёрнутые комбинации

SELECT left.name AS left_name,
left.ident AS left_ident,
right.name AS right_name,
right.ident AS right_ident,
min(left.ident, right.ident) AS new_ident
FROM (
person AS
LEFT JOIN bi_contact ON left.name = bi_contact.left
)
JOIN person AS RIGHT ON bi_contact.right = right.name;
| left_name | left_ident | right_name | right_ident | new_ident |
|-----------------------|------------|-----------------------|-------------|-----------|
| Juana Baeza | 1 | Micaela Laboy | 4 | 1 |
| Juana Baeza | 1 | Verónica Altamirano | 5 | 1 |
| Agustín Rodríquez | 2 | Ariadna Caraballo | 3 | 2 |
| Agustín Rodríquez | 2 | Verónica Altamirano | 5 | 2 |
| Ariadna Caraballo | 3 | Agustín Rodríquez | 2 | 2 |
| Micaela Laboy | 4 | Juana Baeza | 1 | 1 |
| Verónica Altamirano | 5 | Agustín Rodríquez | 2 | 2 |
| Verónica Altamirano | 5 | Juana Baeza | 1 | 1 |
| Reina Rivero | 6 | Pilar Alarcón | 10 | 6 |
| Pilar Alarcón | 10 | Reina Rivero | 6 | 6 |
| Daniela Menéndez | 11 | Cristal Soliz | 13 | 11 |
| Daniela Menéndez | 11 | Marco Antonio Barrera | 12 | 11 |
| Marco Antonio Barrera | 12 | Cristal Soliz | 13 | 12 |
| Marco Antonio Barrera | 12 | Daniela Menéndez | 11 | 11 |
| Cristal Soliz | 13 | Daniela Menéndez | 11 | 11 |
| Cristal Soliz | 13 | Marco Antonio Barrera | 12 | 12 |

WITH recursive labeled AS (
SELECT person.NAME AS NAME,
person.ident AS label
FROM person
UNION -- not 'union all'
SELECT person.NAME AS NAME,
labeled.label AS label
FROM (
person
JOIN bi_contact ON person.NAME = bi_contact.LEFT
)
JOIN labeled ON bi_contact.RIGHT = labeled.NAME
WHERE labeled.label < person.ident
)
SELECT NAME,
min(label) AS group_id
FROM labeled
GROUP BY NAME
ORDER BY label,
NAME;
| name | group_id |
|-----------------------|----------|
| Agustín Rodríquez | 1 |
| Ariadna Caraballo | 1 |
| Juana Baeza | 1 |
| Micaela Laboy | 1 |
| Verónica Altamirano | 1 |
| Pilar Alarcón | 6 |
| Reina Rivero | 6 |
| Elias Merino | 7 |
| Minerva Guerrero | 8 |
| Mauro Balderas | 9 |
| Cristal Soliz | 11 |
| Daniela Menéndez | 11 |
| Marco Antonio Barrera | 11 |
| Bernardo Narváez | 14 |
| Óscar Barrios | 15 |
определяем рекурсивное выражение labeled — оно начинается с базового запроса, который выбирает имена и идентификаторы из таблицы person,
затем используется UNION для объединения с другим запросом, который соединяет таблицы person и bi_contact, используя столбцы name и left в bi_contact и имена и метки из person
затем объединяет результаты этого соединения с ранее помеченными записями из labeled
WHERE устанавливает условие, что метка предыдущей записи должна быть меньше, чем идентификатор текущей записи person
выполняем основной запрос — выбираем имена из labeled и вычисляем минимальную метку для каждого имени как group_id с помощью функции min()
результат группируем по именам и сортируем сначала по метке, а затем по имени
attention: только не используйте тут UNION ALL, иначе возникнет бесконечная рекурсия)

import sqlite3
connection = sqlite3.connect("db/penguins.db")
cursor = connection.execute("SELECT count(*) FROM penguins;")
rows = cursor.fetchall()
print(rows)
[(344,)]
импортируем библиотечку sqlite3 (к слову, она является одной из стандартных библиотек) для работы с SQLite
устанавливаем соединение с БД, расположенной в файле "db/penguins.db", используя метод sqlite3.connect(). Если этого файл не существует, то он будет создан
создаём объект cursor для выполнения SQL-запросов
select count(*) from penguins; — подсчитываем количество всех записей в таблице penguins
fetchall() — получаем результат выполнения запроса, сохраняем его в переменную rows

import sqlite3
connection = sqlite3.connect("db/penguins.db")
cursor = connection.cursor()
cursor = cursor.execute("SELECT species, island FROM penguins LIMIT 5;")
while row := cursor.fetchone():
print(row)
('Adelie', 'Torgersen')
('Adelie', 'Torgersen')
('Adelie', 'Torgersen')
('Adelie', 'Torgersen')
('Adelie', 'Torgersen')
коннектимся к БД с помощью sqlite3.connect("db/penguins.db")
connection.cursor() — создаём объект cursor, это указатель на результат выполнения запросов
select species, island from penguins limit 5; — выбираем первые 5 записей из таблицы penguins, возвращая значения столбцов species и island
пока переменная row из cursor.fetchone() непустая, печатаем её (мы сразу создаём переменную row и тут же используем её при помощи := )

import sqlite3
connection = sqlite3.connect(":memory:")
cursor = connection.cursor()
cursor.execute("CREATE TABLE example(num integer);")
cursor.execute("INSERT INTO example VALUES (10),(20);")
print("after insertion", cursor.execute("SELECT * FROM example;").fetchall())
cursor.execute("DELETE FROM example WHERE num < 15;")
print("after deletion", cursor.execute("SELECT * FROM example;").fetchall())
after insertion [(10,), (20,)]
after deletion [(20,)]
connection = sqlite3.connect(":memory:") — создаём подключение к БД SQLite, созданной в оперативной памяти
cursor = connection.cursor() — создаём объект курсора, который используется для выполнения операций в БД
cursor.execute("CREATE TABLE example(num integer);") — создаём новую таблицу с именем example и одним столбцом num для хранения целых чисел
cursor.execute("INSERT INTO example VALUES (10),(20);") — вставляем 2 строки в example с числами 10 и 20 в столбец num
print("after insertion", cursor.execute("SELECT * FROM example;").fetchall()) — выводим содержимое таблицы example после вставки строк; выполняем операцию SELECT, чтобы выбрать все строки из таблицы, используя метод .fetchall() для извлечения результатов запроса
cursor.execute("DELETE FROM example WHERE num < 15;") — удаляем строки из таблицы example, в которых значение столбца num меньше 15
ну и в конце выводим содержимое таблицы example после удаления строк; также выполняем SELECT, чтобы выбрать все строки из таблицы, используя метод .fetchall() для извлечения результатов запроса

import sqlite3
connection = sqlite3.connect(":memory:")
cursor = connection.cursor()
cursor.execute("CREATE TABLE example(num integer);")
cursor.executemany("insert into example values (?);", [(10,), (20,)])
print("after insertion", cursor.execute("SELECT * FROM example;").fetchall())
after insertion [(10,), (20,)]
connection = sqlite3.connect(":memory:") — устанавливаем соединение с БД SQLite в оперативной памяти
cursor = connection.cursor() — создаём объект курсора, который используется для выполнения операций БД
cursor.execute("create table example(num integer);") — создаём таблицу example с одним столбцом num типа integer
cursor.executemany("insert into example values (?);", [(10,), (20,)]) — вставляем значения 10 и 20 в столбец num таблицы example с использованием параметризованного запроса

import sqlite3
SETUP = """\
DROP TABLE IF EXISTS example;
CREATE TABLE example(num integer);
INSERT INTO example
VALUES (10),
(20);
"""
connection = sqlite3.connect(":memory:")
cursor = connection.cursor()
cursor.executescript(SETUP)
print("after insertion", cursor.execute("SELECT * FROM example;").fetchall())
after insertion [(10,), (20,)]
удаляем таблицу example, если она существует
создаём таблицу example с одним столбцом num типа integer
вставляем 2 записи в таблицу example с числами 10 и 20
выполняем SETUP с помощью метода курсора executescript(), который создает новую таблицу и вставляет данные
выводим after insertion для обозначения того, что последующий запрос к базе данных будет относиться к состоянию после вставки данных
выполняем запрос к БД для выбора всех записей из таблицы example с помощью метода execute() и fetchall() для извлечения результатов

import sqlite3
SETUP = """\
CREATE TABLE example(num integer check(num > 0));
INSERT INTO example
VALUES (10);
INSERT INTO example
VALUES (-1);
INSERT INTO example
VALUES (20);
"""
connection = sqlite3.connect(":memory:")
cursor = connection.cursor()
try:
cursor.executescript(SETUP)
except sqlite3.Error as exc:
print(f"SQLite exception: {exc}")
print("after execution", cursor.execute("SELECT * FROM example;").fetchall())
SQLite exception: CHECK constraint failed: num > 0
after execution [(10,)]
устанавливаем соединение с БД в оперативной памяти с помощью sqlite3.connect(":memory:")
создаём курсор для выполнения операци
создаём таблицу example и вставляем в нее 3 значения с помощью executescript()
в блоке try-except обрабатывается исключение sqlite3.Error, если произойдет какая-либо ошибка при выполнении запросов
выводим содержимое таблицы example после выполнения запросов с помощью метода fetchall()

import sqlite3
SETUP = """\
CREATE TABLE example(num integer);
INSERT INTO example
VALUES (-10),
(10),
(20),
(30);
"""
def clip(value):
if value < 0:
return 0
if value > 20:
return 20
return value
connection = sqlite3.connect(":memory:")
connection.create_function("clip", 1, clip)
cursor = connection.cursor()
cursor.executescript(SETUP)
for row in cursor.execute("SELECT num, clip(num) FROM example;").fetchall():
print(row)
(-10, 0)
(10, 10)
(20, 20)
(30, 20)
создаём БД SQLite в оперативной памяти, создаём табличку example, заполняем её таблицу значениями (-10, 10, 20, 30)
затем определяем функцию clip, которая принимает один аргумент и возвращает этот аргумент, если он находится между 0 и 20, или возвращает 0, если аргумент меньше 0, или возвращает 20, если аргумент больше 20
выбираем значения из столбца num таблицы example и применяет функцию clip к каждому значению

from datetime import date
import sqlite3
# Convert date to ISO-formatted string when writing to database
def _adapt_date_iso(val):
return val.isoformat()
sqlite3.register_adapter(date, _adapt_date_iso)
# Convert ISO-formatted string to date when reading from database
def _convert_date(val):
return date.fromisoformat(val.decode())
sqlite3.register_converter("date", _convert_date)
SETUP = """\
CREATE TABLE events(happened date NOT NULL,
description text NOT NULL);
"""
connection = sqlite3.connect(":memory:", detect_types=sqlite3.PARSE_DECLTYPES)
cursor = connection.cursor()
cursor.execute(SETUP)
cursor.executemany(
"insert into events values (?, ?);",
[(date(2024, 1, 10), "started tutorial"), (date(2024, 1, 29), "finished tutorial")],
)
for row in cursor.execute("SELECT * FROM EVENTS;").fetchall():
print(row)
(datetime.date(2024, 1, 10), 'started tutorial')
(datetime.date(2024, 1, 29), 'finished tutorial')
определяем функцию _adapt_date_iso(val) — она принимает дату и возвращает ее строковое представление в формате ISO
определяем функцию _convert_date(val) — она принимает строку в формате ISO и возвращает объект типа date
затем эти функции регистрируются в SQLite, чтобы обеспечить корректное преобразование данного типа данных при записи и чтении из базы данных
после этого создается строка SETUP, которая содержит SQL-команду для создания таблицы events с двумя столбцами: happened типа date и description типа text
с помощью cursor.executemany в таблицу events вставляются 2 записи с использованием значений типа date и строк
с помощью select * from events и cursor.execute извлекаем значения всех строк из таблицы events

pip install jupysql
%load_ext sql
%sql sqlite:///data/penguins.db
Connecting to 'sqlite:///data/penguins.db'
Подключение к БД:
sqlite:// — протокол с 2 слэшами в конце
/data/penguins.db — 1 слэш спереди, это путь к локальной БД
1 знак процента %sql — для выполнения однострочных SQL-запросов
2 знака процента %%sql показывает, что вся ячейка будет восприниматься как один SQL-запрос
%%sql
SELECT species,
count(*) AS num
FROM penguins
GROUP BY species;
Running query in 'sqlite:///data/penguins.db'
species | num |
|---|---|
Adelie | 152 |
Chinstrap | 68 |
Gentoo | 124 |

pip install pandas
import pandas as pd
import sqlite3
connection = sqlite3.connect("db/penguins.db")
query = "SELECT species, count(*) AS num FROM penguins GROUP BY species;"
df = pd.read_sql(query, connection)
print(df)
species num
0 Adelie 152
1 Chinstrap 68
2 Gentoo 124
select species, count(*) as num from penguins group by species; — извлекаем информацию о количестве пингвинов каждого вида из penguins и группируем результаты по видам
выполняем запрос к БД с использованием метода read_sql библиотеки pandas, который читает результаты запроса и преобразует их в объект DataFrame (df)

pip install polars pyarrow adbc-driver-sqlite
import polars as pl
query = "SELECT species, count(*) AS num FROM penguins GROUP BY species;"
uri = "sqlite:///db/penguins.db"
df = pl.read_database_uri(query, uri, engine="adbc")
print(df)
shape: (3, 2)
┌───────────┬─────┐
│ species ┆ num │
│ --- ┆ --- │
│ str ┆ i64 │
╞═══════════╪═════╡
│ Adelie ┆ 152 │
│ Chinstrap ┆ 68 │
│ Gentoo ┆ 124 │
└───────────┴─────┘
импортирует библиотеку Polars - она похожа на pandas, но с фокусом на параллельную обработку данных
выбираем столбец species и вычисляем количество записей для каждого вида пингвинов из таблицы penguins; результат группируем по столбцу species
устанавливаем строку подключения к базе данных SQLite в переменной uri
используем pl.read_database_uri для выполнения SQL-запроса query к БД, указанной в uri, используя движок adbc
выводим результат выполнения запроса в виде таблицы данных

from sqlmodel import Field, Session, SQLModel, create_engine, select
class Department(SQLModel, table=True):
ident: str = Field(default=None, primary_key=True)
name: str
building: str
engine = create_engine("sqlite:///db/assays.db")
with Session(engine) as session:
statement = select(Department)
for result in session.exec(statement).all():
print(result)
building='Chesson' name='Genetics' ident='gen'
building='Fashet Extension' name='Histology' ident='hist'
building='Chesson' name='Molecular Biology' ident='mb'
building='TGVH' name='Endocrinology' ident='end'
создаём класс Department, который представляет модель данных для отделов; каждый атрибут класса соответствует столбцу в таблице БД
создаём объект engine, который представляет собой подключение к SQLite БД, где assays.db - это имя файла БД
создаём Session для взаимодействия с базой данных через созданный engine
формируем SQL-запрос с помощью select(Department), который выбирает все данные из таблицы, представленной моделью Department
выполняем запрос к БД через session.exec(statement).all(), который возвращает все строки, удовлетворяющие условию запроса

class Staff(SQLModel, table=True):
ident: str = Field(default=None, primary_key=True)
personal: str
family: str
dept: Optional[str] = Field(default=None, foreign_key="department.ident")
age: int
engine = create_engine("sqlite:///db/assays.db")
SQLModel.metadata.create_all(engine)
with Session(engine) as session:
statement = select(Department, Staff).where(Staff.dept == Department.ident)
for dept, staff in session.exec(statement):
print(f"{dept.name}: {staff.personal} {staff.family}")
Histology: Divit Dhaliwal
Molecular Biology: Indrans Sridhar
Molecular Biology: Pranay Khanna
Histology: Vedika Rout
Genetics: Abram Chokshi
Histology: Romil Kapoor
Molecular Biology: Ishaan Ramaswamy
Genetics: Nitya Lal
объявляем класс Staff; он использует SQLModel, что позволяет использовать этот класс как схему для создания таблицы в БД. Указание table=True в качестве аргумента класса говорит SQLModel о том, что данный класс должен отображаться в базу данных как таблица. У Staff есть несколько атрибутов :
ident - строковое поле, которое будет использоваться в качестве первичного ключа в базе данных. Оно имеет значение по умолчанию None и задается как первичный ключ (primary_key=True)
personal - строковое поле
family - строковое поле
dept - опциональное строковое поле; имеет значение по умолчанию None и устанавливается как внешний ключ (foreign_key="department.ident")
age - целочисленное поле
после определения Staff, создается экземпляр движка для работы с БД SQLite с помощью вызова функции create_engine из библиотеки SQLAlchemy
затем вызываем метод create_all у метаданных SQLModel, что приводит к созданию всех таблиц, определенных в виде классов с помощью SQLModel, на основе ранее созданного движка базы данных
далее устанавливаем сессия БД с использованием созданного ранее движка
формируется SQL-запрос, который выбирает данные из таблиц Department и Staff, объединяя их по условию, что поле Staff.dept равно полю Department.ident
выполняем этот запрос в сессии БД, и для каждой строки результата выводится название отдела и персональные данные сотрудника

Что ж, пользуйтесь этими примерами SQL-запросов на здоровье; особенно эта подборка может быть полезной, если хочется кому-то объяснить что-то из SQL, и нужен подходящий пример
Всех с пятницей!