Meduza.io: а как же лайки?
- суббота, 7 мая 2016 г. в 03:14:21
Как-то раз, читая новости на Медузе, я обратил внимание на то, что у разных новостей разное соотношение лайков из Facebook и ВКонтакте. Какие-то новости мегапопулярны на fb, а другими люди делятся только во ВКонтакте. Захотелось присмотреться к этим данным, попытаться найти в них интересные закономерности. Заинтересовавшихся приглашаю под кат!
Первым делом нужно получить данные для анализа. Предвкушая скорое расчехление Python + BeautifulSoup, я начал читать исходный код страниц. Разочарование ждало довольно быстро: эти данные подгружатся не сразу вместе с html'ой, а отложенно. Так как я не умею JavaScript, я начал искать ноги в сетевых соединениях страницы, и довольно быстро наткнулся на замечательную ручку API медузы:
https://meduza.io/api/v3/social?links=["shapito/2016/05/03/poliem-vse-kislotoy-i-votknem-provod-v-rozetku"]Ручка возвращает приятную глазу json'ку:

Ну и конечно, раз links это массив, то сразу хочется попробовать подставить туда сразу несколько записей, и, ура, получаем интересующий нас список.
Даже парсить ничего не пришлось!
Теперь хочется получить данные о самих новостях. Здесь хочется поблагодарить хаброжителя sirekanyan за его статью, где он нашел другую ручку.
https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ruОпытным путём удалось установить, что максимальное значение параметра per_page равно 30, а page около 752 на момент написания статьи. Важной проверка того, что ручка social выдержит все 30 документов, пройдена успешно.
Осталось только выгрузить! Я использовал простенький скрипт на питоне
stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru'
social = 'https://meduza.io/api/v3/social'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36'
headers = {'User-Agent' : user_agent }
def get_page_data(page):
# Достаём страницы
ans = requests.get(stream.format(page = page), headers=headers).json()
# отдельно достаёт все социальные
ans_social = requests.get(social, params = {'links' : json.dumps(ans['collection'])}, headers=headers).json()
documents = ans['documents']
for url, data in documents.iteritems():
try:
data['social'] = ans_social[url]['stats']
except KeyError:
continue
with open('res_dump/page{pagenum:03d}_{timestamp}.json'.format(
pagenum = page, timestamp = int(time.time())
), 'wb') as f:
json.dump(documents, f, indent=2)На всякий случай подставил валидный User-Agent, но и без этого всё работает.
Далее для распараллеливания и визуализации процесса очень помог скрипт моего бывшего коллеги, alexkuku. Подробнее про подход можно почитать в его посте, он позволил сделать вот такой мониторинг:

Данные выгрузились очень быстро, менее чем за 10 минут, никакой капчи или заметного замедления. Качал в 4 потока с одного айпишника, без каких-либо надстроек.
Итак, на выходе у нас получилась большая json'ка с данными. Теперь загоним её в pandas dataframe, и покрутим в Jupyter.
Загрузим нужные данные:
df = pd.read_json('database.json').T
df = df.join(pd.DataFrame(df.social.to_dict()).T)
df.pub_date = pd.DatetimeIndex(df.pub_date)
df['trust']=df.source.apply(lambda x: x.get('trust', None) if type(x) == dict else None)Построим boxplot
df[['fb', 'tw','vk']].plot.box(logy = True);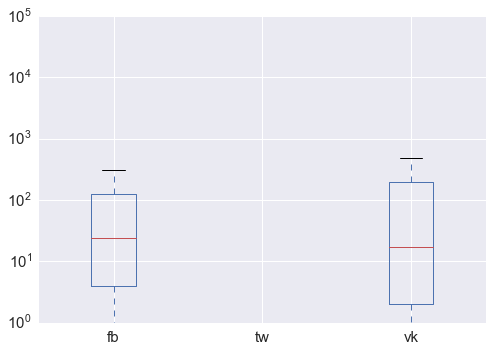
Сразу несколько выводов:
Так кто же те самые супер-репостнутые новости медузы? Угадаете?
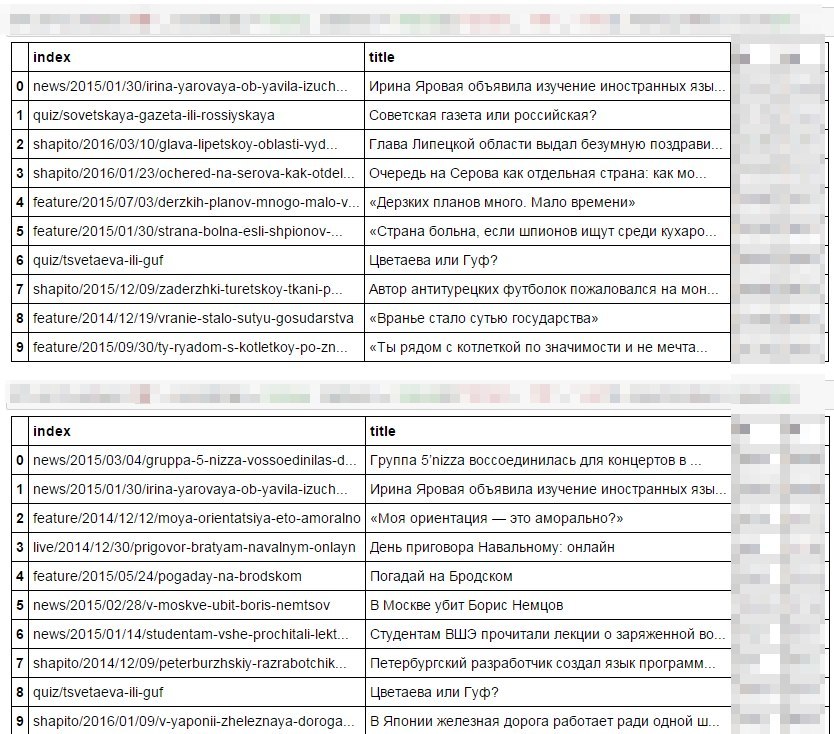
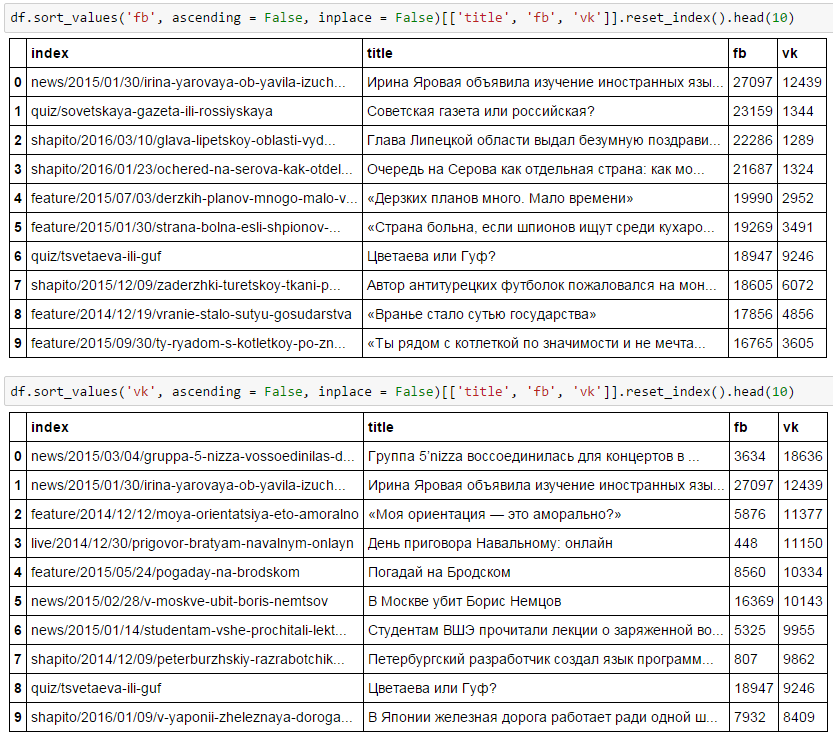
Ну конечно же, первое это FB: там же иностранные языки, советские газеты, Серов. А во второй 5nizza, "Моя ориентация", политика. Не знаю, как по мне, так всё очевидно!
Единственное, в чем схожи предпочтения двух соц.сетей: это Ирина Яровая, да Цветаева с Гуфом.
Теперь, хочется посмотреть на scatter plot двух величин: ожидается, что данные будут хорошо коррелировать друг с другом.
df['logvk'] = np.log10(df.vk)
df['logfb'] = np.log10(df.fb)
# Без логарифмов совсем непонятная картинка
sns.regplot('logfb', 'logvk', data = df )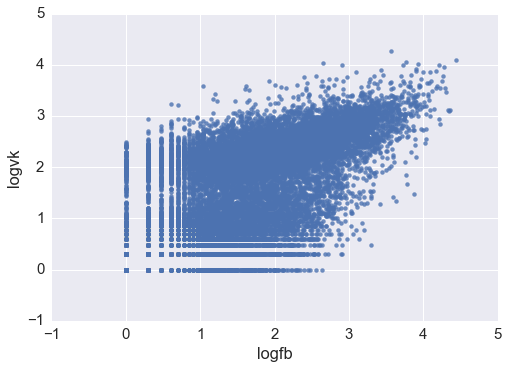
sns.set(style="ticks")
sns.jointplot('logfb', 'logvk',
data = df.replace([np.inf, -np.inf], np.nan).dropna(subset = ['logfb', 'logvk']),
kind="hex")
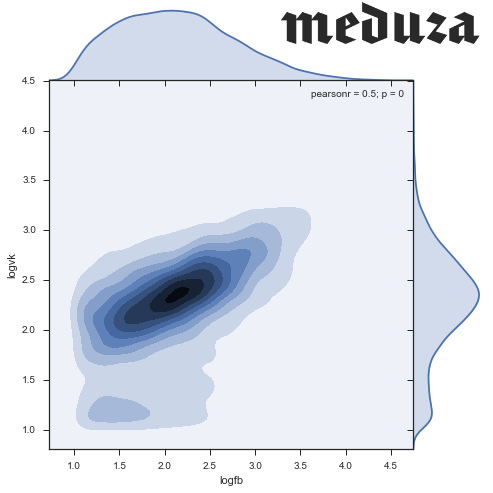
Кажется, видно два кластера: один с центром в (2.3, 2.4), и второй размазанный около нуля. В целом нет цели провести анализ даже для низкочастотных новостей (тех, которые оказались неинтересными в соц.сетях), так что давайте ограничимся только записями с более 10 лайков в обеих сетях. Не забудем проверить, что мы избавились от незначительного числа наблюдений.
stripped = df[(df.logfb > 1) & (df.logvk > 1)]
print "Working with {0:.0%} of news, {1:.0%} of social network activity".format(
float(len(stripped)) / len(df), float(stripped[['vk', 'fb']].sum().sum()) / df[['vk', 'fb']].sum().sum()
)
# Working with 47% of news, 95% of social network activityПлотность:
sns.jointplot('logfb', 'logvk', data = stripped, kind="kde", size=7, space=0)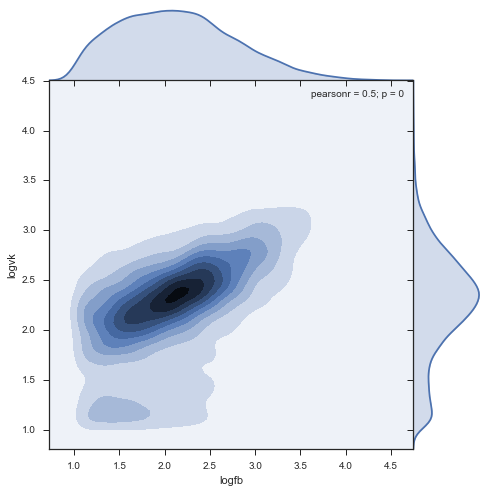
Теперь хочется посмотреть на это соотношений в динамике: возможно, оно менялось.
by_month = stripped.set_index('pub_date').groupby(pd.TimeGrouper(freq = 'MS')).agg({'fb':sum, 'vk':sum})
by_month.plot( kind = 'area')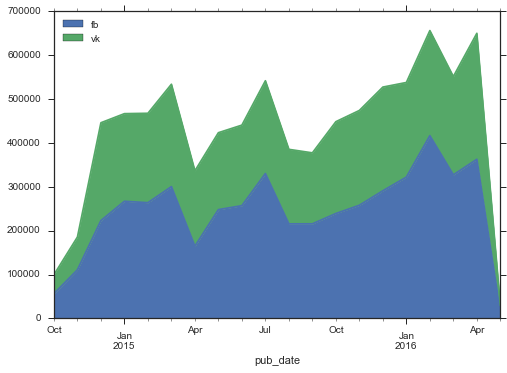
Интересно, что при общем росте объема активности в соц.сетях, фейсбук растёт быстрее. Кроме того здесь не видно какого-то взрывного роста, который я ожидал бы увидеть в Медузе. Первые месяцы активность была довольно низкой, но уже к декабрю 2014 уровень стабилизировался, новый рост начался лишь через год.
Посмотрим на динамику плотности распределения комментариев из двух социальных сетей:
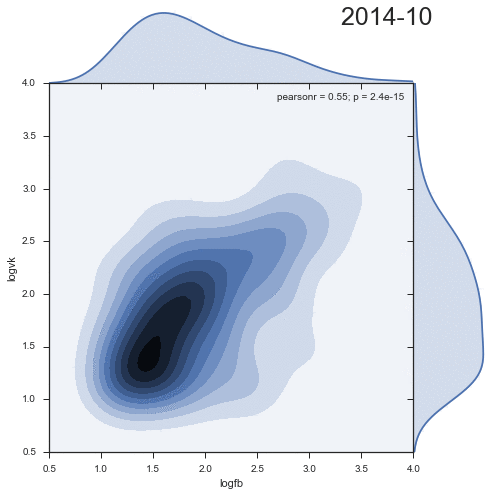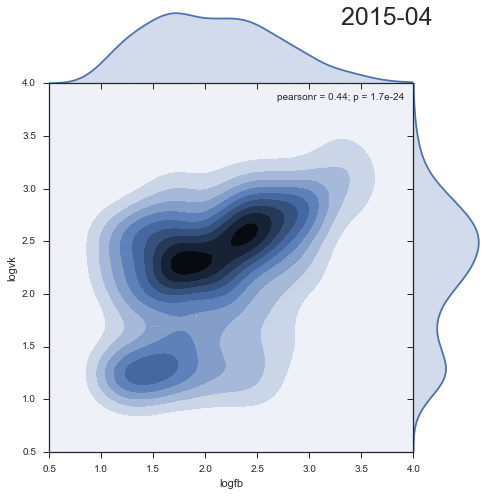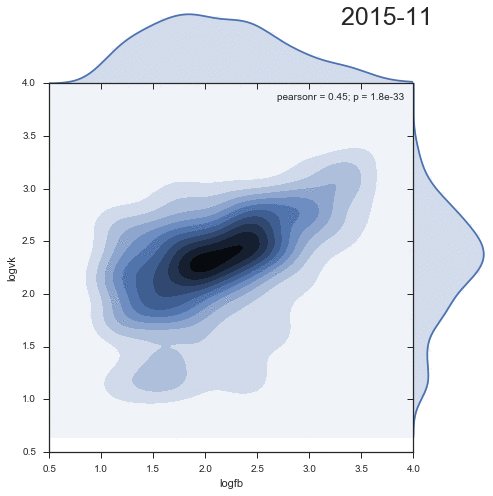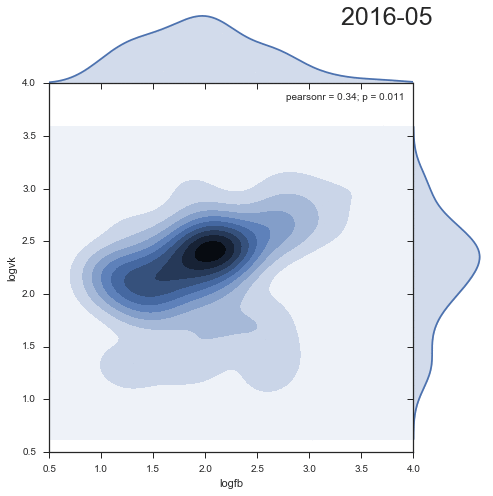
Довольно занятно, что второй кластер уменьшается со временем, и скорее является артефактом прошлого.
Наконец, хочется проверить, что соотношение социальных сетей не меняется от типа документа: у Медузы кроме новостей есть карточки, истории, шапито, галереи, а также полигон.
def hexbin(x, y, color, **kwargs):
cmap = sns.light_palette(color, as_cmap=True)
plt.hexbin(x, y, gridsize=20, cmap=cmap, **kwargs)
g = sns.FacetGrid(stripped.loc[::-1], col="document_type", margin_titles=True, size=5, col_wrap = 3)
g.map(hexbin, "logfb", "logvk", extent=[1, 4, 1, 4]);
В целом видно, что данные вполне себе однородны по классам, нет заметных перекосов. Я ожидал бы от "шапито" большей социальной активности, но этого эффекта не наблюдается.
Зато, если посмотреть на разбивку по уровню доверия к источнику, то приятно видеть, что ненадежный источник менее популярен в соц.сетях, особенно в фейсбуке:

На этом мой вечер завершился, и я пошел спать.